LOCALIZACIÓN DE FALLOS EN ARQUITECTURAS BASADAS EN MÚLTIPLES ÁRBOLES DE EXPANSIÓN.
Un método de localización de un fallo en una red, comprendiendo la red nodos (SW1,
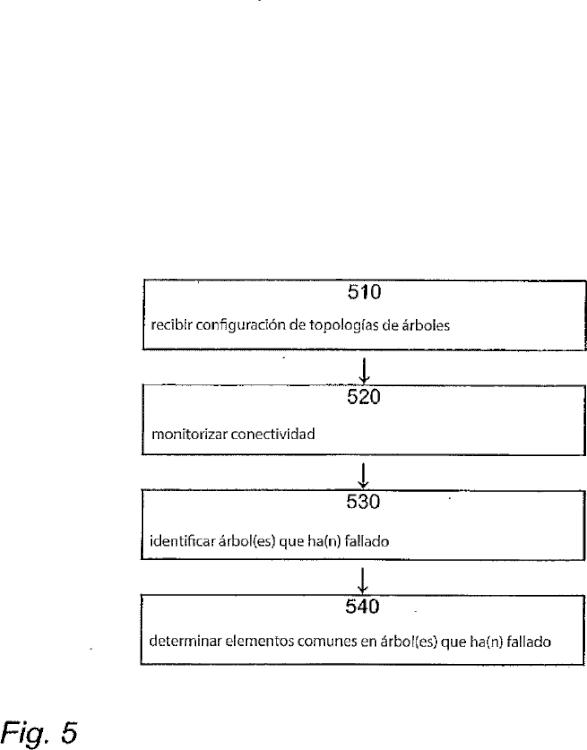
SW2, SW3, SW4), enlaces, y nodos frontera (EN1, EN2, EN3, EN4) configurados en forma de una pluralidad de árboles de expansión, siendo cada árbol un conjunto de nodos y enlaces, siendo parcialmente disjuntos los árboles de expansión; comprendiendo el método las etapas de: - recibir información (510) sobre la configuración de la pluralidad de topologías de árboles en la red; - monitorizar la conectividad (520) de todos los árboles en la red mediante la monitorización de una notificación de pérdida de conectividad en uno o más árboles; recibir una notificación de pérdida de conectividad - al producirse la detección de una notificación de pérdida de conectividad en la red, identificar árboles que han fallado (530); caracterizado porque el método comprende además la etapa de: - determinar la ubicación del fallo (540) como uno de los elementos de red comunes a los árboles que han fallado
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/EP2007/051219.
Solicitante: TELEFONAKTIEBOLAGET LM ERICSSON (PUBL).
Nacionalidad solicitante: Suecia.
Dirección: 164 83 STOCKHOLM SUECIA.
Inventor/es: FARKAS, JANOS, ZHAO, WEI.
Fecha de Publicación: .
Fecha Solicitud PCT: 8 de Febrero de 2007.
Clasificación Internacional de Patentes:
- H04L12/24D
Clasificación PCT:
- H04L12/24 ELECTRICIDAD. › H04 TECNICA DE LAS COMUNICACIONES ELECTRICAS. › H04L TRANSMISION DE INFORMACION DIGITAL, p. ej. COMUNICACION TELEGRAFICA (disposiciones comunes a las comunicaciones telegráficas y telefónicas H04M). › H04L 12/00 Redes de datos de conmutación (interconexión o transferencia de información o de otras señales entre memorias, dispositivos de entrada/salida o unidades de tratamiento G06F 13/00). › Disposiciones para el mantenimiento o la gestión.
Países PCT: Austria, Bélgica, Suiza, Alemania, Dinamarca, España, Francia, Reino Unido, Grecia, Italia, Liechtensein, Luxemburgo, Países Bajos, Suecia, Mónaco, Portugal, Irlanda, Eslovenia, Finlandia, Rumania, Chipre, Lituania, Letonia.
PDF original: ES-2359097_T3.pdf
Fragmento de la descripción:
Campo técnico
La presente invención se refiere a un método para la localización de fallos en redes. Se refiere en particular a un método para localizar fallos en arquitecturas basadas en múltiples árboles de expansión.
Antecedentes
Para que la red de acceso de Ethernet pueda distribuir servicios con calidad de tipo operador, son cada vez más importantes una detección rápida de las averías y un tiempo breve de conmutación por fallo. Después de que se haya detectado una avería y de que los datos se hayan conmutado hacia trayectos alternativos, es necesario que exista un mecanismo para localizar la avería en la red y, a continuación, arreglarla.
El Protocolo Simple de Gestión de Redes (SNMP), RFC1157, proporciona el mecanismo de trampa para que elementos de la red gestionada den la alarma a un sistema de gestión cuando se produce una avería. Las trampas SNMP son eventos predefinidos, entre los cuales, por ejemplo, “enlace averiado” (“link down”) es uno de los eventos más comunes definidos por la RFC 1157 y soportado por todos los proveedores. Cuando se produce una avería de un enlace, el dispositivo de la red gestionada asociado a este enlace emitirá un evento de notificación hacia el sistema de gestión. Tras recibir el evento, el sistema de gestión puede optar por realizar ciertas acciones sobre la base del evento, por ejemplo, arreglar la avería del enlace, etcétera.
Un planteamiento más nuevo, especificado por la IEEE 802.1ag (“Draft Standard for Local and Metropolitan Area Networks – Virtual Bridged Local Area Networks – Amendment 5: Connectivity Fault Management”, IEEE 802.1ag, 2005) intenta afrontar la gestión de averías, incluyendo la localización de las mismas, desde la capa 2. Proporciona tanto una arquitectura como mensajes de trabajo que tienen su correspondencia en la Capa 2 con el Ping y el TraceRoute de IP. La esencia de la arquitectura de 802.1ag se encuentra en los dominios de gestión anidados y en la designación de puntos extremos de mantenimiento y puntos intermedios de mantenimiento. La arquitectura anidada proporciona tanto una visión desde un extremo a otro de la red completa a lo largo del trayecto de aprovisionamiento de servicios como un reproductor responsable detallado de cada asalto de la red. Por tanto, cuando se produce una avería de un enlace, resulta sencillo hace frente a la avería, capa a capa, y llegar al nivel en el que reside la responsabilidad y en el que se deben tomar medidas. Aparte de la propia arquitectura, la 802.1ag define también cuatro mensajes para intercambio de información y localización de averías:
Mensajes de comprobación de continuidad:
Estos son mensajes de “latido” emitidos periódicamente por puntos extremos de mantenimiento. Permiten que los puntos extremos de mantenimiento detecten una pérdida de conectividad de servicio entre ellos mismos. Permiten también que puntos extremos de mantenimiento descubran otros puntos extremos de mantenimiento dentro de un dominio, y permiten que puntos intermedios de mantenimiento descubran puntos extremos de mantenimiento.
Mensajes de rastreo de enlaces:
Los mismos son transmitidos por un punto extremo de mantenimiento al producirse una solicitud, del administrador, de realizar un seguimiento del trayecto (salto a salto) hacia un punto extremo de mantenimiento de destino. Permiten que el nodo de transmisión descubra datos de conectividad vitales sobre el trayecto. El concepto es similar al del Traceroute de IP.
Mensajes de bucle de retorno:
Los mismos son transmitidos por un punto extremo de mantenimiento al producirse una solicitud, del administrador, de verificar la conectividad hacia un punto intermedio de mantenimiento o punto extremo de mantenimiento en particular. El bucle de retorno indica si el punto de mantenimiento objetivo es o no accesible; no permite un descubrimiento del trayecto salto a salto. El concepto es similar al del Eco de ICMP (Ping).
Mensaje de AIS:
Proporcionan una notificación asíncrona a otros elementos de la red informando de que se ha producido un fallo en la red Ethernet metropolitana. La AIS se usa típicamente para suprimir alarmas en elementos de red que no sean aquellos que detectan directamente el fallo.
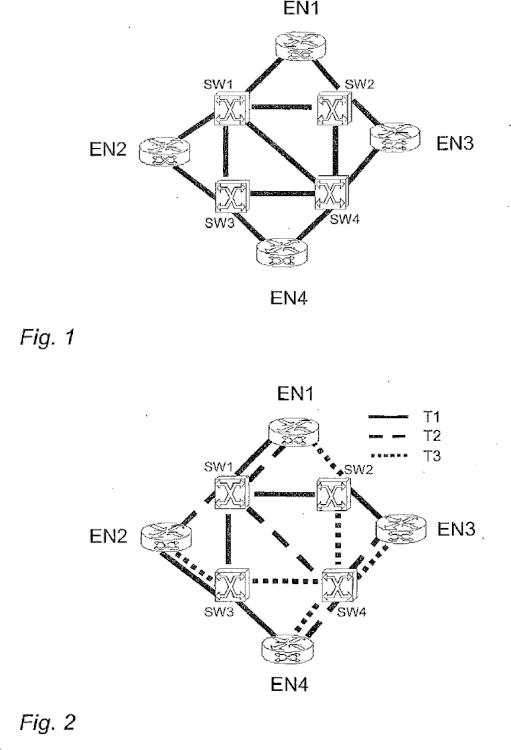
En redes en las que los nodos están interconectados a través de múltiples trayectos, el Protocolo de Árbol de Expansión (STP) puede evitar la formación de bucles. Esto garantiza que exista únicamente un trayecto activo entre dos dispositivos de red cualesquiera. La totalidad de trayectos activos forma un denominado árbol de expansión. ElProtocolo de Múltiples Árboles de Expansión (MSTP) permite establecer una correspondencia de varias VLANs con un número reducido de árboles de expansión. Esto es posible debido a que la mayoría de las redes no requieren más que unas pocas topologías lógicas. Cada árbol puede gestionar múltiples VLANs que tienen la misma topología. Basándose en esto, se han propuesto varias arquitecturas tolerantes a fallos, basadas en múltiples árboles de expansión.
Según describen S. Sharama, K. Gopalan, S. Nanda, y T. Chiueh en “Viking: A multi-spanning-tree Ethernet architecture for metropolitan area and cluster networks”, IEEE INFOCOM 2004, la arquitectura Viking usa múltiples árboles de expansión que se reconfiguran después de un evento de avería. Si ocurre una avería, el Gestor Viking (VM) recibe una notificación por medio de trampas SNMP. El VM notifica entonces a los nodos frontera de la red, de que deben redirigir el tráfico hacia árboles no dañados e inicia el nuevo cálculo y la reconfiguración de los árboles.
Por contraposición, el concepto de una Ethernet flexible de bajo coste se basa en árboles de expansión estáticos que se configuran antes del funcionamiento de la red y no cambian a pesar de la aparición de averías (J. Farkas, C. Antal, G. Toth y L. Westberg, “Distributed Resilient Architecture for Ethernet Networks”, Proceedings of Design of Reliable Communication Networks, 16 a 19 de octubre de 2005, págs. 512 a 522; J. Farkas, C. Antal, L. Westberg, A. Paradisi, T. R. Tronco y V. G. Oliveira, “Fast Failure Handing in Ethernet Networks”, Proceedings of IEEE International Conference on Communications, 11 a 15 de junio de 2006; J. Farkas, A. Paradisi, y C. Antal, “Low-cost survivable Ethernet architecture over fiber”, J. Opt. Netw. 5, págs. 398 a 409, 2006). En esta arquitectura, se implementan una detección de averías y una gestión de fallos de una manera distribuida en los nodos frontera. Esta arquitectura consta de conmutadores de Ethernet convencionales, de serie, de bajo coste, disponibles en el mercado; se excluye cualquier solución que se fundamente en una nueva funcionalidad de los conmutadores de Ethernet, con el fin de mantener la ventaja del precio de los productos de Ethernet actuales. Las funcionalidades adicionales que son necesarias para proporcionar flexibilidad se implementan en forma de un protocolo de software en los nodos frontera de la red Ethernet.
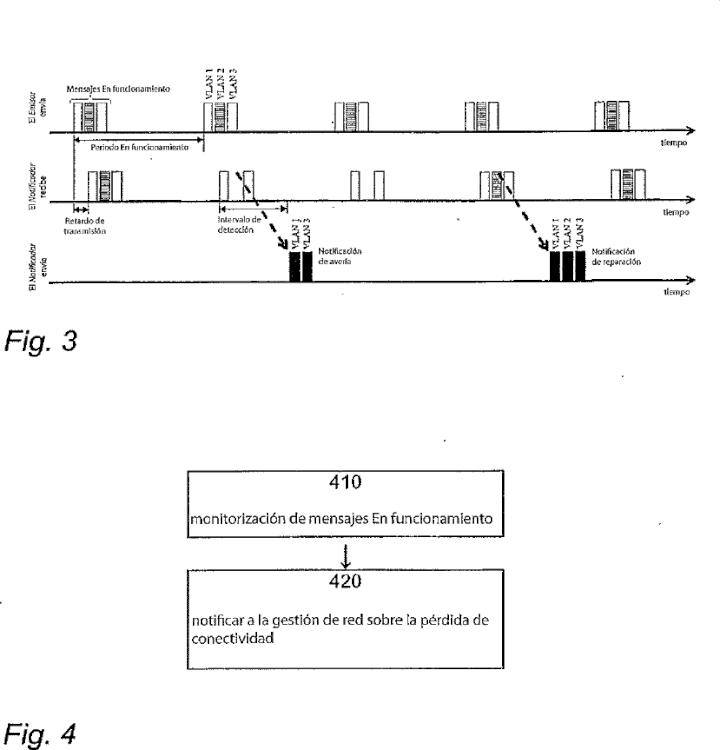
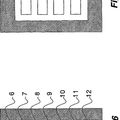
La Fig. 2 muestra un ejemplo correspondiente a dicha arquitectura. Por la red se establecen estáticamente múltiples árboles de expansión predefinidos para que actúen como trayectos o bien principales o bien alternativos que se pueden usar para encaminar tráfico en la red, pudiendo de este modo gestionar posibles averías. Para lograr protección contra cualquier avería individual de un enlace o nodo, la topología de los árboles de expansión debe ser tal que quede por lo menos un árbol funcional completo en caso de avería de cualquier elemento de red individual. Por lo tanto, los árboles de expansión deben ser parcialmente disjuntos, es decir, deben comprender diferentes elementos de red, no pueden ser idénticos. Por ejemplo, se pueden calcular árboles de expansión. Se pueden gestionar múltiples averías con más árboles; es cuestión del diseño de los árboles. Los árboles de expansión se establecen antes de la puesta en marcha de la red, permaneciendo invariables durante el funcionamiento, incluso en presencia de una avería.
En el caso de una avería, cada nodo frontera debe dejar de reenviar tramas a los árboles afectados y debe redirigir el tráfico hacia árboles no dañados. Por lo tanto, es necesario un protocolo para la detección de averías y para notificar a todos los nodos frontera sobre los árboles deteriorados. El tiempo de conmutación por fallo depende principalmente del tiempo transcurrido entre el evento de la avería... [Seguir leyendo]
Reivindicaciones:
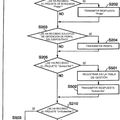
1. Un método de localización de un fallo en una red,
comprendiendo la red nodos (SW1, SW2, SW3, SW4), enlaces, y nodos frontera (EN1, EN2, EN3, EN4) configurados en forma de una pluralidad de árboles de expansión, siendo cada árbol un conjunto de nodos y enlaces, siendo parcialmente disjuntos los árboles de expansión;
comprendiendo el método las etapas de:
- recibir información (510) sobre la configuración de la pluralidad de topologías de árboles en la red;
- monitorizar la conectividad (520) de todos los árboles en la red mediante la monitorización de una notificación de pérdida de conectividad en uno o más árboles; recibir una notificación de pérdida de conectividad
- al producirse la detección de una notificación de pérdida de conectividad en la red, identificar árboles que han fallado (530);
caracterizado porque
el método comprende además la etapa de:
- determinar la ubicación del fallo (540) como uno de los elementos de red comunes a los árboles que han fallado.
2. El método según la reivindicación 1, que comprende además determinar y excluir elementos de red que forman parte de árboles que no han fallado.
3. El método según cualquiera de las reivindicaciones anteriores, que comprende además la etapa de comprobar los elementos de red restantes en busca de un fallo.
4. El método según la reivindicación 1, en el que dicha notificación de pérdida de conectividad comprende una identificación del árbol que ha fallado.
5. El método según la reivindicación 4, en el que dicha notificación de pérdida de conectividad comprende además información del trayecto desde un nodo frontera de difusión general hacia un nodo frontera informador de averías.
6. El método según la reivindicación 4, en el que se aplica una monitorización de conectividad de punto-a-punto y dicha notificación de pérdida de conectividad comprende además información referente a qué conexiones de punto-apunto han fallado.
7. El método según la reivindicación 5, en el que se recupera información del trayecto mediante mensajes de Rastreo de Enlaces.
8. Una gestión de red adaptada para funcionar según todas las etapas del método de acuerdo con una cualquiera de las reivindicaciones 1 a 7.
9. La gestión de red según la reivindicación 8, en la que la gestión de red comprende un servidor.
Patentes similares o relacionadas:
INDICACIÓN DE CABLEADO INCORRECTO DE DISPOSITIVOS, del 6 de Septiembre de 2011, de ABB TECHNOLOGY AG: Procedimiento de identificación de cableado incorrecto de dispositivos (1 a 5) conectados a redes de comunicación industrial redundantes (A, B), que […]
CONTROL Y/O MONITORIZACIÓN DE RENDIMIENTO DE CÉLULA DE RADIO BASADO EN DATOS DE POSICIONAMIENTO DE EQUIPO DE USUARIO Y PARÁMETRO DE CALIDAD DE RADIO, del 24 de Junio de 2011, de NOKIA SIEMENS NETWORKS OY: Sistema de gestión de red, caracterizado porque tiene acceso a un sistema de monitorización de rendimiento de enlace (LPMS) y a una unidad de medición de […]
 PROCEDIMIENTO PARA LA COMUNICACIÓN DE DATOS Y DISPOSITIVO ASÍ COMO SISTEMA DE COMUNICACIÓN, del 19 de Mayo de 2011, de NOKIA SIEMENS NETWORKS OY: Procedimiento para la comunicación de datos entre un sistema de gestión y un elemento de red que comprende las siguientes etapas: - establecer una conexión […]
PROCEDIMIENTO PARA LA COMUNICACIÓN DE DATOS Y DISPOSITIVO ASÍ COMO SISTEMA DE COMUNICACIÓN, del 19 de Mayo de 2011, de NOKIA SIEMENS NETWORKS OY: Procedimiento para la comunicación de datos entre un sistema de gestión y un elemento de red que comprende las siguientes etapas: - establecer una conexión […]
GESTIÓN DE FALLOS DE CONECTIVIDAD PARA SERVICIOS DE TIPO ÁRBOL ETHERNET ( ÁRBOL-E), del 9 de Febrero de 2011, de TELEFONAKTIEBOLAGET L M ERICSSON (PUBL): Un metodo de configurar los Puntos Finales de la Asociacion de Mantenimiento, MEP, para un caso de servicio de tipo Arbol Ethernet, Arbol-E, en el que una […]
 MÉTODO Y SISTEMA DE RETRANSMISIÓN, del 24 de Enero de 2011, de TELEFONAKTIEBOLAGET LM ERICSSON (PUBL): Método de reducción o eliminación de transmisiones a través de una interfaz de radiocomunicaciones en un sistema de comunicaciones, caracterizado el método porque […]
MÉTODO Y SISTEMA DE RETRANSMISIÓN, del 24 de Enero de 2011, de TELEFONAKTIEBOLAGET LM ERICSSON (PUBL): Método de reducción o eliminación de transmisiones a través de una interfaz de radiocomunicaciones en un sistema de comunicaciones, caracterizado el método porque […]
 SISTEMA DE COMUNICACION Y APARATO DE COMUNICACION Y SU PROCEDIMIENTO DE CONTROL, del 23 de Marzo de 2010, de CANON KABUSHIKI KAISHA: Sistema de comunicaciones que comprende un aparato cliente y un aparato proveedor de servicios que proporciona un servicio al […]
SISTEMA DE COMUNICACION Y APARATO DE COMUNICACION Y SU PROCEDIMIENTO DE CONTROL, del 23 de Marzo de 2010, de CANON KABUSHIKI KAISHA: Sistema de comunicaciones que comprende un aparato cliente y un aparato proveedor de servicios que proporciona un servicio al […]
 PROCEDIMIENTO PARA IMPLEMENTAR MANTENIMIENTO EN LINEA EN UNA RED DE COMUNICACION, del 16 de Noviembre de 2009, de HUAWEI TECHNOLOGIES CO., LTD.: Un procedimiento para implementar el mantenimiento en línea en una red de comunicación, que se caracteriza por las etapas de recoger , por un servidor de mantenimiento […]
PROCEDIMIENTO PARA IMPLEMENTAR MANTENIMIENTO EN LINEA EN UNA RED DE COMUNICACION, del 16 de Noviembre de 2009, de HUAWEI TECHNOLOGIES CO., LTD.: Un procedimiento para implementar el mantenimiento en línea en una red de comunicación, que se caracteriza por las etapas de recoger , por un servidor de mantenimiento […]
 Método y dispositivo para la comparación de versiones de datos entre estaciones a través de zonas horarias, del 29 de Julio de 2020, de Advanced New Technologies Co., Ltd: Un método para la comparación de versiones de datos entre sitios a través de zonas horarias, el método que comprende:
cuando los sitios […]
Método y dispositivo para la comparación de versiones de datos entre estaciones a través de zonas horarias, del 29 de Julio de 2020, de Advanced New Technologies Co., Ltd: Un método para la comparación de versiones de datos entre sitios a través de zonas horarias, el método que comprende:
cuando los sitios […]