PROCEDIMIENTO DE DETECCIÓN DE SEGMENTOS DE VOZ.
La presente invención se refiere a un procedimiento de detección de segmentos de voz y de ruido en una señal digital de audio de entrada,
estando dividida dicha señal de entrada en una pluralidad de tramas que comprende:
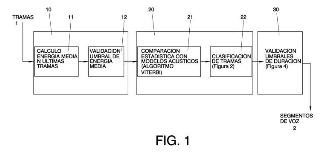
- una primera etapa (10) en la que se realiza una primera clasificación de una trama como ruido si el valor medio de la energía para esta trama y las N tramas anteriores no es superior a un primer umbral de energía, N>1;
- una segunda etapa (20) en la que para cada trama que no ha sido clasificada como ruido en la primera etapa se decide si dicha trama se clasifica como ruido o como voz basándose en combinar al menos un primer criterio de similaridad espectral de la trama con modelos acústicos de ruido y de voz, un segundo criterio de análisis de energía de la trama y un tercer criterio de duración; y en utilizar una máquina de estados para detectar inicio de un segmento como acumulación de un número determinado de tramas consecutivas con parecido acústico superior a un primer umbral y para detectar fin de dicho segmento;
- una tercera etapa (30) en la que se revisa la clasificación como voz o como ruido de las tramas de señal llevada a cabo en la segunda etapa utilizando criterios de duración.
Tipo: Patente de Invención. Resumen de patente/invención. Número de Solicitud: P200930819.
Solicitante: TELEFONICA, S.A..
Nacionalidad solicitante: España.
Inventor/es: GARCIA MARTINEZ,CARLOS, DUXANS BARROBES,HELENCA, SENDRA VICENS,MAURICIO, CADENAS SANCHEZ,DAVID.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G10L11/02
- G10L15/04 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › G10L 15/00 Reconocimiento de la voz (G10L 17/00 tiene prioridad). › Segmentación o detección de los límites de las palabras; Word boundary detection.
- G10L15/20 G10L 15/00 […] › Técnicas de reconocimiento de la voz especialmente adaptadas para trabajar en ambientes adversos, p. ej. en presencia de ruido o para voz emitida en situaciones de estrés (G10L 21/02 tiene prioridad).
Fragmento de la descripción:
Procedimiento de detección de segmentos de voz.
Campo de la invención La presente invención pertenece al área de la tecnología del habla, particularmente reconocimiento del habla y verificación del locutor, en concreto a la detección de voz y ruido.
Antecedentes de la invención El reconocimiento automático del habla es una tarea particularmente complicada. Uno de los motivos es la dificultad de detectar los comienzos y finales de los segmentos de voz pronunciados por el usuario, discriminándolos adecuadamente de los periodos de silencio que se producen antes de que comience a hablar, después de que termine, y los que resultan de las pausas que dicho usuario realiza para respirar mientras habla.
La detección y delimitación de los segmentos de voz pronunciados es fundamental por dos motivos. En primer lugar, por motivos de eficiencia computacional: los algoritmos utilizados en reconocimiento del habla son bastante exigentes en lo que a carga computacional se refiere, por lo que aplicarlos a toda la señal acústica, sin eliminar los periodos en los que no hay presente voz del usuario, supondría disparar la carga de procesamiento y, en consecuencia, provocaría retrasos considerables en la respuesta de los sistemas de reconocimiento. En segundo lugar, y no menos importante, por motivos de eficacia: la eliminación de los segmentos de señal que no contienen voz del usuario, limita considerablemente el espacio de búsqueda del sistema de reconocimiento, reduciendo sustancialmente su tasa de error. Por estos motivos, los sistemas comerciales de reconocimiento automático del habla incorporan un módulo de detección de segmentos de voz y de ruido.
Como consecuencia de la importancia de la detección de segmentos de voz, los esfuerzos para conseguir llevar a cabo esta tarea adecuadamente han sido muy numerosos.
Por ejemplo, la solicitud de patente japonesa JP-A-9050288 presenta un método de detección de segmentos de voz. En concreto, se determinan los puntos de inicio y finalización del segmento de voz mediante la comparación de la amplitud de la señal de entrada con un umbral. Este método presenta el inconveniente de que el funcionamiento depende del nivel de la señal de ruido, por lo que sus resultados no son adecuados en presencia de ruidos de gran amplitud.
Por su parte, la solicitud de patente japonesa JP-A-1244497 muestra un método de detección de segmentos de voz basado en el cálculo de la energía de la señal. En concreto, se calcula la energía media de las primeras tramas de voz y utiliza el valor obtenido como estimación de la energía de la señal de ruido superpuesta a la voz. A continuación, se detectan los pulsos de voz mediante la comparación de la energía de cada trama de la señal con un umbral dependiente de la energía de la señal de ruido estimada. De esta forma, se compensa la posible variabilidad de valores de energía de la señal de ruido. Sin embargo, el método no funciona correctamente cuando aparecen segmentos de ruido de gran amplitud y corta duración.
En la patente estadounidense US-6317711 también se describe un método de detección de segmentos de voz. En este caso, para cada trama de señal se obtiene un vector de características mediante una parametrización LPC-cepstra y MEL-cepstra. A continuación, se busca el valor mínimo de dicho vector y se normalizan todos los elementos de dicho vector dividiendo su valor por este valor mínimo. Finalmente se compara el valor de la energía normalizada con un conjunto de umbrales predeterminados para detectar los segmentos de voz. Este método ofrece mejores resultados que el anterior, aunque sigue presentando dificultades para detectar segmentos de voz en condiciones de ruido desfavorables.
En la patente estadounidense US-6615170 se presenta un método alternativo de detección de segmentos de voz que, en lugar de basarse en la comparación de un parámetro o un vector de parámetros con un umbral o conjunto de umbrales, se basa en el entrenamiento de modelos acústicos de ruido y de voz y en la comparación de la señal de entrada con dichos modelos, determinando si una determinada trama es voz o ruido mediante la maximización de la máxima verosimilitud.
Aparte de estas patentes y otras similares, el tratamiento de la tarea de la detección de segmentos de voz y ruido en la literatura científica es muy extenso, existiendo numerosos artículos y ponencias que presentan diferentes métodos de llevar a cabo dicha detección. Así, por ejemplo, en “Voice Activity Detection Based on Conditional MAP Criterion” (Jong Won Shin, Hyuk Jin Kwon, Suk Ho Jin, Nam Soo Kim; en IEEE Signal Processing Letters, ISSN: 1070-9908, Vo. 15, Feb. 2008) se describe un método de detección de voz basado en una variante del criterio MAP (maximum a posteriori) , que clasifica las tramas de señal en voz o ruido basándose en parámetros espectrales y utilizando umbrales diferentes dependiendo de los resultados de clasificación inmediatamente anteriores.
En lo que respecta al ámbito de la normalización, cabe destacar la recomendación de un método de detección de voz incluida en el estándar de la ETSI de reconocimiento del habla distribuido (ETSI ES 202 050 v1.1.3. Distributed Speech Recognition; Advanced Front-end Feature Extraction Algorithm; Compression Algorithms. Technical Report ETSI ES 202 050, ETSI) . El método recomendado en el estándar se basa en el cálculo de tres parámetros de la señal para cada trama de la misma y su comparación con tres umbrales correspondientes, utilizando un conjunto de varias tramas consecutivas para tomar la decisión voz/ruido final.
Sin embargo, a pesar de la gran cantidad de métodos propuestos, en la actualidad la tarea de detección de segmentos de voz sigue presentando importantes dificultades. Los métodos propuestos hasta el momento, tanto los basados en la comparación de parámetros con umbrales, como los basados en clasificación estadística, son insuficientemente robustos en condiciones desfavorables de ruido, especialmente en presencia de ruido no estacionario, lo que provoca un aumento de los errores de detección de segmentos de voz en tales condiciones. Por este motivo, la utilización de estos métodos en entornos particularmente ruidosos, como es el caso del interior de automóviles, presenta importantes problemas.
Es decir, los métodos de detección de segmentos de voz propuestos hasta el momento, tanto los basados en la comparación de parámetros de la señal con umbrales como los basados en comparación estadística, presentan importantes problemas de robustez en entornos de ruido desfavorables. Particularmente, su funcionamiento se degrada considerablemente ante la presencia de ruidos de carácter no estacionario.
Como consecuencia de la falta de robustez en determinadas condiciones, resulta inviable o particularmente difícil la utilización de sistemas de reconocimiento automático del habla en determinados entornos (como por ejemplo, el interior de automóviles) . En estos casos, el empleo de métodos de detección de segmentos de voz basados en comparación de parámetros de la señal con umbrales, o bien basados en comparaciones estadísticas, no proporciona resultados adecuados. En consecuencia, los reconocedores automáticos del habla obtienen numerosos resultados erróneos, así como frecuentes rechazos de las pronunciaciones del usuario, lo que dificulta enormemente la utilización de este tipo de sistemas.
Descripción de la invención La invención se refiere a un procedimiento de detección de segmentos de voz de acuerdo con la reivindicación 1. Realizaciones preferidas del procedimiento se definen en las reivindicaciones dependientes.
La presente propuesta trata de hacer frente a tales limitaciones, ofreciendo un procedimiento de detección de segmentos de voz robusto en entornos ruidosos, incluso en presencia de ruidos de carácter no estacionario. Para ello, el procedimiento propuesto se basa en la combinación de tres criterios para tomar la decisión de clasificar los segmentos de la señal de entrada como voz o como ruido. En concreto, se utiliza un primer criterio relacionado con la energía de la señal, basado en la comparación con un umbral. Como segundo criterio se utiliza una comparación estadística de una serie de parámetros espectrales de la señal con unos modelos de voz y de ruido. Y se utiliza un tercer criterio basado en la duración de los distintos pulsos de voz y ruido, basado en la comparación con un conjunto de umbrales.
Y el procedimiento de detección de segmentos de voz propuesto se realiza en...
Reivindicaciones:
1. Procedimiento de detección de segmentos de voz (2) y de ruido en una señal digital de audio de entrada, estando dividida dicha señal de entrada en una pluralidad de tramas (1) que comprende:
- una primera etapa (10) en la que se realiza una primera clasificación de una trama como ruido si el valor medio de la energía para esta trama y las N tramas anteriores no es superior a un primer umbral de energía (umbral_energ1) , siendo N un número entero mayor que 1;
- una segunda etapa (20) en la que para cada trama que no ha sido clasificada como ruido en la primera etapa se decide si dicha trama se clasifica como ruido o como voz basándose en combinar al menos un primer criterio de similaridad espectral de la trama con modelos acústicos de ruido y de voz, un segundo criterio de análisis de energía de la trama respecto a un segundo umbral de energía (umbral_energ2) y un tercer criterio de duración consistente en utilizar una máquina de estados para detectar el inicio de un segmento como acumulación de un número determinado de tramas consecutivas con parecido acústico superior a un primer umbral acústico (umbral_ac1) y otro número determinado de tramas consecutivas con parecido acústico inferior a dicho primer umbral acústico para detectar el fin de dicho segmento;
- una tercera etapa (30) en la que se revisa la clasificación como voz o como ruido de las tramas de señal llevada a cabo en la segunda etapa utilizando criterios de duración, clasificando como ruido los segmentos de voz de duración inferior a un primer umbral de duración mínima de segmento, así como aquellos que no contienen un determinado número de tramas consecutivas que simultáneamente superan dicho umbral acústico y dicho segundo umbral de energía.
2. Procedimiento según las reivindicación 1, en el que en dicha tercera etapa se utilizan dos umbrales de duración:
- un primer umbral (umbral_dur1) de duración mínima de segmento o número mínimo de tramas consecutivas clasificadas como voz o como ruido;
- un segundo umbral de duración (umbral_dur2) de tramas consecutivas que en la segunda etapa cumplen tanto el criterio de similaridad espectral como el criterio de análisis de energía de la trama.
3. Procedimiento según cualquiera de las reivindicaciones 1-2, en el que dicho criterio de similaridad espectral usado en la segunda etapa consiste en un análisis comparativo de características espectrales de dicha trama con características espectrales de dichos modelos acústicos de ruido y de voz previamente establecidos.
4. Procedimiento según la reivindicación 3, en el que dicho análisis comparativo de características espectrales se realiza utilizando el algoritmo de Viterbi.
5. Procedimiento según cualquiera de las reivindicaciones 1-4, en el que dichos modelos acústicos de ruido y de voz previamente establecidos se obtienen modelando estadísticamente dos unidades acústicas, de ruido y voz respectivamente, mediante modelos ocultos de Márkov.
6. Procedimiento según cualquiera de las reivindicaciones anteriores, en el que la máquina de estados comprende, al menos, un estado inicial (210) , un estado en el que se comprueba que se ha iniciado un segmento de voz (220) , un estado en el que se comprueba que continúa el segmento de voz (230) , y un estado en el que se comprueba que ha finalizado el segmento de voz (240) .
7. Procedimiento según cualquiera de las reivindicaciones anteriores, en el que en la segunda etapa, para cada trama que no ha sido clasificada como ruido en la primera etapa:
- se calcula una probabilidad de que la trama sea de ruido comparando unas características espectrales de dicha trama con esas mismas características espectrales de un grupo de tramas clasificadas como ruido que no pertenecen a la señal que se está analizando;
- se calcula una probabilidad de que la trama sea de voz comparando unas características espectrales de dicha trama con esas mismas características espectrales de un grupo de tramas clasificadas como voz que no pertenecen a la señal que se está analizando;
- se calcula un estado siguiente de la máquina de estados en función de al menos, un ratio entre la probabilidad de que la trama sea de voz y la probabilidad de que la trama sea de ruido, y de un estado actual de dicha máquina de estados.
8. Procedimiento según la reivindicación 7 cuando depende de la 6, en el que para producirse una transición entre el estado en el que se comprueba que se ha iniciado un segmento de voz (220) y el estado en el que se comprueba que continúa un segmento de voz (230) , se requieren, al menos, dos tramas consecutivas en las que el ratio entre la probabilidad de que la trama sea de voz y la probabilidad de que la trama sea de ruido sea superior a un primer umbral acústico.
9. Procedimiento según la reivindicación 7 cuando depende de la 6 o según la reivindicación 8, en el que para producirse una transición entre el estado que comprueba que se ha finalizado un segmento de voz (240) y el estado inicial (210) se requieren, al menos, dos tramas consecutivas en las que el ratio entre la probabilidad de que la trama sea de voz y la probabilidad de que la trama sea de ruido sea inferior a un primer umbral acústico dividido por un factor.
10. Procedimiento según cualquiera de las reivindicaciones 1-9, en el que el primer umbral de energía utilizado en la primera etapa se actualiza dinámicamente ponderando su valor actual y el valor de energía de las tramas clasificadas como ruido en la segunda y la tercera etapas.
11. Procedimiento según la reivindicación 1 -2, en el que el criterio de análisis de la energía de la trama (2203, 2303) consiste en superar un segundo umbral de energía, calculado al multiplicar el primer umbral de energía por un factor y sumarle un offset.
Patentes similares o relacionadas:
Procedimiento para la identificación y la comprobación de mensajes radiotelefónicos, del 28 de Noviembre de 2018, de Frequentis AG: Procedimiento para la identificación y la comprobación de mensajes radiotelefónicos (M1...M3), así como para la asignación de mensajes radiotelefónicos […]
Un método y circuito de supresión de ruido que incorpora una pluralidad de técnicas de supresión de ruido, del 12 de Marzo de 2014, de Motorola Mobility LLC (50.0%): Un circuito de supresión de ruido para su uso en un circuito de procesamiento de señal de audio, comprendiendo el circuito de supresión de ruido: una […]
 PROCEDIMIENTO ADAPTATIVO AL USUARIO PARA LA MODELIZACION DE RUIDOS, del 7 de Mayo de 2010, de SIEMENS AKTIENGESELLSCHAFT: Procedimiento para el reconocimiento de voz con un banco de datos con varios perfiles de ruido de fondo, que representan distintos fondos de […]
PROCEDIMIENTO ADAPTATIVO AL USUARIO PARA LA MODELIZACION DE RUIDOS, del 7 de Mayo de 2010, de SIEMENS AKTIENGESELLSCHAFT: Procedimiento para el reconocimiento de voz con un banco de datos con varios perfiles de ruido de fondo, que representan distintos fondos de […]
ELECTRODOMESTICO CONTROLADO POR VOZ., del 1 de Junio de 2007, de BSH BOSCH UND SIEMENS HAUSGERATE GMBH: Electrodoméstico, en particular campana extractora de humos , con una unidad de control por voz que tiene un micrófono y un dispositivo de reconocimiento […]
DETECCION DEL HABLA UTILIZANDO MEDIDAS DE CONFIANZA EN EL ESPECTRO DE FRECUENCIAS., del 16 de Julio de 2006, de PANASONIC TECHNOLOGIES, INC.: 2005 (2005/46) por "Refrigerator". OG: A-04246
DETECCION DE PALABRAS CLAVE EN UNA SEÑAL RUIDOSA., del 1 de Diciembre de 2005, de MATSUSHITA ELECTRIC INDUSTRIAL CO., LTD.: Método para detectar palabras en una señal de habla, que comprende las etapas de: generar una pluralidad de puntuaciones de reconocimiento […]
METODO, DISPOSITIVO, TERMINAL Y SISTEMA PARA EL RECONOCIMIENTO AUTOMATICO DE DATOS DE VOZ DISTORSIONADOS., del 1 de Diciembre de 2005, de TELEFONAKTIEBOLAGET L M ERICSSON (PUBL): Un método de procesar espectros de voz distorsionada de corto período para reconocimiento automático de voz, en el que los datos de voz distorsionada […]
 DISPOSITIVO Y PROCEDIMIENTO PARA GENERAR UN PATRÓN DE ACTIVIDAD FILTRADO, SEPARADOR DE FUENTES, PROCEDIMIENTO PARA GENERAR UNA SEÑAL DE AUDIO DEPURADA Y PROGRAMA INFORMÁTICO, del 29 de Abril de 2011, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Dispositivo para generar un patrón de actividad filtrado basándose en un primer patrón de actividad de un modelo auditivo […]
DISPOSITIVO Y PROCEDIMIENTO PARA GENERAR UN PATRÓN DE ACTIVIDAD FILTRADO, SEPARADOR DE FUENTES, PROCEDIMIENTO PARA GENERAR UNA SEÑAL DE AUDIO DEPURADA Y PROGRAMA INFORMÁTICO, del 29 de Abril de 2011, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Dispositivo para generar un patrón de actividad filtrado basándose en un primer patrón de actividad de un modelo auditivo […]