Procedimiento para generar una imagen de color compuesta por una pluralidad de componentes partiendo de por lo menos un mapa de profundidad o disparidad y aparato correspondiente.
Procedimiento para generar una imagen de color compuesta por una pluralidad de componentes partiendo de por lo menos un mapa de profundidad o disparidad y aparato correspondiente.
En dicho procedimiento, se introduce un primer conjunto de píxeles de dicho por lo menos un mapa de profundidad o disparidad (DM1, DM2) en la componente de luminancia (Y) de dicha imagen de color, y en el que se introducen un segundo y un tercer conjunto de píxeles de dicho por lo menos un mapa de profundidad o disparidad (DM1, DM2) en las dos componentes de crominancia (U, V) de dicha imagen de color.
Tipo: Patente de Invención. Resumen de patente/invención. Número de Solicitud: P201430919.
Solicitante: SISVEL TECHNOLOGY S.R.L.
Nacionalidad solicitante: Italia.
Dirección: Via Castagnole 59 I-10060 Turín, None ITALIA.
Inventor/es: D\'AMATO, PAOLO, Grangetto,Marco, LUCENTEFORTE,Maurizio.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- H04N13/02
Fragmento de la descripción:
Procedimiento para generar una imagen de color compuesta por una pluralidad de componentes partiendo de por lo menos un mapa de profundidad o disparidad y aparato correspondiente.
Campo de la invención La presente invención se refiere a un procedimiento y a un dispositivo para generar, almacenar, transmitir, recibir y reproducir mapas de profundidad utilizando las componentes de color de una imagen que pertenece a un flujo de vídeo tridimensional.
Estado de la técnica El desarrollo de aplicaciones de vídeo estereoscópicas depende en gran parte de la disponibilidad de formatos eficaces para representar y comprimir la señal de vídeo tridimensional. Además, en aplicaciones de difusión televisiva (3D-TV) , es necesario mantener el grado más alto posible de retrocompatibilidad con los sistemas en 2D existentes.
Para una distribución (o transmisión) , las soluciones técnicas más extendidas en la actualidad se basan en la denominada “disposición de fotograma compatible”, en la que las dos vistas estereoscópicas, en relación con el mismo instante en el tiempo, se reajustan a escala y se componen para formar una única imagen compatible con los formatos existentes. Entre estas soluciones, se conocen los formatos encima y debajo, de lado a lado y de baldosa. Estas soluciones permiten utilizar toda la infraestructura de distribución de señal de vídeo existente (terrestre, por satélite o de difusión por cable o la transmisión en flujo continuo a través de la red IP) , y no requieren normas nuevas para la compresión del flujo de vídeo. Además, la norma de codificación AVC/H.264 actual (codificación de vídeo avanzada) y la norma HEVC futura (codificación de vídeo de alta eficacia) ya incluyen la posibilidad de señalizar este tipo de organización para permitir una reconstrucción y visualización apropiadas por el receptor.
Para la visualización, las dos soluciones técnicas más extendidas en la actualidad se basan o bien en el principio de “fotograma alterno” (es decir las dos vistas se presentan en sucesión de tiempo en la pantalla) o bien en el principio de “línea alterna”, es decir las dos vistas se disponen en la pantalla con filas alternas (es decir se “entrelazan”) . En ambos casos, para que cada ojo reciba la vista correspondiente, es necesario que el espectador utilice un par de gafas, que pueden ser o bien “activas”, es decir gafas de obturación, en el caso de fotograma alterno,
o bien “pasivas”, es decir con lentas polarizadas de manera diferente, en el caso de línea alterna.
El futuro de una visualización tridimensional se determinará mediante la difusión de pantallasautoestereoscópicas nuevas que no requerirán que el usuario utilice gafas, ya sean pasivas o activas. Estos dispositivos de visualización en 3D, que actualmente están todavía en la fase de prototipo, se basan en la utilización de lentes o barreras de paralaje que pueden hacer que el espectador perciba dos vistas estereoscópicas diferentes para cada punto de vista en el que puede encontrarse el usuario cuando se mueve de manera angular alrededor de la pantalla. Por tanto, estos dispositivos pueden mejorar la experiencia de visión en 3D, pero pueden requerir la generación de un gran número de vistas (algunas decenas de las mismas) .
En cuanto a la representación de vídeo en 3D, la gestión de la producción y distribución de un gran número de vistas es una tarea muy exigente. En los últimos años, la comunidad científicaha evaluado la posibilidad de crear un número arbitrariamente grande de vistas intermedias utilizando técnicas de representación basada en imagen de profundidad (DIBR) conocidas, que aprovechan el denominado mapa de profundidad de escena. Estos formatos también se denominan “Vídeo + Profundidad” (V+D) , en el que cada vista va acompañada de un mapa de profundidad denso. Un mapa de profundidad denso es una imagen en la que cada píxel en coordenadas planas (x, y) , es decir columna, fila, representa un valor de profundidad (z) que corresponde al píxel de la vista respectiva que presenta las mismas coordenadas. Los valores de los mapas de profundidad pueden calcularse partiendo de las dos vistas obtenidas por una cámara de vídeo estereoscópica, de lo contrario pueden medirse mediante sensores adecuados. Tales valores se representan generalmente utilizando imágenes con 256 niveles de escala de grises, que se comprimen utilizando técnicas convencionales. Las técnicas de representación basada en imagen de profundidad aprovechan el hecho de que, dadas las coordenadas (x, y, z) , es decir la posición en el plano de profundidad más la profundidadasociada con cada píxel, es posible proyectar de nuevo el píxel sobre otro plano de imagen en relación con un punto de vista nuevo. El contexto de aplicación más extendido es el de un sistema de cámaras de vídeo estereoscópicas, en el que las dos cámaras de vídeo están situadas horizontalmente a una distancia b entre sus dos centros ópticos, con ejes ópticos paralelos y planos de imagen coplanarios. En una configuración de este tipo, hay una relación simple entre la profundidad z, asociada con un píxel, y la denominada disparidad d, es decir la traslación horizontal que debe aplicarse a un píxel de la imagen de la cámara de vídeo derecha (o izquierda) con el fin de obtener la posición correspondiente en el plano de imagen de la cámara de vídeo izquierda (o derecha) . La disparidad puede ser o bien positiva o bien negativa (la traslación a la izquierda o a la derecha) , dependiendo de la cámara de vídeo que se tiene en cuenta. Indicando f la longitud focal de las dos cámaras de vídeo, existe la siguiente relación entre profundidad z y disparidad d:
d= f b / z.
Para más detalle, véase el artículo: Paradiso, V.; Lucenteforte, M.; Grangetto, M., “A novel interpolation method for 3D view synthesis”, 3DTV-Conference: The True Vision -Capture, Transmission and Display of 3D Video (3DTV-CON) , 2012, vol., n.º, pp. 1, 4, 15-17 de octubre de 2012.
Puesto que, según las hipótesis descritas anteriormente, la disparidad es una función simple de profundidad, el mapa de profundidad y el mapa de disparidad llevan la misma información y, por tanto, son intercambiables. Además, debe señalarse que las imágenes a las que se hace referencia como mapas de profundidad dentro del contexto de MPEG representan los valores de 1/z, a diferencia de z, mapeados en el intervalo 0-255. A continuación, el término “mapa de profundidad” sólo se utilizará para indicar cualquier representación de profundidad o disparidad.
Debe observarse que la señal de vídeo compuesta por un par de imágenes (izquierda y derecha) y los mapas de profundidad respectivos también se ha elegido como caso de uso por el comité de normalización de MPEG para evaluar las técnicas que se introducirán en las normas de codificación de 3D futuras.
Esto lleva a la necesidad de gestionar eficazmente el almacenamiento, transmisión, recepción y reproducción de señales de televisión que comprenden mapas de profundidad.
Sumario de la invención Por tanto, el propósito de la presente invención es proporcionar un procedimiento y un dispositivo para generar, almacenar, transmitir, recibir y reproducir mapas de profundidad utilizando las componentes de color de una imagen, que puedan superar las limitaciones inherentes en las soluciones conocidas en la materia.
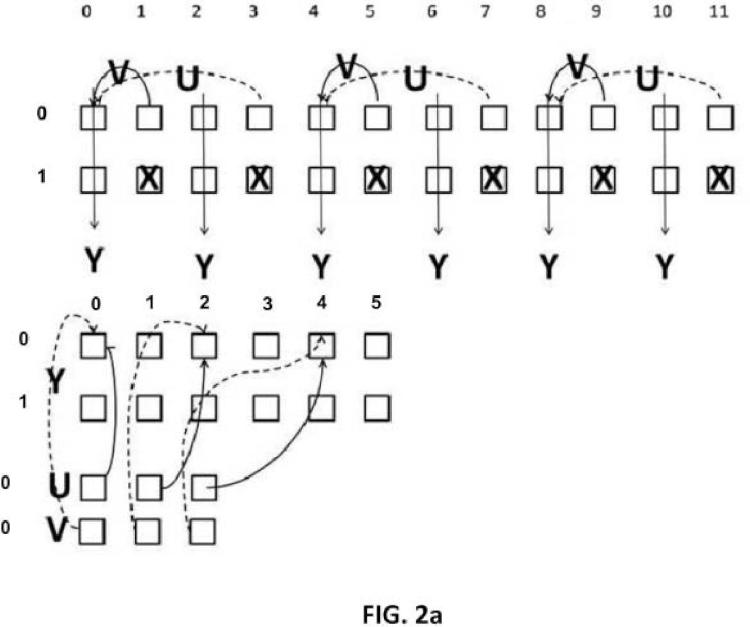
Tal como se mencionó anteriormente, un mapa de profundidad es adecuado para su representación como imagen en escala de grises, es decir constituida por un único valor por posición (x, y) . El término “píxel” se utilizará a continuación para indicar un único elemento (o punto) de una imagen; cada píxel está caracterizado por su posición (x, y) y por valores tales como color o intensidad, que varían en función del sistema de representación que se utiliza. En el campo de la televisión, generalmente se adopta el sistema de representación de píxeles conocido como luminancia (Y) y crominancia (U, V) . En general, los mapas de profundidad se representan como vídeo digital utilizando sólo la componente Y.
La idea básica de la presente invención es aprovechar también las componentes de crominancia U y V para representar los valores del mapa de profundidad, creando por tanto una denominada imagen de “color ficticio”, que permite una mejor compactación de imagen. Una imagen de color ficticio (a continuación en la presente memoria denominada, para abreviar, “imagen de color”) es, en este contexto, una imagen en la que también las componentes de crominancia llevan información útil que, sin embargo, no es información...
Reivindicaciones:
1. Procedimiento para generar una imagen de color compuesta por una pluralidad de componentes (Y, U, V) , partiendo de al menos un mapa de profundidad o disparidad (DM1, DM2) , caracterizado porque se introduce un primer conjunto de píxeles de dicho al menos un mapa de profundidad o disparidad (DM1, DM2) en la componente de luminancia (Y) de dicha imagen de color, y porque se introducen un segundo y tercer conjunto de píxeles de dicho por lo menos un mapa de profundidad o disparidad (DM1, DM2) en las dos componentes de crominancia (U, V) de dicha imagen de color.
2. Procedimiento según la reivindicación 1, caracterizado porque la elección de las posiciones en las que los píxeles de dichos conjuntos se introducirán en dichas componentes de luminancia (Y) y crominancia (U, V) se realiza, de manera que se garantice la correlación espacial entre la componente de luminancia (Y) y las componentes de crominancia (U, V) de dicha imagen de color.
3. Procedimiento según la reivindicación 1 o 2, caracterizado porque la unión de dicho primer, segundo y tercer conjuntos comprende todos los píxeles de dicho por lo menos un mapa de profundidad o disparidad (DM1, DM2) .
4. Procedimiento según la reivindicación 1 o 2, caracterizado porque dicho primer, segundo y tercer conjuntos comprenden sólo una parte de todos los píxeles de dicho por lo menos un mapa de profundidad o disparidad (DM1, DM2) .
5. Procedimiento según cualquiera de las reivindicaciones anteriores, caracterizado porque se introducen dos mapas de profundidad o disparidad (DM1, DM2) de tamaño WxH en una imagen de color del mismo tamaño utilizando una técnica de lado a lado o encima y debajo.
6. Procedimiento según cualquiera de las reivindicaciones anteriores, caracterizado porque lospíxeles de dicho primer y tercer conjuntos que pertenecen a un grupo de píxeles se sustituyen por valores de diferencia en relación con un valor predicho o interpolado, obteniéndose este último a partir de valores de píxeles que pertenecen a dicho primer conjunto.
7. Procedimiento según cualquiera de las reivindicaciones 1 a 4, caracterizado porque comprende la etapa de sustituir los píxeles de dicho por lo menos un mapa de profundidad o disparidad (DM1, DM2) que pertenece a un grupo de píxeles contiguos (a, b, c, d) por sumas o diferencias de los mismos (w0, w1, w2, w3) , colocando las sumas en la componente de luminancia (Y) y eligiendo sólo una de las diferencias (wd) que se colocará de manera alterna en las componentes de crominancia (U, V) .
8. Procedimiento según cualquiera de las reivindicaciones 1 a 4, caracterizado porquecomprende la etapa de sustituir los píxeles de dicho por lo menos un mapa de profundidad o disparidad (DM1, DM2) que pertenece a un grupo de píxeles contiguos (a, b, c, d) por sumas o diferencias de los mismos (w0, w1, w2, w3) , colocando las sumas en la componente de luminancia (Y) , la primera de las dos diferencias en una componente de crominancia (U) , y la segunda en la otra componente de crominancia (V) .
9. Procedimiento según cualquiera de las reivindicaciones anteriores, caracterizado porque comprende la etapa de someter a dicho por lo menos un mapa de profundidad o disparidad (DM1, DM2) a una transformación de dominio antes de introducir dichos conjuntos de píxeles en dichas componentes de la imagen de color (Y, U, V) .
10. Procedimiento para generar un flujo de vídeo, caracterizado porque comprende una secuencia de imágenes de color obtenidas utilizando un procedimiento según una de las reivindicaciones anteriores.
11. Procedimiento para generar un flujo de vídeo según la reivindicación 10, caracterizado
porque se utiliza el formato de empaquetado de fotogramas de formato de baldosa, y porque se introduce dicha imagen de color en la parte de fotograma que está libre de píxeles de imágenes relacionados con las dos vistas estereoscópicas.
12. Aparato, caracterizado porque comprende unos medios de procesamiento de imagen adaptados para generar un flujo de vídeo que comprende una secuencia de imágenes de color obtenidas utilizando un procedimiento según una de las reivindicaciones anteriores.
13. Procedimiento para reconstruir por lo menos un mapa de profundidad o disparidad (DM1, DM2) partiendo de una imagen de color compuesta por una pluralidad de componentes (Y, U, V) , caracterizado porque se introducen un primer conjunto de píxeles obtenidos partiendo de la componente de luminancia (Y) , un segundo conjunto de píxeles obtenidos partiendo de una delas componentes de crominancia (U) y un tercer conjunto de píxeles obtenidos partiendo de la otra componente de crominancia (V) de dicha imagen de color (Y, U, V) en dicho por lo menos un mapa de profundidad o disparidad.
14. Procedimiento según la reivindicación 13, caracterizado porque se toma dicho primer conjunto de píxeles de la componente de luminancia, se toma dicho segundo conjunto de píxeles de una de las componentes de crominancia (U) y se toma dicho tercer conjunto de píxeles de la otra componente de crominancia (V) de dicha imagen de color (Y, U, V) .
15. Procedimiento según la reivindicación 13, caracterizado porque se toma dicho primer conjunto de píxeles de la componente de luminancia, mientras se obtienen dicho segundo o tercer conjuntos realizando una suma de los valores de los píxeles tomados de una o, respectivamente, de la otra de las componentes de crominancia, representando la diferencia en relación con un valor de referencia obtenido mediante interpolación a partir de valores de píxeles que pertenecen a dicho primer conjunto, y dicho valor de referencia.
16. Procedimiento según las reivindicaciones 13, 14, 15, caracterizado porque se obtienen todos los píxeles de dicho por lo menos un mapa de profundidad o disparidad (DM1, DM2) obteniendo dicho primer, segundo y tercer conjuntos de píxeles.
17. Procedimiento según las reivindicaciones 13, 14, 15, caracterizado porque se obtienen algunos píxeles de dicho por lo menos un mapa de profundidad o disparidad (DM1, DM2) obteniendo dicho primer, segundo y tercer conjuntos de píxeles, y se obtienen los píxeles que faltan de los píxeles copiados de nuevo por medio de operaciones de interpolación.
18. Procedimiento según cualquiera de las reivindicaciones 14 a 17, caracterizado porque se obtienen dos mapas de profundidad o disparidad (DM1, DM2) , que presentan el mismo tamaño (WxH) que dicha imagen de color (Y, U, V) , obteniendo dicho primer, segundo y tercer conjuntos de píxeles.
19. Procedimiento para reconstruir por lo menos un mapa de profundidad o disparidad (DM1, DM2) partiendo de una imagen de color compuesta por una pluralidad de componentes (Y, U, V) , caracterizado porque comprende la etapa de combinar linealmente unos valores (w0, w1, wd; w0, w1, w2, w3) tomados de dicha pluralidad de componentes (Y, U, V) , en posiciones contiguas, para reconstruir unos valores (a, b, c, d) que van a ser copiados en dicho por lo menos un mapa de profundidad o disparidad (DM1, DM2) .
20. Procedimiento según cualquiera de las reivindicaciones 13 a 19, caracterizado porque, después de que se han obtenido dichos conjuntos de píxeles de dichas componentes (Y, U, V) de la imagen de color, se realiza una transformación de dominio inversa a la llevada a cabo en la fase de generación con el fin de obtener dicho por lo menos un mapa de profundidad (DM1, DM2) .
21. Procedimiento para reconstruir un flujo de vídeo utilizando el formato de empaquetado de fotogramas denominado formato de baldosa, caracterizado porque comprende unas etapas
destinadas a reconstruir por lo menos un mapa de profundidad o disparidad (DM1, DM2) partiendo de una imagen de color presente en la parte de fotograma que está libre de píxeles de imágenes que se relacionan con las dos vistas estereoscópicas, según cualquiera de las reivindicaciones 13 a 20.
22. Aparato para reconstruir por lo menos un mapa de profundidad o disparidad (DM1, DM2) partiendo de una imagen de color compuesta por las componentes Y, U, V, caracterizado porque comprende unos medios para poner en práctica el procedimiento según cualquiera de las reivindicaciones 13 a 21.
Patentes similares o relacionadas:
Sistema y método de medición estereoscópica, del 3 de Mayo de 2017, de Matrix Electronic Measuring Properties, LLC: Un sistema que comprende módulos ejecutables con al menos un procesador para obtener mediciones de un objeto , comprendiendo el sistema: una memoria que almacena […]
Dispositivo y procedimiento para identificar y documentar al menos un objeto que recorre un campo de radiación, del 29 de Marzo de 2017, de JENOPTIK ROBOT GMBH: Dispositivo para identificar y documentar al menos un objeto que recorre un campo de medida , cuyo dispositivo incluye un sensor con un emisor para emitir […]
Procedimiento para corregir el ajuste de zoom y/o la dislocación vertical de imágenes parciales de una película esteoreoscópica, así como control o regulación de un rig de cámara con dos cámaras, del 1 de Marzo de 2017, de Truality, LLC: Procedimiento para corregir el ajuste de zoom y/o la dislocación vertical en una imagen compuesta por dos imágenes parciales de una película esteoreoscópica, […]
Sistema de control para cables o similar, del 21 de Septiembre de 2016, de ROLLS-ROYCE MARINE AS: Sistema de control de la carga o descarga de un cable o similar sobre un tambor , en el que el tambor presenta un primer eje geométrico de rotación conocido de […]
Aparato de escaneo de enfoque, del 24 de Agosto de 2016, de 3SHAPE A/S: Un escáner para la obtención y/o la medida de la geometría 3D de al menos una parte de la superficie de un objeto, comprendiendo el citado escáner: - al menos […]
 Dispositivo portátil para la medida de mapas de desplazamientos de superficies en las tres direcciones espaciales, del 24 de Septiembre de 2014, de UNIVERSIDAD DE ALCALA.: Dispositivo optoelectrónico portátil como el mostrado en la Figura 1, que permite realizar medidas de desplazamientos de campo completo de una superficie […]
Dispositivo portátil para la medida de mapas de desplazamientos de superficies en las tres direcciones espaciales, del 24 de Septiembre de 2014, de UNIVERSIDAD DE ALCALA.: Dispositivo optoelectrónico portátil como el mostrado en la Figura 1, que permite realizar medidas de desplazamientos de campo completo de una superficie […]
 Método y aparato para codificar una señal de vídeo digital, del 10 de Septiembre de 2014, de KONINKLIJKE PHILIPS N.V: Un método de codificación de una secuencia de vídeo digital, comprendiendo dicha secuencia de vídeo digital un conjunto de imágenes que incluye una […]
Método y aparato para codificar una señal de vídeo digital, del 10 de Septiembre de 2014, de KONINKLIJKE PHILIPS N.V: Un método de codificación de una secuencia de vídeo digital, comprendiendo dicha secuencia de vídeo digital un conjunto de imágenes que incluye una […]
 ANTICUERPOS CONTRA VLA-1, del 2 de Noviembre de 2010, de BIOGEN IDEC MA, INC.: Un anticuerpo anti-VLA-1 o fragmento de unión a antígeno del mismo cuyas regiones determinantes de complementariedad de cadena ligera están definidas […]
ANTICUERPOS CONTRA VLA-1, del 2 de Noviembre de 2010, de BIOGEN IDEC MA, INC.: Un anticuerpo anti-VLA-1 o fragmento de unión a antígeno del mismo cuyas regiones determinantes de complementariedad de cadena ligera están definidas […]