Traducción automática usando formas lógicas.
Un procedimiento implementado por ordenador de descodificación durante un tiempo de ejecución de unatraducción,
de una estructura (552) semántica de entrada representada por una forma lógica (552) de origen obtenidade un texto (550) de origen en un primer idioma, para generar una estructura (556) semántica de salida representadapor una forma lógica (556) de salida, comprendiendo el procedimiento:
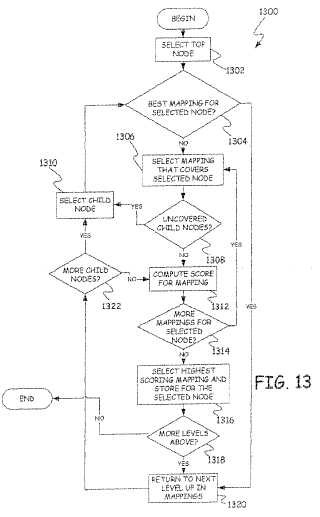
hallar un primer conjunto de correlaciones (800; 900; 1000; 1200; 1500; 1600; 1700; 1800; 1900; 2000; 2100) detransferencia contenidas en una base (518) de datos de correlaciones de transferencia, que fue formada durante elentrenamiento con un corpus bilingüe, teniendo cada correlación de transferencia un sector semántico de entrada quedescribe nodos de la estructura semántica de entrada, y teniendo un sector semántico de salida que describe nodos dela estructura semántica de salida;
calcular (1312) un puntaje para las correlaciones de transferencia en el conjunto de correlaciones de transferencia quecubren un nodo seleccionado de la estructura semántica de entrada usando un modelo estadístico,
en el cual el cálculo de un puntaje para las correlaciones de transferencia comprende
seleccionar (1306), entre el conjunto de correlaciones de transferencia, una correlación de transferencia que tenga un1sector de origen que cubra el nodo seleccionado;
determinar (1308) si hay algún nodo hijo en la estructura semántica de entrada que no esté cubierto por la correlaciónseleccionada y que se extienda directamente desde la correlación seleccionada,
y, si es así, combinar puntajes para las correlaciones de más alto puntaje, para los nodos filiales no cubiertos, con elpuntaje para la correlación seleccionada;
seleccionar (1316) la correlación de transferencia con el más alto puntaje, en base al puntaje;
determinar (1318) si existen más niveles por encima del nodo seleccionado, a fin de determinar (1322) si la correlaciónseleccionada tiene algún otro nodo hijo no cubierto y, si es así, seleccionar (1310) este nodo hijo no cubierto como unnuevo nodo seleccionado, y repetir las etapas del procedimiento, a partir de la etapa del hallazgo; y si no existen másniveles por encima del nodo seleccionado, se seleccionan las correlaciones de transferencia con el más alto puntajeusar las correlaciones de transferencia seleccionadas para construir la estructura semántica de salida; ygenerar un texto (558) de destino en un segundo idioma, en base a la estructura (556) semántica de salida.
Tipo: Patente Europea. Resumen de patente/invención. Número de Solicitud: E05102340.
Solicitante: MICROSOFT CORPORATION.
Nacionalidad solicitante: Estados Unidos de América.
Dirección: ONE MICROSOFT WAY REDMOND, WASHINGTON 98052-6399 ESTADOS UNIDOS DE AMERICA.
Inventor/es: MOORE, ROBERT C., AUE,ANTHONY, MENEZES,ARUL A, QUIRK,CHRISTOPHER B, RINGGER,ERIC K.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G06F17/27
- G06F17/28
PDF original: ES-2416359_T3.pdf
Fragmento de la descripción:
Traducción automática usando formas lógicas
Antecedentes de la invención La presente invención se refiere a sistemas de lenguaje automatizados. Más específicamente, la presente invención se 5 refiere a modelos de lenguaje en sistemas de lenguaje estadísticos.
Los sistemas de lenguaje automatizados incluyen el reconocimiento del habla, el reconocimiento de la escritura manual, la producción del habla, la corrección gramatical y la traducción automática.
Los sistemas de traducción automática (MT) son sistemas que reciben una entrada en un idioma (un idioma “de origen”) , traducen la entrada a un segundo idioma (un idioma “de destino”) y proporcionan una salida en el segundo idioma.
Un ejemplo de un sistema de MT usa formas lógicas (LF) , que son gráficos de dependencia que describen dependencias etiquetadas entre palabras del contenido en una cadena, como un paso intermedio en la traducción. Según este sistema, una cadena en el idioma de origen es analizada primero con un analizador sintáctico del idioma natural para producir una LF de origen. La LF de origen debe luego ser convertida en una LF del idioma de destino. 15 Una base de datos de correlaciones entre trozos de LF del idioma de origen y trozos de LF del idioma de destino (junto con otros metadatos, tales como los tamaños de las correlaciones y las frecuencias de las correlaciones en algunos conjuntos de entrenamiento) es usada para esta conversión. Habitualmente, el trozo de LF del idioma de origen de una única correlación no cubre la LF de origen entera. Como resultado, debe seleccionarse un conjunto de correlaciones (posiblemente solapadas) y sus trozos de LF del idioma de destino deben ser combinados para formar una LF de destino completa.
Para identificar el conjunto de formas lógicas de destino, un sistema de MT usa un algoritmo de búsqueda voraz para seleccionar una combinación de correlaciones a partir de las posibles correlaciones cuyos trozos de LF del idioma de origen coincidan con la LF de origen. Esta búsqueda voraz comienza clasificando las correlaciones por tamaño, frecuencia y otras características que miden cuán bien coinciden los trozos de LF del idioma de origen de la correlación con la LF de origen. La lista clasificada es luego recorrida de arriba hacia abajo y se escoge el primer conjunto de correlaciones compatibles hallado que cubra la forma lógica de origen. Este sistema heurístico, sin embargo, no prueba todas las posibles combinaciones de correlaciones de entrada, sino que sencillamente selecciona el primer conjunto de correlaciones que cubra completamente la LF de origen.
Después de que está seleccionado el conjunto de correlaciones, los trozos de LF del idioma de destino de las correlaciones son combinados de una manera congruente con la LF de origen, para producir una LF de destino. Finalmente, la ejecución de un sistema de generación de idioma natural en la LF de destino produce la salida en el idioma de destino.
Sin embargo, los sistemas de MT no siempre emplean formas lógicas u otras estructuras sintácticamente analizadas como representaciones intermedias. Ni tampoco usan necesariamente procedimientos heurísticos para resolver
ambigüedades de traducción. Algunos otros sistemas de MT intentan predecir la cadena del idioma de salida más probable, dada una cadena de entrada en el idioma de origen, usando modelos estadísticos. Tales sistemas de MT usan marcos y modelos estadísticos tradicionales, tales como el marco de canal ruidoso, para descodificar y hallar la oración T de destino que sea la más probable traducción para una oración S dada de origen. La maximización de esta probabilidad está representada por la:
Ecuación 1
T = arg max P (T’ | S)
T’
donde T’ varía sobre las oraciones en el idioma de destino. Usando la Regla de Bayes, la maximización de esta probabilidad también puede ser representada por:
Ecuación 2
T = arg max P (S | T’) x P (T’)
T’
donde P (S | T’) es la probabilidad de la cadena S de origen, dada una cadena T’ del idioma de destino, y P (T’) es la probabilidad de la cadena T’ del idioma de destino. En la MT estadística basada en cadenas (MT donde no se usa ninguna representación intermedia sintácticamente analizada) , se usa un modelo de idioma de destino entrenado en datos monolingüísticos del idioma de destino para calcular una estimación de P (T) , y se usan modelos de alineación de complejidad variable para calcular y estimar P (S | T) .
Hay un número de problemas asociados a los sistemas convencionales de MT estadística basada en cadenas. En particular, el espacio de búsqueda (todas las posibles cadenas en el idioma de destino) es bastante grande. Sin restringir este espacio de búsqueda, no puede construirse un sistema práctico de MT, porque lleva demasiado tiempo considerar todas las posibles cadenas de traducción. Para abordar esto, muchos sistemas usan una hipótesis simplificadora en cuanto a que las probabilidades del modelo del canal y del modelo del idioma de destino para una cadena entera pueden ser determinadas como el producto de probabilidades de subcadenas dentro de la cadena. Esta hipótesis es solamente válida mientras las dependencias en las cadenas y entre las cadenas estén limitadas a las áreas locales definidas por las subcadenas. Sin embargo, a veces la mejor traducción para un trozo de texto del idioma de origen está condicionada por los elementos de las cadenas del idioma de origen y de destino que están relativamente lejos del elemento a predecir. Dado que las hipótesis simplificadoras hechas en los modelos de MT estadística basada en cadenas están basadas, en gran parte, en la localidad de las cadenas, a veces los elementos condicionantes están lo bastante lejos del elemento a predecir como para que no puedan ser tenidos en cuenta por los modelos.
Por ejemplo, algunos sistemas de MT estadística basada en cadenas usan modelos de n-gramas de cadenas para su modelo lingüístico (LM) . Estos modelos de n-gramas son sencillos de entrenar, usar y optimizar. Sin embargo, los modelos de n-gramas tienen algunas limitaciones. Aunque una palabra puede ser predicha con precisión a partir de uno o dos de sus predecesores inmediatos, un buen número de construcciones lingüísticas colocan palabras sumamente predictivas lo suficientemente lejos de las palabras que predicen como para que estén excluidas del alcance del modelo de n-gramas de cadenas. Consideremos las siguientes oraciones activas y pasivas:
1. Juan golpeó la pelota.
2. Las pelotas fueron golpeadas por Lucía.
Los siguientes trigramas ocurren en estas oraciones con las frecuencias indicadas
<P> <P> Juan 1 <P> <P> Las 1
<P> Juan golpeó 1 <P> Las pelotas 1
Juan golpeó la 1 las pelotas fueron 1
golpeó la pelota 1 pelotas fueron golpeadas 1
la pelota <POSTE> 1 fueron golpeadas por 1
golpeadas por Lucía 1
por Lucía <POSTE> 1
donde “<P>” es una señal imaginaria al comienzo de una oración que proporciona contexto inicial de oración, y “<POSTE>” es una señal imaginaria al final de una oración. Debería observarse que cada uno de estos trigramas aparece una sola vez, incluso aunque el suceso (el golpe de una pelota) es el mismo en ambos casos.
En otro sistema de MT estadística, una estructura sintáctica en el idioma de origen es correlacionada con una cadena en el idioma de destino. Los modelos basados en la sintaxis tienen varias ventajas sobre los modelos basados en cadenas. En un aspecto, los modelos basados en la sintaxis pueden reducir la magnitud del problema de los datos ralos, normalizando los lemas. En otro aspecto, los modelos basados en la sintaxis pueden tener en cuenta la estructura sintáctica del idioma. Por lo tanto, los sucesos que dependen entre sí están a menudo más cercanos entre sí en un árbol de sintaxis de lo que están en la cadena superficial, porque la distancia hasta un padre común puede ser más corta que la distancia en la cadena.
Sin embargo, incluso en un modelo basado en la sintaxis, quedan inconvenientes: la distancia entre palabras interdependientes puede aún ser demasiado grande para ser capturada por un modelo local; además, conceptos 45 similares son expresados por estructuras distintas (p. ej., voz activa contra voz pasiva) y, por lo tanto, no se modelan juntos. Estos dan como resultado un mal entrenamiento del modelo y malas prestaciones de traducción.
A partir del documento US 2003 / 023422 A1, se conoce un sistema hermético de traducción automática.... [Seguir leyendo]
Reivindicaciones:
1. Un procedimiento implementado por ordenador de descodificación durante un tiempo de ejecución de una traducción, de una estructura (552) semántica de entrada representada por una forma lógica (552) de origen obtenida de un texto (550) de origen en un primer idioma, para generar una estructura (556) semántica de salida representada por una forma lógica (556) de salida, comprendiendo el procedimiento:
hallar un primer conjunto de correlaciones (800; 900; 1000; 1200; 1500; 1600; 1700; 1800; 1900; 2000; 2100) de transferencia contenidas en una base (518) de datos de correlaciones de transferencia, que fue formada durante el entrenamiento con un corpus bilingüe, teniendo cada correlación de transferencia un sector semántico de entrada que describe nodos de la estructura semántica de entrada, y teniendo un sector semántico de salida que describe nodos de la estructura semántica de salida;
calcular (1312) un puntaje para las correlaciones de transferencia en el conjunto de correlaciones de transferencia que cubren un nodo seleccionado de la estructura semántica de entrada usando un modelo estadístico,
en el cual el cálculo de un puntaje para las correlaciones de transferencia comprende seleccionar (1306) , entre el conjunto de correlaciones de transferencia, una correlación de transferencia que tenga un 15 sector de origen que cubra el nodo seleccionado;
determinar (1308) si hay algún nodo hijo en la estructura semántica de entrada que no esté cubierto por la correlación seleccionada y que se extienda directamente desde la correlación seleccionada,
y, si es así, combinar puntajes para las correlaciones de más alto puntaje, para los nodos filiales no cubiertos, con el puntaje para la correlación seleccionada;
seleccionar (1316) la correlación de transferencia con el más alto puntaje, en base al puntaje;
determinar (1318) si existen más niveles por encima del nodo seleccionado, a fin de determinar (1322) si la correlación seleccionada tiene algún otro nodo hijo no cubierto y, si es así, seleccionar (1310) este nodo hijo no cubierto como un nuevo nodo seleccionado, y repetir las etapas del procedimiento, a partir de la etapa del hallazgo; y si no existen más niveles por encima del nodo seleccionado, se seleccionan las correlaciones de transferencia con el más alto puntaje usar las correlaciones de transferencia seleccionadas para construir la estructura semántica de salida; y
generar un texto (558) de destino en un segundo idioma, en base a la estructura (556) semántica de salida.
2. El procedimiento de la reivindicación 1, en el cual el cálculo de un puntaje para al menos una correlación de transferencia comprende calcular un puntaje usando un modelo de idioma de destino que proporcione una probabilidad de que un conjunto de nodos aparezca en la estructura semántica de salida.
3. El procedimiento de la reivindicación 1, en el cual el cálculo de un puntaje para al menos una correlación de transferencia comprende calcular un puntaje usando un modelo de canal que proporcione una probabilidad de un sector semántico de entrada de una correlación de transferencia, dado el sector semántico de salida de la correlación de transferencia.
4. El procedimiento de la reivindicación 3, en el cual el cálculo de un puntaje usando el modelo de canal comprende normalizar un puntaje del modelo de canal en base a un cierto número de nodos solapados entre las correlaciones de transferencia.
5. El procedimiento de la reivindicación 1, en el cual el cálculo de un puntaje para el menos una correlación de transferencia comprende calcular un puntaje usando un modelo de fertilidad que proporcione una probabilidad de borrar un nodo en una correlación de transferencia.
6. El procedimiento de la reivindicación 1, en el cual el cálculo de un puntaje para al menos una correlación de transferencia comprende calcular un puntaje de tamaño en base a un cierto número de nodos en el sector semántico de entrada de la correlación de transferencia.
7. El procedimiento de la reivindicación 1, en el cual el cálculo de un puntaje para al menos una correlación de transferencia comprende calcular un puntaje de clasificación en base a un cierto número de características binarias 45 coincidentes en la estructura semántica de entrada y el sector semántico de entrada de la correlación de transferencia.
8. El procedimiento de la reivindicación 1, en el cual el cálculo de un puntaje para al menos una correlación de transferencia en el conjunto de correlaciones de transferencia comprende:
calcular puntajes distintos para una pluralidad de modelos; y combinar los distintos puntajes para determinar el puntaje para la correlación de transferencia.
9. El procedimiento de la reivindicación 8, en el cual la pluralidad de modelos comprende un modelo de canal que
proporciona una probabilidad de un sector semántico de entrada de una correlación de transferencia, dado el sector 5 semántico de salida de la correlación de transferencia.
10. El procedimiento de la reivindicación 8, en el cual la pluralidad de modelos comprende un modelo de fertilidad que proporciona una probabilidad de borrar un nodo en una correlación de transferencia.
11. El procedimiento de la reivindicación 8, en el cual la pluralidad de modelos comprende un modelo de idioma de destino que proporciona una probabilidad de que un conjunto de nodos aparezca en la estructura semántica de salida.
12. El procedimiento de la reivindicación 8, y que comprende adicionalmente:
calcular un puntaje de tamaño para la correlación de transferencia, estando el puntaje de tamaño basado en un cierto número de nodos en el sector semántico de entrada de la correlación de transferencia; y
combinar el puntaje de tamaño con los distintos puntajes para la pluralidad de modelos, para determinar el puntaje para la correlación de transferencia.
13. El procedimiento de la reivindicación 8, y que comprende adicionalmente:
calcular un puntaje de clasificación para la correlación de transferencia, estando el puntaje de clasificación basado en un cierto número de características binarias coincidentes en la estructura semántica de entrada y el sector semántico de entrada de la correlación de transferencia; y
combinar el puntaje de clasificación con los distintos puntajes para la pluralidad de modelos, para determinar el puntaje 20 para la correlación de transferencia.
14. El procedimiento de la reivindicación 8, en el cual la combinación de los puntajes comprende: multiplicar cada puntaje por un peso, para formar puntajes de modelos ponderados; y sumar los puntajes de modelos ponderados para determinar el puntaje para cada correlación de transferencia.
15. El procedimiento de la reivindicación 1, en el cual la provisión de un conjunto de correlaciones de transferencia
comprende proveer un conjunto de correlaciones de transferencia dispuestas como una estructura de árbol y múltiples niveles de sub-árboles anidados, que comprenden una correlación de transferencia de raíz y sub-árboles, comprendiendo cada sub-árbol una correlación de transferencia de raíz, en donde cada correlación de transferencia en el conjunto de correlaciones de transferencia aparece como una correlación de transferencia de raíz en al menos uno entre el árbol y los sub-árboles.
16. Un sistema (500) de traducción automática para traducir una entrada (550) en un primer idioma, a una salida (558) en un segundo idioma, comprendiendo el sistema:
un analizador sintáctico (522) para analizar sintácticamente la entrada en una representación (552) semántica de entrada, como una forma lógica (534) de origen;
un componente (524) de búsqueda configurado para hallar un conjunto de correlaciones de transferencia, de formas lógicas (534) de origen a formas lógicas (536) de destino, en donde cada correlación de transferencia corresponde a una parte de la representación semántica de entrada, y fue formada durante el entrenamiento con un corpus bilingüe;
un componente (554) de descodificación configurado para puntuar (1312) una pluralidad de correlaciones de transferencia que cubren un nodo seleccionado de la representación semántica de entrada, y para seleccionar (1316) la correlación de transferencia de más alto puntaje, en base a los puntajes,
en el cual la puntuación de la pluralidad de correlaciones de transferencia comprende seleccionar (1306) , entre una pluralidad de correlaciones de transferencia, una correlación de transferencia que tenga un sector de origen que cubra el nodo seleccionado;
determinar (1308) si hay algún nodo hijo en la representación semántica de entrada que no esté cubierto por la correlación seleccionada y que se extienda directamente desde la correlación seleccionada,
y, si es así, combinar los puntajes para las correlaciones de más alto puntaje, para los nodos filiales no cubiertos, con el puntaje para la correlación seleccionada;
en el cual el componente de descodificación está adicionalmente configurado para determinar (1318) si existen más niveles por encima del nodo seleccionado, a fin de determinar (1322) si la correlación seleccionada tiene algún otro nodo hijo no cubierto y, si es así, seleccionar (1310) este nodo hijo no cubierto como un nuevo nodo seleccionado para el componente de descodificación y, si no existen más niveles por encima del nodo seleccionado, seleccionar las correlaciones de transferencia con los más altos puntajes y un componente (528) de generación configurado para generar la salida en base a las correlaciones de transferencia seleccionadas con más altos puntajes.
17. El sistema de traducción automática de la reivindicación 16, en el cual el componente de descodificación puntúa 10 cada correlación de transferencia usando una pluralidad de modelos estadísticos.
18. El sistema de traducción automática de la reivindicación 17, en el cual la salida comprende una representación (556) semántica de salida y en el cual la pluralidad de modelos estadísticos comprende un modelo de destino que proporciona una probabilidad de que una secuencia de nodos aparezca en la representación semántica de salida.
19. El sistema de traducción automática de la reivindicación 17, en el cual la pluralidad de modelos estadísticos comprende un modelo de canal que proporciona una probabilidad de un conjunto de nodos semánticos en un sector de entrada de una correlación de transferencia, dado un conjunto de nodos semánticos en un sector de salida de la transferencia.
20. El sistema de traducción automática de la reivindicación 17, en el cual la pluralidad de modelos estadísticos comprende un modelo de fertilidad que proporciona una probabilidad de borrar un nodo en la correlación de 20 transferencia.
21. El sistema de traducción automática de la reivindicación 17, en el cual el componente de descodificación puntúa cada correlación de transferencia usando un puntaje de tamaño, basado en un cierto número de nodos en un sector de entrada de la correlación de transferencia.
22. El sistema de traducción automática de la reivindicación 17, en el cual el componente de descodificación puntúa
cada correlación de transferencia usando un puntaje de clasificación basado en un cierto número de características binarias coincidentes entre la entrada y un sector de salida de la correlación de transferencia.
Patentes similares o relacionadas:
Dispositivo de traducción con sistema automático de conmutación de salida de audio, del 10 de Mayo de 2017, de OCHOA VALEZ, Rómulo Antonio: 1. Dispositivo de traducción con sistema automático de conmutación de salida de audio; caracterizado porque comprende: - un cuerpo acoplable a […]
Procedimientos, aparatos y productos para el procesamiento semántico de texto, del 16 de Noviembre de 2016, de cortical.io GmbH: Procedimiento implementado por ordenador para generar un diccionario legible por ordenador para traducir texto en una forma legible por una red neuronal, que comprende: […]
Gestión de gráficos multilingües para retransmisiones televisivas, del 12 de Octubre de 2016, de INSTITUT FUR RUNDFUNKTECHNIK GMBH: Aparato de gráficos sobreimpresionados en pantalla para inserción de gráficos en una señal de televisión con: - una entrada para […]
Procedimiento de cálculo de correspondencias de traducción entre palabras de diferentes idiomas, del 7 de Septiembre de 2016, de Microsoft Technology Licensing, LLC: Un procedimiento implementado por ordenador para calcular correspondencias de traducción entre palabras, que comprende: calcular puntuaciones de asociación de palabras […]
SISTEMA, MÉTODO Y MEDIO LEGIBLE POR COMPUTADORA DE INTERFAZ DE LENGUAJE, del 13 de Agosto de 2015, de ALVAREZ HEINEMEYER, Marco: Se describe un sistema y método de interfaz de lenguaje para ser usado, preferiblemente, por las personas sordas, con discapacidad auditiva, mudas o con discapacidad visual. […]
Procedimiento, servidor y sistema para la transcripción de lengua hablada, del 25 de Diciembre de 2013, de VerbaVoice GmbH: Un procedimiento de transcripción para la transcripción de lengua hablada en texto continuo para un usuario (U) que comprende las etapas de: (a) introducir una lengua […]
Procedimiento y dispositivo para la adaptación de ficheros digitales, del 23 de Octubre de 2013, de AMADEUS S.A.S.: Procedimiento de adaptación de ficheros digitales que consiste en determinar cadenas de caracteresdenominadas fuentes en un fichero de programa que se va a […]
 MODELO DE PROBABILIDAD DE UNION BASADO EN FRASES PARA TRADUCCION AUTOMATICA ESTADISTICA, del 10 de Agosto de 2010, de UNIVERSITY OF SOUTHERN CALIFORNIA: Procedimiento implementado por ordenador para generar un modelo de probabilidad conjunta basado en frases a partir de un cuerpo paralelo que comprende […]
MODELO DE PROBABILIDAD DE UNION BASADO EN FRASES PARA TRADUCCION AUTOMATICA ESTADISTICA, del 10 de Agosto de 2010, de UNIVERSITY OF SOUTHERN CALIFORNIA: Procedimiento implementado por ordenador para generar un modelo de probabilidad conjunta basado en frases a partir de un cuerpo paralelo que comprende […]