SEGMENTACION DEL HABLA.
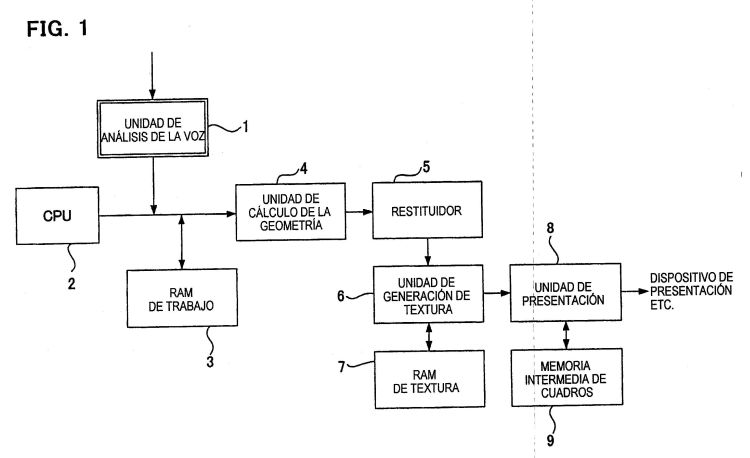
Un método ejecutable en ordenador de análisis de la voz que detecta los límites de fonemas a partir de una señal de voz de entrada,
que comprende: un primer paso que especifica un punto en el tiempo en dicha señal de voz de entrada; un segundo paso de extracción de la señal de voz contenida en un margen de tiempo de una longitud previamente establecida desde dicho punto en el tiempo; y un tercer paso de descomposición de dicha señal de voz extraída en datos de componentes de la frecuencia, en que se hallan n datos de componentes de la frecuencia extraídos de la señal de voz contenida en n márgenes de tiempo de dicha longitud previamente establecida, repitiendo para ello dichos pasos primero, segundo y tercero n veces, donde n es un número natural de al menos 6 para cada tiempo previamente establecido; se hallan (n-1) correlaciones a partir de n de dichos datos de componentes de la frecuencia mediante la obtención de la correlación i-ésima, donde i es un número natural de al menos 1 y no mayor que (n-1), basado en el elemento i-ésimo de dichos datos de componentes de la frecuencia y en el elemento (i+1)-ésimo de dichos datos de componentes de la frecuencia correspondientes a dicha señal de voz contenida en márgenes de tiempo mutuamente adyacentes de dicha longitud previamente establecido; se hallan (n-2) diferencias entre correlaciones a partir de las (n-1) de dichas correlaciones, hallando para ello la diferencia k-ésima entre correlaciones basada en la correlación k-ésima y en dicha correlación (k+1)-ésima, donde k es un número natural de al menos 1 y no mayor que (n-2); cuando m está definido como el número que especifica la diferencia entre correlaciones que es mayor que dos diferencias entre correlaciones adyacentes que la diferencia entre correlaciones especificadas en las (n-2) diferencias entre correlaciones desde la primera hasta la (n-2)-ésima, se halla el número m definido, es decir el m que satisface la condición de que la diferencia m-ésima entre correlaciones esmayor que la diferencia (m-1)ésima entre correlaciones y es mayor que la diferencia (m+1)-ésima entre correlaciones cuando se cambia m de uno en uno desde 2 hasta (n-3); se especifica un margen de tiempo de dicha longitud previamente establecida de acuerdo con el número m definido; y se divide dicha señal de voz de entrada en una pluralidad de secciones de acuerdo con dichos márgenes de tiempo especificados.
Tipo: Resumen de patente/invención.
Solicitante: SEGA CORPORATION.
Nacionalidad solicitante: Japón.
Dirección: 2-12, HANEDA 1-CHOME OHTA-KU,,TOKYO 144-8531.
Inventor/es: KUDOH,HIROKAZU.
Fecha de Publicación: .
Fecha Solicitud PCT: 22 de Febrero de 2005.
Fecha Concesión Europea: 18 de Abril de 2007.
Clasificación PCT:
- G06T13/00 FISICA. › G06 CALCULO; CONTEO. › G06T TRATAMIENTO O GENERACIÓN DE DATOS DE IMAGEN, EN GENERAL. › Animación.
- G10L15/02 G […] › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › G10L 15/00 Reconocimiento de la voz (G10L 17/00 tiene prioridad). › Extracción de características para el reconocimiento de la voz; Selección de la unidad de reconocimiento.
- G10L15/04 G10L 15/00 […] › Segmentación o detección de los límites de las palabras; Word boundary detection.
- G10L15/10 G10L 15/00 […] › utilizando medidas de distorsión o distancia entre la voz desconocida y las plantillas de referencia.
Países PCT: Austria, Bélgica, Suiza, Alemania, Dinamarca, España, Francia, Reino Unido, Grecia, Italia, Liechtensein, Luxemburgo, Países Bajos, Suecia, Mónaco, Portugal, Irlanda, Eslovenia, Finlandia, Rumania, Chipre, Lituania, Letonia, Ex República Yugoslava de Macedonia, Albania.
Patentes similares o relacionadas:
Método y aparato para reconocimiento de voz automático, del 3 de Abril de 2019, de Oxford University Innovation Limited: Método de reconocimiento de voz automático, comprendiendo el método las etapas de: recibir una señal de voz , dividir la señal de voz en ventanas de tiempo, […]
SISTEMA DE IDENTIFICACIÓN DE SONIDOS MEDIANTE CLASIFICACIÓN PARAMÉTRICA DE SERIES DERIVADAS, del 17 de Mayo de 2018, de UNIVERSIDAD DE SEVILLA: La presente invención tiene por objeto un sistema de identificación de sonidos que se basa en la descripción y selección de unos pocos parámetros […]
Sistema de identificación de sonidos mediante clasificación paramétrica de series derivadas, del 11 de Mayo de 2018, de UNIVERSIDAD DE SEVILLA: La presente invención tiene por objeto un sistema de identificación de sonidos que se basa en la descripción y selección de unos pocos parámetros […]
 Sistema y método para realizar consultas textuales en comunicaciones de voz, del 6 de Enero de 2016, de JaJah Ltd: Un sistema para realizar consultas textuales en comunicaciones de voz, comprendiendo el sistema:
un servicio de índices para almacenar […]
Sistema y método para realizar consultas textuales en comunicaciones de voz, del 6 de Enero de 2016, de JaJah Ltd: Un sistema para realizar consultas textuales en comunicaciones de voz, comprendiendo el sistema:
un servicio de índices para almacenar […]
Sistema y método para reconocer un comando de voz de usuario en un entorno con ruido, del 1 de Abril de 2015, de Veovox SA: Sistema automático de reconocimiento de voz para reconocer un comando de voz de usuario en un entorno con ruido, que comprende: - unos medios de concordancia para […]
 Procedimiento y dispositivo para generar una huella digital y procedimiento y dispositivo para identificar una señal de audio, del 15 de Junio de 2012, de M2ANY GMBH: Procedimiento para generar una huella digital de una señal de audio utilizando información de modo, que define una pluralidad de modos de huella […]
Procedimiento y dispositivo para generar una huella digital y procedimiento y dispositivo para identificar una señal de audio, del 15 de Junio de 2012, de M2ANY GMBH: Procedimiento para generar una huella digital de una señal de audio utilizando información de modo, que define una pluralidad de modos de huella […]
PROCEDIMIENTO DE RECONOCIMIENTO DE VOZ., del 1 de Septiembre de 2006, de PROUS SCIENCE, S.A.: Procedimiento de reconocimiento de voz, que comprende: (a) una etapa de descomposición de una señal de voz digitalizada en una pluralidad de fracciones, (b) una etapa de representación […]
EXTRACCION ADAPTABLE DE ONDICULAS PARA RECONOCIMIENTO DE VOZ., del 16 de Octubre de 2005, de MATSUSHITA ELECTRIC INDUSTRIAL CO., LTD.: Método para extraer características para el reconocimiento automático de la voz, que comprende las etapas de: descomponer una señal acústica […]