COMPENSACIÓN DE LA VARIABILIDAD INTERSESIÓN PARA EXTRACCIÓN AUTOMÁTICA DE INFORMACIÓN A PARTIR DE LA VOZ.
Un procedimiento para compensar la variabilidad intersesión para extracción automática de información de una señal de voz de entrada que representa una expresión de un hablante,
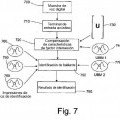
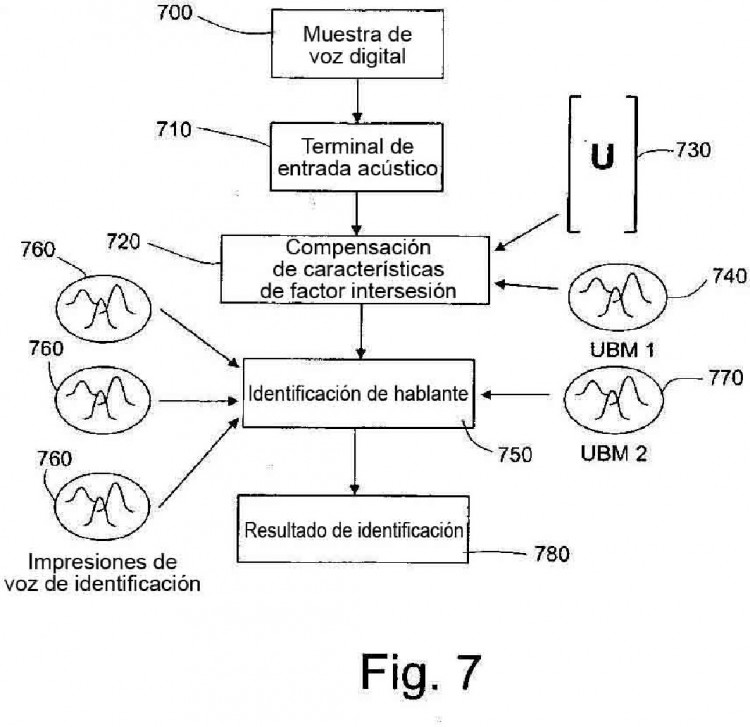
que comprende: • procesar la señal de voz de entrada para proporcionar vectores de características formados cada uno por características acústicas extraídas de la señal de voz de entrada en un intervalo de tiempo; • calcular un vector de características de compensación de la variabilidad intersesión; y • calcular vectores de características compensados restando el vector de características de compensación de la variabilidad intersesión de los vectores de características extraídos; y caracterizado porque el cálculo de un vector de características de compensación de la variabilidad intersesión incluye: • crear un Modelo de Fondo Universal (UBM) basándose en una base de datos de voz de aprendizaje, el Modelo de Fondo Universal (UBM) incluyendo varios gaussianos y modelizando un espacio acústico que define un espacio de modelo acústico; • crear una base de datos de grabaciones de voz relacionada con diferentes hablantes, y que contiene, para cada hablante, varias grabaciones de voz adquiridas bajo diferentes condiciones; • calcular una matriz de subespacio de variabilidad intersesión (U) analizando, para cada hablante, las diferencias entre grabaciones de voz adquiridas bajo diferentes condiciones y contenidas en la base de datos de grabaciones de voz, definiendo la matriz de subespacio de variabilidad intersesión (U) una transformación de un espacio de modelo acústico a un subespacio de variabilidad intersesión que representa la variabilidad intersesión para todos los hablantes; • calcular una vector de factor intersesión independiente del hablante único basándose en la señal de voz de entrada, realizando una técnica de estimación sobre los vectores de características, extraídos de la señal de voz de entrada, basándose en la matriz de subespacio de variabilidad intersesión (U) y el Modelo de Fondo Universal (UBM), representando el vector de factor intersesión la variabilidad intersesión de la señal de voz de entrada en el subespacio de variabilidad intersesión; y • calcular el vector de características de compensación de la variabilidad intersesión basándose en la matriz de subespacio de variabilidad intersesión (U), el vector de factor intersesión y el Modelo de Fondo Universal (UBM)
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/EP2006/004598.
Solicitante: LOQUENDO S.P.A..
Nacionalidad solicitante: Italia.
Dirección: VIA ARRIGO OLIVETTI 6 10100 TORINO ITALIA.
Inventor/es: VAIR,Claudio, COLIBRO,Daniele, LAFACE,Pietro.
Fecha de Publicación: .
Fecha Solicitud PCT: 16 de Mayo de 2006.
Clasificación Internacional de Patentes:
- G10L17/00B6
Clasificación PCT:
- G10L15/20 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › G10L 15/00 Reconocimiento de la voz (G10L 17/00 tiene prioridad). › Técnicas de reconocimiento de la voz especialmente adaptadas para trabajar en ambientes adversos, p. ej. en presencia de ruido o para voz emitida en situaciones de estrés (G10L 21/02 tiene prioridad).
Países PCT: Austria, Bélgica, Suiza, Alemania, Dinamarca, España, Francia, Reino Unido, Grecia, Italia, Liechtensein, Luxemburgo, Países Bajos, Suecia, Mónaco, Portugal, Irlanda, Eslovenia, Finlandia, Rumania, Chipre, Lituania, Letonia, Ex República Yugoslava de Macedonia, Albania.
PDF original: ES-2357674_T3.pdf
Fragmento de la descripción:
Campo técnico de la invención
La presente invención se refiere en general a la extracción automática de información a partir de la voz, como el reconocimiento automático de hablante y habla, y en particular a un procedimiento y un sistema para compensar la variabilidad intersesión de características acústicas debida a entornos y canales de comunicación variables intersesión.
Técnica anterior
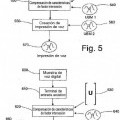
Como es sabido, un sistema de reconocimiento de hablante es un dispositivo capaz de extraer, almacenar y comparar características biométricas de la voz humana, y de realizar, además de una función de reconocimiento, también un procedimiento de aprendizaje, que permite el almacenamiento de características biométricas de la voz de un hablante en modelos apropiados, denominados comúnmente impresiones de voz. El procedimiento de aprendizaje ha de llevarse a cabo para todos los hablantes implicados y es preliminar a etapas de reconocimiento posteriores, durante las cuales los parámetros extraídos de una muestra de voz desconocida se comparan con los de las impresiones de voz para producir el resultado del reconocimiento.
Dos aplicaciones específicas de un sistema de reconocimiento de hablante son la verificación del hablante y la identificación del hablante. En el caso de la verificación del hablante, el propósito del reconocimiento es confirmar o rechazar una declaración de identidad asociada a la pronunciación de una frase o palabra. El sistema debe, es decir, responder a la pregunta: “Es el hablante la persona que dice que es?”. En el caso de la identificación del hablante, el propósito del reconocimiento es identificar, de un conjunto finito de hablantes de cuyas impresiones de voz se dispone, al cual corresponde una voz desconocida. El propósito del sistema es en este caso responder a la pregunta: “A quién pertenece la voz?”.
Una clasificación adicional de los sistemas de reconocimiento de hablante considera el contenido léxico utilizable por el sistema de reconocimiento: reconocimiento de hablante dependiente del texto o reconocimiento de hablante independiente del texto. El caso dependiente del texto requiere que el contenido léxico usado para la verificación o identificación correspondería al que se pronuncia para la creación de la impresión de voz: esta situación es típica en los sistemas de autentificación por voz, en los que la palabra o frase pronunciada asume, a todos los propósitos o efectos, la connotación de una contraseña de voz. El caso independiente del texto, en cambio, no establece ninguna restricción entre el contenido léxico de aprendizaje y el de reconocimiento.
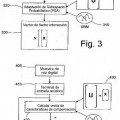
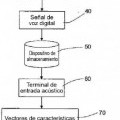
Los modelos ocultos de Markov (HMMs) son una tecnología clásica usada para reconocimiento de habla y de hablante. En general, un modelo de este tipo está constituido por un cierto número de estados conectados por arcos de transición. Asociada a una transición está una probabilidad de pasar del estado de origen al estado de destino. Además, cada estado puede emitir símbolos procedentes de un alfabeto finito según una distribución de probabilidad dada. A cada estado está asociada una densidad de probabilidad, densidad de probabilidad que se define sobre un vector de características acústicas extraído de la voz a cuantías de tiempo fijas (por ejemplo, cada 10 ms), siendo generado dicho vector por un módulo de análisis acústico (terminal de entrada acústico), y se denomina generalmente vector de observación o de características. Los símbolos emitidos, basándose en la densidad de probabilidad asociada al estado, son, por lo tanto, los infinitos vectores de características posibles. Esta densidad de probabilidad está dada por una mezcla de gaussianos en el espacio multidimensional de los vectores de características. Ejemplos de características ampliamente usadas para reconocimiento de hablante son los coeficientes cepstrales en las frecuencias de Mel (MFCC), y las características de las derivadas de primer orden respecto al tiempo se suman a las características básicas.
En el caso de la aplicación de modelos ocultos de Markov al reconocimiento de hablante, además de los modelos HMM descritos previamente, con varios estados, se recurre frecuentemente a los llamados modelos de mezclas de gaussianos (GMMs). Un GMM es un modelo de Markov con un único estado y con un arco de transición hacia sí mismo. Generalmente, la densidad de probabilidad de GMMs está constituida por una mezcla de distribuciones gaussianas multivariantes con cardinalidad del orden de algunos miles de gaussianos. Las distribuciones gaussianas multivariantes se usan comúnmente para modelar los vectores de características de entrada multidimensionales. En el caso de reconocimiento de hablante independiente del texto, los GMMs representan la categoría de modelos más ampliamente usados en la técnica anterior.
El reconocimiento de hablante se realiza creando, durante una etapa de aprendizaje, modelos adaptados a la voz de los hablantes implicados y evaluando la probabilidad que generan basándose en vectores de características extraídos de una muestra de voz desconocida, durante una etapa de reconocimiento posterior. Los modelos adaptados a hablantes individuales, que pueden ser HMMs o GMMs, se denominan comúnmente impresiones de voz. Una descripción de técnicas de aprendizaje de impresiones de voz que se aplica a GMMs y su uso para reconocimiento de hablante se proporciona en el documento de Reynolds, D.A. y col., Speaker verification using adapted Gaussian mixture models, Digital Signal Processing 10 (2000), págs. 19-41.
Una de las principales causas de degradaciones de rendimiento relevantes en el reconocimiento automático de habla y hablante es el desajuste acústico que ocurre entre condiciones de aprendizaje y de reconocimiento. En particular, en el reconocimiento de hablante, los errores se deben no sólo a la similitud entre impresiones de voz de diferentes hablantes, sino también a la variabilidad intrínseca de diferentes expresiones del mismo hablante. Por otra parte, el rendimiento se ve muy afectado cuando un modelo, entrenado en ciertas condiciones, se usa para reconocer una voz de hablante recogida por medio de diferentes micrófonos, canales y entornos. Todas estas condiciones de desajuste se denominan en general variabilidad intersesión.
Se han hecho varias propuestas para contrastar los efectos de la variabilidad intersesión tanto en los dominios de las características como de los modelos.
Una técnica popular usada para mejorar el rendimiento de un sistema de reconocimiento de hablante compensando las características acústicas es el Mapeo de Características, del cual puede encontrarse una descripción en el documento de D. Reynolds, Channel Robust Speaker Versification via Feature Mapping, en las Actas del ICASSP 2003, págs. II-53-6, 2003. En particular, el Mapeo de Características usa la información a priori de un conjunto de modelos dependientes del canal, entrenados en condiciones conocidas, para mapear los vectores de características hacia un espacio de características independientes del canal. Dada una expresión de entrada, primero se detecta el modelo dependiente del canal más probable y luego se mapea cada vector de características en la expresión al espacio independiente del canal basándose en el gaussiano seleccionado en el GMM dependiente del canal. El inconveniente de este enfoque es que requiere datos de aprendizaje etiquetados para crear los modelos dependientes del canal relacionados con las condiciones que se quiere compensar.
Por lo tanto, recientemente se han propuesto técnicas basadas en modelos que pueden compensar las variaciones del hablante y del canal sin requerir identificación explícita y etiquetado de diferentes condiciones. Estas técnicas comparten unos antecedentes comunes, concretamente la variabilidad de modelado de las expresiones del hablante que las restringen a un espacio propio de dimensiones bajas. Gracias a la dimensión reducida del espacio propio restringido, las técnicas basadas en modelos permiten una robusta compensación intersesión aun cuando se disponga únicamente de pocos datos dependientes del hablante.
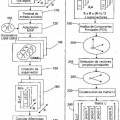
En general, todas las técnicas de espacio propio basadas en modelos construyen supervectores a partir de modelos acústicos. Un supervector se obtiene agregando los parámetros de todos los gaussianos de un HMM/GMM en una sola lista. Típicamente, sólo se incluyen los parámetros gaussianos medios en los supervectores. Considerando, por ejemplo, un GMM de 512 gaussianos, que modela 13 MFCC + 13 características derivadas... [Seguir leyendo]
Reivindicaciones:
1. Un procedimiento para compensar la variabilidad intersesión para extracción automática de información de una señal de voz de entrada que representa una expresión de un hablante, que comprende: procesar la señal de voz de entrada para proporcionar vectores de características formados cada uno
por características acústicas extraídas de la señal de voz de entrada en un intervalo de tiempo; calcular un vector de características de compensación de la variabilidad intersesión; y calcular vectores de características compensados restando el vector de características de
compensación de la variabilidad intersesión de los vectores de características extraídos; y caracterizado porque el cálculo de un vector de características de compensación de la variabilidad intersesión incluye:
crear un Modelo de Fondo Universal (UBM) basándose en una base de datos de voz de aprendizaje, el Modelo de Fondo Universal (UBM) incluyendo varios gaussianos y modelizando un espacio acústico que define un espacio de modelo acústico;
crear una base de datos de grabaciones de voz relacionada con diferentes hablantes, y que contiene, para cada hablante, varias grabaciones de voz adquiridas bajo diferentes condiciones;
calcular una matriz de subespacio de variabilidad intersesión (U) analizando, para cada hablante, las diferencias entre grabaciones de voz adquiridas bajo diferentes condiciones y contenidas en la base de datos de grabaciones de voz, definiendo la matriz de subespacio de variabilidad intersesión (U) una transformación de un espacio de modelo acústico a un subespacio de variabilidad intersesión que representa la variabilidad intersesión para todos los hablantes;
calcular una vector de factor intersesión independiente del hablante único basándose en la señal de voz de entrada, realizando una técnica de estimación sobre los vectores de características, extraídos de la señal de voz de entrada, basándose en la matriz de subespacio de variabilidad intersesión (U) y el Modelo de Fondo Universal (UBM), representando el vector de factor intersesión la variabilidad intersesión de la señal de voz de entrada en el subespacio de variabilidad intersesión; y
calcular el vector de características de compensación de la variabilidad intersesión basándose en la matriz de subespacio de variabilidad intersesión (U), el vector de factor intersesión y el Modelo de Fondo Universal (UBM).
2. El procedimiento de la reivindicación 1, en el que el cálculo del vector de características de compensación de la variabilidad intersesión basándose en la matriz de subespacio de variabilidad intersesión (U), el vector de factor intersesión y el Modelo de Fondo Universal (UBM) incluye:
calcular contribuciones de compensación de la variabilidad intersesión, una para cada uno de los gaussianos del Modelo de Fondo Universal (UBM) basándose en la matriz de subespacio de variabilidad intersesión (U) y el vector de factor intersesión;
ponderar las contribuciones de compensación de la variabilidad intersesión con la probabilidad de ocupación de gaussianos respectivos, dado un vector de características.
3. El procedimiento de la reivindicación 2, en el que el cálculo de contribuciones de compensación de la variabilidad intersesión incluye:
multiplicar el vector de factor intersesión por una submatriz (Um) de la matriz de subespacio de variabilidad intersesión relacionada con un gaussiano correspondiente del Modelo de Fondo Universal (UBM).
4. El procedimiento de la reivindicación 2 ó 3, en el que cada vector de características compensado se calcula basándose en la siguiente fórmula:
Oˆ i (t) Oi (t) m (t)Umxi
m
donde Ôi(t) es el vector de características compensado, Oi(t) es el vector de características extraído, xi es el vector de factor intersesión, i identifica la señal de speech de entrada, m identifica el gaussiano del Modelo de Fondo Universal, Um es la submatriz de la matriz de subespacio de variabilidad intersesión U y relacionada con el gaussiano m-ésimo, y γm(t) es la probabilidad de ocupación del gaussiano m-ésimo en el intervalo de tiempo t.
5. El procedimiento de la reivindicación 1, en el que la técnica de estimación es una Adaptación de Subespacio Probabilístico o una Adaptación de Descomposición Propia de Probabilidad Máxima.
6. El procedimiento de cualquiera de las reivindicaciones precedentes, en el que la determinación de una matriz de subespacio de variabilidad intersesión (U) incluye: calcular un modelo gaussiano para cada hablante y para cada grabación de voz en la base de datos
de voz, incluyendo cada modelo gaussiano varios gaussianos; calcular un supervector (SV) para cada modelo gaussiano; y calcular la matriz de subespacio de variabilidad intersesión (U) basándose en los supervectores (SV).
7. El procedimiento de la reivindicación 6, en el que el cálculo de un modelo gaussiano incluye:
realizar una etapa de adaptación basándose en los vectores de características y el Modelo de Fondo Universal (UBM).
8. El procedimiento de la reivindicación 7, en el que dicha realización de una etapa de adaptación incluye:
realizar una adaptación de Máximo A Posteriori (MAP) basándose en los vectores de características y el Modelo de Fondo Universal (UBM).
9. El procedimiento de cualquiera de las reivindicaciones 6 a 8, en el que el cálculo de un supervector
(SV) incluye: formar vectores medios con valores medios de todos los gaussianos del modelo gaussiano; y concatenar los vectores medios.
10. El procedimiento de la reivindicación 9, en el que la formación de vectores medios incluye: numerar los gaussianos del modelo gaussiano; y considerar los gaussianos en orden ascendente.
11. El procedimiento de cualquiera de las reivindicaciones 6 a 10, en el que el cálculo de la matriz de subespacio de variabilidad intersesión (U) basándose en los supervectores (SV) incluye:
para cada hablante, calcular un supervector de diferencia para cada par de supervectores relacionados con los modelos gaussianos del hablante como una diferencia vectorial entre los dos supervectores del par; y
realizar una reducción de dimensionalidad sobre los supervectores de diferencia para generar un grupo de vectores propios que definen el espacio de supervectores; y calcular la matriz de subespacio de variabilidad intersesión (U) basándose en los vectores propios.
12. El procedimiento de la reivindicación 11, en el que la realización de la reducción de dimensionalidad
incluye: elegir vectores propios específicos según un criterio dado; y calcular la matriz de subespacio de variabilidad intersesión (U) basándose en los vectores propios
elegidos.
13. El procedimiento de la reivindicación 12, en el que el cálculo de la matriz de subespacio de variabilidad intersesión (U) basándose en los vectores propios elegidos incluye:
agrupar los vectores propios elegidos en columnas para formar la matriz de subespacio de variabilidad intersesión (U),
14. El procedimiento de la reivindicación 12 ó 13, en el que cada vector propio está asociado con un valor
propio respectivo, y en el que la elección de vectores propios específicos según un criterio dado incluye: elegir los vectores propios con los valores propios más altos.
15. Un sistema para extraer automáticamente información de una señal de voz de entrada que representa una expresión de un hablante, que comprende un sistema de compensación de la variabilidad intersesión configurado para implementar el procedimiento de compensación de la variabilidad intersesión según cualquiera de las reivindicaciones 1 a 14 precedentes.
16. Un producto de programa informático que se puede cargar en una memoria de un sistema de procesamiento y que comprende porciones de código de software para implementar, cundo el producto de programa informático se ejecuta en el sistema de procesamiento, el procedimiento para compensar la variabilidad intersesión según cualquiera de las reivindicaciones 1 a 14 precedentes.
Patentes similares o relacionadas:
Procedimiento para la identificación y la comprobación de mensajes radiotelefónicos, del 28 de Noviembre de 2018, de Frequentis AG: Procedimiento para la identificación y la comprobación de mensajes radiotelefónicos (M1...M3), así como para la asignación de mensajes radiotelefónicos […]
Un método y circuito de supresión de ruido que incorpora una pluralidad de técnicas de supresión de ruido, del 12 de Marzo de 2014, de Motorola Mobility LLC (50.0%): Un circuito de supresión de ruido para su uso en un circuito de procesamiento de señal de audio, comprendiendo el circuito de supresión de ruido: una […]
 PROCEDIMIENTO DE DETECCIÓN DE SEGMENTOS DE VOZ, del 8 de Agosto de 2012, de TELEFONICA, S.A.: La presente invención se refiere a un procedimiento de detección de segmentos de voz y de ruido en una señal digital de audio de entrada, estando dividida […]
PROCEDIMIENTO DE DETECCIÓN DE SEGMENTOS DE VOZ, del 8 de Agosto de 2012, de TELEFONICA, S.A.: La presente invención se refiere a un procedimiento de detección de segmentos de voz y de ruido en una señal digital de audio de entrada, estando dividida […]
 PROCEDIMIENTO ADAPTATIVO AL USUARIO PARA LA MODELIZACION DE RUIDOS, del 7 de Mayo de 2010, de SIEMENS AKTIENGESELLSCHAFT: Procedimiento para el reconocimiento de voz con un banco de datos con varios perfiles de ruido de fondo, que representan distintos fondos de […]
PROCEDIMIENTO ADAPTATIVO AL USUARIO PARA LA MODELIZACION DE RUIDOS, del 7 de Mayo de 2010, de SIEMENS AKTIENGESELLSCHAFT: Procedimiento para el reconocimiento de voz con un banco de datos con varios perfiles de ruido de fondo, que representan distintos fondos de […]
ELECTRODOMESTICO CONTROLADO POR VOZ., del 1 de Junio de 2007, de BSH BOSCH UND SIEMENS HAUSGERATE GMBH: Electrodoméstico, en particular campana extractora de humos , con una unidad de control por voz que tiene un micrófono y un dispositivo de reconocimiento […]
DETECCION DEL HABLA UTILIZANDO MEDIDAS DE CONFIANZA EN EL ESPECTRO DE FRECUENCIAS., del 16 de Julio de 2006, de PANASONIC TECHNOLOGIES, INC.: 2005 (2005/46) por "Refrigerator". OG: A-04246
METODO, DISPOSITIVO, TERMINAL Y SISTEMA PARA EL RECONOCIMIENTO AUTOMATICO DE DATOS DE VOZ DISTORSIONADOS., del 1 de Diciembre de 2005, de TELEFONAKTIEBOLAGET L M ERICSSON (PUBL): Un método de procesar espectros de voz distorsionada de corto período para reconocimiento automático de voz, en el que los datos de voz distorsionada […]
DETECCION DE PALABRAS CLAVE EN UNA SEÑAL RUIDOSA., del 1 de Diciembre de 2005, de MATSUSHITA ELECTRIC INDUSTRIAL CO., LTD.: Método para detectar palabras en una señal de habla, que comprende las etapas de: generar una pluralidad de puntuaciones de reconocimiento […]