Dispositivo de direccionamiento para procesador paralelo.
Procesador paralelo que comprende procesadores elementales (3) que comprenden cada uno al menos unaunidad de cálculo y al menos una memoria que incluye palabras de memoria,
y dispuestos según una topología, conuna posición determinada en el seno de esta topología y capaces de ejecutar simultáneamente una mismainstrucción sobre datos diferentes, incluyendo la instrucción la lectura de al menos un operando y/o incluyendo laescritura de al menos un resultado, caracterizado porque la instrucción define el conjunto de las lecturas y/o elconjunto de las escrituras de los procesadores elementales, cada uno en su propia memoria como una lectura y/oescritura en un campo de acción, siendo un campo de acción un conjunto de palabras de memoria a razón de unapalabra de memoria por procesador elemental, estando esta palabra de memoria situada en la memoria delprocesador elemental, siendo un campo de acción de un operando el conjunto de las palabras de memoria leídaspor los procesadores elementales, cada uno en su propia memoria para adquirir este operando, siendo un campo deacción de un resultado el conjunto de las palabras de memoria escritas por los procesadores elementales, cada unaen su propia memoria para almacenar este resultado, porque la instrucción comprende para cada operando y/ocada resultado, informaciones relativas a la posición de este campo de acción, porque la posición del campo deacción está definida como una posición en el seno de una estructura de datos única de tipo tabla de dimensión N,siendo N un número entero igual o superior a 1, porque esta tabla está repartida en las memorias de los diferentesprocesadores elementales, porque el procesador paralelo comprende medios de cálculo de la dirección de cadaoperando y/o cada resultado en el seno de cada procesador elemental, en función de la posición del campo deacción y de la posición del procesador elemental en el seno de la topología
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/EP2008/058141.
Solicitante: THALES.
Nacionalidad solicitante: Francia.
Dirección: 45, RUE DE VILLIERS 92200 NEUILLY-SUR-SEINE FRANCIA.
Inventor/es: GAILLAT,GÉRARD.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G06F15/80 FISICA. › G06 CALCULO; CONTEO. › G06F PROCESAMIENTO ELECTRICO DE DATOS DIGITALES (sistemas de computadores basados en modelos de cálculo específicos G06N). › G06F 15/00 Computadores digitales en general (detalles G06F 1/00 - G06F 13/00 ); Equipo de procesamiento de datos en general. › que comprenden un conjunto de unidades de procesamiento con control común, p. ej. varios procesadores de datos de instrucción única (G06F 15/82 tiene prioridad).
- G06F9/34 G06F […] › G06F 9/00 Disposiciones para el control por programa, p. ej. unidades de control (control por programa para dispositivos periféricos G06F 13/10). › Direccionamiento del operando de instrucción o del resultado o acceso al operando de instrucción o al resultado.
PDF original: ES-2391690_T3.pdf
Fragmento de la descripción:
Dispositivo de direccionamiento para procesador paralelo
La presente invención se refiere a un dispositivo de direccionamiento para procesador paralelo, aplicable en particular a ordenadores paralelos de tipo SIMD.
El término SIMD se refiere a la clasificación de los ordenadores paralelos introducida por Flynn. Designa un ordenador paralelo de tipo Single Instruction Multiple Data Stream (SIMD) .
En el pasado, una o más tarjetas electrónicas eran necesarias para implementar un SIMD. Actualmente, una SIMD se puede implantar en un circuito integrado único, por ejemplo un PFGA o un ASIC.
Un SIMD descrito en relación con la figura 1, incluye
un solo secuenciador 1, una sola memoria de instrucciones 2, un gran número de procesadores elementales 3 o Processing Elements (PEs) .
Cada PE 3 incluye
una Unidad Aritmética y Lógica (ALU) 31, un conjunto de memorias y/o de registros de datos 32.
En cada ciclo, el secuenciador
determina la siguiente instrucción y la lee en la memoria de instrucciones transmite esta instrucción a todos los PEs.
La mayoría de las instrucciones definen:
una operación a ejecutar la dirección Ad donde ir a buscar cada operando de la operación, la o las direcciones Ad donde almacenar el resultado.
La operación a ejecutar comprende uno o más operandos. Puede limitarse a una operación elemental (por ejemplo, una inversión de signo o una adición o un si o un cálculo máximo) que comprende uno o más operandos o ser la combinación de varias operaciones elementales que comprenden cada una uno o más operandos (por ejemplo; una multiplicación seguida de una adición) . Asimismo, el resultado puede almacenarse en una o más direcciones.
Cada PE ejecuta esta misma instrucción al mismo tiempo pero sobre datos diferentes, en su caso sobre el conjunto de memorias y/o de registros que le pertenecen.
Evidentemente, cuando se dice en cada ciclo, se habla de un ciclo lógico cuya ejecución puede extenderse sobre varios ciclos físicos según la técnica clásica del conducto. Lo importante es que una nueva instrucción sea puesta en marcha en cada ciclo y que una nueva instrucción se acabe en cada ciclo. Independientemente de si la ejecución de la instrucción se extiende sobre varios ciclos.
Se considera por ejemplo la instrucción R (23) = R (8) + R (3) * R (19) . Significa leer el contenido del registro 3, multiplicarlo por el contenido del registro 19, añadir el resultado de esta multiplicación al contenido del registro 8 y escribir el resultado de esta suma en el registro 23. Esta misma instrucción va a ser ejecutada en paralelo por todos los PEs. Pero ninguno la ejecutará en el conjunto de registros que le pertenece. En total, si hay 129 PEs, la ejecución de la instrucción tendrá como consecuencia que 128 registros 3serán leídos, 128 registros 19 serán leídos, 128 registros 8 serán leídos, 128 multiplicaciones serán realizadas en 2 veces 128 valores diferentes, 128 sumas realizadas en 2 veces 128 valores diferentes y 128 resultados diferentes serán escritos en 128 registros 23.
La eficacia de un SIMD procede de este alto nivel de paralelismo.
En general, en un SIMD, cada PE tiene la posibilidad de leer, es decir ir a buscar los operandos de una instrucción, no solo en el conjunto de las memorias y/o registros que le pertenecen sino también en todo o parte del conjunto de las memorias y/o registros que pertenecen a uno de sus vecinos, véase por ejemplo el documento GB 2 417 105. Una variante que puede ser un complemento o una alternativa es que cada PE tenga la posibilidad de escribir el resultado de una instrucción no solo en memorias y/o registros que le pertenecen sino también en memorias y/o registros que pertenecen a uno de sus vecinos.
La noción de vecindad entre PEs está definida por la arquitectura del SIMD y más concretamente por la topología de interconexión entre PEs. Varias topologías de interconexión entre PEs han sido propuestas. Las más complejas son verdaderas redes de interconexión entre PEs. La más sencilla es una columna vertical de PEs. Otra topología sencilla es una rejilla bidimensional de PEs. Se pueden imaginar también rejillas multidimensionales de PEs. En general, en estos 3 últimos casos, los extremos están “pegado”. De este modo, en la topología monodimensional la columna verrtical de PE se convierte en un círculo (a menudo se denomiona anillo de PE. Gracias a este repegado, el vecino Sur del PE más al Sur es el PE más al Norte y el vecino Norte del PE más al Norte es el PE más al Sur. Asimismo, en la topología bidimensional, la rejilla de PEs se convierte en un toro. Finalmente, en la topología multidimensional, la rejilla muldimensional se convierte en un toro multidimensional.
En el caso de una topología monodimensional (columna vertical o anillo de PEs) , cada PE dispone de 2 vecinos que se denominarán N y S (por Norte y Sur) . En el caso de una topología bidimensional (rejilla bidimensional o toro de PEs) , cada PE dispone de 4 vecinos que se denominarán N, S, E, W (por Norte, Sur, este, Oeste) . En el caso de una topología multidimensional (rejilla multidimensional o toro multidimensional de PEs) , cada PE dispone de 2n vecinos, si n es la dimensión del espacio.
En el resto de este documento, se considerará en primer lugar el caso de las topologías monodimensionales, y a continuación el caso de topologías bidimensionales, y después el caso de las topologías multidimensionales.
Una instrucción típica en un SIMD moderno requiere que todos los PEs (o algunos de los mismos) efectúen una operación, la misma para todos, sobre varios operandos y almacenar el resultado en uno o varios emplazamientos. Para retomar el ejemplo anterior, la instrucción R (23) = (R8) + R (3) * R (19) requiere que todos los PEs efectúen una operación sobre 3 operandos y almacenar el resultado en un emplazamiento.
En la mayoría de los SIMD, la instrucción define para cada operando y para cada resultado, la dirección donde los diferentes PEs van a leer el operando (o almacenar el resultado) . En consecuencia, para un operando dado, como para un emplazamiento de resultado dado, la dirección es necesariamente la misma para todos los PEs.
Tal enfoque plantea un problema, en particular en aplicaciones típicas de los SIMD como el procesamiento de imágenes, la compresión de imágenes, la generación sintética de imágenes, el procesamiento de la señal o algunas técnicas de resolución de ecuaciones en derivadas parciales. Por ejemplo, cuando estas aplicaciones utilizan algoritmos en los cuales un pixel es calculado a partir de sus vecinos, siendo la topología de los PE, bien mono, bi, tri o multidimensional.
Para ilustrar esta dificultad, se toma un ejemplo que aplica el procesamiento de imágenes y se analiza considerando un SIMD de 16 PEs organizado en anillo.
En todo el resto de este documento y para simplificar las fórmulas matemáticas, los procesadores son numerados a partir de 0; al igual que para las líneas y las columnas de una estructura de datos (señal, imagen o volumen) .
Una manera clásica de guardar los píxeles de la imagen en las memorias de los diferentes PEs es utilizar el PE0 (PE nº 0) para almacenar y procesar la línea 0 de la imagen, el PE1 (PE nº 1) para almacenar y procesar la línea 1 y así sucesivamente hasta PE15 (PE nº 15) para almacenar y procesar la línea 15. Como una imagen incluye en general más de 16 líneas, el usuario utilizará el PE0 para almacenar y procesar las líneas 0, 16, 32, 48, 64, 80, … de la imagen, el PE1 para almacenar y procesar las líneas 1, 17, 33, 49, 65, 81, .. de la imagen y así sucesivamente hasta el PE 15 para almacenar y procesar las líneas 15, 31, 47, 63, 79, 95, … de la imagen.
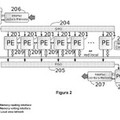
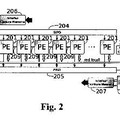
En esta disposición, si Np designa el número de PEs y si Lx designa el ancho de la imagen a procesar, un pixel de coordenadas (x, y) está dispuesto en el procesador p en la dirección Ad según las siguientes fórmulas:
p = y Mod Np
Ad = x + Lx * Int (y / Np) , (designando Int (z) la parte entera de z) .
Esta disposición está representada en la figura 2. Esta figura considera el caso de una imagen de ancho de 64 píxeles y muestra una manera habitual de disponerla en un SIMD de 16 PEs... [Seguir leyendo]
Reivindicaciones:
1. Procesador paralelo que comprende procesadores elementales (3) que comprenden cada uno al menos una unidad de cálculo y al menos una memoria que incluye palabras de memoria, y dispuestos según una topología, con una posición determinada en el seno de esta topología y capaces de ejecutar simultáneamente una misma instrucción sobre datos diferentes, incluyendo la instrucción la lectura de al menos un operando y/o incluyendo la escritura de al menos un resultado, caracterizado porque la instrucción define el conjunto de las lecturas y/o el conjunto de las escrituras de los procesadores elementales, cada uno en su propia memoria como una lectura y/o escritura en un campo de acción, siendo un campo de acción un conjunto de palabras de memoria a razón de una palabra de memoria por procesador elemental, estando esta palabra de memoria situada en la memoria del procesador elemental, siendo un campo de acción de un operando el conjunto de las palabras de memoria leídas por los procesadores elementales, cada uno en su propia memoria para adquirir este operando, siendo un campo de acción de un resultado el conjunto de las palabras de memoria escritas por los procesadores elementales, cada una en su propia memoria para almacenar este resultado, porque la instrucción comprende para cada operando y/o cada resultado, informaciones relativas a la posición de este campo de acción, porque la posición del campo de acción está definida como una posición en el seno de una estructura de datos única de tipo tabla de dimensión N, siendo N un número entero igual o superior a 1, porque esta tabla está repartida en las memorias de los diferentes procesadores elementales, porque el procesador paralelo comprende medios de cálculo de la dirección de cada operando y/o cada resultado en el seno de cada procesador elemental, en función de la posición del campo de acción y de la posición del procesador elemental en el seno de la topología.
2. Procesador paralelo según la reivindicación anterior, caracterizado porque comprende medios (50) de cálculo de la posición del campo de acción en función de dichas informaciones, vinculados a los medios de cálculo de la dirección.
3. Procesador paralelo según una de las reivindicaciones anteriores, caracterizado porque los medios (41, 42, 43) de cálculo de la dirección en el seno de cada procesador elemental están localizados al nivel de cada procesador elemental.
4. Procesador paralelo según la reivindicación anterior, caracterizado porque los medios (41, 42, 43) de cálculo de la dirección en el seno de cada procesador elemental están localizados al nivel de la unidad de cada procesador elemental.
5. Procesador paralelo según una de las reivindicaciones anteriores, caracterizado porque los medios de cálculo de la dirección en el seno de cada procesador elemental están localizados al nivel de cada procesador elemental y parcialmente agrupados entre varios procesadores elementales.
6. Procesador paralelo según una de las reivindicaciones anteriores tomada en combinación con la reivindicación 2, caracterizado porque los medios de cálculo de la posición del campo de acción son:
comunes a todos los procesadores elementales o localizados en totalidad o en parte al nivel de los medios de cálculo de la dirección de los datos.
7. Procesador paralelo según una de las reivindicaciones anteriores, caracterizado porque los procesadores elementales están dispuestos según una topología de P dimensiones, siendo P un número entero superior o igual a
1.
8. Procesador paralelo según una de las reivindicaciones anteriores, caracterizado porque los procesadores elementales están dispuestos según una topología de al menos una dimensión, para cada dimensión los medios de cálculo de la dirección del elemento de la estructura de datos que concierne un procesador elemental de abscisa p según dicha dimensión son obtenidos por combinación de un valor ligado a la posición del campo y de un valor ligado a la posición del procesador elemental.
9. Procesador paralelo según una de las reivindicaciones anteriores, caracterizado porque el campo de acción que presenta extremos definidos por sus coordenadas, la posición del campo de acción está definida por la posición de un baricentro obtenido por combinación lineal de estos extremos, siendo la suma de los pesos de los extremos igual a 1.
10. Procesador paralelo según una de las reivindicaciones anteriores, caracterizado porque el campo de acción que presenta extremos definidos por sus coordenadas, la posición del campo de acción está definida por la posición del extremo cuyas coordenadas son mínimas.
11. Procesador paralelo la reivindicación anterior, caracterizado porque los procesadores que están dispuestos según una topología de al menos una dimensión, para cada dimensión los medios de cálculo de la dirección del elemento de la estructura de datos que concierne un PE de abscisa p según dicha dimensión comprenden medios de cálculo de
siendo Np el número de procesadores elementales considerado en dicha dimensión, estando Wmin definido en dicha dimensión en función de las coordenadas de dicha posición.
12. Procesador paralelo según la reivindicación anterior, caracterizado porque los procesadores están dispuestos según una topología de una dimensión y la estructura de datos es monodimensional y porque la posición del campo de acción está definida por Xmin y Wmin=Xmin.
13. Procesador paralelo según la reivindicación anterior, caracterizado porque siendo Np una potencia de 2, los medios de cálculo de Ad incluyen medios para:
Sumar Xmin y (Np-1-p) .
Suprimir los LNp últimos bits del resultado, siendo LNp el logaritmo de base 2 de Np.
14. Procesador paralelo según la reivindicación 10, caracterizado porque los procesadores están dispuestos según una topología de una dimensión y la estructura de datos es bidimensional, definida en función de X e Y, siendo la dimensión de la estructura según X inferior a un valor predeterminado Lx y porque la posición del campo de acción está definida por Xmin, Ymin y Wmin=Xmin + Lx* Ymin.
15. Procesador paralelo según la reivindicación anterior, caracterizado porque siendo Np y Lx potencias de 2, los medios de cálculo de Ad, incluyen medios para:
Sumar Xmin y (Np-1-p) . Suprimir los LNp últimos bits del resultado, siendo LNp el logaritmo de base 2 de Np, Concatenar en peso débil la cantidad anterior representada en LLx – LNp bits y en peso fuerte Ymin siendo LLx el logaritmo de base 2 de Lx.
16. Procesador paralelo según la reivindicación 10, caracterizado porque los procesadores están dispuestos según una topología de una dimensión, y la estructura de datos es tridimensional, definida en función de X, Y y Z, siendo las dimensiones de la estructura según X e Y respectivamente inferiores a valores predeterminados Lx y Ly y porque la posición del campo de acción está definida por Xmin, Ymin, Zmin y Wmin=Xmin + Lx* (Ymin + Ly * Zmin) .
17. Procesador paralelo según la reivindicación anterior, caracterizado porque siendo Np, Lx y Ly potencias de 2, los medios de cálculo de Ad, incluyen medios para:
Sumar Xmin y (Np-1-p) . Suprimir los LNp últimos bits del resultado, siendo LNp el logaritmo de base 2 de Np, Concatenar en peso débil la cantidad anterior representada en LLx – LNp bits, en peso medio Ymin representado en Ly bits y en peso fuerte Zmin representado en Lz bits, siendo LLx el logaritmo de base 2 de Lx.
18. Procesador paralelo según la reivindicación 10, caracterizado porque los procesadores están dispuestos según una topología de una dimensión y la estructura de datos es de cuatro dimensiones, definida en función de X, Y, Z y T, siendo la dimensión de la estructura según X, Y y Z respectivamente inferiores a valores predeterminados Lx, Ly y Lz y porque la posición del campo de acción está definida por Xmin, Ymin, Zmin, Tmin y Wmin=Xmin + Lx * (Ymin + Ly * (Zmin + Lz * Tmin) ) .
19. Procesador paralelo según la reivindicación 10, caracterizado porque los procesadores están dispuestos según una topología de dos dimensiones y, comprende respectivamente Nx y Ny procesadores según una y otra dimensión, la estructura de datos bidimensional, definida en función de X et Y, siendo la dimensión de la estructura según X inferior a un valor predeterminado Lx y porque la posición del campo de acción está definida por Xmin, Ymin, y
la dirección Adx del elemento que concierne al PE nº px considerado según X en el seno del campo es obtenida por la fórmula:
y la dirección Ady del elemento que concierne al PE nº py considerado según Y en el seno del campo es obtenida por la fórmula:
20. Procesador paralelo según la reivindicación anterior, caracterizado porque siendo Nx, Ny, Lx y Ly potencias de 2, siendo LLx y LLy respectivamente el logaritmo de base 2 de Lx y Ly, los medios de cálculo de Ad incluyen medios para:
sumar Xmin y (Nx-1-px) . suprimir los LNx últimos bits del resultado, siendo LNx el logaritmo de base 2 de Nx, se obtiene Adx en LLx-LNx bits, sumar Ymin y (Ny-1-py) , suprimir los LNy últimos bits del resultado, siendo LNy el logaritmo de base 2 de Ny, se obtiene Ady en LLy-LNy bits, concatenar en peso débil Adx la cantidad anterior representada en LLx – LNx bits, y en peso fuerte LLy-LNy bits.
21. Procesador paralelo según la reivindicación 10, caracterizado porque los procesadores están dispuestos según una topología de al menos tres dimensiones, y comprende respectivamente Nx, Ny, Nz, … procesadores según cada dimensión, la estructura de datos está definida en al menos tres dimensiones en función de X, Y y Z, …, la dimensión de la estructura según cada una de las dimensiones siendo inferior a un valor predeterminado Lx, Ly, Lz, … y siendo Nx, Ny, Nz, …, Lx, Ly, Lz, …, potencias de 2, siendo LLx, LLy, LLz … los logaritmos de base 2 de Lx, Ly, Lz, … los medios de cálculo de Ad incluyen medios para:
concatenar en una palabra única de LLx + LLy + LLz + … bits las diferentes coordenadas del punto utilizado para definir la posición del campo; se obtiene w, permutar el orden de los bits de w; siendo w’ la palabra obtenida, recortar w’ en palabras de dimensión LLx, LLy, LLz, … bits; siendo wx’, wy’, wz’, … las palabras obtenidas, aplicar en cada una de las dimensiones:
i. añadir (Nx - 1 – px) a wx’,
ii. suprimir los LNx últimos bits del resultado; se obtiene Adx’,
iii. añadir (Ny - 1 – py) a wy’,
iv. suprimir los LNy últimos bits del resultado; se obtiene Ady’,
v. y así sucesivamente en cada dirección,
permutar de nuevo el orden de los bits Adx’, Ady’, Adz’, …; se obtienen entonces las direcciones de almacenamiento Adx, Ady, Adz en cada una de las direcciones, concatenar estas direcciones en una palabra única Ad que representa la dirección concernida por el campo en el seno de cada PE.
22. Procesador paralelo según una de las reivindicaciones anteriores, caracterizado porque el procesador paralelo es un ordenador de tipo SIMD.
Patentes similares o relacionadas:
Procesador digital de señales y dispositivo de comunicación de banda base, del 5 de Noviembre de 2018, de MediaTek Sweden AB: Una unidad de ejecución de vectores para su uso en un procesador digital de señales que tiene un núcleo de procesador, […]
Procesador digital de señales y método para direccionar una memoria en un procesador digital de señales, del 18 de Octubre de 2017, de MediaTek Sweden AB: Un procesador digital de señales que comprende al menos una unidad funcional, que puede ser una unidad de ejecución de vectores , o un acelerador, […]
Procesador de señal digital y dispositivo de comunicación de banda base, del 16 de Agosto de 2017, de MediaTek Sweden AB: Un procesador de señal digital que comprende: - un núcleo de procesador que incluye una unidad de ejecución de enteros […]
 Arquitectura híbrida SIMD/MIMD dinámicamente reconfigurable de un coprocesador para sistemas de visión, del 4 de Julio de 2013, de UNIVERSIDADE DE SANTIAGO DE COMPOSTELA: La presente invención se refiere a una arquitectura híbrida Simple Instrucción-Múltiples Datos (SIMD)/Múltiples Instrucciones-Múltiples Datos (MIMD), dinámicamente […]
Arquitectura híbrida SIMD/MIMD dinámicamente reconfigurable de un coprocesador para sistemas de visión, del 4 de Julio de 2013, de UNIVERSIDADE DE SANTIAGO DE COMPOSTELA: La presente invención se refiere a una arquitectura híbrida Simple Instrucción-Múltiples Datos (SIMD)/Múltiples Instrucciones-Múltiples Datos (MIMD), dinámicamente […]
 ARQUITECTURA HÍBRIDA SIMD/MIMD DINÁMICAMENTE RECONFIGURABLE DE UN COPROCESADOR PARA SISTEMAS DE VISIÓN, del 29 de Noviembre de 2012, de UNIVERSIDADE DE SANTIAGO DE COMPOSTELA: La presente invención se refiere a una arquitectura híbrida Simple Instrucción-Múltiples Datos (SIMD)/Múltiples Instrucciones-Múltiples Datos (MIMD), […]
ARQUITECTURA HÍBRIDA SIMD/MIMD DINÁMICAMENTE RECONFIGURABLE DE UN COPROCESADOR PARA SISTEMAS DE VISIÓN, del 29 de Noviembre de 2012, de UNIVERSIDADE DE SANTIAGO DE COMPOSTELA: La presente invención se refiere a una arquitectura híbrida Simple Instrucción-Múltiples Datos (SIMD)/Múltiples Instrucciones-Múltiples Datos (MIMD), […]
 SISTEMA DE PROCESAMIENTO DE DATOS Y DISPOSITIVO DE COMPUTACIÓN, del 12 de Marzo de 2012, de STARLAB BARCELONA SL: Sistema de procesamiento de datos y dispositivo de computación.
El sistema comprende:
- unos dispositivos de computación que procesan en paralelo […]
SISTEMA DE PROCESAMIENTO DE DATOS Y DISPOSITIVO DE COMPUTACIÓN, del 12 de Marzo de 2012, de STARLAB BARCELONA SL: Sistema de procesamiento de datos y dispositivo de computación.
El sistema comprende:
- unos dispositivos de computación que procesan en paralelo […]
REDES NEURONALES., del 1 de Enero de 2004, de BRITISH AEROSPACE: Dispositivo para tratar datos que representan una pluralidad de ejemplos, con lo que se determina una plantilla genérica que representa dichos ejemplos, donde dicho dispositivo […]
 APARATO Y METODO PARA PROCESAR DATOS ENCAUZADOS, del 27 de Mayo de 2010, de XELERATED AB: Método de procesamiento encauzado, que comprende una pluralidad de fases (9a-9e) de procesamiento encauzado, caracterizado por las etapas de:
recibir un […]
APARATO Y METODO PARA PROCESAR DATOS ENCAUZADOS, del 27 de Mayo de 2010, de XELERATED AB: Método de procesamiento encauzado, que comprende una pluralidad de fases (9a-9e) de procesamiento encauzado, caracterizado por las etapas de:
recibir un […]