Biblioteca de oligonucleótidos que codifican péptidos aleatorizados.
Procedimiento de producción de una biblioteca de oligonucleótidos que comprende diversos oligonucleótidos,
teniendo cada oligonucleótido en la biblioteca al menos dos posiciones predeterminadas, un codón de aleatorización seleccionado entre un grupo definido de codones, codificando los codones dentro de dicho grupo definido diferentes aminoácidos y comprendiendo dicho procedimiento las etapas de:
(a) Proporcionar uno o más oligonucleótidos iniciadores de cadena doble, en el que los oligonucleótidos iniciadores tienen uno o más extremos romos;
(b) Proporcionar diversos oligonucleótidos de aleatorización de cadena doble diferentes que comprenden:
(i) una cadena codificadora, comprendiendo la cadena codificadora un codón de aleatorización; y
(ii) una cadena no codificadora sustancialmente complementaria, donde cada oligonucleótido de aleatorización de cadena doble comprende una secuencia de nucleótidos que codifica para un sitio de reconocimiento de endonucleasa de restricción capaz de ser reconocido por una endonucleasa de restricción, la endonucleasa de restricción capaz de escindir el sitio de reconocimiento de endonucleasa secuencia arriba o secuencia abajo del oligonucleótido de aleatorización en un sitio de escisión predeterminado para crear un corte de extremos romos y en el que la endonucleasa escinde el oligonucleótido de aleatorización adyacente al codón de aleatorización proporcionado por el oligonucleótido de aleatorización.
(c) Ligar cada oligonucleótido iniciador de cadena doble a un oligonucleótido de aleatorización de cadena doble para formar oligonucleótidos ligados;
(d) Amplificar los oligonucleótidos ligados;
(e) Digerir el oligonucleótido ligado con la endonucleasa de restricción para formar diversos oligonucleótidos aleatorizados de doble cadena, comprendiendo cada uno de ellos en un extremo un codón de aleatorización; y
(f) Usar los oligonucleótidos iniciadores aleatorizados de cadena doble y repetir las etapas (a) a (e) del procedimiento para producir diversos oligonucleótidos aleatorizados de cadena doble comprendiendo cada uno un codón de aleatorización adicional; en el que la etapa (f) se sigue una vez, u opcionalmente más veces, para producir una biblioteca de oligonucleótidos que comprende diversos oligonucleótidos, teniendo cada oligonucleótido en la biblioteca al menso dos codones aleatorizados contiguos.
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/GB2006/002672.
Solicitante: ASTON UNIVERSITY.
Nacionalidad solicitante: Reino Unido.
Dirección: ASTON TRIANGLE BIRMINGHAM B4 7ET REINO UNIDO.
Inventor/es: ASHRAF,Mohammed, HUGHES,Marcus Daniel, HINE,Anna Victoria.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- C12N15/66 QUIMICA; METALURGIA. › C12 BIOQUIMICA; CERVEZA; BEBIDAS ALCOHOLICAS; VINO; VINAGRE; MICROBIOLOGIA; ENZIMOLOGIA; TECNICAS DE MUTACION O DE GENETICA. › C12N MICROORGANISMOS O ENZIMAS; COMPOSICIONES QUE LOS CONTIENEN; PROPAGACION, CULTIVO O CONSERVACION DE MICROORGANISMOS; TECNICAS DE MUTACION O DE INGENIERIA GENETICA; MEDIOS DE CULTIVO (medios para ensayos microbiológicos C12Q 1/00). › C12N 15/00 Técnicas de mutación o de ingeniería genética; ADN o ARN relacionado con la ingeniería genética, vectores, p. ej. plásmidos, o su aislamiento, su preparación o su purificación; Utilización de huéspedes para ello (mutantes o microorganismos modificados por ingeniería genética C12N 1/00, C12N 5/00, C12N 7/00; nuevas plantas en sí A01H; reproducción de plantas por técnicas de cultivo de tejidos A01H 4/00; nuevas razas animales en sí A01K 67/00; utilización de preparaciones medicinales que contienen material genético que es introducido en células del cuerpo humano para tratar enfermedades genéticas, terapia génica A61K 48/00; péptidos en general C07K). › Métodos generales para insertar un gen en un vector para formar un vector recombinante, utilizando la escisión y la unión; Utilización de "linkers" no funcionales o de adaptadores, p. ej. "linkers" que contienen la secuencia para una endonucleasa de restricción.
PDF original: ES-2378561_T3.pdf
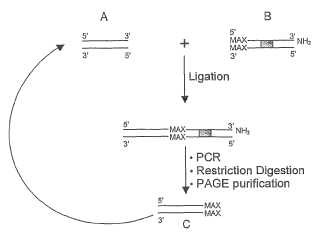
Fragmento de la descripción:
Biblioteca de oligonucleótidos que codifican péptidos aleatorizados La invención se refiere a la producción de bibliotecas de oligonucleótidos que codifican péptidos aleatorizados, a vectores y células huésped que contienen dichas bibliotecas y a kits para la producción de dichas bibliotecas.
Las técnicas combinatoriales para la producción de péptidos han estados disponibles desde la década de los años sesenta y han incluido la síntesis de péptidos en fase sólida y, adicionalmente, los procedimientos paralelos de síntesis en fase sólida desarrollados en los años ochenta. Estas técnicas se revisan en el artículo de Pinilla C., y otros (Nature Medicine (2003) , Vol. 9, páginas 118-122) .
La producción de bibliotecas de ADN que codifican diferentes péptidos es bien conocida per se en la materia. Las bibliotecas de genes aleatorizados tienen poco en común con la genómica convencional o con las bibliotecas de ADNc. Las bibliotecas convencionales consisten en clones que cubren colectivamente un genoma/transcriptoma completo y, generalmente, se seleccionan mediante hibridación de ácidos nucleicos. Por el contrario, las bibliotecas aleatorizadas generalmente contienen variaciones de un gen o de un fragmento de un gen que se seleccionan por su actividad novedosa. Los genes aleatorizados se expresan y seleccionan de forma convencional, por ejemplo, en fagos, bacterias o en técnicas de despliegue in vitro.
Convencionalmente, las técnicas de aleatorización de genes convencionales obligan a la clonación de un exceso de genes usando los codones NNN o NN G/T donde N = A, C, G y T, y tienen que clonarse 64 o 32 codones, respectivamente, para asegurarse la representación de los 20 aminoácidos. En un principio, estos datos pueden parecer relativamente pequeños pero, si consideramos posiciones múltiples de aleatorización, existe una relación exponencial entre el número de genes clonados y el número de proteínas obtenidas. Hine y otros han descrito previamente un procedimiento alternativo para producir bibliotecas de ADN, la aleatorización "MAX", en la que se aleatorizan dos o más posiciones de modo que están representados los 20 aminoácidos, o un subgrupo de los mismos (publicación de PCT WO 00/15777) . Esta metodología requiere un conjunto de oligonucleótidos para cada posición que se va a aleatorizar, que hibrida con un molde, convencionalmente (NNN) , aleatorizado en las posiciones apropiadas. Esta aproximación permite que cada aminoácido esté codificado sólo una vez dentro de los conjuntos de oligonucleótidos, por tanto, el número de genes únicos generados es equivalente al número de proteínas codificadas, independientemente del número de posiciones de aleatorización. Aunque esta metodología representa una mejora significativa con respecto a las técnicas tradicionales, sigue habiendo un porcentaje relativamente alto de codones no MAX no deseados (~10%) en las posiciones aleatorizadas. Adicionalmente, debido a las limitaciones del proceso de hibridación sólo se producen pequeñas cantidades de las construcciones de ADN, las cuales son difíciles de manipular especialmente cuando codifican subconjuntos de aminoácidos.
Posteriormente, Hine y otros han hecho mejoras en esta metodología que eliminan prácticamente la presencia de secuencias no deseadas y mejoran el rendimiento de ADN (Hine, A.V., Hughes, M.D., Nagel, D.A., Ashraf, M. y Santos, A.F. (2002) . MAX Codon Gene Libraries. Documento WO 03/106679; Hughes M.D., Nagel D.A., Santos A.F., Sutherland A.J. y Hine A.V. (2003) . Removing the redundancy from randomised gene libraries. J. Mol. Biol. 331 (5) , 973-979) . Esta metodología emplea algunos oligonucleótidos adicionales que hibridan con la cadena molde pero que también proporcionan una extensión que no es complementaria a la cadena molde. Esto permite la amplificación selectiva de la cadena codificadora requerida aumentando de este modo el rendimiento y minimizando las secuencias no deseadas.
El problema asociado con los procedimientos previos de la técnica ha sido la producción de más de dos codones aleatorizados contiguos. Esto es importante para permitir extensiones de varios aminoácidos en la secuencia que se va a aleatorizar. Las variaciones de los procedimientos descritos en, por ejemplo, el documento WO 03/106679 sólo permiten aleatorizar dos codones contiguos ya que se requiere el uso de secuencias de oligonucleótidos flanqueantes que hibriden con las cadenas molde. Adicionalmente, estos procedimientos requieren la producción de una cadena molde aleatorizada que se producirá antes de usar los oligonucleótidos de selección. Potencialmente esto limita el número de codones que pueden aleatorizarse debido a la complejidad/masa del oligonucleótido molde.
Los inventores probaron diversas técnicas en las que se aletorizaban tres o más oligonucleótidos consecutivos, lo que demostraba que era difícil obtener o, alternativamente producir, unos resultados satisfactorios. Entre estos se incluyen intentar ligar aleatoriamente tres o más trinucleótidos MAX en un oligonucleótido de cadena sencilla usando la ARN ligasa. Se comprobó que esta última técnica proporcionaba un resultado muy pobre y la posterior amplificación por PCR producía una mancha de la que los inventores no podían aislar muestras individuales. También se ha comprobado que es difícil la adición de codones MAX, que contienen 3 nucleótidos, ligados directamente al extremo romo de un oligonucleótido.
La técnica identificada ahora y descrita por los inventores permite inesperadamente la producción de codones aleatorizados contiguos sin la necesidad de producir oligonucleótidos molde aleatorizados.
La invención proporciona un procedimiento para producir una biblioteca de oligonucleótidos como se define en la reivindicación 1.
Los oligonucleótidos aleatorizados difieren porque tienen diferentes codones aleatorizados.
Los oligonucleótidos utilizados son preferiblemente de ADN, sin embargo, pueden usarse otros nucleótidos de cadena doble, como ARN o análogos de ADN o ARN.
Preferiblemente, los oligonucleótidos iniciadores de cadena doble comprenden un extremo romo al cual se ligan los oligonucleótidos de cadena doble aleatorizados.
El codón de aleatorización de la cadena codificadora y el codón complementario de la cadena no codificadora forman, preferiblemente, un extremo romo en los oligonucleótidos de aleatorización y están preferiblemente ligados al extremo romo del oligonucleótido iniciadores de cadena doble.
Al menos una porción del oligonucleótido iniciador al que se une el codón de aleatorización puede codificar una parte de un gen o de otra secuencia de nucleótidos que codifica una secuencia de aminoácidos predeterminada.
Preferiblemente, los oligonucleótidos aleatorizados y los oligonucleótidos iniciadores se ligan mediante una ADN ligasa. Las ADN ligasas son bien conocidas en la materia. Por ejemplo, E. coli y el fago T4 codifican una enzima, la ADN ligada, que sella mellas de cadena sencilla entre oligonucleótidos adyacentes en una cadena de ADN doble. Los requisitos de las diferentes enzimas son bien conocidos. Por ejemplo, la enzima de T4 necesita ATP mientras que la enzima de E. coli necesita NAD+. En cada caso, el cofactor se escinde y forma un complejo enzima-AMP. El complejo se une a uno de los lados de las cadenas de ADN que se quieren unir y establece un enlace covalente entre un 5'-fosfato de una cadena y un grupo 3'-OH de la cadena adyacente.
Por tanto, preferiblemente al menos uno de los extremos 5' de los oligonucleótidos que se van a ligar comprende un grupo fosfato que permite que los oligonucleótidos se liguen mediante una ADN ligasa.
Preferiblemente, ambos extremos 5' de los oligonucleótidos que se van a ligar comprenden un grupo fosfato. Preferiblemente la cadena adyacente a los grupos fosfato contendrán un grupo 3'-OH.
El sitio de escisión predeterminado para la endonucleasa está inmediatamente adyacente al codón de aleatorización.
Los oligonucleótidos ligados pueden amplificarse mediante, por ejemplo, PCR usando cebadores complementarios a, p. ej., secuencias de los oligonucleótidos iniciadores.
El producto de PCR producido puede purificarse y aislarse, por ejemplo, usando técnicas convencionales, como una electroforesis en geles de poliacrilamida (PAGE) y la escisión de la banda relevante de ADN antes del aislamiento del ADN y la digestión con la endonucleasa de restricción.
Se sigue la etapa (f) una o más veces... [Seguir leyendo]
Reivindicaciones:
1. Procedimiento de producción de una biblioteca de oligonucleótidos que comprende diversos oligonucleótidos, teniendo cada oligonucleótido en la biblioteca al menos dos posiciones predeterminadas, un codón de aleatorización seleccionado entre un grupo definido de codones, codificando los codones dentro de dicho grupo definido diferentes aminoácidos y comprendiendo dicho procedimiento las etapas de:
(a) Proporcionar uno o más oligonucleótidos iniciadores de cadena doble, en el que los oligonucleótidos iniciadores tienen uno o más extremos romos;
(b) Proporcionar diversos oligonucleótidos de aleatorización de cadena doble diferentes que comprenden:
(i) una cadena codificadora, comprendiendo la cadena codificadora un codón de aleatorización; y
(ii) una cadena no codificadora sustancialmente complementaria,
donde cada oligonucleótido de aleatorización de cadena doble comprende una secuencia de nucleótidos que codifica para un sitio de reconocimiento de endonucleasa de restricción capaz de ser reconocido por una endonucleasa de restricción, la endonucleasa de restricción capaz de escindir el sitio de reconocimiento de endonucleasa secuencia arriba o secuencia abajo del oligonucleótido de aleatorización en un sitio de escisión predeterminado para crear un corte de extremos romos y en el que la endonucleasa escinde el oligonucleótido de aleatorización adyacente al codón de aleatorización proporcionado por el oligonucleótido de aleatorización.
(c) Ligar cada oligonucleótido iniciador de cadena doble a un oligonucleótido de aleatorización de cadena doble para formar oligonucleótidos ligados;
(d) Amplificar los oligonucleótidos ligados;
(e) Digerir el oligonucleótido ligado con la endonucleasa de restricción para formar diversos oligonucleótidos aleatorizados de doble cadena, comprendiendo cada uno de ellos en un extremo un codón de aleatorización; y
(f) Usar los oligonucleótidos iniciadores aleatorizados de cadena doble y repetir las etapas (a) a (e) del procedimiento para producir diversos oligonucleótidos aleatorizados de cadena doble comprendiendo cada uno un codón de aleatorización adicional; en el que la etapa (f) se sigue una vez, u opcionalmente más veces, para producir una biblioteca de oligonucleótidos que comprende diversos oligonucleótidos, teniendo cada oligonucleótido en la biblioteca al menso dos codones aleatorizados contiguos.
2. Procedimiento según la reivindicación 1, en el que el sitio de reconocimiento de la endonucleasa de restricción y el sitio de escisión son:
5'-GAGTCNNNNN^-3' (SEC ID Nº 1.
3. CTCAGNNNNN^-5' (SEC ID Nº 2)
donde N = cualquier nucleótido ^ = el sitio de escisión de la endonucleasa de restricción.
3. Procedimiento según la reivindicación 2 en el que la endonucleasa de restricción se seleccionan entre SchI y MlyI.
4. Procedimiento según cualquiera de las reivindicaciones precedentes que se centra en el grupo de codones aleatorizados.
5. Procedimiento según cualquier de las reivindicaciones precedentes en el que los oligonucleótidos aleatorizados utilizados en cada etapa (f) según se define en la reivindicación 1 comprende una secuencia de nucleótidos diferente unida al codón de aleatorización, comparado con los utilizados en los ciclos previos de adición de codones aleatorios (etapas (a) a (e) ) .
6. Procedimiento según cualquiera de las reivindicaciones precedentes que adicionalmente comprende ligar un oligonucleótido de finalización que tiene una secuencia predefinida al oligonucleótido aleatorizado después de que se haya añadido un número predeterminado de codones de aleatorización.
7. Procedimiento según cualquiera de las reivindicaciones precedentes, en el que los codones de aleatorización consisten en codones MAX que representan el uso óptimo de codones de un organismo de interés predeterminado o una selección predeterminada de dichos codones MAX.
8. Procedimiento según cualquiera de las reivindicaciones precedentes, comprendiendo la cadena codificadora del oligonucleótido de aleatorización de doble cadena un extremo 5' y un extremo 3', comprendiendo el extremo 3' de la cadena codificadora un grupo bloqueante.
9. Procedimiento según la reivindicación 8, en el que el grupo bloqueante se selecciona entre un grupo amino, un grupo fosfato, un resto glicerol, un grupo tiol y un resto polietilénglicol.
10. Procedimiento según cualquiera de las reivindicaciones precedentes, en el que la cadena no codificadora comprende un extremo 3' y un extremo 5', extendiéndose el extremo 5' de la cadena no codificadora uno o más nucleótidos más allá del extremo 3' de la cadena complementaria a la codificadora.
11. Procedimiento según cualquiera de las reivindicaciones precedentes, en el que se purifica el oligonucleótido iniciador de cadena doble aleatorizado obtenido en la etapa (e) .
12. Procedimiento según cualquiera de las reivindicaciones precedentes que adicionalmente comprende las etapas de:
(g) Proporcionar un oligonucleótido iniciador de cadena doble aleatorizado producido mediante un procedimiento según cualquiera de las reivindicaciones precedentes;
(h) Proporcionar un oligonucleótido predefinido que comprende:
(i) una cadena codificadora, comprendiendo la cadena codificadora un codón predefinido que codifica un aminoácido predefinido; y
(ii) una cadena no codificadora sustancialmente complementaria,
donde el oligonucleótido predefinido comprende una secuencia de nucleótidos que codifica un sitio de reconocimiento de endonucleasa de restricción capaz de ser reconocido por una endonucleasa de restricción, siendo la endonucleasa de restricción capaz de escindir el oligonucleótido predefinido secuencia arriba o abajo del reconocimiento de la endonucleasa en un sitio de escisión predeterminado para crear un corte de extremos romos.
(i) Ligar el oligonucleótido iniciador de cadena doble aleatorizado con el oligonucleótido predefinido para formar un oligonucleótido ligado;
(j) Amplificar el oligonucleótido ligado; y
(k) Digerir el oligonucleótido ligado con la endonucleasa de restricción para formar un oligonucleótido aleatorizado que comprende en un extremo el codón predefinido.
13. Procedimiento según la reivindicación 12, que adicionalmente comprende las etapas de usar el oligonucleótido aleatorizado el codón predefinido como oligonucleótido iniciador y repetir las etapas (a) a (e) del procedimiento, y opcionalmente la etapa (f) como se define en la reivindicación 1, para añadir uno o más codones aleatorios adicionales a los oligonucleótidos.
14. Procedimiento según cualquiera de las reivindicaciones precedentes, que adicionalmente comprende la etapa de insertar un oligonucleótido obtenido de un procedimiento realizado como se define en cualquiera de las reivindicaciones precedentes en un vector de expresión.
15. Procedimiento según cualquiera de las reivindicaciones precedentes, en el que el vector de expresión se inserta en una célula huésped de expresión.
16. Procedimiento de producción de una biblioteca de péptidos aleatorizada que comprende la expresión de una biblioteca de oligonucleótidos obtenida por un procedimiento según cualquiera de las reivindicaciones precedentes.
Patentes similares o relacionadas:
Etiquetado y evaluación de una secuencia diana, del 13 de Mayo de 2020, de RhoDx, Inc: Un método para modificar un ácido nucleico, que comprende: (a) poner en contacto un ácido nucleico de cadena sencilla con una actividad de transferasa […]
Métodos para la expresión recombinante del gen de la beta-glucosidasa, del 29 de Abril de 2020, de Wilmar (shanghai) Biotechnology Research & Development Center Co., Ltd: Una proteína de fusión, en donde dicha proteína de fusión comprende: (a) una proteasa aspártica o un fragmento soluble de la misma, en donde dicho fragmento soluble […]
 Procedimientos y composiciones relacionados con los fragmentos de anticuerpos monocatenarios que se unen a la glucoproteína 72 asociada a tumor (TAG-72), del 25 de Marzo de 2020, de Ohio State Innovation Foundation: Un fragmento de anticuerpo scFv que se une específicamente a la glucoproteína 72 asociada a tumor (TAG-72), donde el fragmento de anticuerpo comprende SEQ ID NO: […]
Procedimientos y composiciones relacionados con los fragmentos de anticuerpos monocatenarios que se unen a la glucoproteína 72 asociada a tumor (TAG-72), del 25 de Marzo de 2020, de Ohio State Innovation Foundation: Un fragmento de anticuerpo scFv que se une específicamente a la glucoproteína 72 asociada a tumor (TAG-72), donde el fragmento de anticuerpo comprende SEQ ID NO: […]
Montaje de ADN mediado por nucleasas, del 8 de Enero de 2020, de REGENERON PHARMACEUTICALS, INC.: Un método in vitro para ensamblar en forma continua dos o más ácidos nucleicos de doble cadena, que comprende: (a) poner en contacto un primer […]
Adaptador vesicular y sus usos en la construcción y secuenciación de una biblioteca de ácidos nucleicos, del 10 de Julio de 2019, de MGI Tech Co., Ltd: Uso de un adaptador vesicular del oligonucleótido para la construcción de una biblioteca de ácidos nucleicos monocatenarios cíclicos en donde dicho adaptador […]
Composiciones y métodos para el ensamblaje de alta fidelidad de ácidos nucleicos, del 24 de Abril de 2019, de Gen9, Inc: Un método de producción de un ácido nucleico objetivo que tiene una secuencia predefinida, comprendiendo el método: proporcionar una pluralidad de fragmentos de […]
Oligonucleótido aislado y su uso en la secuenciación de ácidos nucleicos, del 27 de Marzo de 2019, de MGI Tech Co., Ltd: Un oligonucleótido aislado, que comprende una primera cadena y una segunda cadena, en las que un primer nucleótido terminal en el extremo […]
Adaptador vesicular y usos de este en la construcción y secuenciación de bibliotecas de ácidos nucleicos, del 9 de Enero de 2019, de MGI Tech Co., Ltd: Un adaptador vesicular de oligonucleótido para construir una biblioteca de ácidos nucleicos, que comprende: una región bicatenaria emparejada en 5' en un primer […]