Molécula de ARN monocatenario que tiene esqueleto alicíclico que contiene nitrógeno.
Una molécula de ARN monocatenario que comprende una secuencia inhibidora de la expresión que inhibe laexpresión de un gen diana,
donde:
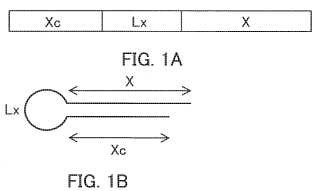
- la molécula comprende: una región (Xc); una región de ligador (Lx), una región interna (Z) que comprendela secuencia inhibidora de la expresión y que está compuesta por una región (X) y una región (Y), unaregión de ligador (Ly) y una región (Yc) en este orden;
- la región (Xc) es complementaria a la región (X);
- la región (Yc) es complementaria a la región (Y); y
- las regiones de ligador (Lx) y (Ly) se representan por la siguiente fórmula (I):en la que:
X1 y X2 son cada uno independientemente H2, O, S o NH;
Y1 y Y2 son cada uno independientemente un enlace sencillo, CH2, NH, O o S;
R3 es un átomo de hidrógeno o sustituyente que está unido a C-3, C-4, C-5 o C-6 sobre un anilloA;
L1 es una cadena de alquileno compuesta por n átomos, y un átomo de hidrógeno sobre un átomode carbono del alquileno puede o puede no estar sustituido con OH, ORa, NH2, NHRa, NRaRb, SHo SRa, o
L1 es una cadena de poliéter obtenida sustituyendo al menos un átomo de carbono sobre lacadena de alquileno con un átomo de oxígeno,
a condición de que: cuando Y1 sea NH, O o S, un átomo unido a Y1 en L1 sea carbono, un átomounido a OR1 en L1 sea carbono y los átomos de oxígeno no sean adyacentes entre sí;
L2 es una cadena de alquileno compuesta por m átomos, y un átomo de hidrógeno sobre un átomode carbono del alquileno puede o puede no estar sustituido con OH, ORc, NH2, NHRc, NRcRd, SH oSRc, o
L2 es una cadena de poliéter obtenida sustituyendo al menos un átomo de carbono sobre lacadena de alquileno con un átomo de oxígeno,
a condición de que: cuando Y2 sea NH, O o S, un átomo unido a Y2 en L2 sea carbono, un átomounido a OR2 en L2 sea carbono y los átomos de oxígeno no sean adyacentes entre sí;
Ra, Rb, Rc y Rd son cada uno independientemente un sustituyente o un grupo protector;
l es 1 ó 2;
m es un número entero en el intervalo de 0 a 30;
n es un número entero en el intervalo de 0 a 30;
las regiones (Xc) y (X) están cada una ligadas a la región de ligador (Lx) mediante -OR1- o -OR2-; y
R1 y R2 pueden o pueden no estar presentes, y cuando están presentes, R1 y R2 son cada unoindependientemente un residuo de nucleótido o la estructura de fórmula (I).
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/JP2011/067292.
Solicitante: Bonac Corporation.
Nacionalidad solicitante: Japón.
Dirección: Fukuoka BIO Factory 4F 1488-4 Aikawa-machi Kurume-shi, Fukuoka 839-0861 JAPON.
Inventor/es: SUZUKI, HIROSHI, OHGI, TADAAKI, HAYASHI,HIROTAKE, SHIROHZU,HISAO, HAMASAKI,TOMOHIRO, ITOH,AKIHIRO.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- C07D207/08 QUIMICA; METALURGIA. › C07 QUIMICA ORGANICA. › C07D COMPUESTOS HETEROCICLICOS (Compuestos macromoleculares C08). › C07D 207/00 Compuestos heterocíclicos que contienen ciclos de cinco miembros no condensados con otros ciclos, con solamente un átomo de nitrógeno como heteroátomo. › con radicales hidrocarbonados, sustituidos por heteroátomos, unidos a los átomos de carbono del ciclo.
- C12N15/113 C […] › C12 BIOQUIMICA; CERVEZA; BEBIDAS ALCOHOLICAS; VINO; VINAGRE; MICROBIOLOGIA; ENZIMOLOGIA; TECNICAS DE MUTACION O DE GENETICA. › C12N MICROORGANISMOS O ENZIMAS; COMPOSICIONES QUE LOS CONTIENEN; PROPAGACION, CULTIVO O CONSERVACION DE MICROORGANISMOS; TECNICAS DE MUTACION O DE INGENIERIA GENETICA; MEDIOS DE CULTIVO (medios para ensayos microbiológicos C12Q 1/00). › C12N 15/00 Técnicas de mutación o de ingeniería genética; ADN o ARN relacionado con la ingeniería genética, vectores, p. ej. plásmidos, o su aislamiento, su preparación o su purificación; Utilización de huéspedes para ello (mutantes o microorganismos modificados por ingeniería genética C12N 1/00, C12N 5/00, C12N 7/00; nuevas plantas en sí A01H; reproducción de plantas por técnicas de cultivo de tejidos A01H 4/00; nuevas razas animales en sí A01K 67/00; utilización de preparaciones medicinales que contienen material genético que es introducido en células del cuerpo humano para tratar enfermedades genéticas, terapia génica A61K 48/00; péptidos en general C07K). › Acidos nucleicos no codificantes que modulan la expresión de genes, p.ej. oligonucleótidos antisentido.
PDF original: ES-2443346_T3.pdf
Fragmento de la descripción:
Molécula de ARN monocatenario que tiene esqueleto alicíclico que contiene nitrógeno
Campo técnico
La presente invención se refiere a una molécula de ácido nucleico monocatenario que inhibe la expresión génica. En particular, la presente invención se refiere a una molécula de ácido nucleico monocatenario que tiene un esqueleto alicíclico que contiene nitrógeno, una composición que contiene la molécula de ácido nucleico monocatenario y el uso de la molécula de ácido nucleico monocatenario.
Técnica anterior
Como una técnica para inhibir la expresión génica se conoce, por ejemplo, la interferencia por ARN (iARN) (Fire y col., Nature, Feb. 19, 1998; 391 (6669) : 806-811) . La inhibición de la expresión génica por interferencia por ARN generalmente se lleva a cabo administrando una molécula de ARN bicatenario corto a, por ejemplo, una célula o similares. La molécula de ARN bicatenario generalmente se llama ARNip (ARN interferente pequeño) . Se ha informado que no solo el ARNip, sino que también una molécula de ARN circular que se ha convertido en parcialmente bicatenaria por hibridación intermolecular, también pueden inhibir la expresión génica (publicación de patente de EE.UU. nº 2004-058886, documento WO 2004/015075) . Sin embargo, las moléculas de ARN usadas en estas técnicas para inducir la inhibición de la expresión génica tienen los siguientes problemas.
Primero, con el fin de producir el ARNip, es necesario sintetizar una hebra codificante y una hebra no codificante por separado e hibridar estas hebras al final del procedimiento. Así, hay un problema de baja eficiencia de fabricación. Además, cuando el ARNip se administra a una célula, es necesario administrar el ARNip a la célula mientras que se inhibe la disociación a ARN monocatenario, que requiere una tarea laboriosa de fijar las condiciones para manipular el ARNip. Por otra parte, la molécula de ARN circular tiene un problema en que su síntesis es difícil.
Estas moléculas de ARN están básicamente compuestas por residuos de nucleótidos. Por ahora, con el fin de conferir alguna función a las moléculas de ARN o marcar las moléculas de ARN, no hay otra forma sino que modificar cualquiera de los componentes, es decir, una base, un residuo de azúcar o un grupo fosfato, del (de los) residuo (s) de nucleótido (s) . Por tanto, en el desarrollo de productos farmacéuticos y similares que utilizan interferencia por ARN es muy difícil alterar las moléculas de ARN de manera que se confiera otra función a las mismas o marcarlas mientras que se mantiene su función para inhibir la expresión génica.
Kumar y col., Organic Letters, vol. 3, nº 9, 1269-1272, 2001, informan de la síntesis de análogos de ADN positivamente cargados quirales basados en pirrolidina. Se presenta la síntesis de ácido (2S, 4S) y (2R, 4R) -timin-1-ilpirrolidin-N-acético, su incorporación específica de sitio en la quimera de PNA:ADN y PNA, y el estudio de sus propiedades de unión con secuencias de ADN/ARN complementarias.
Lonkar y Kumar, Bioorg. Med. Chem. Lett. 14 (2004) , 2147-2149, informan del diseño y síntesis de novedosos PNA de piperidina quirales a partir de 4-hidroxi-L-prolina que se produce naturalmente. La reacción de expansión del anillo estereoespecífica para conseguir un derivado de piperidina de seis miembros a partir del derivado de pirrolidina de 5 miembros se explota para esta síntesis. El PNA conformacionalmente contenido resultante se utiliza para la síntesis de mixmeros de PNA y el concepto está confirmado por estudios de UV-Tm de los complejos de PNA2:ADN resultantes.
El documento WO 98/16550 se refiere a ácidos nucleicos peptídicos quirales que se hibridan fuertemente con ácidos nucleicos complementarios y tienen potencial como agentes anti-gen y antisentido y herramientas en biología molecular. El documento US 2003/0059789 A1 se refiere a análogos de oligonucleótidos que incluyen moléculas de ácidos nucleicos (PNA) de proteínas. Los PNA se caracterizan porque incluyen una variedad de clases de moléculas tales como, por ejemplo, ácidos nucleicos peptídicos de hidroxiprolina (HypNA) y ácidos nucleicos peptídicos de serina (SerNA) .
El documento WO 2004/090108 se refiere a un agente de iARN que comprende una secuencia codificante y una secuencia no codificante, donde el agente comprende una modificación estabilizante tal como un grupo catiónico y la secuencia no codificante elige como diana un ARN expresado en el riñón.
El documento EP 1669450 A1 (WO 2005/030960) se refiere a los llamados oligonucleótidos de “apilamiento” para su uso como medicamentos. Los oligonucleótidos de apilamiento son monocatenarios y comprenden una secuencia del extremo 5', y secuencia intermedia y una secuencia del extremo 3'. La secuencia del extremo 5' tiene complementariedad inversa con la secuencia intermedia. La secuencia del extremo 3' tiene una complementariedad inversa con la secuencia intermedia. La secuencia intermedia tiene bucles de 3 a 10 nucleótidos en ambos extremos. Cada bucle no forma un enlace complementario intramolecularmente.
El documento WO 2006/074108 se refiere a moléculas de ácidos nucleicos que incluyen una región complementaria a un gen diana y unas o más regiones autocomplementarias. Se divulga el uso de tales moléculas de ácidos nucleicos y de composiciones que comprenden las moléculas para modular la expresión génica y tratar una variedad de enfermedades e infecciones.
El documento WO 2006/088490 se refiere a un ribonucleósido sustituido con un grupo fosfonamidito en la posición 3'. En ciertas realizaciones, el fosfonamidito es un fosfonamidito de alquilo. El documento WO 2006/088490 también se refiere a un oligonucleótido bicatenario que comprende al menos un enlace de no fosfato. Enlaces de no fosfato representativos incluyen enlaces fosfonato, hidroxilamina, hidroxilhidrazinilo, amida y carbamato. En ciertas realizaciones, el enlace de no fosfato es un enlace fosfonato.
El documento EP 2233573 A1 (documento WO 2009/074076) se refiere a una molécula compleja que interfiere con la expresión de genes diana y que contiene dos hebras de ARNip X1 y X2 que tienen al menos el 80 % de complementariedad. El extremo 5' de X1 y el extremo 3' de X2 están ligados mediante molécula de no ácido nucleico L1. El extremo 5' de X2 y el extremo 3' de X1 están ligados mediante molécula de no ácido nucleico L2.
Como ambos extremos 5' y 3' de dos hebras de ARNip X1 y X2 de la molécula compleja están ligados mediante moléculas de no ácido nucleico, no es fácil para las hebras de ARNip desenrollarse y degradarse.
El documento WO 2009/076321 divulga moléculas de ácidos nucleicos que incluyen una región complementaria a un gen diana y una o más regiones autocomplementarias. Tales ácidos nucleicos se usan para 20 modular la expresión génica y tratar una variedad de enfermedades e infecciones.
Breve resumen de la invención Teniendo en cuenta lo anterior, es un objetivo de la presente invención proporcionar una molécula de ácido nucleico 25 novedosa que pueda producirse fácilmente y eficazmente y pueda inhibir la expresión génica.
Con el fin de lograr el objetivo anterior, la presente invención proporciona una molécula de ARN monocatenario que comprende una secuencia inhibidora de la expresión que inhibe la expresión de un gen diana donde:
- la molécula comprende: una región (Xc) ; una región de ligador (Lx) , una región interna (Z) que comprende la secuencia inhibidora de la expresión y que está compuesta por una región (X) y una región (Y) , una región de ligador (Ly) y una región (Yc) en este orden; -la región (Xc) es complementaria a la región (X) ; -la región (Yc) es complementaria a la región (Y) ; y
-las regiones de ligador (Lx) y (Ly) se representan por la siguiente fórmula (I) :
en la que:
X1 y X2 son cada uno independientemente H2, O, S o NH; Y1 y Y2 son cada uno independientemente un enlace sencillo, CH2, NH, O o S; R3 es un átomo de hidrógeno o sustituyente que está unido a C-3, C-4, C-5 o C-6 sobre un anillo A; L1 es una cadena de alquileno compuesta por n átomos, y un átomo de hidrógeno sobre un átomo de 45 carbono del alquileno puede o puede no estar sustituido con OH, ORa, NH2, NHRa, NRaRb, SH o SRa, o L1 es una cadena de poliéter obtenida sustituyendo al menos un átomo de carbono sobre la cadena de alquileno con un átomo de oxígeno, a condición de que: cuando Y1 sea NH, O o S, un átomo unido a Y1 en L1 sea carbono, un átomo 50 unido a OR1 en L1 sea carbono y los átomos de oxígeno no sean adyacentes entre sí; L2 es una cadena de alquileno compuesta por m átomos, y un átomo de hidrógeno sobre un átomo de carbono del alquileno... [Seguir leyendo]
Reivindicaciones:
1. Una molécula de ARN monocatenario que comprende una secuencia inhibidora de la expresión que inhibe la expresión de un gen diana, donde:
- la molécula comprende: una región (Xc) ; una región de ligador (Lx) , una región interna (Z) que comprende la secuencia inhibidora de la expresión y que está compuesta por una región (X) y una región (Y) , una región de ligador (Ly) y una región (Yc) en este orden; -la región (Xc) es complementaria a la región (X) ; -la región (Yc) es complementaria a la región (Y) ; y -las regiones de ligador (Lx) y (Ly) se representan por la siguiente fórmula (I) :
en la que:
X1 y X2 son cada uno independientemente H2, O, S o NH; Y1 y Y2 son cada uno independientemente un enlace sencillo, CH2, NH, O o S; R3 es un átomo de hidrógeno o sustituyente que está unido a C-3, C-4, C-5 o C-6 sobre un anillo A; L1 es una cadena de alquileno compuesta por n átomos, y un átomo de hidrógeno sobre un átomo de carbono del alquileno puede o puede no estar sustituido con OH, ORa, NH2, NHRa, NRaRb, SH o SRa, o L1 es una cadena de poliéter obtenida sustituyendo al menos un átomo de carbono sobre la cadena de alquileno con un átomo de oxígeno, a condición de que: cuando Y1 sea NH, O o S, un átomo unido a Y1 en L1 sea carbono, un átomo unido a OR1 en L1 sea carbono y los átomos de oxígeno no sean adyacentes entre sí; L2 es una cadena de alquileno compuesta por m átomos, y un átomo de hidrógeno sobre un átomo de carbono del alquileno puede o puede no estar sustituido con OH, ORc, NH2, NHRc, NRcRd, SH o SRc, o L2 es una cadena de poliéter obtenida sustituyendo al menos un átomo de carbono sobre la cadena de alquileno con un átomo de oxígeno, a condición de que: cuando Y2 sea NH, O o S, un átomo unido a Y2 en L2 sea carbono, un átomo unido a OR2 en L2 sea carbono y los átomos de oxígeno no sean adyacentes entre sí; Ra, Rb, Rc y Rd son cada uno independientemente un sustituyente o un grupo protector; l es 1 ó 2; m es un número entero en el intervalo de 0 a 30; n es un número entero en el intervalo de 0 a 30; las regiones (Xc) y (X) están cada una ligadas a la región de ligador (Lx) mediante -OR1-o -OR2-; y R1 y R2 pueden o pueden no estar presentes, y cuando están presentes, R1 y R2 son cada uno independientemente un residuo de nucleótido o la estructura de fórmula (I) .
2. La molécula de ARN monocatenario según la reivindicación 1, donde el enlace de las regiones (Xc) y (X) a la estructura de la región de ligador (Lx) representada por la fórmula (I) y el enlace de las regiones (Yc) y (Y) a la estructura de la región de ligador (Ly) representada por la fórmula (I) satisfacen una cualquiera de las condiciones (1) a (4) :
-Condición (1) :
las regiones (Xc) y (X) están ligadas a la estructura de fórmula (I) mediante -OR2-y -OR1-, respectivamente, y las regiones (Yc) y (Y) están ligadas a la estructura de fórmula (I) mediante -OR1-y -OR2-, respectivamente;
-Condición (2) :
las regiones (Xc) y (X) están ligadas a la estructura de fórmula (I) mediante -OR2-y -OR1-,
respectivamente, y las regiones (Yc) y (Y) están ligadas a la estructura de fórmula (I) mediante -OR2-y -OR1-, respectivamente;
- Condición (3) :
las regiones (Xc) y (X) están ligadas a la estructura de fórmula (I) mediante -OR1-y -OR2-, respectivamente, y las regiones (Yc) y (Y) están ligadas a la estructura de fórmula (I) mediante -OR1-y -OR2-,
respectivamente;
-Condición (4) :
las regiones (Xc) y (X) están ligadas a la estructura de fórmula (I) mediante -OR1-y -OR2-,
respectivamente; y las regiones (Yc) y (Y) están ligadas a la estructura de fórmula (I) mediante -OR2-y -OR1-, respectivamente.
3. La molécula de ARN monocatenario según la reivindicación 1 ó 2, donde, en la fórmula (I) :
- L1 es la cadena de poliéter, y la cadena de poliéter es polietilenglicol, y/o - (m + n) total del número de átomos (n) en L1 y el número de átomos (m) en L2 está en el intervalo de 0 a 30.
4. La molécula de ARN monocatenario según una cualquiera de las reivindicaciones precedentes, donde la estructura de fórmula (I) es una cualquiera de las siguientes fórmulas (I-1) a (I-9) en las que n es un número entero 5. La molécula de ARN monocatenario según la reivindicación 4, donde:
en la fórmula (I-1) , n = 8; en la fórmula (I-2) , n = 3; en la fórmula (I-3) , n = 4 u 8; la fórmula (I-4) , n = 7 u 8; en la fórmula (I-5) , n = 3 y m = 4;
en la fórmula (I-6) , n = 8 y m = 4; en la fórmula (I-7) , n = 8 y m = 4; en la fórmula (I-8) , n = 5 y m = 4; y en la fórmula (I-9) , q = 1 y m = 4.
8. La molécula de ARN monocatenario según la reivindicación 7, donde el número de bases (X) en la región (X) y el número de bases (Xc) en la región del lado 5' (Xc) satisfacen una condición de la expresión (II) :
X –Xc = 1, 2 ó 3 … (11) 30
9. La molécula de ARN monocatenario según una cualquiera de las reivindicaciones precedentes, donde el número de bases (Xc) en la región (Xc) es 19 a 30.
10. La molécula de ARN monocatenario según una cualquiera de las reivindicaciones precedentes, donde el número
de bases (X) en la región (X) , el número de bases (Y) en la región (Y) , el número de bases (Xc) en la región (Xc) y el número de bases (Yc) en la región (Yc) satisfacen una condición de la expresión (2) :
11. La molécula de ARN monocatenario según una cualquiera de las reivindicaciones precedentes, donde el número de bases (X) en la región (X) , el número de bases (Xc) en la región (Xc) , el número de bases (Y) en la región (Y) y el número de bases (Yc) en la región (Yc) satisfacen una cualquiera de condiciones (a) a (d) :
(a) Se satisfacen las condiciones de las expresiones (3) y (4) ;
(b) Se satisfacen las condiciones de las expresiones (5) y (6) ;
(c) Se satisfacen las condiciones de las expresiones (7) y (8) ;
(d) Se satisfacen las condiciones de las expresiones (9) y (10) ;
12. La molécula de ARN monocatenario según la reivindicación 11, donde, en las condiciones (a) a (d) , la diferencia entre el número de bases (X) en la región (X) y el número de bases (Xc) en la región (Xc) y la diferencia entre el número de bases (Y) en la región (Y) y el número de bases (Yc) en la región (Yc) satisfacen las siguientes condiciones:
(a) Se satisfacen las condiciones de las expresiones (11) y (12) ;
X –Xc = 1, 2 ó3 … (11)
(b) Se satisfacen las condiciones de las expresiones (13) y (14) ;
Y –Yc = 1, 2 ó 3 … (14)
(c) Se satisfacen las condiciones de las expresiones (15) y (16) ;
X –Xc = 1, 2 ó 3 … (15) Y –Yc = 1, 2 ó 3 … (16)
(d) Se satisfacen las condiciones de las expresiones (17) y (18) ;
13. La molécula de ARN monocatenario según una cualquiera de las reivindicaciones precedentes, donde el número de bases (Xc) en la región (Xc) es 1 a 11.
14. La molécula de ARN monocatenario según la reivindicación 13, donde el número de bases (Xc) en la región (Xc) es 1 a 7.
15. La molécula de ARN monocatenario según la reivindicación 14, donde el número de bases (Xc) en la región (Xc) es 1 a 3.
16. La molécula de ARN monocatenario según una cualquiera de las reivindicaciones precedentes, donde el número de bases (Yc) en la región (Yc) es 1 a 11.
17. La molécula de ARN monocatenario según la reivindicación 16, donde el número de bases (Yc) en la región (Yc) es 1 a 7.
18. La molécula de ARN monocatenario según la reivindicación 17, donde el número de bases (Yc) en la región (Yc) es 1 a 3.
19. La molécula de ARN monocatenario según una cualquiera de las reivindicaciones precedentes, que comprende al menos un residuo modificado y/o una sustancia de marcado y/o un isótopo estable.
20. La molécula de ARN monocatenario según una cualquiera de las reivindicaciones precedentes, donde el número total de bases en la molécula es 50 o más.
21. Una composición para inhibir la expresión de un gen diana, comprendiendo la composición la molécula de ARN monocatenario según una cualquiera de las reivindicaciones precedentes.
22. Una composición farmacéutica que comprende la molécula de ARN monocatenario según una cualquiera de las reivindicaciones 1 a 20.
23. La composición farmacéutica según la reivindicación 22 para su uso en el tratamiento de inflamación.
24. Un procedimiento in vitro para inhibir la expresión de un gen diana, comprendiendo el procedimiento usar la molécula de ARN monocatenario según una cualquiera de las reivindicaciones 1 a 20.
25. El procedimiento según la reivindicación 24, que comprende administrar la molécula de ARN monocatenario a una célula, un tejido o un órgano in vitro.
26. Un procedimiento in vitro para inducir la interferencia por ARN que inhibe la expresión de un gen diana, comprendiendo el procedimiento usar la molécula de ARN monocatenario según una cualquiera de las reivindicaciones 1 a 20.
27. Una molécula de ARN para su uso en el tratamiento de una enfermedad, donde la molécula es la molécula de ARN monocatenario según una cualquiera de las reivindicaciones 1 a 20, y la molécula de ARN monocatenario comprende como secuencia inhibidora de la expresión una secuencia que inhibe la expresión de un gen que causa la enfermedad.
(pb)
Patentes similares o relacionadas:
Compuesto heterocíclico, del 16 de Octubre de 2019, de TAKEDA PHARMACEUTICAL COMPANY LIMITED: Un compuesto representado por la fórmula (I):**Fórmula** en la que el anillo A es un anillo de benceno opcionalmente sustituido adicionalmente; […]
Proceso de preparación de agonistas beta-3 y productos intermedios, del 10 de Julio de 2019, de MERCK SHARP & DOHME CORP: Un proceso de preparación del compuesto I-6:**Fórmula** que comprende: (a-2) reducir el compuesto I-3:**Fórmula** en presencia de […]
Compuestos de tetraciclina, del 13 de Mayo de 2019, de Tetraphase Pharmaceuticals, Inc: Un compuesto que tiene la siguiente Fórmula Estructural: **Fórmula** o una sal farmacéuticamente aceptable del mismo, en la que: R4 es -(alquilo C1-C6); […]
Derivado de bifenilo novedoso y método para preparar el mismo, del 24 de Abril de 2019, de Dong-A ST Co., Ltd: Un derivado de bifenilo representado por la siguiente fórmula 1, un estereoisómero del mismo, o una sal farmacéuticamente aceptable del mismo:**Fórmula** en la que […]
Derivados de dolastatina 10 y auristatinas, del 11 de Diciembre de 2018, de PIERRE FABRE MEDICAMENT: Compuesto de la fórmula (I) siguiente:**Fórmula** en la que: - R1 es H u OH, - R2 es un grupo alquilo (C1-C6), COOH, COO-(alquilo (C1-C6)) […]
Composiciones que contienen y métodos que implican derivados de dolastatina enlazados con aminoácidos no naturales y usos de los mismos, del 23 de Noviembre de 2018, de AMBRX, INC: Un compuesto que tiene: **Fórmula** en donde: Z tiene la estructura de: **Fórmula** R5 es H, COR8, C1-C6 alquilo o tiazol; R8 es OH o -NH-(alquileno-O)n-NH2; […]
Compuesto 3-fenoximetilpirrolidina, del 11 de Abril de 2018, de Theravance Biopharma R&D IP, LLC: Compuesto de fórmula I:**Fórmula** en la que: R1 se selecciona de entre alquilo C2-6, cicloalquilo C3-8 sustituido opcionalmente con 1 o 2 átomos de flúor, […]
Composiciones farmcéuticas que comprenden poli(beta-amino-ésteres) biodegradables, del 7 de Marzo de 2018, de MASSACHUSETTS INSTITUTE OF TECHNOLOGY: Una composición farmacéutica que comprende un polinucleótido y un compuesto de fórmula:**Fórmula** o una sal del mismo, en la que: el conector […]