SISTEMA DE RECONOCIMIENTO DE LA VOZ QUE USA ADAPTACIÓN IMPLÍCITA AL ORADOR.
Un procedimiento para realizar el reconocimiento de voz que comprende:
realizar el apareo de patrones de un primer segmento de voz de entrada con al menos una primera plantilla acústica de un modelo acústico (230, 232) independiente del orador, para producir al menos una plantilla de apareo de patrones de entrada y para determinar una clase de emisión vocal reconocida, en el cual la clase de emisión vocal es una palabra o segmento de habla específico; comparar dicha(s) plantilla(s) de apareo de patrones de entrada con una plantilla correspondiente asociada a al menos una segunda plantilla acústica proveniente del modelo acústico (234) del orador de la primera voz de entrada, la segunda plantilla acústica asociada a la clase de emisión vocal reconocida; y determinar si se actualiza o no dicha(s) segunda(s) plantilla(s) acústica(s), en donde dicha(s) segunda(s) plantilla(s) acústica(s) se actualiza(n) si dicha(s) plantilla(s) de apareo de patrones de entrada es (son) mejor(es) que la correspondiente plantilla asociada a dicha(s) segunda(s) plantilla(s) acústica(s)
Tipo: Patente Europea. Resumen de patente/invención. Número de Solicitud: E07014802.
G10L15/10FISICA. › G10INSTRUMENTOS MUSICALES; ACUSTICA. › G10LANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › G10L 15/00 Reconocimiento de la voz (G10L 17/00 tiene prioridad). › utilizando medidas de distorsión o distancia entre la voz desconocida y las plantillas de referencia.
G10L15/12G10L 15/00 […] › utilizando técnicas de programación dinámica, p. ej. normalización temporal por comparación dinámica [DTW].
G10L15/14M
G10L15/14M1
Clasificación PCT:
G10L15/06G10L 15/00 […] › Creación de plantillas de referencia; Entrenamiento de sistemas de reconocimiento de la voz, p. ej. adaptación a las características de la voz de la persona que habla (G10L 15/14 tiene prioridad).
G10L15/12G10L 15/00 […] › utilizando técnicas de programación dinámica, p. ej. normalización temporal por comparación dinámica [DTW].
G10L15/14G10L 15/00 […] › utilizando técnicas de programación dinámica, p. ej. normalización temporal por comparación dinámica [DTW] (G10L 15/18 tiene prioridad).
Países PCT: Austria, Bélgica, Suiza, Alemania, Dinamarca, España, Francia, Reino Unido, Grecia, Italia, Liechtensein, Luxemburgo, Países Bajos, Suecia, Mónaco, Portugal, Irlanda, Finlandia, Chipre.
Sistema de reconocimiento de la voz que usa adaptación implícita al orador ANTECEDENTES Campo La presente invención se refiere al procesamiento de señales de voz. De manera particular, la presente invención se refiere a un procedimiento y aparato novedosos de reconocimiento de voz para conseguir prestaciones mejoradas a través de un entrenamiento sin supervisión. Antecedentes El reconocimiento de voz representa una de las técnicas más importantes para dotar a una máquina con inteligencia simulada para reconocer órdenes habladas del usuario y para facilitar la interfaz humana con la máquina. Los sistemas que emplean técnicas para recuperar un mensaje lingüístico a partir de una señal de voz acústica, se denominan sistemas de reconocimiento de voz (VR). La FIG. 1 muestra un sistema de VR básico que tiene un filtro 102 de preénfasis, una unidad 104 de extracción de características acústicas (AFE) y un motor 110 de apareo de patrones. La unidad AFE 104 convierte una serie de muestras digitales de voz en un conjunto de valores de medida (por ejemplo, las componentes de frecuencia extraídas) denominados un vector de características acústicas. El motor 110 de apareo de patrones aparea una serie de vectores de características acústicas con las plantillas contenidas en un modelo acústico 112 de VR. Los motores de apareo de patrones de VR emplean por lo general técnicas de distorsión dinámica en el tiempo (DTW) o el Modelo de Markov Oculto (HMM). Tanto DTW como HMM son bien conocidas en la técnica y se describen con detalle en el documento de Rabiner, L. R., y Juang, B. H., FUNDAMENTOS DEL RECONOCIMIENTO DE VOZ, Prentice-Hall, 1993. Cuando una serie de características acústicas coincide con una plantilla en el modelo acústico 112, la plantilla identificada se usa para generar un formato de salida deseado, tal como una secuencia identificada de palabras lingüísticas correspondientes a la voz de entrada. Como se ha hecho notar anteriormente el modelo acústico 112 generalmente es un modelo HMM o un modelo DTW. Se puede pensar en un modelo acústico DTW como en una base de datos de plantillas asociadas con cada una de las palabras que necesitan ser reconocidas. En general, una plantilla DTW consiste en una secuencia de vectores de características que han sido promediados sobre muchas muestras de la palabra asociada. El apareo de patrones del DTW generalmente implica la localización de una plantilla almacenada que tiene una distancia mínima a la secuencia del vector de características de entrada que representa la voz de entrada. Una plantilla usada en un modelo acústico basado en HMM contiene una descripción estadística detallada de la emisión vocal de la voz asociada. En general, una plantilla HMM almacena una secuencia de vectores de media, vectores de varianza y un conjunto de probabilidades de transición. Estos parámetros se usan para describir las estadísticas de una unidad de voz y se estiman a partir de muchos ejemplos de la unidad de voz. El apareo de patrones de HMM generalmente implica la generación de una probabilidad para cada plantilla del modelo basada en la serie de vectores de características de entrada asociados a la voz de entrada. La plantilla que tenga la probabilidad más alta se selecciona como la emisión vocal de entrada más probable. El entrenamiento se refiere al proceso de recoger muestras de voz de un segmento o sílaba particular del habla de uno o más oradores con el fin de generar plantillas en el modelo acústico 112. Cada plantilla en el modelo acústico está asociada a una palabra o segmento de voz particulares denominados una clase de emisión vocal. Puede haber múltiples plantillas en el modelo acústico asociadas a la misma clase de emisiones vocales. Prueba se refiere al procedimiento para aparear las plantillas del modelo acústico con una secuencia de vectores de características extraídos de la voz de entrada. Las prestaciones de un sistema dado dependen en gran medida del grado de coincidencia entre la voz de entrada del usuario final y el contenido de la base de datos, y por ello de la coincidencia entre las plantillas de referencia creadas a través del entrenamiento y las muestras de voz usadas para la prueba de VR. Los dos tipos comunes de entrenamiento son el entrenamiento supervisado y el entrenamiento no supervisado. En el entrenamiento supervisado, la clase de emisión vocal asociada a cada conjunto de vectores de características de entrenamiento se conoce a priori. Al hablante que proporciona la voz de entrada a menudo se le proporciona un guión de palabras o segmentos de voz correspondientes a las clases de emisión vocal predeterminadas. Los vectores de características resultantes de la lectura del guión pueden ser incorporados entonces en las plantillas del modelo acústico asociado a las clases de emisiones vocales correctas. En el entrenamiento no supervisado, la clase de emisión vocal asociada a un conjunto de vectores de características de entrenamiento no se conoce a priori. La clase de emisión vocal debe ser identificada de manera correcta antes de que se pueda incorporar un conjunto de vectores de características de entrenamiento en la plantilla correcta del modelo acústico. En el entrenamiento no supervisado, un error al identificar la clase de emisión vocal para un conjunto de vectores de características de entrenamiento puede conducir a una modificación de la plantilla del modelo acústico erróneo. Dicho error por lo general degrada, en lugar de mejorar, el funcionamiento del reconocimiento de la voz. Con el fin de evitar dichos errores, cualquier modificación del modelo acústico basada en el entrenamiento no supervisado se debe hacer por lo general de una manera muy conservadora. Se incorpora un conjunto de vectores de características de entrenamiento en el modelo acústico solamente si hay una confianza relativamente alta de que la clase de emisión vocal se ha identificado de manera correcta. Dicho conservadurismo necesario hace que la construcción de un modelo acústico SD a través de un entrenamiento no supervisado sea un proceso muy lento. Hasta que se construya de esta manera el modelo acústico SD, las prestaciones de la VR probablemente serán inaceptables para la mayoría de los usuarios. De manera óptima, el usuario final proporciona vectores de características acústicas de voz tanto durante el 2 E07014802 03-11-2011 entrenamiento como durante la prueba, de forma que el modelo acústico 112 coincidirá notablemente con la voz del usuario final. Un modelo acústico individualizado que esté personalizado para un único hablante también se denomina un modelo acústico dependiente del orador (SD). La generación de un modelo acústico SD por lo general requiere que el usuario final proporcione una gran cantidad de muestras de entrenamiento supervisadas. Primero, el usuario debe proporcionar muestras de entrenamiento para una gran variedad de clases de formas de habla. Además, con el fin de conseguir las mejores prestaciones, el usuario final debe proporcionar múltiples plantillas, que representen una variedad de posibles entornos acústicos para cada clase de emisión vocal. Debido a que la mayoría de los usuarios son incapaces o están poco dispuestos a proporcionar la voz de entrada necesaria para generar un modelo acústico SD, muchos sistemas de VR existentes, en lugar de esto, usan modelos acústicos generalizados que están entrenados usando la voz de muchos hablantes representativos. Se hace referencia a dichos modelos acústicos como modelos acústicos independientes del orador (SI), y están diseñados para tener las mejores prestaciones sobre una amplia gama de usuarios. Los modelos acústicos SI, sin embargo, pueden no estar optimizados para cualquier usuario único. Un sistema de VR que use un modelo acústico SI no funcionará tan bien para un usuario específico como un sistema de VR que use un modelo acústico SD personalizado para ese usuario. Para algunos usuarios, tales como los que tienen fuertes acentos extranjeros, las prestaciones de un sistema de VR que use un modelo acústico SI pueden ser tan pobres que no puedan usar de manera efectiva los servicios de VR en absoluto. De manera óptima, un modelo acústico SD sería generado para cada usuario independiente. Como se ha expuesto con anterioridad, la construcción de modelos acústicos SD que usen entrenamiento supervisado no es práctica. Pero el uso de entrenamiento no supervisado para generar un modelo acústico SD puede llevar mucho tiempo, durante el que las prestaciones de VR basadas en un modelo acústico SD parcial pueden ser muy pobres. Existe una necesidad en la técnica de un sistema de VR que funcione razonablemente bien antes y durante la generación de un modelo acústico SD usando el entrenamiento no supervisado. Se reclama atención al documento EP-A-1 011 094, que se refiere a un procedimiento para... [Seguir leyendo]
Reivindicaciones:
1. Un procedimiento para realizar el reconocimiento de voz que comprende: realizar el apareo de patrones de un primer segmento de voz de entrada con al menos una primera plantilla acústica de un modelo acústico (230, 232) independiente del orador, para producir al menos una plantilla de apareo de patrones de entrada y para determinar una clase de emisión vocal reconocida, en el cual la clase de emisión vocal es una palabra o segmento de habla específico; comparar dicha(s) plantilla(s) de apareo de patrones de entrada con una plantilla correspondiente asociada a al menos una segunda plantilla acústica proveniente del modelo acústico (234) del orador de la primera voz de entrada, la segunda plantilla acústica asociada a la clase de emisión vocal reconocida; y determinar si se actualiza o no dicha(s) segunda(s) plantilla(s) acústica(s), en donde dicha(s) segunda(s) plantilla(s) acústica(s) se actualiza(n) si dicha(s) plantilla(s) de apareo de patrones de entrada es (son) mejor(es) que la correspondiente plantilla asociada a dicha(s) segunda(s) plantilla(s) acústica(s). 2. El procedimiento de la reivindicación 1, en el cual la realización del apareo de patrones comprende adicionalmente: realizar el apareo de patrones (230) del modelo oculto de Markov (HMM) del primer segmento de voz de entrada con al menos una plantilla HMM, para generar al menos una plantilla HMM de apareo; realizar el apareo de patrones (232) de la distorsión dinámica en el tiempo (DTW) con al menos una plantilla de DTW, para generar al menos una plantilla de apareo DTW; y realizar al menos una suma ponderada de al menos una plantilla de apareo HMM y al menos una plantilla de apareo DTW para generar al menos una plantilla de apareo del patrón de entrada. 3. El procedimiento de la reivindicación 1, que comprende adicionalmente: generar al menos una plantilla de apareo independiente del orador, realizando el apareo de patrones de un segundo segmento de voz de entrada con al menos una primera plantilla acústica, en donde al menos dicha primera plantilla acústica es independiente del orador; generar al menos una plantilla de apareo dependiente del orador, realizando el apareo de patrones de un segundo segmento de voz de entrada con al menos dicha segunda plantilla acústica, en donde dicha al menos una plantilla acústica es dependiente del orador; y combinar dicha al menos una plantilla de apareo independiente del orador con dicha al menos una plantilla de apareo dependiente del orador para generar al menos una plantilla de apareo combinada. 4. El procedimiento de la reivindicación 3, que comprende adicionalmente identificar la clase de emisión vocal asociada a la mejor entre dicha(s) plantilla(s) de apareo combinada(s). 5. El procedimiento de la reivindicación 1, en el cual el procedimiento es adicionalmente para realizar el entrenamiento y prueba del reconocimiento de voz sin supervisión, que comprende: realizar en un motor (220) de reconocimiento de voz el apareo de patrones de la voz de entrada de un orador con el contenido de un modelo acústico (230, 232) independiente del orador, para producir plantillas de apareo de patrones independientes del orador; comparar las plantillas de apareo de patrones independientes del orador con plantillas asociadas a plantillas de un modelo acústico (234) dependiente del orador por el motor (220) de reconocimiento de voz, en donde el modelo acústico dependiente del orador está personalizado para el orador; y si las plantillas de apareo de patrones independientes del orador son mejores que las plantillas asociadas a plantillas del modelo acústico (234) dependiente del orador, generar una nueva plantilla para el modelo acústico (234) dependiente del orador, en base a las plantillas de apareo del patrón independiente del orador. 6. El procedimiento de la reivindicación 5, en el cual el modelo acústico (230, 232) independiente del orador comprende al menos un modelo acústico del modelo oculto de Markov (HMM). 7. El procedimiento de la reivindicación 5, en el cual el modelo acústico (230, 232) independiente del orador comprende al menos un modelo acústico de distorsión dinámica en el tiempo (DTW). 8. El procedimiento de la reivindicación 5, en el cual el modelo acústico (230, 232) independiente del orador comprende al menos un modelo acústico del modelo oculto de Markov (HMM) y al menos un modelo acústico de distorsión dinámica en el tiempo (DTW). 9. El procedimiento de la reivindicación 5, en el cual el modelo acústico (230, 232) independiente del orador incluye al menos una plantilla de información inservible, en donde la comparación incluye comparar la voz de entrada con dicha al menos una plantilla de información inservible. 10. El procedimiento de la reivindicación 5, en el cual el modelo acústico (234) dependiente del orador comprende al menos un modelo acústico de distorsión dinámica en el tiempo (DTW). 9 E07014802 03-11-2011 11. El procedimiento de la reivindicación 5, que comprende adicionalmente: configurar el motor (220) de reconocimiento de voz para comparar un segundo segmento de voz de entrada con el contenido del modelo acústico independiente del orador y el modelo acústico dependiente del orador, para generar al menos una plantilla de apareo combinada, dependiente del orador e independiente del orador, e identificar una clase de emisión vocal con la mejor plantilla combinada de apareo dependiente del orador e independiente del orador. 12. El procedimiento de la reivindicación 11, en el cual el modelo acústico (230, 232) independiente del orador comprende al menos un modelo acústico (230) del modelo oculto de Markov (HMM). 13. El procedimiento de la reivindicación 11, en el cual el modelo acústico (230, 232) independiente del orador comprende al menos un modelo acústico (232) de distorsión dinámica en el tiempo (DTW). 14. El procedimiento de la reivindicación 11, en el cual el modelo acústico (230, 232) independiente del orador comprende al menos un modelo acústico (230) del modelo oculto de Markov (HMM) y al menos un modelo acústico (232) de distorsión dinámica del tiempo (DTW). 15. El procedimiento de la reivindicación 11, en el cual el modelo acústico (234) dependiente del orador comprende al menos un modelo acústico de distorsión dinámica del tiempo (DTW). 16. El procedimiento de la reivindicación 1, que comprende adicionalmente: realizar el apareo de patrones del segmento de voz de entrada con una plantilla acústica dependiente del orador, para generar al menos una plantilla de apareo dependiente del orador; y combinar dicha al menos una plantilla de apareo independiente del orador con dicha al menos una plantilla de apareo dependiente del orador para generar al menos una plantilla de apareo combinada, en donde cada plantilla de apareo combinada corresponde a una clase de emisión vocal y depende de la plantilla de apareo del patrón independiente del orador para la clase de emisión vocal, y de la plantilla de apareo del patrón dependiente del orador para la clase de emisión vocal. 17. El procedimiento de la reivindicación 1, en el cual la etapa de realizar y la etapa de combinar son llevadas a cabo por un motor (220) de reconocimiento de voz. 18. Un producto de programa de ordenador que comprende instrucciones que, cuando son ejecutadas por un procesador, causan que el procesador realice un procedimiento de cualquiera de las reivindicaciones 1 a 17. E07014802 03-11-2011 11 E07014802 03-11-2011 12 E07014802 03-11-2011 13 E07014802 03-11-2011 14 E07014802 03-11-2011 E07014802 03-11-2011 16 E07014802 03-11-2011
Patentes similares o relacionadas:
SISTEMA DE RECONOCIMIENTO DE VOZ QUE USA ADAPTACION IMPLICITA DEL QUE HABLA, del 16 de Diciembre de 2009, de QUALCOMM INCORPORATED: Un procedimiento para realizar un entrenamiento no supervisado para el reconocimiento de voz, que comprende: la realización de la casación de un patrón […]
SISTEMA DE RECONOCIMIENTO QUE UTILIZA ARBOLES LEXICOS., del 1 de Septiembre de 2005, de MATSUSHITA ELECTRIC INDUSTRIAL CO., LTD.: Sistema de procesamiento dinámico, que comprende una estructura de datos en árbol implementada en una memoria legible por ordenador, accesible […]
PROCEDIMIENTO Y APARATO PARA DETERMINAR UNA MEDIDA DE LA COMPATIBILIDAD ENTRE DOS MUESTRAS, ASI COMO DISPOSITIVO DE RECONOCIMIENTO DE LA VOZ Y MODULO DE PROGRAMA PARA EL MISMO., del , de ALCATEL SEL AKTIENGESELLSCHAFT ALCATEL N.V.: DOS MUESTRAS SE CONFIGURAN A PARTIR DE VECTORES DE CARACTERISTICAS, QUE SE SUJETAN EN UNA MATRIZ. PARA CADA PUNTO DE ESTA MATRIZ DEBEN SER EJECUTADOS CALCULOS COSTOSOS […]
SISTEMA DE RECONOCIMIENTO DE LA VOZ QUE USA ADAPTACION IMPLICITA DEL HABLANTE, del 16 de Enero de 2008, de QUALCOMM INCORPORATED: Un aparato de reconocimiento de la voz que comprende: un modelo acústico independiente del hablante; un modelo acústico dependiente del hablante que está […]
METODO PARA COMPRIMIR DATOS DE DICCIONARIO, del 16 de Noviembre de 2007, de NOKIA CORPORATION: Método para preprocesar un diccionario de pronunciación con vistas a su compresión en un dispositivo de procesado de datos, comprendiendo el diccionario de pronunciación […]
SISTEMA DE IDENTIFICACIÓN DE SONIDOS MEDIANTE CLASIFICACIÓN PARAMÉTRICA DE SERIES DERIVADAS, del 17 de Mayo de 2018, de UNIVERSIDAD DE SEVILLA: La presente invención tiene por objeto un sistema de identificación de sonidos que se basa en la descripción y selección de unos pocos parámetros […]
Sistema de identificación de sonidos mediante clasificación paramétrica de series derivadas, del 11 de Mayo de 2018, de UNIVERSIDAD DE SEVILLA: La presente invención tiene por objeto un sistema de identificación de sonidos que se basa en la descripción y selección de unos pocos parámetros […]
Procedimiento y dispositivo para generar una huella digital y procedimiento y dispositivo para identificar una señal de audio, del 15 de Junio de 2012, de M2ANY GMBH: Procedimiento para generar una huella digital de una señal de audio utilizando información de modo, que define una pluralidad de modos de huella […]
Utilizamos cookies para mejorar nuestros servicios y mostrarle publicidad relevante. Si continua navegando, consideramos que acepta su uso. Puede obtener más información aquí. .
 SISTEMA DE RECONOCIMIENTO DE VOZ QUE USA ADAPTACION IMPLICITA DEL QUE HABLA, del 16 de Diciembre de 2009, de QUALCOMM INCORPORATED: Un procedimiento para realizar un entrenamiento no supervisado para el reconocimiento de voz, que comprende: la realización de la casación de un patrón […]
SISTEMA DE RECONOCIMIENTO DE VOZ QUE USA ADAPTACION IMPLICITA DEL QUE HABLA, del 16 de Diciembre de 2009, de QUALCOMM INCORPORATED: Un procedimiento para realizar un entrenamiento no supervisado para el reconocimiento de voz, que comprende: la realización de la casación de un patrón […]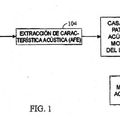 SISTEMA DE RECONOCIMIENTO DE LA VOZ QUE USA ADAPTACION IMPLICITA DEL HABLANTE, del 16 de Enero de 2008, de QUALCOMM INCORPORATED: Un aparato de reconocimiento de la voz que comprende: un modelo acústico independiente del hablante; un modelo acústico dependiente del hablante que está […]
SISTEMA DE RECONOCIMIENTO DE LA VOZ QUE USA ADAPTACION IMPLICITA DEL HABLANTE, del 16 de Enero de 2008, de QUALCOMM INCORPORATED: Un aparato de reconocimiento de la voz que comprende: un modelo acústico independiente del hablante; un modelo acústico dependiente del hablante que está […] METODO PARA COMPRIMIR DATOS DE DICCIONARIO, del 16 de Noviembre de 2007, de NOKIA CORPORATION: Método para preprocesar un diccionario de pronunciación con vistas a su compresión en un dispositivo de procesado de datos, comprendiendo el diccionario de pronunciación […]
METODO PARA COMPRIMIR DATOS DE DICCIONARIO, del 16 de Noviembre de 2007, de NOKIA CORPORATION: Método para preprocesar un diccionario de pronunciación con vistas a su compresión en un dispositivo de procesado de datos, comprendiendo el diccionario de pronunciación […] Procedimiento y dispositivo para generar una huella digital y procedimiento y dispositivo para identificar una señal de audio, del 15 de Junio de 2012, de M2ANY GMBH: Procedimiento para generar una huella digital de una señal de audio utilizando información de modo, que define una pluralidad de modos de huella […]
Procedimiento y dispositivo para generar una huella digital y procedimiento y dispositivo para identificar una señal de audio, del 15 de Junio de 2012, de M2ANY GMBH: Procedimiento para generar una huella digital de una señal de audio utilizando información de modo, que define una pluralidad de modos de huella […]