METODO Y SISTEMA DE MODELADO DE MEMORIA CACHE.
Un método de modelado de una memoria cache de datos de un procesador destino,
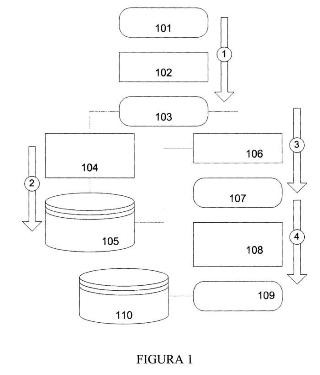
para simular el comportamiento de dicha memoria cache de datos en la ejecución de un código software en una plataforma que comprenda dicho procesador destino, donde dicha simulación se realiza en una plataforma nativa que tiene un procesador diferente del procesador destino que comprende dicha memoria cache de datos que se va a modelar, donde dicho modelado se realiza mediante la ejecución en dicha plataforma nativa de un código software que se basa en dicho código software a ejecutar en dicha plataforma destino, extendido con información para modelar dicho comportamiento de dicha memoria cache de datos del procesador destino, donde el método comprende las etapas de: analizar (102) el código software a ejecutar en la plataforma destino (101) para identificar unos bloques básicos (104) de dicho código y una pluralidad de variables accedidas en cada bloque; añadir (106) a dicho código anotaciones relativas a la memoria cache de datos a simular, donde dichas anotaciones comprenden información para modelar el efecto de dicha memoria en el procesador destino, obteniéndose un código anotado (107); compilar (108) dicho código anotado; ejecutar (109) dicho código anotado compilado junto con un modelo hardware de dicha memoria cache de datos. La etapa de añadir (106) a dicho código anotaciones relativas a la memoria cache de datos a simular comprende añadir información que permite obtener las direcciones de las variables que dicha memoria cache de datos simulada debe acceder, para así estimar si cada acceso a dichas variables resulta en un acierto o en un fallo de memoria cache de datos.
Tipo: Patente de Invención. Resumen de patente/invención. Número de Solicitud: P201001284.
Solicitante: UNIVERSIDAD DE CANTABRIA.
Nacionalidad solicitante: España.
Inventor/es: POSADAS COBO,Héctor, DIAZ SUAREZ,Luis, VILLAR BONET,EUGENIO.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G06F11/34 FISICA. › G06 CALCULO; CONTEO. › G06F PROCESAMIENTO ELECTRICO DE DATOS DIGITALES (sistemas de computadores basados en modelos de cálculo específicos G06N). › G06F 11/00 Detección de errores; Corrección de errores; Monitorización (detección, corrección o monitorización de errores en el almacenamiento de información basado en el movimiento relativo entre el soporte de registro y el transductor G11B 20/18; monitorización, es decir, supervisión del progreso del registro o reproducción G11B 27/36; en memorias estáticas G11C 29/00). › Registro o evaluación estática de la actividad del computador, p. ej. de las interrupciones o de las operaciones de entrada-salida.
- G06F12/10 G06F […] › G06F 12/00 Acceso, direccionamiento o asignación en sistemas o arquitecturas de memoria (entrada digital a partir de, o salida digital hacia soportes de registro, p. ej. hacia unidades de almacenamiento de disco G06F 3/06). › Traducción de direcciones.
- G06F9/455 G06F […] › G06F 9/00 Disposiciones para el control por programa, p. ej. unidades de control (control por programa para dispositivos periféricos G06F 13/10). › Emulación; Interpretación; Simulación delsoftware, p. ej. virtualización o emulación de motores de ejecución de aplicaciones o sistemas operativos.
Fragmento de la descripción:
Método y sistema de modelado de memoria cache.
Campo de la invención
La presente invención pertenece a los campos de la electrónica y la informática. Más concretamente, la invención pertenece a las áreas de diseño de procesadores y sistemas que contienen elementos procesadores, incluyendo tanto desarrollo de programas (software, SW) como de la plataforma física sobre la que se ejecuta el código (hardware, HW). La invención es especialmente relevante en aquellos ámbitos donde el tiempo de ejecución y/o el consumo son importantes.
Antecedentes de la invención
Un micro-procesador en un componente electrónico diseñado para ejecutar código. En general un procesador está diseñado de tal forma que el número de instrucciones ejecutadas sea similar a su frecuencia. Por ejemplo, un procesador a 2 Gigahertzios ejecuta en torno a dos mil millones de instrucciones por segundo. Sin embargo, para poder ejecutar, el procesador necesita saber qué tiene que hacer (instrucciones) y con qué valores ha de operar (datos).
Esta información (instrucciones y datos) se guarda en una memoria, de tal forma que el procesador ha de acceder a esa memoria para obtener cada instrucción y los datos asociados, y guardar el resultado de la ejecución. Dado que el acceso a las memorias es, por lo general, mucho más lento que la velocidad de ejecución del procesador, el procesador ha de estar la mayor parte del tiempo parado esperando a las memorias, por lo que la velocidad del sistema se reduce enormemente. Además, el acceso a las memorias incrementa el consumo y entorpece el funcionamiento de otros elementos del sistema que utilicen las memorias y/o los canales de comunicación del sistema, al no permitir estos elementos la realización de accesos simultáneos.
Para evitar estas ineficiencias, la solución convencional es colocar una o varias memorias junto al procesador. Estas memorias son mucho más pequeñas y más rápidas que la memoria principal. Los datos e instrucciones se mantienen en dichas memorias durante su uso, reduciendo drásticamente el número de accesos a la memoria principal, y acelerando el sistema. Estas memorias se llaman habitualmente memorias cache o caches.
El funcionamiento es el siguiente: cada vez que el procesador requiere información (instrucción o dato), realiza una petición al exterior: envía la dirección de memoria donde está la instrucción o el dato y si hay que leer o escribir. Si hay cache, esta está conectada al procesador, recibe la petición y comprueba si tiene la información. En caso afirmativo responde al procesador. Si no, realiza una petición a la memoria principal, espera a que responda y a su vez responde al procesador.
El desarrollo de estos sistemas, tanto parte de la plataforma física, como el software, se realiza utilizando inicialmente simulaciones para poder crear finalmente el sistema real con el menor coste posible. Para realizar estas simulaciones, es necesario que el ordenador donde se realizan las simulaciones contenga una infraestructura que modele el comportamiento esperado del sistema real. Esto implica estimar cuál será el comportamiento del sistema real, e introducir esta información en la simulación.
Dado el enorme impacto de las caches en el rendimiento del sistema, es fundamental tenerlas en cuenta a la hora de tratar de mejorar la eficiencia del procesador y del sistema en general. En consecuencia, los efectos de las caches se han tenido en cuenta en una amplia variedad de intentos de estimar el rendimiento del sistema, como por ejemplo por M. Lajolo y otros, en "Fast instruction cache simulation strategies in a HW/SW co-design environment", ASP-DAC 1999. Así, cualquier técnica de estimación (predicción) del tiempo o consumo requerido para ejecutar un programa en un sistema ha de modelar el funcionamiento de las memorias caches. Dicho modelado se basa en comprobar para cada instrucción o dato requerido por el procesador, si el dato está en la cache correspondiente (llamado acierto, en inglés, "hit") o si hay que ir a la memoria principal a por el dato (fallo de cache, en inglés, "miss").
Las técnicas más comunes para realizar estas operaciones se basan en ejecutar el código SW añadiendo el modelado de las caches. En nuestro ámbito, esto se traduce en añadir un sistema de modelado de caches que se integre en la simulación del código SW y pueda conectarse con un modelo de la plataforma HW.
En general se distinguen dos tipos de técnicas de modelado y estimación de caches: estáticas o dinámicas (basadas en simulación).
Las técnicas estáticas se basan en realizar análisis matemáticos que predigan el funcionamiento de las caches. Las caches almacenan valores en sus líneas internas dependiendo de las direcciones de memoria. En consecuencia, el modelado de caches estático requiere normalmente como entrada las trazas de acceso a memoria. Las trazas de acceso a memoria se obtienen usando modelos ISS (del inglés "Instruction Set Simulator", ISS), lo cual hace que estas técnicas sean muy lentas. Por ejemplo, E.S. Sorenson y otros, en "Cache Characterization Surfaces and Predicting Workload Miss Rates", In proc. of the Workload characterization, 2001, WWC-4. 2001 IEEE International Workshop, emplean las trazas de acceso a memoria para construir una superficie de pérdida (miss surface) analizando la localidad del acceso.
Estos análisis suelen ser bastante pesimistas y proporcionan resultados generales. En consecuencia, presentan limitaciones en la precisión del modelado de programas concretos y en el modelado del efecto en el resto de la plataforma HW. Estas técnicas están diseñadas para modelar la probabilidad de fallos media, pero no generan información que permita predecir en qué momento ocurrirá cada fallo de cache, con lo que no se pueden modelar dichos fallos en la simulación. Es decir, la aplicación de modelados estáticos o híbridos no es la solución más adecuada para modelado de caches en co-simulación nativa. La co-simulación nativa se ejecuta en un computador anfitrión o computador host (del inglés, host computer), por lo que no es posible obtener una traza válida de acceso a memoria para modelar la ejecución de un software en la plataforma destino (del inglés, target platform). Además, los modelos de cache deben enviar dinámicamente transferencias de datos al modelo de bus cuando ocurren fallos (del inglés, miss).
Las técnicas dinámicas se asocian habitualmente a simuladores de procesadores, denominados simuladores de conjunto de instrucciones (del inglés Instruction Set Simulator, ISS). Estos simuladores contienen descripciones del funcionamiento interno del procesador y reciben las mismas entradas y salidas que el procesador real. Un ISS recibe el código SW compilado para el procesador a modelar y los datos en su formato, que son habitualmente distintos a los utilizados por el computador donde se realiza la simulación. Cada acceso a memoria realizado por el modelo de procesador se gestiona por el correspondiente modelo de cache. En este contexto, se han usado ampliamente soluciones, como DineroIV (
A partir de estos simuladores, el modelado de caches se realiza analizando la información que pide el ISS mediante un modelo de cache con la información de su funcionamiento interno. Dado que el ISS pide exactamente lo que pediría el real (las direcciones de memoria y si es lectura o escritura), se emula directamente el comportamiento real del sistema. Esta técnica de modelado (tanto del procesador como de las caches) basada en el modelado de lo que el sistema realiza en cada ciclo de reloj es precisa, pero bastante lenta. Las soluciones basadas en ISS no son adecuadas para estimaciones de rendimiento tempranas, ya que la ejecución de ISS requiere mucho tiempo, y esto es una gran limitación cuando se requiere un gran número de simulaciones de sistemas complejos, como ocurre en los primeros pasos del desarrollo de sistemas complejos.
Para obtener estimaciones más rápidas se han desarrollado técnicas que evitan la ejecución con un ISS. Se ha comprobado que la co-simulación basada en ejecución nativa del software es una técnica más efectiva. El código se ejecuta directamente en el computador de la simulación. Para simular retrasos y consumos se añade información adicional en el código, se compila y se ejecuta. Esto permite obtener simulaciones muy rápidas (mil veces o más que un ISS) con un error un poco mayor, de en torno al 5-10%, para sistemas sin caches.
Por...
Reivindicaciones:
1. Un método de modelado de una memoria cache de datos de un procesador, para simular el comportamiento de dicha memoria cache de datos en la ejecución de un código software en una plataforma destino que comprenda dicho procesador, donde dicha simulación se realiza en una plataforma nativa que tiene un procesador diferente del procesador que comprende dicha memoria cache de datos a modelar, donde dicho modelado se realiza mediante la ejecución en dicha plataforma nativa de un código software que se basa en dicho código software a ejecutar en dicha plataforma destino, extendido con información para modelar dicho comportamiento de dicha memoria cache de datos del procesador de la plataforma destino, donde el método comprende las etapas de:
- analizar (102) el código software a ejecutar en la plataforma destino (101) para identificar unos bloques básicos (104) de dicho código y una pluralidad de variables accedidas en cada bloque;
- añadir (106) a dicho código anotaciones relativas a la memoria cache de datos a simular, donde dichas anotaciones comprenden información para modelar el efecto de dicha memoria en el procesador destino, obteniéndose un código anotado (107);
- compilar (108) dicho código anotado;
- ejecutar (109) dicho código anotado compilado junto con un modelo hardware de dicha memoria cache de datos;
estando el método caracterizado por que para chequear si cada una de dicha pluralidad de variables accedidas en cada bloque (104) se encuentra en dicha memoria cache de datos o no, se accede a la información de la memoria cache de datos utilizando la dirección asociada a dicha variable mediante la llamada a una función de dicho modelo hardware de la memoria cache de datos.
2. El método de la reivindicación 1, donde a dichos bloques básicos (104) se les añade información del rendimiento, en términos de instrucciones ensamblador, de cada bloque básico.
3. El método de cualquiera de las reivindicaciones anteriores, donde dicha información añadida al código que permite obtener las direcciones de las variables que dicha memoria cache de datos simulada debe acceder comprende un identificador único para cada variable para comprobar cada vez si ésta se encuentra almacenada en la memoria cache de datos o no.
4. El método de cualquiera de las reivindicaciones anteriores, donde dicha información añadida comprende la dirección de cada variable a chequear en la plataforma en la que se realiza la simulación o plataforma nativa, para analizar la localidad espacial de dichas variables.
5. El método de la reivindicación 4, donde, para obtener la dirección de cada variable a chequear, se utiliza un operador de indirección seguido del nombre de la variable.
6. El método de la reivindicación 5, donde, en caso de acceso a una variable simple, se realiza un único chequeo de la memoria cache de datos.
7. El método de la reivindicación 5, donde, en caso de acceso a un puntero, a un array o a un miembro de una estructura o de una clase, se realiza un acceso adicional por cada nivel de indirección.
8. El método de cualquiera de las reivindicaciones anteriores, donde, si el procesador destino al que pertenece la memoria cache de datos a simular tiene un ancho de palabra diferente del ancho de palabra del procesador de la plataforma sobre la que se simula dicha memoria cache de datos o plataforma nativa, durante la etapa de compilación (108) se modifican los tipos de los datos del procesador destino para que se ajusten a tipos de tamaño equivalentes del procesador de la plataforma nativa.
9. El método de cualquiera de las reivindicaciones anteriores, donde, para reducir el número de chequeos, se analiza la localidad de los accesos en el código.
10. El método de cualquiera de las reivindicaciones 1-8, donde, para reducir el número de chequeos, y dado que en la memoria cache de datos las variables se agrupan por líneas, se chequea solamente si la línea está en memoria cache de datos, identificándose la línea con la dirección de la variable.
11. El método de cualquiera de las reivindicaciones 1-8, donde, para reducir el número de chequeos, si al menos dos variables se han declarado consecutivamente, es suficiente con comprobar el acceso a la primera de dichas variables.
12. El método de cualquiera de las reivindicaciones anteriores, donde se traslada el proceso de búsqueda de la dirección en la memoria cache de datos, desde el modelo de memoria cache de datos a la anotación de código (106), y donde dicho modelo hardware de memoria cache de datos (110) es un modelo basado en arrays de memoria, asignándose una zona de memoria en la que en cada bit se indica si una línea de memoria está en memoria cache o no, siendo así suficiente chequear el bit correspondiente a la línea para saber si está en cache o no.
13. Un sistema que comprende medios adaptados para llevar a cabo el método de cualquiera de las reivindicaciones anteriores.
14. Un programa informático que comprende medios de código de programa informático adaptados para realizar las etapas del método según cualquiera de las reivindicaciones de la 1 a la 12, cuando dicho programa se ejecuta en un ordenador, un procesador de señal digital, una disposición de puertas de campo programable, un circuito integrado de aplicación específica, un microprocesador, un microcontrolador, y cualquier otra forma de hardware programable.
Patentes similares o relacionadas:
Procedimiento de gestión de módulos de software integrados para una computadora electrónica de un dispositivo de conmutación eléctrica, del 17 de Junio de 2020, de SCHNEIDER ELECTRIC INDUSTRIES SAS: Procedimiento de gestión de módulos de software integrados para una computadora electrónica integrada de un dispositivo eléctrico de conmutación de […]
Restauración de aceleración de servicio, del 10 de Junio de 2020, de Microsoft Technology Licensing, LLC: Un método para restaurar la aceleración del servicio para un servicio, el método que comprende: determinar que la aceleración del servicio para el […]
Aparato, sistema y método para procesar datos de registro de aplicaciones, del 3 de Junio de 2020, de LSIS Co., Ltd: Un sistema de procesamiento de datos de registro que comprende: un dispositivo de control de supervisión que se configura para ejecutar una aplicación y generar […]
Método y dispositivo para procesar información de llamadas de servicio, del 20 de Mayo de 2020, de Advanced New Technologies Co., Ltd: Un método para procesar una cadena de llamadas de servicio, el método que comprende: adquirir una o más cadenas de llamadas de servicio […]
Un método y sistema para modelado de tareas de aplicaciones de teléfono móvil, del 1 de Enero de 2020, de DEUTSCHE TELEKOM AG: Un sistema para determinar el uso y ayudar en la operación de aplicaciones secuenciales interactivas que se ejecutan en uno o más dispositivos móviles, que comprende: […]
Procedimiento de supervisión del rendimiento de una aplicación de software, del 13 de Noviembre de 2019, de Actual Experience PLC: Procedimiento de supervisión del nivel de rendimiento de una aplicación de software que se ejecuta en un dispositivo informático conectado a una red de ordenadores y […]
 Control de utilización de red, del 30 de Octubre de 2019, de Microsoft Technology Licensing, LLC: Un procedimiento de especificación y asignación de ancho de banda de red para aplicaciones distribuidas que se ejecutan en una red en máquinas (114; […]
Control de utilización de red, del 30 de Octubre de 2019, de Microsoft Technology Licensing, LLC: Un procedimiento de especificación y asignación de ancho de banda de red para aplicaciones distribuidas que se ejecutan en una red en máquinas (114; […]
Notificación de instrumentación en tiempo de ejecución, del 21 de Agosto de 2019, de INTERNATIONAL BUSINESS MACHINES CORPORATION: Un procedimiento implementado por ordenador para la notificación de instrumentación en tiempo de ejecución, el procedimiento que comprende: ejecutar […]