NUEVO METODO PARA DETERMINAR LA REPRESENTATIVIDAD DE UN CORPUS.
Nuevo método para determinar la representatividad de un corpus.
La presente invención supone una solución eficaz para determinar a posteriori el tamaño mínimo de un corpus o colección textual, independientemente de la lengua o tipo textual de dicha colección, estableciendo, por tanto, el umbral mínimo de representatividad a través de un algoritmo (N-Cor) de análisis de la densidad léxica en función del aumento incremental del corpus. A partir de esta premisa se ha llegado a una propuesta de implementación en ordenador que se ha concretado en una aplicación desarrollada en Java, y que hemos denominado ReCor. Dicho sistema posee las siguientes clases principales: a) Palabras (algoritmo de cómputo, lectura y escritura a archivo); b) Gui (interfaz de usuario); y c) Ventana Gráfica (adaptador para la representación gráfica)
Tipo: Patente de Invención. Resumen de patente/invención. Número de Solicitud: P200603157.
Solicitante: UNIVERSIDAD DE MALAGA.
Nacionalidad solicitante: España.
Provincia: MALAGA.
Inventor/es: CORPAS PASTOR,GLORIA, SEGHIRI DOMINGUEZ,MIRIAM, MAGGI,ROMANO.
Fecha de Solicitud: 5 de Diciembre de 2006.
Fecha de Publicación: .
Fecha de Concesión: 21 de Enero de 2010.
Clasificación Internacional de Patentes:
- G06F17/27A4
Clasificación PCT:
- G06F17/27
Fragmento de la descripción:
Nuevo método para determinar la representatividad de un corpus.
Sector de la técnica
La presente invención se refiere a un método de procesamiento de datos implementado en ordenador, particularmente datos e información lingüística.
Estado de la técnica La cuestión de la representatividad sigue siendo hoy día uno de los aspectos más controvertidos de la lingüística del corpus. En el caso de los corpus especializados, los cuales suelen tener un tamaño mucho más reducido que los denominados "corpus generales" o "de referencia", la cuestión de la representatividad es realmente clave, es más, es una de sus características definitorias.
Dejando a un lado que la representatividad de un corpus depende, en primer lugar, de haber aplicado los criterios de diseño externos e internos adecuados, en la práctica la cuantificación del tamaño mínimo que debe tener un corpus especializado aún no se ha abordado de forma objetiva. Y es que no hay consenso sobre cuál sea el número mínimo de documentos o palabras que debe tener un determinado corpus para que sea considerado válido y representativo de la población que se desea representar. Las cifras varían de forma espectacular de unos autores a otros. Así, si para Biber (1995. Dimensions of Register Variation: A cross-linguistic comparison. Cambridge University Press), 1000 palabras y 10 documentos son suficientes para asegurar la representatividad de un corpus especializado; según Friedblicher y Friedblicher (2000. The Argument for Using English Specialized Corpora to Understand Academic and Professional Language. Discourse in the Professions: Perspectives From Corpus Linguistics. John Benjamins), el tamaño oscila entre 500.000 y 5.000.000 palabras; mientras que McEnery y Wilson (2006 [2000]. ICT4LT Module 3.4. Corpus Linguistics. <http://www.ict4lt.org/en/en_mod3-4.htm> [09/11/2006]) sitúan el límite en 1.000.000 palabras. Pero todas estas cifras no resuelven el problema de calcular la representatividad de un corpus, dado que son cifras establecidas a priori, carentes de fundamento objetivo, medible y cuantificable.
Descripción detallada de la invención
La presente invención supone una solución eficaz para determinar a posteriori el tamaño mínimo de un corpus o colección textual, independientemente de la lengua o tipo textual de dicha colección, estableciendo, por tanto, el umbral mínimo de representatividad a través de un algoritmo (N-Cor) de análisis de la densidad léxica en función del aumento incremental del corpus.
A partir de esta premisa se ha llegado a una propuesta de implementación en ordenador que se ha concretado en una aplicación desarrollada en Java, y que hemos denominado ReCor. Dicho sistema posee las siguientes clases principales: a) Palabras (algoritmo de cómputo, lectura y escritura a archivo); b) Gui (interfaz de usuario); y c) VentanaGrafica (adaptador para la representación gráfica).
Descripción de los dibujos
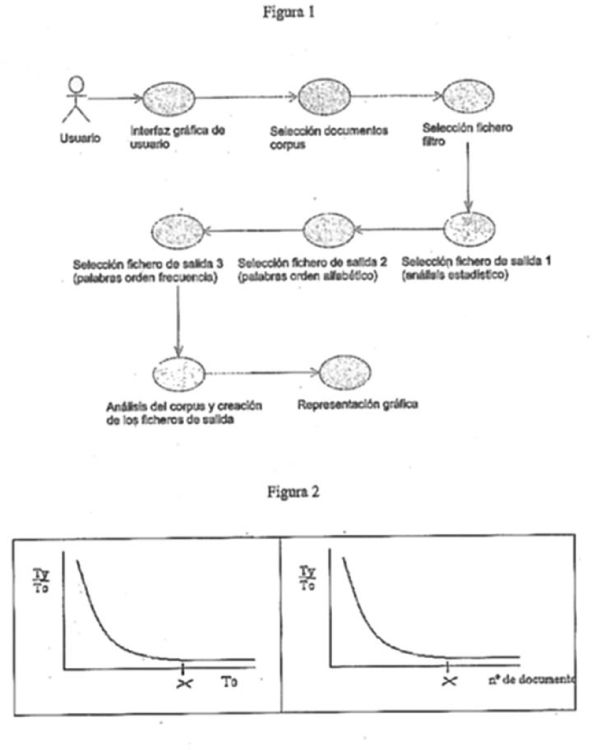
Figura 1: Ciclo de vida del uso del sistema
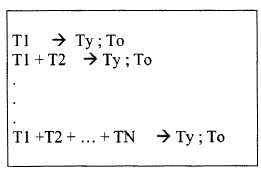
Figura 2: Ejemplificación de representaciones gráficas A y B
Figura 3: Implementación de la ventana gráfica
Figura 4: Clase OrdenFrecuencia definida en método compareTo de la interfaz Comparable
Figura 5: Clase Gui para la creación del interfaz gráfico de usuario
Figura 6: Clase Palabra para el análisis del corpus
Figura 7: Clase Controlador que especifica la acción asociada a cada evento
Figura 8: Clase ruta con método main.
Modos de realización de la invención
Algoritmo N-Cor
Como se expone más arriba, el presente método calcula el tamaño mínimo de un corpus mediante el análisis de la densidad léxica (d) en relación a los aumentos incrementales del corpus (C) documento a documento, según muestra la siguiente ecuación:

Para ello, se analizan gradualmente todos los archivos que componen el corpus, extrayendo información sobre la frecuencia de las palabras tipo (types) y las ocurrencias o palabras distintas (tokens) de cada archivo del corpus. En esta operación se utilizan dos criterios de selección de archivos, a saber, por orden alfabético y de forma aleatoria,
donde:
Ty: Se refiere a los types, es decir el número de palabras distintas hasta ese momento.
To: Muestra los tokens, es decir el número de palabras en total hasta ese momento.
N: Número de documentos que componen el corpus.
El ciclo de vida del uso del sistema puede ser el siguiente (Figura 1): Cada archivo que integra el corpus debe estar identificado de forma unívoca mediante un nombre en código alfanumérico (por ejemplo, A001, A002, A003 ... A00n). El algoritmo opera primero por orden alfabético y, a continuación, de forma aleatoria, a fin de garantizar que el orden en el que son seleccionados los archivos no afecte al resultado. Cuando se seleccionan los documentos por orden alfabético, el algoritmo analiza el primer archivo (por ejemplo, A001) y para éste se calculan los tokens (To) y los types (Ty), y la densidad léxica correspondiente. Con ello ya se obtiene un punto en la representación gráfica que se pretende extraer. A continuación, siguiendo el mismo criterio de selección que en el primero, se toma el siguiente documento del corpus (por ejemplo, A002) y se calculan de nuevo los To y Ty para éste, pero sumando los resultados a los Ty y To de la iteración anterior (en este caso a los del primer documento analizado), se calcula la densidad léxica y con esto se obtiene un segundo punto para la representación gráfica. Se sigue este algoritmo hasta que se hayan tratado todos los documentos que componen el corpus que se estudia, que en la presente ejemplificación sería el A00n. La segunda fase del análisis toma los documentos en orden aleatorio, por ejemplo el A003 primero, luego el A00n, y así hasta haber analizado todos los documentos del corpus.
Éste es el mismo algoritmo para el análisis de n-gramas, esto es, la opción de realizar un análisis de la frecuencia de aparición de secuencias de palabras (1-grama, 2-grama, ..., n-grama). La aplicación ofrece la posibilidad de hacer el cómputo de estas secuencias considerando un rango de longitudes de secuencia (números de palabras) definido por el usuario. Al igual que se realiza con palabras independientes (tokens), se muestra un gráfico con la información de representatividad del corpus tanto para un orden aleatorio de los ficheros como para un orden alfabético por el nombre de éstos. En el eje horizontal se mantiene el número de ficheros consultados, y en el eje vertical el cociente (número de n-gramas distintos) / (número de n-gramas totales). A estos efectos, un n-grama es considerado como un token. Así mismo, los ficheros de salida generados indican los n-gramas.
Tanto en el análisis por orden alfabético como en el aleatorio llega un momento en el que un determinado documento no aporta apenas types al corpus, lo cual indica que se ha llegado a un tamaño adecuado, es decir, que el corpus analizado ya se puede considerar una muestra representativa de la población en términos estadísticos. En una representación gráfica estaríamos en el punto en el que las líneas de types y tokens se estabilizan y se aproximan al cero (Figura 2).
Si el corpus es realmente representativo la gráfica tiende a descender exponencialmente porque los tokens (To) crecen en cada iteración mucho más que los types (Ty), debido a que, en teoría, cada vez van apareciendo menos palabras nuevas que no están almacenadas en las estructuras de datos que utiliza el programa. Así pues, podremos afirmar que el corpus es representativo cuando la gráfica es constante en valores cercanos a cero, pues, en la práctica, es imposible alcanzar la incorporación de cero types en el corpus ya que los documentos siempre van a contener variables del tipo números, nombres propios, etc.
Si un corpus produce esta representación gráfica podemos afirmar que es representativo y que nos basta con X archivos (los que correspondan al punto del eje horizontal donde la gráfica se estabiliza en torno a cero). De este modo habremos identificado el tamaño mínimo de la colección, a partir del cual...
Reivindicaciones:
1. Método implementado en ordenador de determinación de la representatividad de un corpus mediante la ejecución de un programa caracterizado porque:
2. Método implementado en ordenador de determinación de la representatividad de un corpus mediante la ejecución de un programa según la reivindicación anterior caracterizado porque en base a dicho algoritmo N-Cor es posible realizar un análisis de la frecuencia de aparición de secuencias de palabras, pudiéndose hacerse el cómputo de dichas secuencias considerando un rango de longitudes definido por el usuario.
3. Método implementado en ordenador de determinación de la representatividad de un corpus mediante la ejecución de un programa según cualquiera de las reivindicaciones anteriores caracterizado porque dicha aplicación informática (ReCor) ha sido desarrollada en Java 2 SDK Standard Edition usando la librería Java ara gráficas y diagramas JFreeChart; y empleando el entorno JCreator Pro como editor y compilador de Java.
4. Método implementado en ordenador de determinación de la representatividad de un corpus mediante la ejecución de un programa según la reivindicación anterior caracterizado porque comprende las siguientes clases:
5. Aparato electrónico programado para determinar la representatividad de un corpus según cualquiera de las reivindicaciones anteriores caracterizado porque permite establecer el umbral mínimo de representatividad a través del algoritmo N-Cor mediante la ejecución de la aplicación informática ReCor.
Patentes similares o relacionadas:
Representación de información de documentos, del 25 de Diciembre de 2019, de Financial & Risk Organisation Limited: Un sistema para extracción automática de datos no estructurados introduce un formato de datos estructurado que comprende: un servidor que incluye […]
MÉTODO DE ANÁLISIS DE SENTIMIENTO EN UN TEXTO BASADO EN MODELO LÉXICON, del 27 de Junio de 2019, de ZARAGOZA SICRE, Sergio Jesús: El general de un lexicón que se presenta para el análisis de sentimientos que permite integrar técnicas de aprendizaje automático al análisis basado en lexicones, […]
Procedimiento, sistema y producto de programa informático para proporcionar una descripción de un programa a un equipo de usuario, del 18 de Enero de 2019, de TV Control Ltd: Un procedimiento para proporcionar una descripción de un programa a un equipo de usuario, que comprende: - mantener, para un usuario y/o un equipo […]
METODO Y SISTEMA PARA COMUNICACION ENTRE DISPOSITIVOS A TRAVES DE LENGUAJE NATURAL USANDO APLICACIONES DE MENSAJERIA INSTANTANEA E IDENTIFICADORES PUBLICOS INTEROPERABLES, del 16 de Agosto de 2018, de GONZALO VACA, Antonio: Sistema y un método para comunicación entre dispositivos a través de lenguaje natural usando aplicaciones de mensajería instantánea e identificadores públicos interoperables […]
MODELO LÉXICO PARA EL ANÁLISIS DE SENTIMIENTOS EN UN TEXTO, del 21 de Junio de 2018, de ZARAGOZA SICRE, Sergio Jesús: El general de un lexicón que se presenta para el análisis de sentimientos que permite integrar técnicas de aprendizaje automático al análisis basado en lexicones, el modelo […]
Dispositivo contador, programa de conteo, medio de memoria y procedimiento de conteo, del 20 de Septiembre de 2017, de RAKUTEN, INC: Dispositivo contador, que comprende: una parte de entrada para introducir una primera oración y una segunda oración; una parte de […]
Dispositivo de registro de palabras relacionadas, dispositivo de procesamiento de información, método de registro de palabras relacionadas, programa para dispositivo de registro de palabras relacionadas, y medio de almacenamiento, del 30 de Agosto de 2017, de RAKUTEN, INC: Un dispositivo de registro de palabras relacionadas que comprende: un medio de recepción configurado para recibir una consulta de búsqueda […]
Un método para la extracción de patrones de relación a partir de artículos, del 7 de Junio de 2017, de THE EUROPEAN UNION, REPRESENTED BY THE EUROPEAN COMMISSION: Un método para formar relaciones de implicación; comprendiendo proporcionar un dispositivo informático y a) proporcionar a dicho dispositivo informático […]