MÉTODO, SISTEMA Y ENCAMINADOR DE EVITACIÓN DE BLOQUEOS EN UNA RED DE INTERCONEXIÓN.
Método, sistema y encaminador de evitación de bloqueos en una red de interconexión.
#El método comprende:#a) detectar una situación propensa a un bloqueo; e#b) identificar un ciclo de encaminamiento involucrado en la situación propensa a un bloqueo detectada, mediante la realización de las siguientes sub-etapas por parte de un encaminador (r{sup,i}), mediante un mecanismo de búsqueda asíncrono intra-encaminador e inter-encaminadores que no requiere del uso de temporizadores:#b1) componer y enviar un mensaje de identificación desde un búfer de entrada (a{sup,i}{sub,j}) del encaminador (r{sub,i}) a un búfer de salida (b{sup,h}{sub,k}) de otro encaminador (r{sup,h}); y#b2) recibir el mensaje de identificación en el búfer de salida (b{sup,h}{sub,k}) asociado a dicho búfer de entrada (a{sup,i}{sub,j}) del encaminador (r{sup,i}) que lo compuso, tras su retransmisión por parte de cómo mínimo otro encaminador (r{sup,h}) desde un búfer de entrada (a{sup,i}{sub,j}) del mismo.#El sistema y el encaminador están adaptados para implementar el método propuesto por la invención.
Tipo: Patente de Invención. Resumen de patente/invención. Número de Solicitud: P201101048.
Solicitante: UNIVERSITAT AUTONOMA DE BARCELONA.
Nacionalidad solicitante: España.
Inventor/es: ZARZA,GONZALO, LUGONES,DIEGO, FRANCO PUNTES,DANIEL, LUQUE FADÓN,EMILIO.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G06F11/34 FISICA. › G06 CALCULO; CONTEO. › G06F PROCESAMIENTO ELECTRICO DE DATOS DIGITALES (sistemas de computadores basados en modelos de cálculo específicos G06N). › G06F 11/00 Detección de errores; Corrección de errores; Monitorización (detección, corrección o monitorización de errores en el almacenamiento de información basado en el movimiento relativo entre el soporte de registro y el transductor G11B 20/18; monitorización, es decir, supervisión del progreso del registro o reproducción G11B 27/36; en memorias estáticas G11C 29/00). › Registro o evaluación estática de la actividad del computador, p. ej. de las interrupciones o de las operaciones de entrada-salida.
Fragmento de la descripción:
Método, sistema y encaminador de evitación de bloqueos en una red de interconexión.
Sector de la técnica
La presente invención concierne en general, en un primer aspecto, a un método de evitación de bloqueos en una red de interconexión basado en la identificación de ciclos de encaminamiento involucrados en situaciones propensas a un bloqueo, y más particularmente a un método que comprende llevar a cabo dicha identificación mediante un mecanismo que no requiere del uso de temporizadores.
La invención pertenece al ámbito de las redes de interconexión de computadores paralelos y se centra en el área de tolerancia a fallos para redes de interconexión de alta velocidad.
El objeto de la presente invención es identificar ciclos de dependencias de recursos en redes de interconexión de alta velocidad de forma asíncrona intra-encaminador e inter-encaminadores. La identificación tiene como finalidad evitar que la ocurrencia de fallos en los dispositivos de red generen situaciones de bloqueo en la red de interconexión, permitiendo así la finalización de las aplicaciones que se encuentren en ejecución en el computador paralelo.
Un segundo aspecto de la invención concierne a un sistema de evitación de bloqueos en una red de interconexión adaptado para implementar el método del primer aspecto.
Un tercer aspecto de la invención concierne a un encaminador previsto para la implementación del método del primer aspecto de la invención.
Estado de la técnica anterior
El rendimiento de los sistemas de cómputo paralelo de última generación se encuentra íntimamente relacionado con las prestaciones de la red de interconexión que comunica sus elementos de cómputo. Esta interrelación confiere vital importancia a los mecanismos de tolerancia a fallos de la red de interconexión ya que, en última instancia, es la red la que permite el funcionamiento de dichos computadores como entidades coherentes y cohesionadas.
Ante estas circunstancias, la ocurrencia de tan solo un fallo de red es capaz de generar anomalías potencialmente dañinas en el sistema de cómputo, e impedir la correcta finalización de las aplicaciones que se encuentren en ejecución en dicho sistema. De entre estas anomalías, los escenarios de bloqueos, "deadlocks", son quizás los de mayor probabilidad de ocurrencia debido a que la mayor parte de los sistemas de cómputo actuales utilizan algoritmos de encaminamiento que no fueron diseñados para tolerar fallos (situación que incrementa la probabilidad de aparición de bloqueos en dichos sistemas). Este problema se vuelve crítico en situaciones en las que el sistema de cómputo debe lidiar con fallos que aparecen aleatoriamente, es decir con fallos dinámicos. Algunos ejemplos pueden ser los sistemas de transacciones bancarias o los sistemas utilizados para estudios geológicos y de catástrofes naturales, entre otros.
En el contexto de las redes de interconexión, los bloqueos se producen cuando al menos un mensaje no puede llegar a destino, debido a que en su trayecto solicita recursos que no se encuentran disponibles, más específicamente, espacio de almacenamiento en la cola de un dispositivo de red. Esta situación tiene como resultado el bloqueo total del sistema debido a que los mensajes no liberan los recursos que necesitan otros mensajes, mientras solicitan recursos que se encuentran en posesión de otros mensajes. Esto lleva a que un grupo de mensajes se bloque de forma permanente, provocando que todo el sistema de cómputo quede fuera de servicio. Desafortunadamente, la aparición de bloqueos es frecuente en las situaciones en las que fallan uno o más dispositivos de red. Esto se debe a que incluso un número relativamente bajo de fallos puede generar dependencias cíclicas de recursos, derivadas de los cambios en las características de la red, principalmente en la topología.
Durante las últimas décadas, varios autores han propuesto soluciones al problema de los bloqueos en las redes de interconexión, entre las que se encuentran: limitar la inyección de mensajes en la red [1], [2]; utilizar canales virtuales [3], [4]; y modificar los dispositivos de red y algoritmos de encaminamiento [5], [6], [7], Desafortunadamente, todas las soluciones propuestas hasta el momento han sido diseñadas para evitar bloqueos en redes libres de fallos, por lo que su aplicabilidad en el ámbito de la tolerancia a fallos es muy reducida.
La presencia de fallos en la red causa que la gran mayoría -por no decir todos- los mecanismos de evitación de bloqueos actuales se vean seriamente afectados y limitados, llegando incluso a no ser efectivos. Dichas limitaciones se relacionan con aspectos importantes de la teoría general de la tolerancia a fallos, tales como el momento y la forma de aparición de los fallos, el número de fallos a tolerar, la duración de los fallos, las características de los sistemas utilizados, etc.
El modo en que se da el fallo es el aspecto más importante a tener en cuenta debido a que se encuentra íntimamente relacionado con la aplicabilidad e idoneidad de las técnicas de evitación de bloqueos. Si se asume un modo de fallos estático, es indispensable conocer de antemano la ubicación de dichos fallos en la red. En contraste, al asumir un modo de fallos dinámico, los fallos aparecen en tiempos y localizaciones aleatorias durante la ejecución del sistema. El modelo de fallos estático permite implementar soluciones más simples pero el modelo de fallos dinámico plasma de forma fidedigna el comportamiento de los fallos en los sistemas de cómputo reales.
Si se utilizan los algoritmos de encaminamiento más simples, los basados en el modo de fallos estático, resulta imposible evitar fallos dinámicos debido a que dichos algoritmos no permiten (por sí mismos) la utilización de caminos alternativos y adaptativos. En contraste, los algoritmos de encaminamiento más complejos, los adaptativos, permiten utilizar caminos alternativos para la evitación de fallos. Aun así, pese a perfilarse como una solución muy prometedora, desde el punto de vista de la tolerancia a fallos, el enfoque de los algoritmos adaptativos presenta un nuevo e importante problema: la aparición de bloqueos o "deadlocks". Este problema se vuelve crítico en situaciones en las que el sistema de cómputo debe lidiar con fallos que aparecen aleatoriamente a lo largo de la ejecución del sistema, es decir, con fallos dinámicos.
Actualmente, la gran mayoría de las técnicas de evitación de bloqueos capaces de tolerar fallos en redes de interconexión utilizan canales virtuales para romper las dependencias cíclicas de recursos entre los mensajes. El uso de canales virtuales limita la escalabilidad de dichas técnicas debido a que el número de canales virtuales necesarios es directamente proporcional al número de fallos a tolerar. Por este motivo, la mayor parte de las técnicas propuestas se basan en modelos de fallos estáticos, a fin de reducir el número de canales virtuales requeridos. Otro grupo de técnicas comúnmente utilizadas se basa en el concepto de limitar la inyección de paquetes, evitando el acaparamiento los recursos de la red a fin de evitar las situaciones de bloqueo indefinidas. Sin embargo, estas técnicas son útiles para algoritmos de encaminamiento basados en la utilización de caminos mínimos, lo que dificulta o simplemente imposibilita tolerar un número medio o alto de fallos. Prácticamente todos estos métodos y técnicas de evitación de bloqueos se basan en diferentes tipos de mecanismos de identificación de ciclos. Desafortunadamente, la mayoría de estos métodos fueron diseñados para operar en ausencia de fallos, por lo que se vuelven inaplicables ante la ocurrencia de fallos de red.
Desde el punto de vista del estado de la técnica, el antecedente más cercano a la invención aquí propuesta es un mecanismo de evitación de bloqueos de tres etapas, denominado "Non-blocking Adaptive Cycles" (NAC), propuesto por los autores de la presente invención en [8] y [9]. A partir de la explicación del método y su entorno de aplicación, es posible inferir de forma directa que el método NAC presenta una serie de problemas de sincronización que limitan su aplicación en redes de interconexión de alta velocidad. Más concretamente, NAC utiliza un mecanismo de identificación de ciclos de tipo "best effort", que se aplica paso a paso de forma serial y está basado en el control de los ciclos de reloj de los encaminadores para intentar evitar las situaciones conocidas como "falsos negativos". Es decir, el método utiliza los relojes de los...
Reivindicaciones:
1. Método de evitación de bloqueos en una red de interconexión, que comprende realizar secuencialmente las siguientes etapas:
a) detectar al menos una situación propensa a un bloqueo; e
b) identificar al menos un ciclo de encaminamiento involucrado en dicha situación propensa a un bloqueo detectada, mediante la realización de las siguientes sub-etapas por parte de un encaminador (ri) de dicha red de interconexión:
estando el método caracterizado porque comprende realizar dicha etapa b) mediante un mecanismo de búsqueda asíncrono intra-encaminador e inter-encaminadores que no requiere del uso de temporizadores.
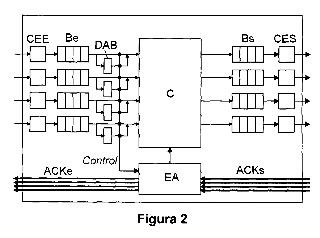
2. Método según la reivindicación 1, caracterizado porque, para identificar una pluralidad de ciclos de encaminamiento involucrados en situaciones propensas a un bloqueo, el método comprende realizar, en paralelo, una pluralidad de etapas b) por parte de dicho encaminador (ri), iniciadas mediante una correspondiente pluralidad de sub-etapas b1) de composición y envío, en paralelo, de una pluralidad de dichos mensajes de identificación desde unos respectivos búferes de entrada (ai1, ai2, ai3, ai4), y finalizadas mediante una correspondiente pluralidad de etapas b2) de recepción de dichos mensajes de identificación en el búfer de salida (bi1, bi2, bi3, bi4) asociado a dicho búfer de entrada (ai1, ai2, ai3, ai4) de dicho encaminador (ri).
3. Método según una cualquiera de las reivindicaciones anteriores, caracterizado porque dicho mecanismo de búsqueda asíncrono intra-encaminador e inter-encaminadores es un mecanismo de búsqueda en amplitud.
4. Método según una cualquiera de las reivindicaciones anteriores, caracterizado porque dicho mensaje de identificación incluye por lo menos información referente al identificador del encaminador (ri) que lo creó, a la identificación del búfer de entrada (aij) por el que se envió y al identificador del búfer de salida (bik) por el que se debería recibir el mensaje de identificación si es parte del ciclo de encaminamiento.
5. Método según una cualquiera de las reivindicaciones anteriores, caracterizado porque dicha etapa a) comprende evaluar localmente en cada búfer de entrada (ai1, ai2, ai3, ai4) de dicho encaminador (ri) unas condiciones de funcionamiento cuyo cumplimiento establece que el encaminador (ri) se encuentra en un estado previo a una situación de bloqueo, que es interpretado como dicha detección de una situación propensa a un bloqueo.
6. Método según la reivindicación 5, caracterizado porque comprende, por parte de al menos dicho otro encaminador (rh), llevar a cabo dicha etapa a) para sus búferes de entrada (ah1, ah2, ah3, ah4) y realizar dicha retransmisión del mensaje o mensajes de identificación recibidos a través del búfer o búferes de entrada (ah1, ah2, ah3, ah4) donde se cumplan dichas condiciones de funcionamiento.
7. Método según la reivindicación 6, caracterizado porque comprende realizar dicha retransmisión del mensaje o mensajes de identificación a través de una pluralidad de encaminadores (rh, ry, rz, rm), por sus búferes de entrada que cumplan con dichas condiciones de funcionamiento, antes de ser recibido o recibidos, en dicha sub-etapa b2), en el búfer o búferes de salida (bik) de dicho encaminador (ri) que compuso el mensaje o mensajes de identificación enviados.
8. Método según la reivindicación 5, caracterizado porque dicha condiciones de funcionamiento describen una situación en la que un búfer de entrada (aij) de un encaminador (ri) no posee espacio de almacenamiento disponible e intenta escoger como próximo paso un búfer de salida (bik), del mismo encaminador (ri), que tampoco posee espacio disponible y se encuentra físicamente enlazado con el búfer de entrada (amj) de otro encaminador (rm) que tampoco tiene espacio disponible.
9. Método según una cualquiera de las reivindicaciones anteriores, caracterizado porque comprende al menos iniciar una correspondiente sub-etapa b1) por parte de al menos dicho otro encaminador (rh) o de al menos un encaminador de dicha pluralidad de encaminadores (rh, rm), durante la realización de la etapa b) por parte de dicho encaminador (ri).
10. Método según una cualquiera de las reivindicaciones anteriores, caracterizado porque comprende, tras identificar un ciclo de encaminamiento en dicha etapa b) asociado a un búfer de entrada (aij) y uno de salida (bik) de dicho encaminador (ri), liberar un espacio en dicho búfer de entrada (aij) moviendo un primer mensaje de dicho búfer de entrada (aij) a un búfer de evitación de bloqueos (dij) unido al mismo fuera de su camino crítico.
11. Método según la reivindicación 10, caracterizado porque comprende, tras dicha liberación de un espacio en el búfer de entrada (aij) de dicho encaminador (ri), iniciar un protocolo de recuperación gradual de movimiento de mensajes que garantice el movimiento de mensajes en dicho ciclo de encaminamiento identificado en la etapa b).
12. Método según la reivindicación 11, caracterizado porque comprende iniciar una pluralidad de dichos protocolos de recuperación gradual de movimiento de mensajes, en paralelo, para una correspondiente pluralidad de ciclos de encaminamiento identificados en la etapa b).
13. Sistema de evitación de bloqueos en una red de interconexión, caracterizado porque comprende al menos dos encaminadores (ri, rh) previstos para la implementación del método según una cualquiera de las reivindicaciones anteriores, con unos búferes de entrada (aij, ahj), unos búferes de salida (bik, bhk) y una unidad de control apta para realizar dicha detección de dicha etapa a) y dicha identificación de dicha etapa b).
14. Sistema según la reivindicación 13, caracterizado porque al menos uno (ri) de dichos dos encaminadores (ri, rh) comprende un búfer de evitación de bloqueos (dij) unido a un búfer de entrada (aij) del mismo fuera de su camino crítico, estando su unidad de control prevista para implementar el método según la reivindicación 9 para realizar dicha liberación de un espacio en dicho búfer de entrada (aij).
15. Sistema según la reivindicación 14, caracterizado porque dicha unidad de control está prevista para ejecutar al menos un protocolo de recuperación gradual de movimiento de mensajes mediante la implementación del método según la reivindicación 11 ó 12.
16. Encaminador de evitación de bloqueos en una red de interconexión, caracterizado porque está previsto para la implementación del método según una cualquiera de las reivindicaciones 1 a 12, comprendiendo unos búferes de entrada (aij), unos búferes de salida (bik) y una unidad de control apta para realizar dicha detección de dicha etapa a) y dicha identificación de dicha etapa b).
17. Encaminador según la reivindicación 16, caracterizado porque comprende un búfer de evitación de bloqueos (dij) unido a un búfer de entrada (aij) del mismo fuera de su camino crítico, estando dicha unidad de control prevista para implementar el método según la reivindicación 10 para realizar dicha liberación de un espacio en dicho búfer de entrada (aij).
18. Encaminador según la reivindicación 17, caracterizado porque dicha unidad de control está prevista para ejecutar al menos un protocolo de recuperación gradual de movimiento de mensajes mediante la implementación del método según la reivindicación 11 ó 12.
Patentes similares o relacionadas:
Procedimiento de gestión de módulos de software integrados para una computadora electrónica de un dispositivo de conmutación eléctrica, del 17 de Junio de 2020, de SCHNEIDER ELECTRIC INDUSTRIES SAS: Procedimiento de gestión de módulos de software integrados para una computadora electrónica integrada de un dispositivo eléctrico de conmutación de […]
Restauración de aceleración de servicio, del 10 de Junio de 2020, de Microsoft Technology Licensing, LLC: Un método para restaurar la aceleración del servicio para un servicio, el método que comprende: determinar que la aceleración del servicio para el […]
Aparato, sistema y método para procesar datos de registro de aplicaciones, del 3 de Junio de 2020, de LSIS Co., Ltd: Un sistema de procesamiento de datos de registro que comprende: un dispositivo de control de supervisión que se configura para ejecutar una aplicación y generar […]
Método y dispositivo para procesar información de llamadas de servicio, del 20 de Mayo de 2020, de Advanced New Technologies Co., Ltd: Un método para procesar una cadena de llamadas de servicio, el método que comprende: adquirir una o más cadenas de llamadas de servicio […]
Un método y sistema para modelado de tareas de aplicaciones de teléfono móvil, del 1 de Enero de 2020, de DEUTSCHE TELEKOM AG: Un sistema para determinar el uso y ayudar en la operación de aplicaciones secuenciales interactivas que se ejecutan en uno o más dispositivos móviles, que comprende: […]
Procedimiento de supervisión del rendimiento de una aplicación de software, del 13 de Noviembre de 2019, de Actual Experience PLC: Procedimiento de supervisión del nivel de rendimiento de una aplicación de software que se ejecuta en un dispositivo informático conectado a una red de ordenadores y […]
 Control de utilización de red, del 30 de Octubre de 2019, de Microsoft Technology Licensing, LLC: Un procedimiento de especificación y asignación de ancho de banda de red para aplicaciones distribuidas que se ejecutan en una red en máquinas (114; […]
Control de utilización de red, del 30 de Octubre de 2019, de Microsoft Technology Licensing, LLC: Un procedimiento de especificación y asignación de ancho de banda de red para aplicaciones distribuidas que se ejecutan en una red en máquinas (114; […]
Notificación de instrumentación en tiempo de ejecución, del 21 de Agosto de 2019, de INTERNATIONAL BUSINESS MACHINES CORPORATION: Un procedimiento implementado por ordenador para la notificación de instrumentación en tiempo de ejecución, el procedimiento que comprende: ejecutar […]