Método y equipo para la recuperación de fallos en un anillo óptico de ráfagas adaptable y un método de gestión de fallos.
Un método para gestionar el fallo de un Anillo Óptico de Ráfagas Adaptable,
ROBR, que comprende:
aplicar un mecanismo steering (dirección) cuando falla un canal de control; y
aplicar, cuando falla un canal de datos, un mecanismo para dejar de utilizar el canal de datos que falla y continuar utilizando los canales de datos que funcionan correctamente.
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/CN2006/003326.
Solicitante: HUAWEI TECHNOLOGIES CO., LTD..
Nacionalidad solicitante: China.
Dirección: CHINA.
Inventor/es: CHEN, JIANPING, LIU,Yue, WU,Guiling, LI,Xinwan, QIAN,Wenjun.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- H04J14/02 ELECTRICIDAD. › H04 TECNICA DE LAS COMUNICACIONES ELECTRICAS. › H04J COMUNICACIONES MULTIPLEX (peculiar de la transmisión de información digital H04L 5/00; sistemas para transmitir las señales de televisión simultánea o secuencialmente H04N 7/08; en las centrales H04Q 11/00). › H04J 14/00 que utiliza sensores de imagen de estado sólido. › Sistemas múltiplex de división de longitud de onda.
- H04L12/42 H04 […] › H04L TRANSMISION DE INFORMACION DIGITAL, p. ej. COMUNICACION TELEGRAFICA (disposiciones comunes a las comunicaciones telegráficas y telefónicas H04M). › H04L 12/00 Redes de datos de conmutación (interconexión o transferencia de información o de otras señales entre memorias, dispositivos de entrada/salida o unidades de tratamiento G06F 13/00). › Redes en bucle.
- H04Q11/00 H04 […] › H04Q SELECCION (conmutadores, relés, selectores H01H; redes de comunicación inalámbricas H04W). › Dispositivos de selección para sistemas multiplex (sistemas multiplex H04J).
PDF original: ES-2381748_T3.pdf
Fragmento de la descripción:
Método y equipo para la recuperación de fallos en un anillo óptico de ráfagas adaptable y un método de gestión de fallos.
Campo de la invención
La presente invención está relacionada con el campo de las comunicaciones ópticas y, en particular, con un método y un equipo para la recuperación de fallos de un Anillo Óptico de Ráfagas Adaptable (ROBR) y un método de gestión de fallos.
Antecedentes
La Conmutación Óptica de Ráfagas (OBS) es un modelo de red óptica atractivo orientado a la Multiplexación por División de Longitud de Onda Densa (DWDM) de servicios IP de elevada velocidad y elevado índice de ráfagas, y en los últimos años se ha convertido en un tema de actualidad en la investigación dentro del campo de las redes ópticas. En la OBS, un nodo extremo encapsula los datos de usuario en un Paquete de Datos de Ráfaga (BDP) y genera el correspondiente Paquete de Control de Ráfaga (BCP) . El BCP tiene prioridad de transmisión sobre el BDP en el canal de control dedicado, y en los nodos intermedios se reserva el canal exclusivamente óptico para el BDP
correspondiente. El BDP se transmite directamente en el canal exclusivamente óptico preconfigurado después de ser retardado un período en el nodo extremo. Dicho modelo de reserva unidireccional sin la necesidad de confirmación reduce el tiempo de espera de retardo requerido para configurar un canal, y mejora la tasa de utilización del ancho de banda; el BDP de una granularidad media reduce la sobrecarga y mejora la tasa de utilización. La separación del BDP respecto al BCP, una granularidad apropiada y un modo de conmutación sin ranuras de tiempo reducen los requisitos de los componentes ópticos y la complejidad de los nodos de conmutación intermedios, y hacen uso completo de las ventajas de las tecnologías ópticas y las tecnologías electrónicas actuales.
Una red óptica de ráfagas en anillo, caracterizada por una estructura simple y una recuperación automática protectora, no necesita una matriz de conmutación rápida a gran escala, y puede gestionar la estructura de red óptica popularizada en la actualidad para proteger las inversiones realizadas. Por lo tanto, la red de conmutación óptica de ráfagas en anillo basada en una topología de anillo es de importancia práctica.
En los últimos años, se considera la red óptica de ráfagas en anillo como un modo de conmutación ideal de la Internet de próxima generación exclusivamente óptica, y acapara más y más atención.
La Figura 1 muestra la estructura de un Anillo Óptico de Ráfagas Adaptable (ROBR) en la técnica anterior.
Un ROBR es una red de conmutación óptica de ráfagas en anillo que integra un Anillo de Paquetes Adaptable (RPR)
y un OBS. El ROBR tiene una estructura de anillo dual inverso como el RPR. Con la integración de las características de OBS en el protocolo de control RPR estandarizado, el ROBR implementa gestión de tiempo de retardo, protección y restauración, y asignación de ancho de banda dinámico equitativo de los anillos ópticos de ráfagas. Más aún, el BDP se transmite en modo exclusivamente óptico, y es transparente al formato y velocidad del paquete de datos. El ROBR se caracteriza por: comparado con el RPR, el ROBR reserva recursos de canal de forma unidireccional y es específico de un grupo de canales de datos y un grupo de canales de control, respectivamente; comparado con el OBS, el ROBR adopta una estructura de red en anillo y un modo de control basado en el anillo de paquetes adaptable.
La Figura 1 muestra la estructura de una red de ROBR. Un ROBR es una estructura de anillo doble inverso. El anillo externo se conoce generalmente como anillo 1, y el anillo interno se conoce generalmente como anillo 0. Cada anillo 40 tiene N+1 canales de longitud de onda, incluyendo un canal de control y N canales de datos. El canal de control se utiliza para transmitir los BCPs, mientras que los canales de datos se utilizan para transmitir los BDPs. El nodo del ROBR encapsula en un BDP los paquetes de datos que vienen de la subred local y que deberán pasar a través de la red ROBR, y envía el BDP a un anillo (determinado por el modo de selección de anillo) mediante conmutación de ráfagas. Los paquetes de datos dirigidos a la subred local se desvían a la subred correspondiente. Más aún, el nodo 45 del ROBR transfiere o procesa el BCP y el BDP correspondiente en función de la información recibida en el BCP procedente del canal de control. El BDP destinado al nodo local se devuelve al paquete de datos original (como por ejemplo un paquete IP) y, a continuación, se desvía a la subred correspondiente. La Tabla 1 es una comparación de las características de una red RPR con una red ROBR.
Tabla 1 Comparación entre las características de una red RPR y una red ROBR La comparación anterior indica que el ROBR se diferencia del RPR en que:
Condiciones de red correspondientes protección y restauración de RPR a la Óptica/eléctrica/óptica, punto a punto, cabecera del paquete unida al paquete de datos, anillo bidireccional de dos fibras Condiciones de red correspondientes protección y restauración de ROBR a la Combinación óptica-eléctrica (óptica/eléctrica/óptica para el BCP, exclusivamente óptica para el BDP) , cabecera BCP separada del BDP, anillo bidireccional de dos fibras1. En el ROBR, la cabecera BCP está separada del BDP en términos de tiempo y longitud de onda; y
2. El canal de datos del ROBR es exclusivamente óptico y no es punto a punto.
La protección y la restauración es una de las claves para la implementación de redes operables. Sin embargo, hasta ahora, no se ha presentado ninguna investigación sobre la protección y restauración de redes ópticas de ráfagas en anillo. En otras palabras, la técnica anterior no proporciona protección ni restauración de redes ópticas de ráfagas en anillo.
A continuación se describe el modelo de recuperación de fallos RPR con referencia a la Tabla 2, Figura 2 y Figura 3.
La Figura 2 muestra el mecanismo steering (dirección) del RPR en la técnica anterior, la Figura 3 muestra el mecanismo wrapping (cambio de dirección) del RPR en la técnica anterior, y la Figura 4 muestra el mecanismo passthrough (traspaso) del RPR en la técnica anterior.
Tabla 2 tipos de protección y detección del RPR
Tipo de fallo Detección y localización del fallo Nodo Fallo software Comprobación de consistencia Fallo hardware: la función de reenvío sigue funcionando Monitorización de pulsos Fallo hardware: la función de reenvío no funciona, por ejemplo, falla la fuente de alimentación o está desenchufada la tarjeta Autocomprobación Fallo del enlaceFallo del transmisor óptico Alarma de potencia óptica o del circuito de control: Signal_Failure (Fallo de la Señal) o Signal_Degrade (Degradación de la Señal) Falo del receptor óptico Alarma de potencia óptica, Relación Señal Ruido Ópticos (OSNR) , y circuito de detección: Signal_Failure o Signal_Degrade Corte en la fibra Detección de la potencia óptica: Signal_Failure Error de conexión del cable óptico (conexión incorrecta de los cables) Error de conexión del cable óptico: Signal_Failure GestiónConmutación forzada Notificación de orden de gestión a la MAC: Forced_Switch (Conmutación forzada) Conmutación manual Notificación de orden de gestión a la MAC: Manual_Switch (Conmutación manual)El RPR dispone de tres mecanismos de gestión de fallos:
Mecanismo steering: cuando ocurre un fallo, cada nodo (desde S1 a S7) conmuta los datos bajo protección a otro anillo en dirección al destino. Todos los nodos deben soportar este mecanismo. (Ver Figura 2)
Mecanismo wrapping: cuando ocurre un fallo, el nodo próximo al nodo que ha fallado cambia el servicio al anillo inverso. Este mecanismo es opcional. (Ver Figura 3)
Mecanismo passthrough: cuando dentro de un nodo ocurre un fallo software/hardware que no afecta a la función de 20 desvío, el nodo se convierte en un repetidor para desviar todos los paquetes. Este modo es opcional. (Ver Figura 4)
Mediante la comparación anterior, el RPR se diferencia del ROBR en algunas características. En concreto, en el RPR se combina una cabecera de paquete con el paquete de datos, mientras que en el ROBR el canal de datos está separado del canal de control, lo que implica que en el ROBR no se pueda aplicar la gestión de fallos y el mecanismo de recuperación de fallos en su conjunto del RPR.
La solicitud de patente internacional WO 2006030435 A2 divulga... [Seguir leyendo]
Reivindicaciones:
1. Un método para gestionar el fallo de un Anillo Óptico de Ráfagas Adaptable, ROBR, que comprende: aplicar un mecanismo steering (dirección) cuando falla un canal de control; y aplicar, cuando falla un canal de datos, un mecanismo para dejar de utilizar el canal de datos que falla y continuar
utilizando los canales de datos que funcionan correctamente.
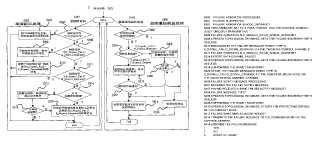
2. El método de acuerdo con la reivindicación 1, que comprende, además: configurar (paso S102) un modelo de fallos en función de las características del ROBR, donde el modelo de fallos cubre al menos los fallos del canal de control y los fallos del canal de datos.
3. El método de acuerdo con la reivindicación 2, que comprende, además: enviar (paso S104) a la capa de Control de Acceso al Medio, MAC, una señal de alarma del fallo correspondiente cuando ocurre al menos un fallo cubierto por el modelo de fallos.
4. El método de acuerdo con cualquiera de las reivindicaciones 1 a 3, donde los tipos de fallo de los canales de control comprenden el fallo de la señal de control y degradación de la señal de control, y el mecanismo steering cuando falla el canal de control comprende:
desviar un servicio si el tipo de fallo de un canal de control en un anillo es un fallo de la señal de control;
desviar un servicio si el tipo de fallo de un canal de control en un anillo es una degradación de la señal de control y el anillo inverso funciona normalmente; y mantener sin cambios la dirección del anillo de proceso actual si el tipo de fallo de un canal de control en un anillo es una degradación de la señal de control y el tipo de fallo en el anillo inverso es un fallo de la señal de control.
5. El método de acuerdo con cualquiera de las reivindicaciones 1 a 3, donde el modo para dejar de utilizar el canal de datos que falla comprende:
dejar de utilizar, por parte de un primer nodo, el canal de datos que falla si el fallo del canal de datos que falla se localiza en un puerto de salida del primer nodo del fallo; y enviar una notificación del fallo a un nodo adyacente anterior a través de un canal de control del anillo inverso si el primer nodo no soporta conversión de la longitud de onda;
enviar una notificación del fallo a través de un canal de control del anillo inverso si el fallo del canal de datos se localiza en el puerto de entrada del primer nodo; y configurar, por parte del nodo adyacente anterior que recibe la notificación del fallo del canal de datos, el canal de datos que falla como deshabilitado; desviar la notificación del fallo si el nodo adyacente anterior no soporta conversión de la longitud de onda; y absorber la notificación del fallo si el nodo adyacente anterior soporta conversión de la longitud de onda.
6. El método de acuerdo con cualquiera de las reivindicaciones 1 a 5, que comprende, además:
aplicar el mecanismo steering con ajuste del tiempo de retardo en el caso de un fallo de enlace o un fallo asociado a un traspaso; y/o aplicar un mecanismo de traspaso en el caso de un fallo de un nodo no relacionado con la desviación de la señal.
7. El método de acuerdo con la reivindicación 6, donde el mecanismo de traspaso comprende: forzar a una tarjeta de control del nodo que falla para que desvíe directamente el paquete de control anterior; y configurar todos los canales del Multiplexor Óptico para Añadir/Descartar, OADM, como traspaso.
8. El método para gestionar fallos de acuerdo con cualquiera de las reivindicaciones 1 a 5, donde el mecanismo steering se acompaña por un ajuste del tiempo de retardo.
9. El método de gestión de fallos de acuerdo con la reivindicación 8, donde el mecanismo steering con ajuste del tiempo de retardo comprende:
difundir la notificación del fallo por parte de un segundo nodo que detecta el fallo; y desviar, por parte del primer nodo que detecta y/o recibe localmente la notificación del fallo, el servicio que viene del primer nodo y pasa a través del segundo nodo al anillo en dirección al nodo de destino, y ajustar el tiempo de retardo, y descartar el servicio bajo protección que pasa a través del primer nodo.
10. El método de acuerdo con cualquiera de las reivindicaciones 1 a 9, donde se determina el tipo de fallo mediante detección y localización de fallos; y la detección del fallo se realiza en el modo de separación del canal de datos del canal de control.
11. Un equipo de gestión de recuperación de fallos de un Anillo Óptico de Ráfagas Adaptable (ROBR) , que comprende:
un módulo (30) de conmutación con protección, adaptado para aplicar un mecanismo steering cuando falla un canal de control; y, cuando falla un canal de datos, aplicar un mecanismo para dejar de utilizar el canal de datos que falla y continuar la utilización de los canales de datos que funcionan correctamente.
12. El equipo de acuerdo con la reivindicación 11, que comprende, además:
un módulo (10) de modelado, adaptado para establecer un modelo de fallos en función de las características del ROBR, donde el modelo de fallos cubre, al menos, los fallos del canal de control y los fallos del canal de datos.
13. El equipo de acuerdo con la reivindicación 12, que comprende, además:
un módulo (20) de generación de señal, adaptado para enviar una señal de alarma de fallo apropiada a la capa MAC cuando ocurre al menos un fallo cubierto por el modelo de fallos.
14. El equipo de acuerdo con cualquiera de la reivindicación 13, donde el módulo (30) de conmutación con protección comprende:
un primer submódulo de proceso, adaptado para ejecutar el mecanismo steering con ajuste del tiempo de retardo si la señal de alarma se corresponde con un fallo de un canal de control; y un segundo submódulo de proceso, adaptado para dejar de utilizar el canal de datos que falla y continuar utilizando los canales de datos que funcionan correctamente, si la señal de alarma se corresponde con un fallo del canal de datos.
15. El equipo de la reivindicación 14, donde:
si el modelo de fallos cubre fallos de nodos no relacionados con el traspaso, el módulo (30) de conmutación con protección comprende, además: un tercer submódulo de proceso, adaptado para ejecutar la acción de traspaso cuando la señal de alarma se corresponde con un fallo del nodo no relacionado con el traspaso;
si el modelo de fallos cubre fallos de nodos y/o fallos de enlaces relacionados con el traspaso, el primer submódulo de proceso se adapta, además, para ejecutar el mecanismo steering con ajuste del tiempo de retardo cuando la señal de alarma se corresponde con los fallos de nodos y/o fallos de enlaces relacionados con el traspaso.
16. El equipo de la reivindicación 15, donde el tercer submódulo de proceso comprende:
una unidad de desvío, adaptada para forzar que la tarjeta de control del nodo que falla desvíe directamente el paquete de control procedente del nodo anterior; y una unidad de configuración del traspaso, adaptada para configurar todos los canales de OADM del nodo que falla para que apliquen el mecanismo passthrough.
17. El equipo de acuerdo con cualquiera de las reivindicaciones 14 a 16, donde el primer submódulo de proceso comprende:
una unidad de difusión, adaptada para hacer que un segundo nodo que detecta el fallo difunda la notificación del fallo;
una unidad de configuración del tiempo de retardo, adaptada para hacer que un primer nodo, que detecta y/o recibe localmente la notificación del fallo, desvíe un servicio que viene del primer nodo y atraviesa el segundo nodo del anillo en dirección a un nodo de destino, y para ajustar el tiempo de retardo; y una unidad de descarte, adaptada para descartar un servicio que atraviesa el primer nodo y necesita protección.
18. El equipo de acuerdo con cualquiera de las reivindicaciones 14 a 16, donde el segundo submódulo de proceso comprende:
una primera unidad de bloqueo, adaptada para hacer que el primer nodo deje de utilizar el canal de datos que falla si el fallo está localizado en un puerto de salida del primer nodo del fallo; y hacer que el primer nodo envíe una notificación del fallo al nodo adyacente anterior a través del canal de control del anillo inverso si el primer nodo no soporta conversión de longitud de onda;
una segunda unidad de bloqueo, adaptada para hacer que el primer nodo envíe una notificación de fallo a través de un canal de control del anillo inverso si el fallo está localizado en un puerto de entrada del primer nodo;
una tercera unidad de bloqueo, adaptada para hacer que el nodo adyacente anterior, que recibe la notificación del fallo del canal de datos, deshabilite el canal de datos correspondiente; y una cuarta unidad de bloqueo, adaptada para hacer que el nodo adyacente anterior desvíe la notificación del fallo si el nodo adyacente anterior no soporta conversión de longitud de onda; o hacer que el nodo adyacente anterior 5 absorba la notificación del fallo si el nodo anterior soporta conversión de longitud de onda.
19. El equipo de acuerdo con cualquiera de las reivindicaciones 14 a 16, donde el módulo (20) de generación de señal comprende un submódulo de monitorización de enlaces, adaptado para determinar el tipo de fallo mediante la detección y localización de fallos; y la detección de fallos se realiza en el modo de separación del canal de datos del canal de control.
Patentes similares o relacionadas:
Detección de rotura de cables en comunicaciones redundantes, del 22 de Abril de 2020, de Tesla, Inc: Sistema de comunicaciones de datos que comprende: una pluralidad de módulos de batería que incluyen: un primer módulo de batería (110x) que […]
Procedimiento de comunicación ferroviaria, del 26 de Junio de 2019, de EAcom Systems, S.L: Procedimiento de comunicación ferroviaria. La presente invención se refiere a un procedimiento de comunicaciones ferroviarias entre un puesto móvil que se comunica a través […]
Procedimiento y módulo concentrador para integrar a un socio de comunicación en una red de comunicación cableada, en particular anular, del 3 de Abril de 2019, de PILLER GROUP GMBH (100.0%): Procedimiento para integrar a un socio de comunicación a través de un módulo concentrador , que presenta tres puertos cada uno de ellos con un transmisor […]
Procedimiento y dispositivo de comunicaciones de acoplamiento para la transmisión de mensajes en una red de comunicaciones industrial que puede operarse de forma redundante, del 17 de Octubre de 2018, de SIEMENS AKTIENGESELLSCHAFT: Procedimiento para la transmisión de mensajes en una red de comunicaciones industrial que puede operarse de forma redundante, en el cual - la red […]
Procedimiento para la comunicación de datos entre un número limitado de participantes de comunicación conectados a una red de comunicación común, del 10 de Octubre de 2018, de PILLER GROUP GMBH (100.0%): Procedimiento para la comunicación de datos entre participantes de comunicación (5 a 11) que en un número limitado están conectados a una red de comunicación común , […]
Procedimiento para la transmisión de mensajes en una red de comunicaciones industrial operable de manera redundante y aparato de comunicaciones para una red de comunicaciones industrial operable de manera redundante, del 7 de Febrero de 2018, de SIEMENS AKTIENGESELLSCHAFT: Procedimiento para la transmisión de mensajes en una red de comunicaciones industrial operable de manera redundante, en el que - los mensajes […]
Nodo de red para una red de comunicaciones, del 18 de Octubre de 2017, de SIEMENS AKTIENGESELLSCHAFT: Nodo de red (310, 312, MRM+) para una red de comunicaciones , la cual comprende una primera subred que utiliza un protocolo Spanning […]
Método de configuración de red, del 9 de Agosto de 2017, de HUAWEI TECHNOLOGIES CO., LTD.: Un método de configuración de red, aplicado en un anillo que comprende n nodos, en donde n es mayor que 2 y n es un número natural, que comprende: […]