ARQUITECTURA HÍBRIDA SIMD/MIMD DINÁMICAMENTE RECONFIGURABLE DE UN COPROCESADOR PARA SISTEMAS DE VISIÓN.
La presente invención se refiere a una arquitectura híbrida Simple Instrucción-Múltiples Datos (SIMD)/Múltiples Instrucciones-Múltiples Datos (MIMD),
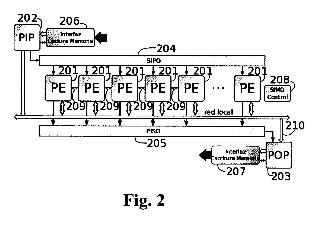
dinámicamente reconfigurable, de un coprocesador que se emplea en sistemas altas prestaciones para tareas de visión por computador. La arquitectura comprende un conjunto de elementos de procesamiento (PE) que reciben datos a través de una red local o de una cola de entrada serie salida paralela (SIPO), ambas gestionadas por un procesado de entrada programable (PIP). Los resultados obtenidos se envían al exterior a través de una cola de entrada paralela y salida serie (PISO) o a través de la red local, estando ambos elementos gestionados por el procesador de salida programable (POP).
Tipo: Patente de Invención. Resumen de patente/invención. Número de Solicitud: P201101381.
Solicitante: UNIVERSIDADE DE SANTIAGO DE COMPOSTELA.
Nacionalidad solicitante: España.
Inventor/es: NIETO LAREO,Alejandro Manuel, BREA SÁNCHEZ,Victor Manuel, LÓPEZ VILARIÑO,David.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G06F15/80 FISICA. › G06 CALCULO; CONTEO. › G06F PROCESAMIENTO ELECTRICO DE DATOS DIGITALES (sistemas de computadores basados en modelos de cálculo específicos G06N). › G06F 15/00 Computadores digitales en general (detalles G06F 1/00 - G06F 13/00 ); Equipo de procesamiento de datos en general. › que comprenden un conjunto de unidades de procesamiento con control común, p. ej. varios procesadores de datos de instrucción única (G06F 15/82 tiene prioridad).
Fragmento de la descripción:
CAMPO DE LA TÉCNICA
La presente invención se refiere a una arquitectura híbrida Simple InstrucciónMúltiples Datos (SIMD) /Múltiples Instrucciones-Múltiples Datos (MIMD) , dinámicamente reconfigurable, de un coprocesador que se emplea en sistemas de altas prestaciones para tareas de visión por computador.
La invención presenta una aplicación en sistemas de visión artificial para aplicaciones de vídeo-vigilancia inteligente, guiado de robots, procesado de imagen médica o dispositivos de seguridad en el automóvil, y en general a sistemas que se basen en el procesado de imágenes o vídeo digitales.
ANTECEDENTES DE LA INVENCIÓN
En la actualidad existen una gran variedad de técnicas para procesar imagen y vídeo digital que son ampliamente utilizadas en la industria, algunos ejemplos de estas técnicas son la detección y el seguimiento de objetos o la monitorización de procesos. Estas técnicas suelen tener un elevado coste computacional, que implican un elevado tiempo de cómputo cuando se procesan en sistemas convencionales, como puede ser un
"
ordenador personal, por lo que existe una gran demanda de dispositivos hardware que permiten reducir su tiempo de cómputo. La traslación de la implementación software en un ordenador a dispositivos hardware no es directa y en muchos casos hay que realizar una serie de simplificaciones que reducen la funcionalidad del sistema. Además, los elevados costes computacionales de estas técnicas van en contra de los requerimientos de bajo consumo de potencia, consumo de memoria y forma de las plataformas hardware.
La industria demanda aplicaciones de visión capaces de realizar tareas de
análisis sin afectar a la precisión o al rendimiento del sistema. Los recientes avances en la industria han permitido el desarrollo de sistemas de visión por computador que poseen una gran eficiencia y un gran poder de cómputo, así como bajo consumo de potencia y un reducido coste de ingeniería no recurrente. Debido al elevado coste computacional de muchas aplicaciones industriales, tales como vídeo-vigilancia, guiado de robots o dispositivos de seguridad en el automóvil, los campos de arquitectura de computadores, computación serie y paralela y sistemas inteligentes han sufrido un gran desarrollo durante estos últimos años. Los esfuerzos realizados en estas áreas han ido encaminados al desarrollo de sistemas de procesado de imagen y vídeo. Además de los requerimientos de precisión y rendimiento, a este tipo de sistemas también se les exige la obtención de prototipos en un corto período de tiempo y a un bajo precio.
Los circuitos programables Field Programmable Gate Array (FPGA) se usan ampliamente para reducir el tiempo de cómputo de las aplicaciones de visión por computador. Debido a que las FPGAs ofrecen unas prestaciones menores que los circuitos integrados para aplicaciones específicas, ASIC del inglés Application Specific Integrated Circuit, al permitir reconfigurar el hardware en aplicaciones que requieran que la respuesta del sistema sea un factor crítico el producto final suele ser un ASIC. Sin embargo, en los últimos años las FPGAs han dado un gran salto al incorporar más recursos, como pueden ser bloques de Procesador de Señal Digital, del inglés Digital Signal Processor (DSP) o bloques de memoria RAM, sin un incremento significativo del coste no recurrente. Los Sistemas en Chip, del inglés System on Chip (SoC) , se ven favorecidos, reduciendo el ciclo de desarrollo, por el uso de FPGAs. Así, el uso de uno u otro tipo de circuitos dependerá en gran medida del volumen de producción.
Los sistemas de visión por computador tienen que gestionar eficientemente una serie de operaciones, dependencias entre datos y flujo de datos. Las operaciones matemáticas que se deben realizar en los sistemas de visión por computador se pueden agrupar en:
• Operaciones de bajo nivel simples y repetitivas que trabajan sobre un conjunto de datos elevados, en las que se requiere gran paralelismo. Son operaciones con un patrón regular de acceso a los datos y de control.
• Operaciones de nivel medio en las que existe dependencias en el flujo de datos. Son operaciones que presentan un acceso regular a los datos pero en las que hay un flujo irregular de datos y control.
• Operaciones de alto nivel que trabajan sobre conjuntos complejos y reducidos de datos y que requieren una gran precisión. Debido a su complejidad este tipo de operaciones suelen ser llevadas a cabo por procesadores de propósito general.
Debido a la complejidad de los algoritmos de visión por computador cualquier sistema de propósito general debe ser capaz de abordar estos tres tipos de operaciones, . A causa de la variabilidad de operaciones con las que tienen que trabajar los sistemas de visión por computador se han desarrollado arquitecturas que permiten operar con la diversidad de operaciones empleadas en este tipo de sistemas. Así, se han desarrollado sistemas que permiten resolver operaciones de bajo y medio nivel de forma eficiente, en las que se puede explotar el paralelismo espacial ofrecido por una implementación hardware, y que actúan como aceleradores de procesadores de propósito general, que se encargan de llevar a cabo las operaciones de alto nivel.
Las operaciones de bajo nivel se enmarcan dentro del campo de procesadores SIMD, que están formados por un elevado conjunto de elementos de procesamiento, que realizan la misma operación sobre distintos datos y con los que obtienen un grado de paralelismo espacial elevado. Por contra, las operaciones de nivel medio son tratadas por procesadores MIMD, que están formados por varios elementos de procesamiento, en los que se ejecutan distintas instrucciones sobre distintos datos de acuerdo a flujos irregulares de datos y de control.
Los procesadores SIMD han sido ampliamente utilizados para la resolución de tareas de bajo nivel, pero el desarrollo de técnicas avanzadas de procesado de imágenes y vídeo han propiciado nuevas necesidades, por lo que el desarrollo de procesadores MIMD se ha visto favorecido. Recientemente, se han propuesto procesadores híbridos
que se engloban en la tipología SIMD y MIMD, que combinan características de ambos
tipos de procesadores.
En la [Refeferencia 1] se propone un sistema híbrido SIMD/MIMD cuya funcionalidad queda restringida a multiplicación de matrices, 10 que limita su aplicación en algoritmos de visión por computador complejos, reduciendo su aplicación a operaciones de convolución (operación de bajo nivel) . En la [Referencia 2] se propone un sistema híbrido SIMD/MIMD en el que la funcionalidad de los elementos de procesamiento se define mediante una serie de instrucciones almacenadas en un buffer. Se permite el paso de modo SIMD a MIMD y viceversa aplicando una serie de conmutadores. La principal desventaja de este sistema es que la memoria se encuentra separada de los elementos de procesamiento, con 10 que se reduce la eficiencia del sistema en términos de acceso a datos. En la [Referencia 3] se propone una arquitectura híbrida SIMD/MIMD en la que los elementos de procesamiento SIMD se agrupan en bloques MIMD, 10 que es ineficiente para tareas de visión por computador en las que la presencia de un gran número de elementos de procesamiento que funcionen en modo SIMD es de gran importancia. En la [Referencia 4] se propone un sistema formado por una matriz 2D de elementos de procesamiento, en el que las instrucciones se envían a los elementos de procesamiento mediante el uso de un decodificador de filas y columnas, 10 que es altamente ineficiente en términos de consumo de área. En la [Referencia 5] se propone un sistema en el que la funcionalidad de los elementos de procesamiento está almacenada en memorias dentro del sistema, y por medio de conmutadores se puede elegir la funcionalidad de los elementos de procesamiento. Esta estructura presenta el inconveniente del gran e~pacio de memoria requerida para dotar al sistema de una funcionalidad amplia, ya que se necesitaría un gran número de memorias, 10 que redundaría en el área ocupada. En la [Referencia 6] se propone un sistema híbrido SIMD/MIMD centrado en la gestión de la eficiencia de la comunicación de los elementos de procesamiento con la memoria, que acarrea una gestión complicada de la memoria y limita su aplicación en aplicaciones de visión por computador.
[Refeferencia 1] Xiaofang Wang and Sotirios G. Ziavras....
Reivindicaciones:
1. Una arquitectura de un coprocesador empleado para el procesado de imágenes que comprende:
a. Un conjunto de elementos de procesamiento formado por dos o más elementos (201) que pueden trabajar en modo SIMD (Single Instruction Multiple Data) o MIMD (Multiple Instruction Multiple Data) .
b. Un procesador de entrada programable (202) , PIP (Programmable Input Processor) , que suministra datos al conjunto de elementos de procesamiento.
c. Un procesador de salida programable (203) , POP (Programmable Output Processor) , que extrae los datos obtenidos por el conjunto de elementos de procesamiento hacia el exterior del coprocesador.
d. Una red de conexión local (210) que permite la comunicación entre los elementos de procesamiento cuando estos trabajan en modo MIMD.
e. Un conjunto de interconexiones directas entre los elementos de procesamiento (209) que permite la conexión de uno de estos elementos de procesamiento con sus 2 vecinos adyacentes, es decir, los situados a izquierda y derecha cuando estos trabajan en modo SIMD.
f. Una cola de entrada serie-salida paralela (204) , SIPO (Serial InputParallel Output) , que distribuye los datos proporcionados por el procesador de entrada programable a los elementos de procesamiento cuando estos trabajan en modo SIMD.
g. Una cola de entrada paralela-salida serie (205) , PISO (Parallel InputSerial Output) , que extrae los datos de los elementos de procesamiento y los distribuye al procesador de salida programable cuando estos trabajan en modo SIMD.
h. Un módulo de control SIMD global (208) que permite programar la funcionalidad del conjunto de elementos de procesamiento cuando estos trabajan en modo SIMD.
1. Una interfaz de lectura de memoria (206) , que permite la comunicación del PIP con la memoria externa para realizar la lectura de datos.
J. Una interfaz de escritura de memoria (207) , que permite la comunicación del POP con la memoria externa para realizar la escritura de datos.
2. La arquitectura según la reivindicación 1, apartado a., en la que los elementos de procesamiento (201) consisten esencialmente en:
a. Una Unidad Aritmética y Lógica (407) , ALU (Arithmetic and Logic Unit) , que opera con aritmética en punto fijo (1 aritmética en punto flotante y permite la representación de datos con signo o sin signo. b. Un elemento de memoria (405) que proporciona datos a la Unidad Aritmética y Lógica cuando el elemento de procesamiento trabaja en los modos SIMD o MIMD, y que almacena el conjunto de instrucciones que el elemento de procesamiento debe ejecutar cuando trabaja en modo MIMD (404) . c. Un banco de registros (402) que permite el almacenamiento de datos. d. Una interfaz de lectura y escritura que comunica el elemento de procesamiento con la red de conexión local y con los vecinos adyacentes, que permite el intercambio de datos entre los elementos de procesamiento. e. Un módulo de control SIMD local (412) basado en banderas (Control Flag) que permite programar la funcionalidad del elemento de procesamiento cuando este trabaja en modo SIMD. f. Un módulo de control MIMD (408) que permite programar la funcionalidad de los elementos de procesamiento cuando estos trabajan en modo MIMD. g. Un selector de datos (411) que proporciona los datos a la Unidad Aritmética y Lógica. h. Una cola FIFO (401) , del inglés First In-First Out, que almacena datos provenientes de la red de acceso local y permite realizar la sincronización del flujo de datos de los distintos elementos de procesamiento.1. Un interfaz de red (409) que permite en envío y recepción de datos de la red de conexión local (410)
J. Una conexión directa a los elementos de procesamiento adyancentes
(406) que permite intercambiar información cuando los elementos de procesamiento trabajan en modo MIMD.
3. La arquitectura según la reivindicación 2, apartado a, en la que la Unidad Aritmética y Lógica puede operar con hasta 3 datos y permite realizar las siguientes operaciones:
a. Operaciones básicas aritméticas.
b. Operaciones de procesador digital de señal, DSP (Digital Signal Processor) .
c. Operaciones para el cálculo del máximo o el mínimo de un conjunto de datos.
d. Operaciones booleanas: desplazamiento (shift) y operaciones a nivel de bit (bitwise operations) .
e. Operaciones de conversión del tipo de datos: conversión a punto flotante, punto fijo y entero
4. La arquitectura según la reivindicación 2, apartado b., en la que el elemento de memoria consiste esencialmente en una Memoria de Acceso Aleatorio, RAM (Random Access Memor y ) , de doble puerto que almacena datos, cuando los elementos de procesamiento trabajan en modo SIMD, y datos e instrucciones cuando los elementos de procesamiento trabajan en modo MIMD.
5. La arquitectura según la reivindicación 2, apartado e., en la que el módulo de control SIMD local basado en banderas recibe instrucciones del módulo de control SIMD global y las demultiplexa para que sean ejecutadas por el elemento de procesamiento.
6. La arquitectura según la reivindicación 2, apartado f., en la que el módulo de control MIMD local recibe instrucciones del Procesador de Entrada Programable, que establecen la funcionalidad del elemento de procesamiento.
7. La arquitectura según la reivindicación 2, apartado g., en la que el selector de datos puede seleccionar datos del banco de registros, del elemento de memoria, de la red de conexión local y de la conexión directa del elemento de procesamiento con sus vecinos adyacentes.
8. La arquitectura según la reivindicación 1, apartado b., en la que el procesador
de entrada programable (202) consiste esencialmente en:
a. Una memoria (301) que almacena las instrucciones que va a ejecutar el procesador de entrada programable con el fin de enviar información a los elementos de procesamiento,
b. Un conjunto de registros (302) organizados en cuartetos que controlan la aritmética de generación de direcciones de memoria.
c. Una unidad aritmética y lógica (303) de enteros que opera con datos con signo y sin signo, que calcula direcciones de memoria de acuerdo a la aritmética de generación de direcciones de memoria.
d. Una memoria caché (304) que almacena direcciones de memoria y datos que se envían a los elementos de procesamiento.
e. Una interfaz (305) que permite la comunicación de la memoria caché con la cola entrada serie-salida paralela cuando los elementos de procesamiento trabajan en modo SIMD o con la red de conexión local cuando estos trabajan en modo MIMD.
f. Una interfaz (306 y 307) que permite la comunicación de la memoria caché con una memoria externa para leer datos de la misma cuando los elementos de procesamiento trabajan en modo SIMD (306) y MIMD (307) .
9. La arquitectura según la reivindicación 8, apartado b., en la que cada cuarteto de registros consiste en:
a. Un registro, denominado registro base, que almacena la dirección base del conjunto de datos a los que se accede.
b. Un registro, denominado registro índice, que almacena el desplazamiento relativo dentro del conjunto de datos a los que se accede.
c. Un registro, denominado registro de incremento, que almacena el incremento del registro índice que se realiza después de cada operación de lectura.
d. Un registro, denominado registro de módulo, que almacena el tipo de aritmética de generación de direcciones que se usa para la obtención de direcciones de memoria.
10. La arquitectura según la reivindicación 1, apartado c, en la que el procesador de salida programable (203) consiste esencialmente en:
11. La arquitectura según la reivindicación 10, apartado b, en la que cada cuarteto de registros comprende:
a. Un registro, denominado registro base, que almacena la dirección base del conjunto de datos a los que se accede.
b. Un registro, denominado registro índice, que almacena el desplazamiento relativo dentro del conjunto de datos.
c. Un registro, denominado registro de incremento, que almacena el incremento del registro índice que se realiza después de cada operación de lectura.
d. Un registro, denominado registro de módulo, que almacena el tipo de aritmética que se usa para la generación de direcciones de memoria.
12. La arquitectura según la reivindicación 1, aparatado d, en la que la red de conexión local puede ser configurada con distintas topologías de red.
Patentes similares o relacionadas:
Procesador digital de señales y dispositivo de comunicación de banda base, del 5 de Noviembre de 2018, de MediaTek Sweden AB: Una unidad de ejecución de vectores para su uso en un procesador digital de señales que tiene un núcleo de procesador, […]
Procesador digital de señales y método para direccionar una memoria en un procesador digital de señales, del 18 de Octubre de 2017, de MediaTek Sweden AB: Un procesador digital de señales que comprende al menos una unidad funcional, que puede ser una unidad de ejecución de vectores , o un acelerador, […]
Procesador de señal digital y dispositivo de comunicación de banda base, del 16 de Agosto de 2017, de MediaTek Sweden AB: Un procesador de señal digital que comprende: - un núcleo de procesador que incluye una unidad de ejecución de enteros […]
 Arquitectura híbrida SIMD/MIMD dinámicamente reconfigurable de un coprocesador para sistemas de visión, del 4 de Julio de 2013, de UNIVERSIDADE DE SANTIAGO DE COMPOSTELA: La presente invención se refiere a una arquitectura híbrida Simple Instrucción-Múltiples Datos (SIMD)/Múltiples Instrucciones-Múltiples Datos (MIMD), dinámicamente […]
Arquitectura híbrida SIMD/MIMD dinámicamente reconfigurable de un coprocesador para sistemas de visión, del 4 de Julio de 2013, de UNIVERSIDADE DE SANTIAGO DE COMPOSTELA: La presente invención se refiere a una arquitectura híbrida Simple Instrucción-Múltiples Datos (SIMD)/Múltiples Instrucciones-Múltiples Datos (MIMD), dinámicamente […]
Dispositivo de direccionamiento para procesador paralelo, del 15 de Agosto de 2012, de THALES: Procesador paralelo que comprende procesadores elementales que comprenden cada uno al menos unaunidad de cálculo y al menos una memoria que incluye palabras […]
 SISTEMA DE PROCESAMIENTO DE DATOS Y DISPOSITIVO DE COMPUTACIÓN, del 12 de Marzo de 2012, de STARLAB BARCELONA SL: Sistema de procesamiento de datos y dispositivo de computación.
El sistema comprende:
- unos dispositivos de computación que procesan en paralelo […]
SISTEMA DE PROCESAMIENTO DE DATOS Y DISPOSITIVO DE COMPUTACIÓN, del 12 de Marzo de 2012, de STARLAB BARCELONA SL: Sistema de procesamiento de datos y dispositivo de computación.
El sistema comprende:
- unos dispositivos de computación que procesan en paralelo […]
REDES NEURONALES., del 1 de Enero de 2004, de BRITISH AEROSPACE: Dispositivo para tratar datos que representan una pluralidad de ejemplos, con lo que se determina una plantilla genérica que representa dichos ejemplos, donde dicho dispositivo […]
 APARATO Y METODO PARA PROCESAR DATOS ENCAUZADOS, del 27 de Mayo de 2010, de XELERATED AB: Método de procesamiento encauzado, que comprende una pluralidad de fases (9a-9e) de procesamiento encauzado, caracterizado por las etapas de:
recibir un […]
APARATO Y METODO PARA PROCESAR DATOS ENCAUZADOS, del 27 de Mayo de 2010, de XELERATED AB: Método de procesamiento encauzado, que comprende una pluralidad de fases (9a-9e) de procesamiento encauzado, caracterizado por las etapas de:
recibir un […]