Método para la detección y corrección de errores en memorias volátiles.
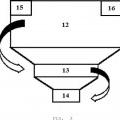
La invención describe un método para la detección y corrección de múltiples errores en los datos almacenados en la memoria volátil de un sistema electrónico,
como los causados por radiación cósmica en sistemas aeroespaciales, basado en una codificación/decodificación piramidal a través de los llamados bits semilla HSB que son soldados o fijados físicamente en la placa del circuito impreso.
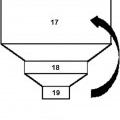
La fase de codificación agrupa en bloques los bits de la memoria seleccionados de forma equiespaciada, calcula las palabras de chequeo de detección y corrección para cada bloque, y calcula y fija físicamente los bits semilla HSB.
La fase de decodificación calcula periódicamente en dos funciones duplicadas las palabras de chequeo de detección y corrección de cada bloque, detecta y corrige errores en estas palabras de chequeo a partir de los bits semilla HSB fijados en codificación, y detecta y corrige errores en los datos almacenados en la memoria.
Tipo: Patente de Invención. Resumen de patente/invención. Número de Solicitud: P201430854.
Solicitante: UNIVERSIDAD CARLOS III DE MADRID.
Nacionalidad solicitante: España.
Inventor/es: PLEITE GUERRA,JORGE, JIMÉNEZ OLAZÁBAL,Andrés.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G06F11/08 FISICA. › G06 CALCULO; CONTEO. › G06F PROCESAMIENTO ELECTRICO DE DATOS DIGITALES (sistemas de computadores basados en modelos de cálculo específicos G06N). › G06F 11/00 Detección de errores; Corrección de errores; Monitorización (detección, corrección o monitorización de errores en el almacenamiento de información basado en el movimiento relativo entre el soporte de registro y el transductor G11B 20/18; monitorización, es decir, supervisión del progreso del registro o reproducción G11B 27/36; en memorias estáticas G11C 29/00). › Detección o corrección de errores por introducción de redundancia en la representación de los datos, p. ej. utilizando códigos de control.
PDF original: ES-2553152_A1.pdf



Patentes similares o relacionadas:
Método para hacer copia de seguridad de un contenido cinematográfico digital, del 29 de Abril de 2020, de ONO FILMS: Método para hacer copias de seguridad de un contenido cinematográfico digital, que incluye las etapas que consisten en: - generar, a partir de dicho contenido, un flujo […]
ALINEACION DE BITS DE PARIDAD PARA ELIMINAR ERRORES EN LA CONMUTACION DE UN CIRCUITO DE PROCESAMIENTO ACTIVO A UNO DE RESERVA., del 16 de Abril de 2007, de AT&T IPM CORP.: SE PRESENTA UN METODO DE CONMUTACION ENTRE UN APARATO DE COMUNICACION ACTIVO Y EN ESPERA QUE TENGA BITS DE PARIDAD JERARQUICAMENTE ANIDADOS. SE […]
PROCEDIMIENTO PARA LA TRANSMISION DE DATOS CON SEÑALIZACION SEGURA ENTRE ORDENADORES CON SEÑALIZACION SEGURA, ASI COMO DISPOSITIVO PARA ELLO., del 16 de Julio de 2006, de SIEMENS AKTIENGESELLSCHAFT: Procedimiento para la transmisión de datos útiles con señalización segura entre dos ordenadores (SRQ, SRS) con señalización segura de un sistema informático a través de la generación […]
PROCEDIMIENTO Y SISTEMA QUE PERMITE UTILIZAR DATOS EN FORMA DE COPIA INVERTIDA PARA DETECTAR DATOS ALTERADOS., del 1 de Marzo de 2001, de ABBOTT LABORATORIES: SE DETECTAN LOS ERRORES EN LOS DATOS ALMACENADOS EN LA MEMORIA DE UN ORDENADOR ANTES DE UTILIZAR LOS DATOS. AL ESCRIBIR UN PROGRAMA EN EL […]
PROCEDIMIENTO PARA SEGURIDAD DE DATOS, del 1 de Mayo de 1999, de ALCATEL ALSTHOM COMPAGNIE GENERALE D'ELECTRICITE: SEGURIDAD DE DATOS FIABLE MEDIANTE ADMINISTRACION DE MEMORIA DINAMICA. A PARTIR DE UNA MODIFICACION SE ELABORA PREVIAMENTE UN NUEVO VALOR DE LOS DATOS ACTUALES Y SE AVERIGUA […]
PROCEDIMIENTO DE DETECCION DE ERRORES DE EJECUCION DE UN LOGICIAL., del 1 de Noviembre de 1997, de GEC ALSTHOM TRANSPORT SA: PROCEDIMIENTO DE DETECCION DE ERRORES DE EJECUCION DE UN LOGICIAL, CUYAS VARIAS REPLICAS IDENTICAS SE EJECUTAN EN PARALELO O SECUENCIALMENTE, COMPRENDIENDO ESTE LOGICIAL EN […]
METODO DE AUTODIAGNOSTICO DE UN EQUIPO DE TELEFONO MOVIL PARA SU USO EN UN SISTEMA DE CONMUTACION DE TELEFONO MOVIL Y EQUIPO DE TELEFONO MOVIL APLICADO AL METODO., del 1 de Mayo de 1997, de NEC CORPORATION: EL PRESENTE INVENTO DESCRIBE UN METODO DE AUTODIAGNOSTICO QUE ACORTA EL TIEMPO DE DIAGNOSTICO DE UNA ROM QUE ESTA PROVISTA EN UN EQUIPO DE TELEFONO MOVIL PARA SU USO […]
 SISTEMA DE FRENOS CONTROLADO ELECTRÓNICAMENTE, del 10 de Mayo de 2011, de DENSO CORPORATION: Una unidad de control que consta de: un microordenador ; en donde la unidad de control se aplica como una unidad de control electrónico para un sistema de control […]
SISTEMA DE FRENOS CONTROLADO ELECTRÓNICAMENTE, del 10 de Mayo de 2011, de DENSO CORPORATION: Una unidad de control que consta de: un microordenador ; en donde la unidad de control se aplica como una unidad de control electrónico para un sistema de control […]