Identificación automática de llamadores telefónicos en base a las características de voz.
Un procedimiento de identificación de un llamador de una llamada del llamador a un destinatario,
comprendiendo el procedimiento;
a) la recepción de una entrada de voz procedente del llamador;
b) la división de la entrada de voz en subsecciones y la aplicación de las características 5 de cada subseccióna una pluralidad de modelos acústicos, la cual comprende un modelo acústico genérico y unos modelosacústicos de cualquier llamador identificado con anterioridad, para obtener una pluralidad de puntuacionesacústicas respectivas que representan en qué medida las características de cada subsección coinciden conlos modelos acústicos respectivos;
c) para cada subsección, la identificación del modelo acústico que presenta la mejor puntuación acústicapara esa subsección;
la identificación del llamador como uno de los llamadores identificados con anterioridad, solo si las mejorespuntuaciones acústicas para todas las subsecciones se corresponden con el mismo llamador identificadocon anterioridad; y
en otro caso, la identificación del llamador como un nuevo llamador ; y
d) si el llamador se identifica como un nuevo llamador en la etapa c), la generación de un nuevo modeloacústico para el nuevo llamador, el cual es específico para el nuevo llamador
Tipo: Patente Europea. Resumen de patente/invención. Número de Solicitud: E04030909.
Solicitante: MICROSOFT CORPORATION.
Nacionalidad solicitante: Estados Unidos de América.
Dirección: ONE MICROSOFT WAY REDMOND, WA 98052 ESTADOS UNIDOS DE AMERICA.
Inventor/es: PASCOVICI,ANDREI.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G10L17/00 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › Identificación o verificación de la persona que habla.
PDF original: ES-2391454_T3.pdf
Fragmento de la descripción:
Identificación automática de llamadores telefónicos en base a las características de voz
Campo de la invención
La presente invención se refiere a un procedimiento y a un aparato implementado por computadora para identificar automáticamente a los llamadores de las llamadas telefónicas entrantes en base a las características de voz. En particular, la presente invención se refiere a unas técnicas de reconocimiento del habla computerizadas para encaminar y filtrar las llamadas telefónicas entrantes.
Antecedentes de la invención
En los sistemas de comunicaciones telefónicas a menudo son utilizados unos centros de llamadas para encaminar o seleccionar con carácter previo las llamadas en base a las respuestas del llamador a las indicaciones automatizadas. Dichos mecanismos de respuesta a las indicaciones a menudo son retardatarias, dado que el llamador debe navegar a través de un gran número de invitaciones antes de ser encaminado hasta el destinatario de la llamada o hasta la base de datos de información deseados. Así mismo, dichos mecanismos se basan en que el llamador sigue adecuadamente los comandos de invitación. Si el llamador no coopera con los comandos de invitación la llamada no puede ser encaminada de manera precisa. De modo similar, los mecanismos de selección de las llamadas se basan en la cooperación por parte del llamador para que responda sinceramente a las invitaciones de filtración. Esto hace difícil que el llamador y el destinatario encaminen y filtren las llamadas de una manera precisa y eficiente.
Por tanto, los sistemas de reconocimiento del habla, han sido propuestos para contribuir al proceso de encaminamiento de las llamadas. Sin embargo, dichos sistemas de reconocimiento del habla se han basado así mismo en un mecanismo de respuesta a la invitación en el cual el llamador debe responder a unas invitaciones predeterminadas. Por ejemplo, el sistema puede solicitar que el llamador declare el nombre del llamador y / o declare una palabra o secuencia de palabras predeterminada que represente la materia objeto de la llamada o la identidad del destinatario deseado. También aquí, estos sistemas son eficaces únicamente si el llamador es sincero al responder a las invitaciones predeterminadas. Así mismo, los modelos de reconocimiento del habla que son utilizados para determinar el contenido del habla deben ser capaces de segmentar con precisión el contenido, dado el amplio margen de las características de entrada de voz para diferentes llamador s. Dichos sistemas pueden, por tanto, seguir siendo retardatarios o imprecisos y pueden fácilmente ser eludidos por llamadores que no cooperen.
Por tanto, lo que se necesita son unos procedimientos y aparatos mejorados para el prefiltrado y encaminamiento automáticos de las llamadas telefónicas entrantes en base a las características de voz.
El trabajo de Rosenberg, Aaron E. et al.: “Utilización de Carpetas de Mensajes de Correo Electrónico de Voz por Parte de un Llamador que Utiliza un Reconocimiento del Hablante Independiente del Texto” [“Foldering Voice-mail Messages by Caller Using Text Independent Speaker Recognition”, ] Proceedings of International Conference of Speech and Language Processing, ICSLP 2000, vol. 2, páginas 474 a 477, se refiere a la utilización de carpetas de mensajes de correo electrónico de voz por el llamador que utiliza un reconocimiento del hablante independiente del texto. El discurso de un mensaje entrante es procesado y puntuado con respecto a los modelos llamador s. Un mensaje cuya puntuación coincidente sobrepase un umbral es archivado en la carpeta de llamadores coincidentes; de no ser así, es etiquetado como “desconocido”. El abonado tiene la capacidad de escuchar un mensaje “desconocido” y archivarlo en la carpeta apropiada, si existe, o crear una nueva carpeta, si no existe. Dichos mensajes etiquetados por el abonado se utilizan para entrenar y adaptar los modelos llamador s.
El trabajo de Carex, M.J. et al.: “Un sistema de verificación del hablante utilizando “alpha - nets” [“A speaker verification system using alpha-nets”], Speech Processing 2, VLSI, International Conference on Acoustics, Speech and Signal Processing, ICASSP, IEEE, US, vol. 2, Conf. 16, páginas 397 a 400, se refiere a un sistema de verificación del hablante que utiliza “alpha - nets”. En la forma más simple de un sistema de verificación se propone que hay dos modelos globales de palabras. Un modelo se deriva de las expresiones del hablante que va a ser verificado. El segundo modelo se deriva de las expresiones de una muestra de la población en general. La puntuación de la prueba de verificación para cada modelo es generada de salida como una medida de la probabilidad de registro a partir de una búsqueda Viterbi sincrónica de tramas. La diferencia entre las puntuaciones para los modelos personal y general es a continuación computada y comparada con un umbral. Si la diferencia sobrepasa el umbral, la persona es aceptada.
El trabajo de Leggetter, Woodland: “Adaptación del Hablante de los HMMs de Densidad Continua Utilizando una Regresión Lineal Multivariada” [“Speaeker Adaptation of Continuous Density HMMs Using Multivariate Linear Regression”, ICSLP 94: 1994 International Conference on Spoken Language Processing, Yokohama, Japón, 18 a 22 de septiembre de 1994 utiliza un conjunto inicial de modelos independientes de hablante satisfactorios y adapta los parámetros modales a un nuevo hablante mediante la transformación de los parámetros medios de los modelos con un conjunto de transformadas lineales. Las transformaciones se encuentran utilizando unos criterios de probabilidad máxima los cuales son implementados de manera similar a los algoritmos de entrenamiento de ML estándar para los HMMs.
Sumario de la invención
Constituye el objetivo de la presente invención reducir el tiempo de entrenamiento de un nuevo modelo acústico de un nuevo llamador.
Este objetivo lo consigue la invención como se reivindica en las reivindicaciones independientes. Formas de realización preferentes se definen en las reivindicaciones dependientes.
Una forma de realización de la presente invención se refiere a un procedimiento de identificación de un llamador de una llamada del llamador a un destinatario. Una entrada de voz es recibida del llamador , y la entrada de voz es dividida en subsecciones. Las características de cada subsección son aplicadas a una pluralidad de modelos acústicos, los cuales comprenden un modelo acústico genérico y modelos acústicos de cualquier llamador identificado con anterioridad, para obtener una pluralidad de puntuaciones acústicas que representan la medida en que las características de cada subsección coinciden con los respectivos modelos acústicos. Para cada subsección, se identifica el modelo acústico que presenta la mejor puntuación acústica de la subsección. El llamador es identificado como uno de los llamadores identificado con anterioridad solo si las mejores puntuaciones acústicas de todas las subsecciones se corresponden con el mismo llamador identificado con anterioridad. En otro caso, el llamador es identificado como un nuevo llamador . Si el llamador es identificado como un nuevo llamador, se genera un nuevo modelo acústico para el nuevo llamador , que es específico del nuevo llamador .
Otro forma de realización de la presente invención se refiere a un sistema para la identificación de un llamador de una llamada del llamador a un destinatario. El sistema incluye un destinatario para la recepción de una entrada de voz del llamador y un repositorio de modelos acústicos para el almacenamiento de una pluralidad de modelos acústicos. La pluralidad de los modelos acústicos incluye un modelo acústico genérico y unos modelos acústicos de cualquier llamador identificado con anterioridad. El sistema incluye así mismo unos medios para la división de la entrada de voz en subsecciones. Además de ello, el sistema comprende unos medios para la aplicación de las características de cada subsección a una pluralidad de modelos acústicos para obtener una pluralidad de puntuaciones acústicas respectivas que representen la medida en que las características de cada subsección coinciden con los respectivos modelos acústicos. Así mismo, el sistema incluye, para cada subsección, unos medios para la identificación del modelo acústico que presente la mejor puntuación acústica de esa subsección y unos medios para la identificación del llamador como... [Seguir leyendo]
Reivindicaciones:
1. Un procedimiento de identificación de un llamador de una llamada del llamador a un destinatario, comprendiendo el procedimiento;
a) la recepción de una entrada de voz procedente del llamador;
b) la división de la entrada de voz en subsecciones y la aplicación de las características de cada subsección a una pluralidad de modelos acústicos, la cual comprende un modelo acústico genérico y unos modelos acústicos de cualquier llamador identificado con anterioridad, para obtener una pluralidad de puntuaciones acústicas respectivas que representan en qué medida las características de cada subsección coinciden con los modelos acústicos respectivos;
c) para cada subsección, la identificación del modelo acústico que presenta la mejor puntuación acústica para esa subsección;
la identificación del llamador como uno de los llamadores identificados con anterioridad, solo si las mejores puntuaciones acústicas para todas las subsecciones se corresponden con el mismo llamador identificado con anterioridad; y
en otro caso, la identificación del llamador como un nuevo llamador ; y
d) si el llamador se identifica como un nuevo llamador en la etapa c) , la generación de un nuevo modelo acústico para el nuevo llamador, el cual es específico para el nuevo llamador.
2. El procedimiento de la reivindicación 1, en el que:
la etapa a) comprende la segmentación de la entrada de voz en una secuencia de unidades de habla reconocidas utilizando el modelo acústico genérico;
cada una de la pluralidad de modelos acústicos comprende los modelos de las unidades de habla segmentadas en la etapa a) ; y
la etapa b) comprende la aplicación de las características a una secuencia de los modelos de las unidades de habla segmentadas en la etapa a) para la pluralidad de modelos acústicos.
3. El procedimiento de la reivindicación 1, en el que cada uno de la pluralidad de modelos acústicos comprende unos modelos de unidades de habla y en el que el procedimiento comprende así mismo:
e) si el llamador es identificado como uno de los llamadores identificados con anterioridad en la etapa c) , la actualización del respectivo modelo acústico para el llamador identificado con anterioridad mediante la identificación de los modelos de las unidades de habla que están incluidas en la entrada de voz, en base a las características.
4. El procedimiento de la reivindicación 3, en el que la etapa e) comprende la modificación de los modelos de las unidades de habla que están incluidas en la entrada de voz en base a tan poco como a una sola emisión sonora.
5. El procedimiento de la reivindicación 1, que comprende así mismo:
e) el almacenamiento del nuevo modelo acústico en un repositorio de modelos acústicos con la pluralidad de modelos acústicos, de tal manera que el nuevo modelo acústico se convierte en uno de la pluralidad de modelos acústicos de la etapa b) y el nuevo llamador es incluido como un llamador identificado con anterioridad.
6. El procedimiento de la reivindicación 1, en el que el modelo acústico genérico comprende unos modelos independientes del llamador de una pluralidad de unidades de habla, y en el que la etapa d) comprende:
d) 1) la generación del nuevo modelo acústico a partir de los modelos independientes del llamador del modelo acústico genérico y la modificación de los modelos independientes del llamador de las unidades de habla que están incluidas en la entrada de voz para representar las características recibidas del nuevo llamador.
7. El procedimiento de la reivindicación 1, en el que las etapas a) a c) se llevan a cabo sin alertar al llamador durante la llamada de que el llamador está siendo identificado,
8. El procedimiento de la reivindicación 1, que comprende así mismo:
e) el mantenimiento de un modelo de leguaje específico del llamador para cada uno de los llamadores identificados con anterioridad en base a las entradas de voz procedentes de esos llamador s;
f) la aplicación de las características al modelo acústico genérico y a cada uno de los modelos de lenguaje
específicos del llamador para producir una pluralidad de secuencias de unidades de habla reconocidas; g) la elección de la secuencia de unidades de habla reconocidas que presenta la probabilidad más alta con respecto a las probabilidades de las demás secuencias de unidades de habla reconocidas; y
h) la identificación del llamador en base, en menos en parte, a la secuencia de las unidades de habla reconocidas que presentan la probabilidad más alta.
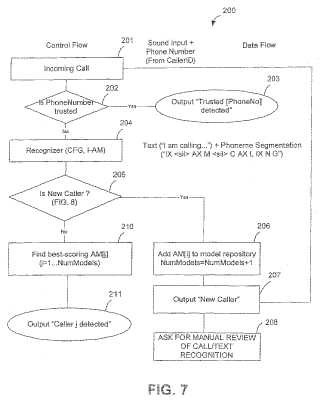
9. El procedimiento de la reivindicación 8, que comprende así mismo: i) si el llamador identificado en la etapa h) es diferente del llamador identificado en la etapa c) , la generación de una invitación al usuario para que efectúe un examen manual de al menos uno de los factores siguientes: la entrada de voz, la secuencia de unidades de habla reconocidas, los llamadores identificados, el modelo acústico del llamador identificado en la etapa c) , y el modelo de lenguaje específico del llamador del llamador identificado en la etapa h) .
10. El procedimiento de la reivindicación 1, que comprende así mismo: e) la utilización de una medida de distancia entre la pluralidad de modelos acústicos de los llamadores identificados con anterioridad para señalar determinados modelos acústicos para fusionarlos entre sí.
11. El procedimiento de la reivindicación 10, en el que la etapa e) comprende la señalización de determinados modelos acústicos con fines de inspección manual.
12. Un sistema para la identificación de un llamador de una llamada del llamador a un destinatario, comprendiendo
el sistema: un receptor (102) para la recepción de una entrada de voz procedente del llamador ; un repositorio (111) de modelos acústicos que comprende una pluralidad de modelos acústicos, que incluye
un modelo acústico genérico y unos modelos acústicos de los llamadores identificados con anterioridad; un medio para la división de la entrada de voz en subsecciones; un medio para la aplicación de las características a cada subsección a una pluralidad de modelos acústicos
para obtener una pluralidad de puntuaciones acústicas que representen en qué medida las características
de cada subsección coinciden con los modelos acústicos respectivos; para cada subsección, un medio para la identificación (112) del modelo acústico que presenta la mejor puntuación acústica para esa subsección;
un medio para la identificación del llamador como uno de los llamadores identificados con anterioridad solo si las mejores puntuaciones acústicas para todas las subsecciones se corresponden con el mismo llamador identificado con anterioridad; y
en otro caso, un medio para la identificación del llamador como nuevo llamador ; y un medio generador de un modelo acústico para la generación de un nuevo modelo acústico para el nuevo llamador si el llamador es identificado como un nuevo llamador .
13. El sistema de la reivindicación 12, en el que:
el sistema comprende así mismo un módulo de reconocimiento del habla, el cual segmenta la entrada de voz en una secuencia de unidades de habla reconocidas utilizando el modelo acústico genérico; cada uno de la pluralidad de modelos acústicos comprende unos modelos de las unidades de habla
reconocidas por el módulo de reconocimiento del habla; y el medio para la aplicación comprende un medio para la aplicación de las características a una secuencia de los modelos de las unidades de habla segmentadas por el módulo de reconocimiento del habla para la pluralidad de modelos acústicos.
14. El sistema de la reivindicación 12, en el que cada uno de la pluralidad de modelos acústicos comprende unos modelos de unidades de habla; el sistema así mismo comprende un modelo de actualización del modelo acústico el cual, si el llamador es
identificado como uno de los llamadores identificados con anterioridad, actualiza el modelo acústico
respectivo para el llamador identificado con anterioridad mediante la modificación de los modelos de las unidades de habla que están incluidas en la entrada de voz, en base a las características.
15. El sistema de la reivindicación 14, en el que el módulo de actualización de modelos acústicos es capaz de modificar los modelos de las unidades de habla que están incluidos en la entrada de voz en base a tan poco como una emisión sonora de habla procedente del llamador.
16. El sistema de la reivindicación 12, en el que el medio generador de modelos acústicos almacena el nuevo modelo acústico en el repositorio de modelos acústicos, de tal manera que el nuevo modelo acústico se convierte en uno de la pluralidad de modelos acústicos y el nuevo llamador es incluido como un llamador identificado con anterioridad.
17. El sistema de la reivindicación 16, en el que:
el modelo acústico genérico comprende unos modelos independiente del llamador de una pluralidad de unidades de habla; y
el generador de modelos acústicos genera el nuevo modelo acústico a partir de los modelos independientes del llamador del modelo acústico genérico y modifica los modelos independientes del llamador de las unidades de habla que están incluidas en la entrada de voz para representar las características.
18. El sistema de la reivindicación 12, en el que el sistema está configurado para recibir la entrada de voz e identificar al llamador sin alertar al llamador durante la llamada de que el llamador está siendo identificado.
19. El sistema de la reivindicación 12, que comprende así mismo:
un repositorio de modelos de lenguaje para el almacenamiento de un modelo de lenguaje específico del llamador para cada uno de los llamadores identificados con anterioridad en base a las entradas de voz procedentes de esos llamador s;
un medio para la aplicación de las características al modelo acústico genérico y a cada uno de los modelos de lenguaje del modelo específico para producir una pluralidad de secuencias de unidades de habla reconocidas; y
un medio para la elección de la secuencia de unidades de habla reconocidas que presente la probabilidad más alta con respecto a las probabilidades de las demás secuencias de unidades de habla reconocidas,
en el que el medio para la identificación identifica al llamador en base, al menos en parte, a la secuencia de unidades de habla reconocidas que presente la probabilidad más alta.
20. El sistema de la reivindicación 19, en el que el medio para la identificación comprende un medio para la generación de una invitación al usuario para que efectúe un examen manual de al menos uno de los factores siguientes: 1) la entrada de voz, la secuencia de unidades de habla reconocidas que presente la probabilidad más alta, 2) el modelo de lenguaje específico del llamador que produce la secuencia de unidades de habla reconocidas que presente la probabilidad más alta, y 3) el modelo acústico que presente la mejor puntuación acústica, si el modelo de lenguaje específico del llamador que presenta la probabilidad más alta se corresponde con un llamador diferente del modelo acústico que presenta la mejor puntuación acústica en 3) .
21. El sistema de la reivindicación 12, que comprende así mismo:
un medio para la señalización de determinados modelos acústicos para que se fusionen entre sí en base a una medición de distancia entre la pluralidad de modelos acústicos.
22. El procedimiento de la reivindicación 21, en el que el medio de señalización comprende un medio para la señalización de determinados modelos acústicos a los fines de su inspección manual.
23. Un medio legible por computadora que comprende unas instrucciones ejecutables por computadora las cuales, cuando son ejecutadas por una computadora, llevan a cabo el procedimiento que comprende:
a) la recepción de una entrada de voz de una llamada de un llamador;
b) la división de la entrada de voz en subsecciones y la aplicación de las características de cada subsección a una pluralidad de modelos acústicos, la cual comprende un modelo acústico genérico y unos modelos acústicos de cualquier llamador identificado con anterioridad, para obtener una pluralidad de puntuaciones acústicas respectivas que representen en qué medida las características de cada subsección coinciden con los modelos acústicos respectivos;
c) para cada subsección, la identificación del modelo acústico que presenta la mejor puntuación acústica para esa subsección;
la identificación del llamador como uno de los llamadores identificados con anterioridad solo si las mejores puntuaciones acústicas para todas las subsecciones se corresponden con el mismo llamador identificado con anterioridad; y
en otro caso, la identificación del llamador como un nuevo llamador ; y
d) si el llamador es identificado como un nuevo llamador en la etapa c) , la generación de un nuevo modelo acústico para el nuevo llamador el cual es específico para el nuevo llamador.
24. El medio legible por computadora de la reivindicación 23, en el que:
la etapa a) comprende la segmentación de la entrada de voz en una secuencia de unidades de habla reconocidas que utilizan el modelo acústico genérico;
cada uno de la pluralidad de modelos acústicos comprende unos modelos de las unidades de habla segmentadas en la etapa a) ; y
la etapa b) comprende la aplicación de las características a una secuencia de los modelos de las unidades de habla segmentadas en la etapa a) para la pluralidad de modelos acústicos.
25. El medio legible por computadora de la reivindicación 23, en el que cada uno de la pluralidad de modelos acústicos comprende unos modelos de unidades de habla y en el que el procedimiento comprende así mismo:
e) si el llamador es identificado como uno de los llamadores identificados con anterioridad en la etapa c) , la actualización del modelo acústico respectivo del llamador identificado con anterioridad mediante la modificación de los modelos de las unidades de habla que están incluidos en la entrada de voz en base a las características.
26. El medio legible por computadora de la reivindicación 23, en el que el procedimiento comprende así mismo:
e) el almacenamiento del nuevo modelo acústico en un repositorio de modelos acústicos con la pluralidad de modelos acústicos, de tal manera que el nuevo modelo acústico se convierte en uno de la pluralidad de modelos acústicos de la etapa b) , y el nuevo llamador se incluye como un llamador identificado con anterioridad.
27. El medio legible por computadora de la reivindicación 26, en el que el modelo acústico genérico comprende unos modelos independientes del llamador de una pluralidad de unidades de habla, y en el que la etapa d) comprende:
d) 1) la generación del nuevo modelo acústico a partir de los modelos independientes de la llamada del modelo acústico genérico y la modificación de los modelos genéricos de la llamada de las unidades de habla que están incluidos en la entrada de voz para representar las características.
28. El medio legible por computadora de la reivindicación 23, en el que el procedimiento comprende así mismo:
e) el mantenimiento de un modelo de lenguaje específico del llamador para cada uno de los llamadores identificados con anterioridad; y
f) la identificación del llamador en base, al menos en parte, a las probabilidades de las secuencias de unidades de habla reconocidas producidas por los modelos de lenguaje específicos del llamador a partir de la entrada de voz.
29. El medio legible por computadora de la reivindicación 28, en el que el procedimiento comprende:
g) si el llamador identificado en la etapa f) es diferente del llamador identificado en la etapa c) , la generación de una invitación al usuario para que efectúe un examen manual de al menos uno de los factores siguientes: la entrada de voz, la secuencia de unidades de habla reconocidas, los llamadores identificados, el modelo acústico del llamador identificado en la etapa c) , y el modelo de lenguaje específico del llamador del llamador identificado en la etapa f) .
30. El medio legible por computadora de la reivindicación 23, en el que el procedimiento comprende así mismo:
e) la utilización de una medida de distancia entre la pluralidad de modelos acústicos de los llamadores identificados con anterioridad para señalar determinados modelos acústicos para que se fusionen entre sí.
31. El medio legible por computadora de la reivindicación 30, en el que la etapa e) comprende la señalización de determinados modelos acústicos con fines de inspección manual.
Patentes similares o relacionadas:
Sistema y procedimiento de registro de audio inteligente para dispositivos móviles, del 2 de Noviembre de 2018, de QUALCOMM INCORPORATED: Un procedimiento para un dispositivo móvil, comprendiendo el procedimiento: mientras el dispositivo móvil está en una modalidad de reposo, capturar una señal […]
Dispositivo de montaje sobre la cabeza para percepción de realidad aumentada, del 30 de Octubre de 2017, de UNIVERSIDAD DE MALAGA: Dispositivo de montaje sobre la cabeza para percepción de realidad aumentada. La invención refiere un dispositivo que comprende medios de montaje sobre la […]
Procedimiento para verificar la identidad de un orador y medio legible por ordenador y ordenador relacionados, del 12 de Octubre de 2016, de AGNITIO, S.L.: Procedimiento para verificar la identidad de un orador en base a la voz de oradores, que comprende las etapas de: a) recibir una expresión de voz de una palabra o una […]
Procedimiento y dispositivo para la clasificación de interlocutores, del 18 de Marzo de 2015, de DEUTSCHE TELEKOM AG: Procedimiento para la clasificación automática de un interlocutor gracias a un sistema numérico, en el que se aplican, como mínimo, dos procedimientos distintos […]
Tarjeta inteligente con micrófono, del 7 de Enero de 2015, de VODAFONE HOLDING GMBH: Una tarjeta inteligente, que comprende un micrófono para capturar una señal de audio, y al menos un medio (104; 110; 111i) de procesamiento para procesar […]
 Método para la evaluación clínica del sistema fonador de pacientes con patologías laríngeas a través de una evaluación acústica de la calidad de la voz, del 3 de Diciembre de 2013, de UNIVERSIDAD DE LAS PALMAS DE GRAN CANARIA: Método para la evaluación clínica del sistema fonador de pacientes con patologías laríngeas a través de una evaluación acústica de la calidad de la voz.
La presente […]
Método para la evaluación clínica del sistema fonador de pacientes con patologías laríngeas a través de una evaluación acústica de la calidad de la voz, del 3 de Diciembre de 2013, de UNIVERSIDAD DE LAS PALMAS DE GRAN CANARIA: Método para la evaluación clínica del sistema fonador de pacientes con patologías laríngeas a través de una evaluación acústica de la calidad de la voz.
La presente […]
Detección de falsificación por cortar y pegar por alineamiento temporal dinámico, del 27 de Noviembre de 2013, de AGNITIO, S.L.: Procedimiento para comparar expresiones de voz, comprendiendo el procedimiento las etapas de: extraer una pluralidad de rasgos de una primera expresión […]
 Segmentación de señales de audio en eventos auditivos, del 11 de Abril de 2013, de DOLBY LABORATORIES LICENSING CORPORATION: Un método para dividir cada uno de los múltiples canales de señales de audio digital en eventos auditivos, quecomprende:
detectar cambios en el contenido […]
Segmentación de señales de audio en eventos auditivos, del 11 de Abril de 2013, de DOLBY LABORATORIES LICENSING CORPORATION: Un método para dividir cada uno de los múltiples canales de señales de audio digital en eventos auditivos, quecomprende:
detectar cambios en el contenido […]