PROCEDIMIENTO ADAPTATIVO AL USUARIO PARA LA MODELIZACION DE RUIDOS.
Procedimiento para el reconocimiento de voz con un banco de datos con varios perfiles de ruido de fondo,
que representan distintos fondos de ruido,
- en el que cuando en el banco de datos se encuentra un perfil de ruido de fondo adecuado como modelo de ruido para el fondo de ruido actual, se elige este perfil de ruido de fondo y se realiza el reconocimiento de voz teniendo en cuenta el perfil de ruido de fondo,
- en el que cuando en el banco de datos no se encuentra ningún perfil de ruido de fondo adecuado como modelo de ruido para el actual fondo de ruido, se confecciona un perfil de ruido de fondo para este fondo de ruido y el reconocimiento de voz se realiza considerando el perfil de ruido de fondo confeccionado
Tipo: Patente Europea. Resumen de patente/invención. Número de Solicitud: E04100134.
Solicitante: SIEMENS AKTIENGESELLSCHAFT.
Nacionalidad solicitante: Alemania.
Dirección: WITTELSBACHERPLATZ 2,80333 MUNCHEN.
Inventor/es: MAJOR, ANDREAS RALPH, SCHRIER,ANDREAS.
Fecha de Publicación: .
Fecha Solicitud PCT: 16 de Enero de 2004.
Fecha Concesión Europea: 24 de Febrero de 2010.
Clasificación Internacional de Patentes:
- G10L15/20 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › G10L 15/00 Reconocimiento de la voz (G10L 17/00 tiene prioridad). › Técnicas de reconocimiento de la voz especialmente adaptadas para trabajar en ambientes adversos, p. ej. en presencia de ruido o para voz emitida en situaciones de estrés (G10L 21/02 tiene prioridad).
Clasificación PCT:
- G10L15/20 G10L 15/00 […] › Técnicas de reconocimiento de la voz especialmente adaptadas para trabajar en ambientes adversos, p. ej. en presencia de ruido o para voz emitida en situaciones de estrés (G10L 21/02 tiene prioridad).
Clasificación antigua:
- G10L15/20 G10L 15/00 […] › Técnicas de reconocimiento de la voz especialmente adaptadas para trabajar en ambientes adversos, p. ej. en presencia de ruido o para voz emitida en situaciones de estrés (G10L 21/02 tiene prioridad).
Países PCT: Austria, Bélgica, Suiza, Alemania, Dinamarca, España, Francia, Reino Unido, Grecia, Italia, Liechtensein, Luxemburgo, Países Bajos, Suecia, Mónaco, Portugal, Irlanda, Eslovenia, Finlandia, Rumania, Chipre, Lituania, Letonia, Ex República Yugoslava de Macedonia, Albania.
Fragmento de la descripción:
Procedimiento adaptivo al usuario para la modelización de ruidos.
Los procedimientos técnicos para reconocer la voz humana se utilizan hoy día en múltiples aparatos móviles como por ejemplo teléfonos móviles, asistentes personales digitales (Personal Digital Assistants, PDAs) y wearables o portables (reproductor MP3, terminales móviles-relojes, etc.). Al respecto se utiliza entre otros un reconocimiento de voz independiente del orador basado en la modelización Hidden-Markov (HMM) de los fonemas (o de otras unidades de sonido) de una voz y del fondo de ruido o del silencio.
Entonces dan lugar los dos puntos que siguen a que la calidad del reconocimiento se vea fuertemente perjudicada: En primer lugar, poseen los canales de audio (micrófono y convertidor analógico/digital) de los aparatos antes citados típicamente una curva característica muy diferente, por ejemplo con respecto a la resolución y precisión de la conversión A/D y al ruido que resulta en una toma de audio. En segundo lugar, se utilizan todos los aparatos citados en entornos acústicamente muy diferentes, es decir, por ejemplo en el automóvil, en la oficina, en la calle, etcétera. Por ello es muy difícil modelizar el fondo de ruido en el reconocimiento de voz.
Un procedimiento estándar para la modelización del fondo de ruido consiste en que en la generación de los datos del modelo se tengan en cuenta muchas expresiones con distinto fondo de ruido. Este llamado proceso de entrenamiento se realiza entonces sobre un banco de datos que contiene tomas procedentes de diversos entornos acústicos, como por ejemplo automóvil, oficina, etcétera. El inconveniente entonces es que las distintas curvas características de los canales de audio no pueden ser captadas por los aparatos móviles y que es imposible representar de manera adecuada todos los entornos acústicos.
Otra posibilidad adicional consiste en captar modelizaciones para ruidos especiales en el vocabulario activo del reconocedor (modelización Garbage o de desecho). No obstante, este tipo de modelización tiene el inconveniente de que sólo antes y después de la palabra a reconocer pueden reproducirse ruidos secundarios sobre estas palabras Garbage o de desecho. El reconocimiento de la palabra pronunciada se realiza a continuación dificultado por ruidos de fondo.
Otra posibilidad utilizada en muchos casos para asegurar una buena modelización del ruido de fondo son procedimientos para reducir el ruido que intentan suprimir ruidos de fondo en los datos de audio. No obstante, la reducción de los ruidos no está en competencia con los demás procedimientos aquí descritos, ya que los mismos no se excluyen mutuamente y la reducción de ruidos se basa en otra forma de proceder totalmente distinta: La misma modifica los datos de audio y no formula ninguna hipótesis sobre la modelización del ruido de fondo.
Además es posible captar la acústica de una sala y con ello adaptar el canal de audio un poco a una sala muy determinada.
Por el documento de patente US, 5,970,446 se conoce la consideración en el reconocimiento de voz de un perfil de ruido de fondo adecuado al actual fondo de ruido.
Partiendo de ello, la invención tiene como tarea básica incrementar la calidad del reconocimiento de voz y garantizar un reconocimiento de voz seguro, en particular también con diferentes fondos de ruido.
Esta tarea se resuelve mediante las invenciones indicadas en las reivindicaciones independientes. Ventajosas configuraciones mejoradas resultan de las reivindicaciones subordinadas.
Correspondientemente, se utilizan en un procedimiento para el reconocimiento de voz automático, apoyado por ordenador, varios perfiles de fondos de ruido, que representan respectivos fondos de ruido diferentes. Cuando se encuentra en el banco de datos con perfiles de ruido de fondo un perfil de ruido de fondo adecuado como modelo de ruido para el fondo de ruido actual, se elige este perfil de ruido de fondo y se realiza el reconocimiento de voz teniendo en cuenta el perfil de ruido de fondo. Cuando en el banco de datos no se encuentra ningún perfil de ruido de fondo adecuado como modelo de ruido para el actual fondo de ruido, se confecciona un perfil de ruido de fondo para este fondo de ruido y el reconocimiento de voz se realiza considerando el perfil de ruido de fondo confeccionado. La elección de los perfiles de ruido de fondo a partir del banco de datos se realiza preferiblemente de forma automática en base a determinadas prescripciones, pero también puede realizarse manualmente por parte de un usuario. Estas prescripciones pueden contener y/o tener en cuenta por ejemplo los ruidos de fondo medidos en ese momento, pero también alternativa o adicionalmente otros parámetros, como por ejemplo la hora del día o un determinado entorno en el que se encuentra en ese momento el dispositivo que realiza reconocimiento de voz.
El reconocimiento de voz se realiza entonces considerando el perfil de ruido de fondo elegido.
Preferiblemente se analiza para seleccionar el perfil de ruido de fondo el fondo de ruido actual y se elige el perfil de ruido de fondo considerando este análisis. Preferiblemente se elige entonces naturalmente el perfil de ruido de fondo que representa mejor el fondo de ruido actual.
Alternativa o adicionalmente puede no obstante también realizar el usuario la elección del perfil de ruido de fondo o influir sobre la misma.
Otra posibilidad alternativa o adicional consiste en la consideración de otros parámetros. Así puede por ejemplo estar insertado el dispositivo con el que se realiza el reconocimiento de voz en un soporte de fijación de un vehículo. En el procedimiento se detecta entonces que el dispositivo está colocado en el soporte de fijación de un vehículo, para lo cual el dispositivo dispone de los correspondientes medios. A continuación se elige un perfil de ruido de fondo que en particular esté adaptado para un reconocimiento de voz en un automóvil.
Preferiblemente pueden confeccionarse los perfiles de ruido de fondo mediante el dispositivo utilizado para el procedimiento. Para ello se capta un fondo de ruido y el dispositivo confecciona un perfil de ruido de fondo para este fondo de ruido. De esta manera puede adaptarse el procedimiento a los más diversos fondos de ruido y con ello adaptarse a las necesidades del usuario.
Además es ventajoso que se detecte con ayuda de un Voice Activity Detector (VAD, detector de actividad de voz) si existe un fondo con ruido o si existe voz. Esta detección puede realizarse tanto al elegir un perfil de ruido de fondo como también al confeccionar un nuevo perfil de ruido de fondo.
Un dispositivo que está preparado para realizar el procedimiento antes descrito presenta en particular respectivos medios que están equipados para realizar las distintas etapas del procedimiento. Configuraciones mejoradas preferentes del dispositivo resultan análogamente a las configuraciones mejoradas preferentes del procedimiento. El dispositivo es preferiblemente un aparato terminal móvil en forma de un teléfono móvil, PDA o wearable (portable).
Un producto de programa para una instalación de tratamiento de datos que contiene secciones de códigos, con las que puede ejecutarse uno de los procedimientos descritos sobre la instalación de tratamiento de datos, puede ejecutarse mediante implementación adecuada del procedimiento en un lenguaje de programación y conversión a un código que pueda ejecutar la instalación de tratamiento de datos. Las secciones de códigos se memorizan para ello. Al respecto se entiende bajo un producto de programa el programa como producto comercializable. El mismo puede existir en cualquier forma, como por ejemplo en papel, en un soporte de datos legible por ordenador o distribuido a través de una red.
Otras ventajas y características esenciales de la invención resultan de la descripción de un ejemplo de ejecución en base al dibujo. Al respecto muestra
figura 1 la señal de audio de las palabras "encuentro en la estación";
figura 2 un diagrama secuencial para la confección de un perfil de ruido de fondo para un fondo de ruido;
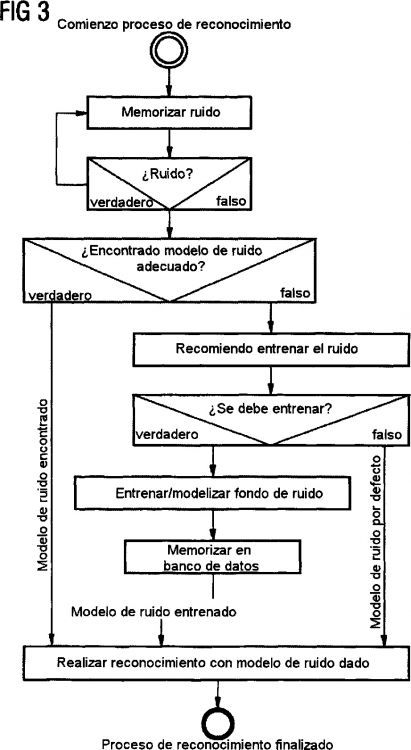
figura 3 un diagrama secuencial para un procedimiento para el reconocimiento de voz.
En el procedimiento para el reconocimiento de voz se entrenan con la mayor precisión posible en relación con el canal de audio y el perfil de usuario perfiles de ruido de fondo adecuados (modelos de silencio) en un aparato terminal. Estos perfiles de ruido de fondo se utilizan entonces en el reconocimiento. Se procede en...
Reivindicaciones:
1. Procedimiento para el reconocimiento de voz con un banco de datos con varios perfiles de ruido de fondo, que representan distintos fondos de ruido,
2. Procedimiento según la reivindicación 1,
3. Procedimiento según una de las reivindicaciones precedentes,
en el que con ayuda de un Voice-Activity-Detector (detector de actividad de voz) se detecta si existe un fondo de ruido.
4. Dispositivo, en particular aparato terminal móvil, equipado para realizar un procedimiento según una de las reivindicaciones precedentes, para lo que el mismo presenta en cada caso medios para realizar las distintas etapas de procedimiento.
5. Producto de programa para una instalación de tratamiento de datos que contiene secciones de códigos con las que puede realizarse un procedimiento según una de las reivindicaciones 1 a 3 sobre la instalación de tratamiento de datos.
Patentes similares o relacionadas:
Procedimiento para la identificación y la comprobación de mensajes radiotelefónicos, del 28 de Noviembre de 2018, de Frequentis AG: Procedimiento para la identificación y la comprobación de mensajes radiotelefónicos (M1...M3), así como para la asignación de mensajes radiotelefónicos […]
Un método y circuito de supresión de ruido que incorpora una pluralidad de técnicas de supresión de ruido, del 12 de Marzo de 2014, de Motorola Mobility LLC (50.0%): Un circuito de supresión de ruido para su uso en un circuito de procesamiento de señal de audio, comprendiendo el circuito de supresión de ruido: una […]
 PROCEDIMIENTO DE DETECCIÓN DE SEGMENTOS DE VOZ, del 8 de Agosto de 2012, de TELEFONICA, S.A.: La presente invención se refiere a un procedimiento de detección de segmentos de voz y de ruido en una señal digital de audio de entrada, estando dividida […]
PROCEDIMIENTO DE DETECCIÓN DE SEGMENTOS DE VOZ, del 8 de Agosto de 2012, de TELEFONICA, S.A.: La presente invención se refiere a un procedimiento de detección de segmentos de voz y de ruido en una señal digital de audio de entrada, estando dividida […]
ELECTRODOMESTICO CONTROLADO POR VOZ., del 1 de Junio de 2007, de BSH BOSCH UND SIEMENS HAUSGERATE GMBH: Electrodoméstico, en particular campana extractora de humos , con una unidad de control por voz que tiene un micrófono y un dispositivo de reconocimiento […]
DETECCION DEL HABLA UTILIZANDO MEDIDAS DE CONFIANZA EN EL ESPECTRO DE FRECUENCIAS., del 16 de Julio de 2006, de PANASONIC TECHNOLOGIES, INC.: 2005 (2005/46) por "Refrigerator". OG: A-04246
DETECCION DE PALABRAS CLAVE EN UNA SEÑAL RUIDOSA., del 1 de Diciembre de 2005, de MATSUSHITA ELECTRIC INDUSTRIAL CO., LTD.: Método para detectar palabras en una señal de habla, que comprende las etapas de: generar una pluralidad de puntuaciones de reconocimiento […]
METODO, DISPOSITIVO, TERMINAL Y SISTEMA PARA EL RECONOCIMIENTO AUTOMATICO DE DATOS DE VOZ DISTORSIONADOS., del 1 de Diciembre de 2005, de TELEFONAKTIEBOLAGET L M ERICSSON (PUBL): Un método de procesar espectros de voz distorsionada de corto período para reconocimiento automático de voz, en el que los datos de voz distorsionada […]
 DISPOSITIVO Y PROCEDIMIENTO PARA GENERAR UN PATRÓN DE ACTIVIDAD FILTRADO, SEPARADOR DE FUENTES, PROCEDIMIENTO PARA GENERAR UNA SEÑAL DE AUDIO DEPURADA Y PROGRAMA INFORMÁTICO, del 29 de Abril de 2011, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Dispositivo para generar un patrón de actividad filtrado basándose en un primer patrón de actividad de un modelo auditivo […]
DISPOSITIVO Y PROCEDIMIENTO PARA GENERAR UN PATRÓN DE ACTIVIDAD FILTRADO, SEPARADOR DE FUENTES, PROCEDIMIENTO PARA GENERAR UNA SEÑAL DE AUDIO DEPURADA Y PROGRAMA INFORMÁTICO, del 29 de Abril de 2011, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Dispositivo para generar un patrón de actividad filtrado basándose en un primer patrón de actividad de un modelo auditivo […]