Predicción de cabecera de porciones para mapas de profundidad en códecs de vídeo tridimensionales.
Un procedimiento de decodificación de datos de vídeo, comprendiendo el procedimiento:
recibir una porción de textura para un componente de vista de textura asociado con uno o más bloques codificados de datos de vídeo representativos de información de textura, comprendiendo la porción de textura el uno o más bloques codificados y una cabecera de porciones de textura que comprende elementos de sintaxis representativos de características de la porción de textura;
recibir una porción de profundidad para un componente de vista de profundidad asociado con uno o más bloques codificados de información de profundidad correspondiente al componente de vista de textura, en el que la porción de profundidad comprende el uno o más bloques codificados de información de profundidad y una cabecera de porciones de profundidad que comprende elementos de sintaxis representativos de características de la porción de profundidad, y en el que el componente de vista de profundidad y el componente de vista de textura pertenecen ambos a una vista y a una unidad de acceso;
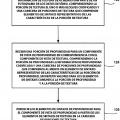
decodificar una primera porción, en el que la primera porción comprende la porción de textura, en el que la primera porción tiene una cabecera de porciones que comprende elementos de sintaxis representativos de características de la primera porción;
determinar elementos de sintaxis comunes para una segunda porción a partir de la cabecera de porciones de la primera porción; y
decodificar la segunda porción después de la decodificación de la primera porción, al menos parcialmente basándose en los elementos de sintaxis comunes determinados, en el que la segunda porción comprende la porción de profundidad, en el que la segunda porción tiene una cabecera de porciones que comprende elementos de sintaxis representativos de características de la segunda porción, excluyendo valores para los elementos de sintaxis que son comunes con la primera porción.
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/US2012/047690.
Solicitante: QUALCOMM INCORPORATED.
Nacionalidad solicitante: Estados Unidos de América.
Dirección: 5775 MOREHOUSE DRIVE SAN DIEGO, CA 92121-1714 ESTADOS UNIDOS DE AMERICA.
Inventor/es: KARCZEWICZ, MARTA, CHEN,YING.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- H04N19/172 ELECTRICIDAD. › H04 TECNICA DE LAS COMUNICACIONES ELECTRICAS. › H04N TRANSMISION DE IMAGENES, p. ej. TELEVISION. › H04N 19/00 Métodos o disposiciones para la codificación, decodificación, compresión o descompresión de señales de vídeo digital. › siendo la región una imagen, un fotograma o un campo.
- H04N19/174 H04N 19/00 […] › siendo la región de un sector, p. ej. una línea de bloques o un grupo de bloques.
- H04N19/44 H04N 19/00 […] › Decodificadores adaptados especialmente para ello, p. ej. decodificadores de vídeo que son asimétricos con respecto al codificador.
- H04N19/46 H04N 19/00 […] › Incorporación de información adicional en la señal de vídeo durante el proceso de compresión (H04N 19/517, H04N 19/68, H04N 19/70 tienen prioridad).
- H04N19/597 H04N 19/00 […] › especialmente adaptado para la codificación de secuencias de videos multivista.
- H04N19/61 H04N 19/00 […] › en combinación con codificación predictiva.
- H04N19/70 H04N 19/00 […] › caracterizado por los aspectos relacionados con la sintaxis de codificación de vídeo, p. ej en relación con los estándares de compresión.
PDF original: ES-2548778_T3.pdf


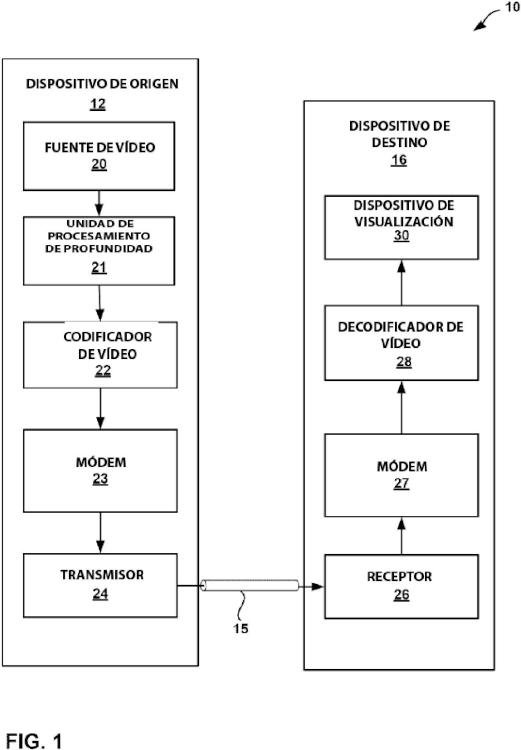
Fragmento de la descripción:
Predicción de cabecera de porciones para mapas de profundidad en códecs de vídeo tridimensionales La presente solicitud reivindica el beneficio de las Solicitudes Provisionales de Estados Unidos Nº 61/510.738, presentada el 22 de julio de 2011, Nº 61/522.584, presentada el 11 de agosto de 2011, Nº 61/563.772, presentada el 26 de noviembre de 2011, y Nº 61/624.031, presentada el 13 de abril de 2012.
Campo técnico
La presente divulgación se refiere al campo de la codificación de vídeos, por ejemplo, codificación de datos de vídeo tridimensionales.
Antecedentes Las capacidades de vídeo digitales se pueden incorporar en una amplia gama de dispositivos, incluyendo televisores digitales, sistemas de radiodifusión directa digitales, dispositivos de comunicación inalámbricos, tales como terminales de radioteléfonos, sistemas de transmisión inalámbricos, asistentes digitales personales (PDA) , ordenadores portátiles u ordenadores de escritorio, cámaras digitales, dispositivos de grabación digitales, dispositivos de videojuegos, consolas de videojuegos, y similares. Los dispositivos de vídeo digitales implementan técnicas de compresión de vídeo, tales como MPEG-2, MPEG-4 o H.264/MPEG-4, Parte 10, Codificación de Vídeo Avanzada (AVC) , para transmitir y recibir vídeos digitales más eficazmente. Las técnicas de compresión de vídeo realizan una predicción espacial y temporal para reducir o eliminar la redundancia inherente en las secuencias de vídeo.
Las técnicas de compresión de vídeo realizan una predicción espacial y/o una predicción temporal para reducir o eliminar la redundancia inherente en las secuencias de vídeo. Para la codificación de vídeos basándose en bloques, un fotograma o franje de vídeo se pueden dividir en macrobloques. Cada macrobloque se puede dividir aún más. Los macrobloques en un fotograma o porción intra-codificado (I) se codifican utilizando predicción espacial con respecto a los macrobloques vecinos. Los macrobloques en un fotograma o porción inter-codificado (P o B) pueden utilizar predicción espacial con respecto a los macrobloques vecinos en el mismo fotograma o una porción o predicción temporal con respecto a otros fotogramas de referencia.
Después de que los datos de vídeo se han codificado, los datos de vídeo pueden empaquetarse para su transmisión o almacenamiento. Los datos de vídeo se pueden recopilar en un archivo de vídeo en conformidad con cualquiera de una variedad de normas, tales como formato de archivo multimedia de base de la Organización Internacional de Normalización (ISO) y sus extensiones, tales como AVC.
Se han realizado esfuerzos para desarrollar nuevos estándares de codificación de vídeos basándose en H.264/AVC. Uno de tales estándares es el estándar de codificación de vídeos escalable (SVC) , que es la extensión escalable de H.264/AVC. Otro estándar es la codificación de vídeos en múltiples vistas (MVC) , que se ha convertido en la extensión de múltiples vistas de H.264/AVC. Un proyecto conjunto de la MVC se describe en JVT-AB204, "Proyecto Conjunto 8.0 en Codificación de vídeos de Múltiples Vistas". 28ª sesión JVT, Hannover, Alemania, julio de 2008, disponible en http://wftp3.itu.int/av-arch/ JVT-site/2008_07_Hannover/JVT-AB204.zip. Una versión de la norma AVC se describe en JVT-AD007, "Revista del proyecto de los Editores a la Codificación de Vídeo Avanzada UIT-T Rec H.264|ISO/IEC 14496-10 -en preparación para el Consentimiento UIT-T SG 16 AAP (en forma integrada) , "Reunión JVT 30, Ginebra, CH, febrero de 2009", disponible en http://wftp3.itu.int/av-arch/jvt-site/2009_01_Geneva/JVTAD007.zip. La presente memoria integra SVC y MVC en la especificación de AVC.
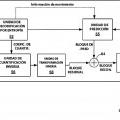
Sumario En general, la presente divulgación describe técnicas para soportar procesamiento de vídeos tridimensionales (3D) . En particular, las técnicas de la presente divulgación se refieren a la codificación y decodificación de contenidos de vídeos 3D. La presente divulgación propone también técnicas de señalación para unidades de bloque codificadas de datos de vídeo. Por ejemplo, la presente divulgación propone la reutilización de elementos de sintaxis incluidos en una cabecera de porciones de componentes de vista de textura para componentes de vista de profundidad correspondientes. Adicionalmente, la presente divulgación propone la reutilización de elementos de sintaxis en la información de cabecera de porciones de componentes de vista de profundidad para componentes de vista de textura.
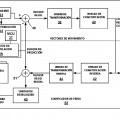
En un codec 3D, un componente de vista de cada vista de datos de vídeo en un instante de tiempo específica puede incluir un componente de vista de textura y un componente de vista de profundidad. El componente de vista de textura puede incluir componentes de luminancia (Y) y componentes de crominancia (Cb y Cr) . Los componentes de luminancia (brillo) y crominancia (color) se denominan colectivamente en la presente memoria como componentes "textura". El componente de vista de profundidad puede ser un mapa de profundidad de una imagen. En la representación de imágenes en 3D, los mapas de profundidad incluyen componentes de profundidad que son representativos de valores de profundidad, por ejemplo, para los componentes de textura correspondientes. Los componentes de vista de profundidad se pueden utilizar para generar vistas virtuales desde una perspectiva de vista
proporcionada.
Los elementos de sintaxis para los componentes de profundidad y los componentes de textura pueden señalarse con una unidad de bloque codificado. Las unidades de bloques codificados, también conocido simplemente como "bloques codificados" en la presente divulgación, pueden corresponder a macrobloques en UIT-T H.264/AVC (Codificación de Vídeo Avanzada) o unidades de codificación de Codificación de vídeos de Alta Eficiencia (HEVC) .
En un aspecto, un procedimiento de decodificación incluye la recepción de una porción de textura para un componente de vista de textura asociado con uno o más bloques codificados de datos de vídeo representativos de la información de textura, comprendiendo la porción de textura el uno o más bloques codificados y una cabecera de porciones de textura que comprende elementos de sintaxis representativos de las características de la porción de textura. El procedimiento incluye además recibir una porción de profundidad para un componente de vista de profundidad asociado con uno o más bloques codificados de la información de profundidad correspondiente al componente de vista de textura, en el que la porción de profundidad comprende el uno o más bloques codificados de la información de profundidad y una cabecera de porciones de profundidad que comprende elementos de sintaxis representativos de las características de la porción de profundidad, y en el que el componente de vista de profundidad y el componente de vista de textura pertenecen ambos a una unidad de vista y acceso. El procedimiento comprende además decodificar una primera porción, en el que la primera porción comprende una de la porción de textura y de la porción de profundidad, en el que la primera porción tiene una cabecera de porciones que comprende todos los elementos de sintaxis representativos de las características de la primera porción y la determinación de los elementos de sintaxis comunes para una segunda porción de la cabecera de porciones de la primera porción. El procedimiento puede incluir además la decodificación de la segunda porción después de la codificación de la primera porción, al menos parcialmente basándose en los elementos de sintaxis comunes determinados, en el que la segunda porción comprende una de la porción de textura y porción de profundidad diferentes de la primera porción, en el que la segunda porción tiene una cabecera de porciones que comprende elementos de sintaxis representativos de las características de la segunda porción, excluyendo los valores de los elementos de sintaxis comunes a la primera porción.
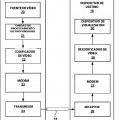
En otro aspecto, un dispositivo para la decodificación de datos incluye un decodificador de vídeo configurado para recibir una porción de textura para un componente de vista de textura asociado con uno o más bloques codificados de datos de vídeo representativos de la información de textura, comprendiendo la porción de textura el uno o más bloques codificados y una cabecera de porciones de textura que comprende elementos de sintaxis representativos de las características de la porción de textura, recibir una porción de profundidad para un componente de vista de profundidad asociado con uno o más bloques codificados de la información de profundidad correspondiente al componente de vista de textura, en el que la porción de profundidad comprende el uno o más bloques codificados de... [Seguir leyendo]
Reivindicaciones:
1. Un procedimiento de decodificación de datos de vídeo, comprendiendo el procedimiento:
recibir una porción de textura para un componente de vista de textura asociado con uno o más bloques codificados de datos de vídeo representativos de información de textura, comprendiendo la porción de textura el uno o más bloques codificados y una cabecera de porciones de textura que comprende elementos de sintaxis representativos de características de la porción de textura; recibir una porción de profundidad para un componente de vista de profundidad asociado con uno o más bloques codificados de información de profundidad correspondiente al componente de vista de textura, en el que la porción de profundidad comprende el uno o más bloques codificados de información de profundidad y una cabecera de porciones de profundidad que comprende elementos de sintaxis representativos de características de la porción de profundidad, y en el que el componente de vista de profundidad y el componente de vista de textura pertenecen ambos a una vista y a una unidad de acceso; decodificar una primera porción, en el que la primera porción comprende la porción de textura, en el que la primera porción tiene una cabecera de porciones que comprende elementos de sintaxis representativos de características de la primera porción; determinar elementos de sintaxis comunes para una segunda porción a partir de la cabecera de porciones de la primera porción; y decodificar la segunda porción después de la decodificación de la primera porción, al menos parcialmente basándose en los elementos de sintaxis comunes determinados, en el que la segunda porción comprende la porción de profundidad, en el que la segunda porción tiene una cabecera de porciones que comprende elementos de sintaxis representativos de características de la segunda porción, excluyendo valores para los elementos de sintaxis que son comunes con la primera porción.
2. El procedimiento de la reivindicación 1, en el que la cabecera de porciones de la segunda porción comprende uno
o más de:
un elemento de sintaxis señalado de una identificación de un conjunto de parámetros de una imagen de referencia; un elemento de sintaxis señalado de una diferencia de parámetros de cuantificación entre un parámetro de cuantificación de la segunda porción y un parámetro de cuantificación señalado en un conjunto de parámetros de imagen; un elemento de sintaxis señalado de una posición de partida de uno de los bloques codificados; un número de fotograma; un recuento del orden de imágenes de la segunda porción; elementos de sintaxis relacionados con una construcción de la lista de imágenes de referencia; un número de fotogramas de referencia activos para cada lista; una tabla de sintaxis de modificación de la lista de imágenes de referencia; una tabla de ponderación de predicción; y elementos de sintaxis relacionados con parámetros de filtro de desbloqueo o parámetros de filtrado de bucle adaptativo para la segunda porción.
3. El procedimiento de cualquiera de las reivindicaciones 1-2, que comprende además:
determinar que una posición de partida de la porción profundidad es cero cuando una posición de partida del componente de vista de profundidad no se señala en la cabecera de porciones de textura o en la cabecera de porciones de profundidad.
4. Un dispositivo para la decodificación de datos de vídeo, que comprende:
medios para recibir una porción de textura para un componente de vista de textura asociado con uno o más bloques codificados de datos de vídeo representativos de información de textura, comprendiendo la porción de textura el uno o más bloques codificados y una cabecera de porciones textura que comprende elementos de sintaxis representativos de características de la porción de textura; medios para recibir una porción de profundidad para un componente de vista de profundidad asociado con uno o más bloques codificados de información de profundidad correspondiente al componente de vista de textura, en el que la porción de profundidad comprende el uno o más bloques codificados de información de profundidad y una cabecera de porciones de profundidad que comprende elementos de sintaxis representativos de características de la porción de profundidad, y en el que el componente de vista de profundidad y el componente de vista de textura pertenecen ambos a una vista y a una unidad acceso; medios para decodificar una primera porción, en el que la primera porción comprende la porción de textura, en el que la primera porción tiene una cabecera de porciones que comprende elementos de sintaxis representativos de características de la primera porción; medios para determinar los elementos de sintaxis comunes para una segunda porción a partir de la cabecera de porciones de la primera porción; y medios para decodificar la segunda porción después de la decodificación de la primera porción, al menos
parcialmente basándose en los elementos de sintaxis comunes determinados, en el que la segunda porción comprende la porción de profundidad, en el que la segunda porción tiene una cabecera de porciones que comprende elementos de sintaxis representativos de características de la segunda porción, excluyendo valores para los elementos de sintaxis que son comunes a la primera porción.
5. El dispositivo de la reivindicación 4, en el que la cabecera de porciones de la segunda porción comprende uno o más de:
un elemento de sintaxis señalado de una identificación de un conjunto de parámetros de una imagen de referencia; un elemento de sintaxis señalado de una diferencia de parámetros de cuantificación entre un parámetro de cuantificación de la segunda porción y un parámetro de cuantificación señalado en un conjunto de parámetros de imagen; un elemento de sintaxis señalado de una posición de partida de uno de los bloques codificados; un número de fotograma; un recuento del orden de imágenes de la segunda porción; elementos de sintaxis relacionados con una construcción de la lista de imágenes de referencia; un número de fotogramas de referencia activos para cada lista; una tabla de sintaxis de modificación de la lista de imágenes de referencia; una tabla de ponderación de predicción; y elementos de sintaxis relacionados con parámetros de filtro de desbloqueo o parámetros de filtrado de bucle adaptativo para la segunda porción.
6. Un procedimiento de codificación de datos de vídeo, comprendiendo el procedimiento:
recibir una porción de textura para un componente de vista de textura asociado con uno o más bloques de datos de vídeo representativos de información de textura, comprendiendo la porción de textura el uno o más bloques y una cabecera de porciones textura que comprende elementos de sintaxis representativos de características de la porción de textura; recibir una porción de profundidad para un componente de vista de profundidad asociado con uno o más bloques de información de profundidad correspondiente al componente de vista de textura, en el que la porción de profundidad comprende el uno o más bloques de información de profundidad y una cabecera de porciones de profundidad que comprende elementos de sintaxis representativos de características de la porción de profundidad, y en el que el componente de vista de profundidad y el componente de vista de textura pertenecen ambos a una vista y a una unidad de acceso; codificar una primera porción, en el que la primera porción comprende la porción de textura, en el que la primera porción tiene una cabecera de porciones que comprende elementos de sintaxis representativos de características de la primera porción; determinar los elementos de sintaxis comunes para una segunda porción a partir de la cabecera de porciones de la primera porción; y codificar la segunda porción después de la codificación de la primera porción, al menos parcialmente basándose en los elementos de sintaxis comunes determinados, en el que la segunda porción comprende la porción de profundidad, en el que la segunda porción tiene una cabecera de porciones que comprende elementos de sintaxis representativos de características de la segunda porción, excluyendo valores para los elementos de sintaxis que son comunes a la primera porción.
7. El procedimiento de la reivindicación 6, en el que la cabecera de porciones de la segunda porción comprende uno
o más de:
un elemento de sintaxis señalado de una identificación de un conjunto de parámetros de una imagen de referencia; un elemento de sintaxis señalado de una diferencia de parámetros de cuantificación entre un parámetro de cuantificación de la segunda porción y un parámetro de cuantificación señalado en un conjunto de parámetros de imagen; un elemento de sintaxis señalado de una posición de partida de uno de los bloques codificados; un número de fotograma; un recuento del orden de imágenes de la segunda porción; elementos de sintaxis relacionados con una construcción de la lista de imágenes de referencia; un número de fotogramas de referencia activos para cada lista; una tabla de sintaxis de modificación de la lista de imágenes de referencia; una tabla de ponderación de predicción; y elementos de sintaxis relacionados con parámetros de filtro de desbloqueo o parámetros de filtrado de bucle adaptativo para la segunda porción.
8. El procedimiento de cualquiera de las reivindicaciones 6-7, que comprende además:
determinar que una posición de partida de la porción profundidad es cero cuando una posición de partida del componente de vista de profundidad no se señala en la cabecera de porciones de textura o en la cabecera de porciones de profundidad.
9. El procedimiento de cualquiera de las reivindicaciones 6-8, que comprende además:
señalar una indicación de qué elementos de sintaxis están explícitamente señalados en la cabecera de porciones de la segunda porción en el conjunto de parámetros de secuencia.
10. Un dispositivo para la codificación de datos de vídeo, que comprende:
medios para recibir una porción de textura para un componente de vista de textura asociado con uno o más bloques de datos de vídeo representativos de información de textura, comprendiendo la porción de textura el uno o más bloques y una cabecera de porciones textura que comprende elementos de sintaxis representativos de características de la porción de textura; medios para recibir una porción de profundidad para un componente de vista de profundidad asociado con uno o más bloques de información de profundidad correspondiente al componente de vista de textura, en el que la porción de profundidad comprende el uno o más bloques de información de profundidad y una cabecera de porciones de profundidad que comprende elementos de sintaxis representativos de características de la porción de profundidad, y en el que el componente de vista de profundidad y el componente de vista de textura pertenecen ambos a una vista y a una unidad de acceso; medios para codificar una primera porción, en el que la primera porción comprende la porción de textura, en el que la primera porción tiene una cabecera de porciones que comprende elementos de sintaxis representativos de características de la primera porción; medios para determinar los elementos de sintaxis comunes para una segunda porción a partir de la cabecera de porciones de la primera porción; y medios para codificar la segunda porción después de la codificación de la primera porción, al menos parcialmente basándose en los elementos de sintaxis comunes determinados, en el que la segunda porción comprende la porción de profundidad, en el que la segunda porción tiene una cabecera de porciones que comprende elementos de sintaxis representativos de características de la segunda porción, sin repetir valores para los elementos de sintaxis que son comunes a la primera porción.
11. El dispositivo de la reivindicación 10, en el que la cabecera de porciones de la segunda porción comprende uno o más de:
un elemento de sintaxis señalado de una identificación de un conjunto de parámetros de una imagen de referencia; un elemento de sintaxis señalado de una diferencia de parámetros de cuantificación entre un parámetro de cuantificación de la segunda porción y un parámetro de cuantificación señalado en un conjunto de parámetros de imagen; un elemento de sintaxis señalado de una posición de partida de uno de los bloques codificados; un número de fotograma; un recuento del orden de imágenes de la segunda porción; elementos de sintaxis relacionados con una construcción de la lista de imágenes de referencia; un número de fotogramas de referencia activos para cada lista; una tabla de sintaxis de modificación de la lista de imágenes de referencia; una tabla de ponderación de predicción; y elementos de sintaxis relacionados con parámetros de filtro de desbloqueo o parámetros de filtrado de bucle adaptativo para la segunda porción.
12. El dispositivo de cualquiera de las reivindicaciones 10-11, que comprende además:
medios para señalar una indicación de qué elementos de sintaxis están explícitamente señalados en la cabecera de porciones de la segunda porción en el conjunto de parámetros de secuencia.
13. Un medio de almacenamiento legible por ordenador que tiene almacenado en su interior instrucciones que, cuando son ejecutadas, hacen que un procesador de un dispositivo de descodificación de vídeos realice el procedimiento de cualquier combinación de las reivindicaciones 1-3 o hacen que un procesador de un dispositivo de descodificación de vídeos realice el procedimiento de cualquier combinación de las reivindicaciones 6-9.
Patentes similares o relacionadas:
Procedimiento de codificación de imágenes, procedimiento de descodificación de imágenes, aparato de codificación de imágenes, aparato de descodificación de imágenes y aparato de codificación / descodificación de imágenes, del 27 de Mayo de 2020, de Sun Patent Trust: Un procedimiento de codificación de imágenes que comprende: dividir (S201) una imagen en mosaicos; codificar (S202) los mosaicos para […]
Procedimiento de codificación de imágenes, procedimiento de descodificación de imágenes, dispositivo de codificación de imágenes, dispositivo de descodificación de imágenes y dispositivo de codificación/descodificación de imágenes, del 29 de Abril de 2020, de Sun Patent Trust: Un procedimiento de descodificación de imágenes de descodificación de un flujo de bits para generar un bloque descodificado, comprendiendo el procedimiento de descodificación […]
Sistema interactivo y procedimiento para transmitir imágenes clave seleccionadas de un flujo de vídeo sobre una red de ancho de banda bajo, del 22 de Abril de 2020, de THALES: Un procedimiento de transmisión en línea de una secuencia de vídeo de alta resolución compuesta por una sucesión de imágenes T, caracterizado porque comprende al […]
Procedimiento de codificación de imágenes, procedimiento de decodificación de imágenes, dispositivo de codificación de imágenes, y dispositivo de decodificación de imágenes, del 1 de Enero de 2020, de Sun Patent Trust: Un procedimiento de codificación para codificar bloques de imágenes por medio de inter predicción en base a imágenes de referencia codificadas […]
Inferencia mejorada de indicador de no emisión de imagen previa en codificación de video, del 18 de Diciembre de 2019, de QUALCOMM INCORPORATED: Un aparato para codificar o decodificar información de video, comprendiendo el aparato: medios para almacenar información de video asociada con una capa actual; medios […]
Dispositivo de procesamiento de imágenes y procedimiento de procesamiento de imágenes, del 4 de Diciembre de 2019, de Velos Media International Limited: Un dispositivo de procesamiento de imágenes que comprende: una unidad configurada para: decodificar datos codificados de datos de imagen para generar […]
Procedimiento de descodificación de imágenes en movimiento, del 6 de Noviembre de 2019, de Godo Kaisha IP Bridge 1: Un procedimiento de descodificación de imágenes para descodificar un flujo de bits de una señal de imagen codificada, comprendiendo el procedimiento de descodificación […]
Procedimiento de descodificación de imágenes en movimiento, del 6 de Noviembre de 2019, de Godo Kaisha IP Bridge 1: Un procedimiento de descodificación de imágenes para descodificar un flujo de bits de una señal de imagen codificada, comprendiendo el procedimiento […]