DIFERENCIACION DEL HABLA.
Procedimiento para la diferenciación entre tres o más voces, comprendiendo el procedimiento las etapas de
1) analizar propiedades de señal de cada señal de habla que representa una voz respectiva de las tres o más voces,
2) determinar tres o más conjuntos de parámetros, en el que cada conjunto representa mediciones de las propiedades de señal de una señal de habla respectiva,
3) definir una plantilla diferenciadora de voz adaptada para controlar un algoritmo de modificación de voz, en el que cada conjunto de parámetros se refiere a una posición en la plantilla,
4) determinar un punto central entre las tres o más posiciones de los conjuntos de parámetros en la plantilla,
5) extraer la plantilla diferenciadora de voz de modo que represente una modificación de al menos un parámetro de al menos un primer conjunto de parámetros, en el que la modificación sirve para aumentar una distancia de parámetros mutua a lo largo de una línea entre el punto central y la posición de un conjunto de parámetros respectivo de las tres o más voces tras el procesamiento por el algoritmo de modificación controlado por la plantilla diferenciadora de voz
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/IB2007/051845.
Solicitante: KONINKLIJKE PHILIPS ELECTRONICS N.V..
Nacionalidad solicitante: Países Bajos.
Dirección: GROENEWOUDSEWEG 1,5621 BA EINDHOVEN.
Inventor/es: HARMA,AKI,S.
Fecha de Publicación: .
Fecha Concesión Europea: 27 de Enero de 2010.
Clasificación Internacional de Patentes:
- G10L13/02E
Clasificación PCT:
- G10L13/02 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › G10L 13/00 Síntesis de la voz; Sistemas de síntesis de la voz a partir de texto. › Métodos de producción de voz sintética; Sintetizadores de voz.
- G10L21/00 G10L […] › Tratamiento de la señal de la voz para producir otra señal audible o no audible, p. ej. visual o táctil, con el fin de modificar su calidad o su inteligibilidad (G10L 19/00 tiene prioridad).
Fragmento de la descripción:
Diferenciación del habla.
La presente invención se refiere al campo del procesamiento de señales, especialmente el procesamiento de señales de habla. Más específicamente, la invención se refiere a un procedimiento para la diferenciación entre tres o más voces y a un procesador de señales y un dispositivo para realizar el procedimiento.
La diferenciación de las voces de diferentes hablantes es un problema ampliamente conocido, por ejemplo, en telefonía y en sistemas de teleconferencia. Por ejemplo en un sistema de teleconferencia sin claves visuales, un oyente remoto tendrá dificultades al seguir una discusión entre varios hablantes que hablan simultáneamente. Incluso aunque solo esté hablando un hablante, el oyente remoto puede tener dificultades para identificar la voz y por tanto identificar quién está hablando. En telefonía móvil, en entornos ruidosos, la identificación de hablantes también puede ser problemática, especialmente debido al hecho de que llamantes regulares, debido a relaciones genéticas y/o sociolingüísticas próximas, tienden a tener voces similares. Además, en aplicaciones de sitio de trabajo virtual en las que una línea está abierta para varios hablantes, la identificación de hablantes rápida y precisa puede ser importante.
El documento US 2002/0049594 A1 da a conocer un procedimiento y aparato para proporcionar señales para una voz sintética a modo de datos representativos de voz derivados, que se derivaron mediante la combinación de datos representativos de voces primera y segunda de un repertorio de base. La combinación puede tener lugar mediante la interpolación entre o la extrapolación más allá de las voces del repertorio de base.
El documento WO 99/48087 y el documento WO 03/094149 A1 dan a conocer un procedimiento y aparato similares. El sonido sintético se forma de la siguiente manera: dos sonidos se transforman espectralmente en un espacio de coordenadas y se proyecta una función lineal entre un par de puntos. Para exagerar los sonidos, se extrapolan puntos fuera del par de puntos a lo largo de una función lineal.
El documento US 2004/0013252 describe un procedimiento y aparato para mejorar la diferenciación de hablantes por parte de un oyente durante una audioconferencia. El procedimiento usa una señal transmitida a través de un sistema de telecomunicación, y el procedimiento incluye la voz de cada uno de la pluralidad de hablantes hacia el oyente, y un indicador indica el hablante real al oyente. El documento US 2004/0013252 menciona diferentes modificaciones de la señal de audio original con el fin de permitir que el oyente distinga mejor a los hablantes. Por ejemplo, la diferenciación espacial, en la que cada hablante individual se traduce en direcciones aparentes diferentes en el espacio auditivo, por ejemplo usando síntesis binaural tal como aplicando diferentes filtros de función de transferencia asociada a la cabeza (HRTF) a los diferentes hablantes. La motivación de esto es la observación de que las señales de habla son más fáciles de entender si los hablantes aparecen en diferentes direcciones. Además, el documento US 2004/0013252 menciona que voces similares pueden alterarse ligeramente de varias formas para ayudar al reconocimiento de la voz por el oyente. Se menciona un algoritmo de "nasalización" basado en modulación de frecuencia para proporcionar una ligera desviación de frecuencia de una de las voces de los hablantes para permitir una mejor diferenciación de la voz de la voz de otro hablante.
Las soluciones de diferenciación de habla propuestas en el documento US 2004/0013252 tienen diversas desventajas. Con el fin de la separación espacial entre hablantes, tal procedimiento requiere dos o más canales de audio para proporcionar al oyente la impresión espacial requerida, y por tanto tales procedimientos no son adecuados para aplicaciones en las que sólo está disponible un canal de audio, por ejemplo en sistemas de telefonía normales tales como en telefonía móvil. El algoritmo de "nasalización" mencionado en el documento US 2004/0013252 puede usarse en combinación con el procedimiento de diferenciación espacial. Sin embargo, el algoritmo produce voces que no suenan naturales y si se usa para diferenciar entre varias voces similares, no mejora la diferenciación porque todas las voces modificadas adquieren una calidad "nasal" perceptivamente similar. Además, el documento US 2004/0013252 no proporciona medios para el control automático del efecto de "nasalización" mediante las propiedades de las voces de los hablantes.
Por consiguiente, es un objetivo proporcionar un procedimiento que pueda procesar automáticamente señales de habla con el fin de ayudar a un oyente a identificar de manera inmediata una voz, por ejemplo una voz escuchada en un teléfono, es decir ayudar al oyente a diferenciar entre varias voces conocidas.
Este objetivo y otros diversos objetivos se obtienen mediante el objeto respectivo de las reivindicaciones independientes. Realizaciones a modo de ejemplo adicionales se describen en las reivindicaciones dependientes respectivas.
En general, un procedimiento para la diferenciación entre diferentes voces comprende las etapas de
1) analizar propiedades de señal de cada señal de habla que representa una voz,
2) determinar conjuntos de parámetros que representan mediciones de las propiedades de señal de cada señal de habla,
3) extraer una plantilla diferenciadora de voz adaptada para controlar un algoritmo de modificación de voz, extrayéndose la plantilla diferenciadora de voz de modo que represente una modificación de al menos un parámetro de al menos un primer conjunto de parámetros, en el que la modificación sirve para aumentar una distancia de parámetros mutua entre las voces tras el procesamiento por el algoritmo de modificación controlado por la plantilla diferenciadora de voz.
Por "plantilla diferenciadora de voz" se entiende un conjunto de parámetros de modificación de voz para su introducción en el algoritmo de modificación de voz con el fin de controlar su función de modificación de voz. Preferiblemente, el algoritmo de modificación de voz puede realizar la modificación de dos o más parámetros de voz, y por tanto la plantilla diferenciadora de voz preferiblemente incluye estos parámetros. La plantilla diferenciadora de voz puede incluir diferentes parámetros de modificación de voz asignados a cada una de las voces, y en caso de más de dos voces, la plantilla diferenciadora de voz puede incluir parámetros de modificación de voz asignados a un subconjunto de las voces o a todas las voces.
Según este procedimiento, es posible analizar automáticamente un conjunto de señales de habla que representan un conjunto de voces y llegar a una o más plantillas diferenciadora de voz asignadas a una o más del conjunto de voces basándose en propiedades de características de las voces. Aplicando algoritmos de modificación de voz asociados de manera correspondiente, individualmente para cada voz, es posible producir las voces con un sonido natural, pero con distancia perceptiva aumentada entre las voces ayudando así al oyente a diferenciar las voces.
El efecto del procedimiento es que las voces pueden hacerse más diferentes al tiempo que se sigue conservando un sonido natural de las voces. Esto es posible también si el procedimiento se realiza automáticamente, debido al hecho de que la plantilla de modificación de voz se basa en propiedades de señal, es decir características de las propias voces. Por tanto, el procedimiento buscará exagerar diferencias existentes o aumentar de manera artificial diferencias perceptivamente relevantes entre las voces en lugar de aplicar efectos de sonido sintéticos.
El procedimiento puede o bien realizarse por separado para un evento, por ejemplo una sesión de teleconferencia, en la que se seleccionan parámetros de modificación de voz individualmente para cada participante en la sesión. Alternativamente, puede ser una configuración permanente de parámetros de modificación de voz para llamantes individuales, en la que los parámetros de modificación de voz se almacenan en un dispositivo asociado con la identidad de cada llamante (por ejemplo número de teléfono), almacenado por ejemplo en una guía de un teléfono móvil.
Puesto que el procedimiento descrito sólo necesita como entrada una señal de audio de un único canal y puesto que puede funcionar con un único canal de salida, el procedimiento puede aplicarse por ejemplo en una amplia gama de aplicaciones de comunicación, por ejemplo telefonía, tal como telefonía móvil...
Reivindicaciones:
1. Procedimiento para la diferenciación entre tres o más voces, comprendiendo el procedimiento las etapas de
2. Procedimiento según la reivindicación 1, en el que la plantilla diferenciadora de voz se extrae de modo que represente una modificación de al menos un parámetro de cada uno de los tres o más conjuntos de parámetros.
3. Procedimiento según la reivindicación 1, en el que la plantilla diferenciadora de voz se extrae de modo que represente una modificación de dos o más parámetros de al menos el primer conjunto de parámetros.
4. Procedimiento según la reivindicación 1, en el que las mediciones de las propiedades de señal de cada señal de habla representan atributos perceptivamente significativos de las señales.
5. Procedimiento según la reivindicación 4, en el que las mediciones incluyen al menos una medición seleccionada del grupo que consiste en: tono, varianza tonal a lo largo del tiempo, forma de pulso glotal, amplitud de señal, frecuencias de formantes, diferencias de energía entre segmentos de habla sonoros y sordos, características relacionadas con el contorno del espectro global de habla, características relacionadas con la variación dinámica de una o más mediciones en segmentos de habla largos.
6. Procedimiento según la reivindicación 1, en el que la etapa 5) incluye calcular la distancia de parámetros mutua teniendo en cuenta al menos parte de los parámetros de cada conjunto de parámetros, y en el que el tipo de distancia calculada se selecciona del grupo que consiste en: distancia euclídea y distancia de Mahalanobis.
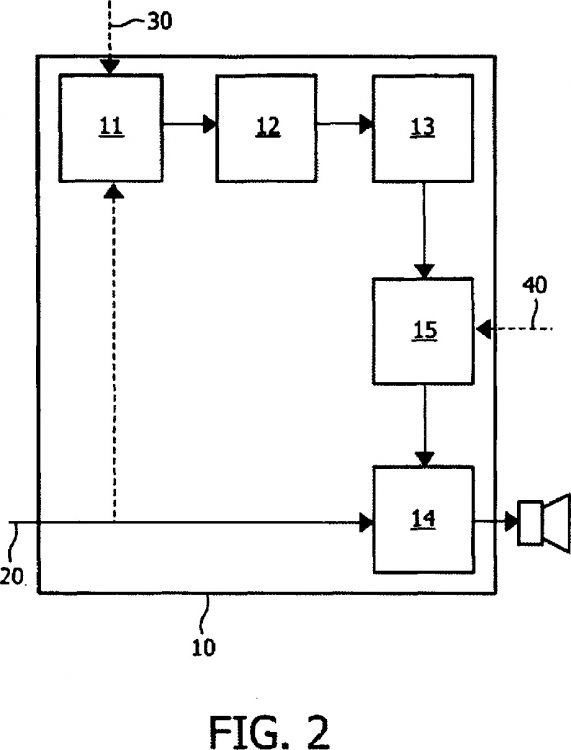
7. Procesador (10) de señales que comprende:
8. Procesador (10) de señales según la reivindicación 7, en el que el generador (13) de plantilla diferenciadora de voz está dispuesto para extraer la plantilla diferenciadora de voz de modo que represente una modificación de al menos un parámetro de cada uno de los tres o más conjuntos de parámetros.
9. Procesador (10) de señales según la reivindicación 7, en el que el generador (13) de plantilla diferenciadora de voz está dispuesto para extraer la plantilla diferenciadora de voz de modo que represente una modificación de dos o más parámetros de al menos el primer conjunto de parámetros.
10. Procesador (10) de señales según la reivindicación 7, en el que las mediciones de las propiedades de señal de cada una de las tres o más señales de habla representan atributos perceptivamente significativos de las señales.
11. Dispositivo que comprende un procesador (10) de señales según la reivindicación 7.
12. Código de programa ejecutable por ordenador adaptado para realizar el procedimiento según la reivindicación 1.
13. Medio de almacenamiento legible por ordenador que comprende un código de programa ejecutable por ordenador según la reivindicación 12.
Patentes similares o relacionadas:
 DISPOSITIVO Y PROCEDIMIENTO DE EDICIÓN DIFERENCIADA DE VOZ, del 28 de Abril de 2011, de BAYERISCHE MOTOREN WERKE AKTIENGESELLSCHAFT: Dispositivo de edición diferenciada de voz que puede unirse con un primer sistema y al menos con otro sistema (32, 33 a 3N), estando asociada a […]
DISPOSITIVO Y PROCEDIMIENTO DE EDICIÓN DIFERENCIADA DE VOZ, del 28 de Abril de 2011, de BAYERISCHE MOTOREN WERKE AKTIENGESELLSCHAFT: Dispositivo de edición diferenciada de voz que puede unirse con un primer sistema y al menos con otro sistema (32, 33 a 3N), estando asociada a […]
 SINTESIS DE SEÑAL DE AUDIO, del 26 de Enero de 2010, de KONINKLIJKE PHILIPS ELECTRONICS N.V.: Dispositivo de síntesis de señal para sintetizar una señal (r'') de audio, comprendiendo el dispositivo:
- una unidad de síntesis sinusoidal […]
SINTESIS DE SEÑAL DE AUDIO, del 26 de Enero de 2010, de KONINKLIJKE PHILIPS ELECTRONICS N.V.: Dispositivo de síntesis de señal para sintetizar una señal (r'') de audio, comprendiendo el dispositivo:
- una unidad de síntesis sinusoidal […]
 PROCEDIMIENTO Y SISTEMA DE DIALOGO DE VOZ, del 14 de Diciembre de 2009, de MOTOROLA, INC.: Un método para diálogo de voz, incluyendo:
recibir una frase vocal que incluye una frase de petición que incluye una variable instanciada; […]
PROCEDIMIENTO Y SISTEMA DE DIALOGO DE VOZ, del 14 de Diciembre de 2009, de MOTOROLA, INC.: Un método para diálogo de voz, incluyendo:
recibir una frase vocal que incluye una frase de petición que incluye una variable instanciada; […]
Método y disposición para suavizar ruido estacionario de fondo, del 25 de Diciembre de 2019, de TELEFONAKTIEBOLAGET LM ERICSSON (PUBL): Un método para suavizar ruido de fondo, comprendiendo el método: recibir y decodificar (S10) una señal codificada que comprende tanto una componente de voz […]
Procedimiento y dispositivo para suavizar ruido de fondo estacionario, del 22 de Julio de 2015, de TELEFONAKTIEBOLAGET LM ERICSSON (PUBL): Un procedimiento para suavizar ruido de fondo en una sesión de voz de telecomunicaciones, que comprende recibir y descodificar (S10) una señal representativa de […]
Aparato y método para procesar una señal de audio y para proporcionar una mayor granularidad temporal para un códec de voz y de audio unificado combinado (USAC), del 3 de Diciembre de 2014, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un tablero decorativo de melamina producido por apilamiento de una capa decorativa, una capa central y una capa posterior en este orden, y después conformado […]
Aparato y método para modificar una señal de audio de entrada, del 3 de Diciembre de 2014, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un aparato para modificar una señal de audio de entrada, que comprende: un determinador de la excitación configurado para determinar un valor de un parámetro […]
Re-muestreo de señales de salida de códecs de audio basados en QMF, del 11 de Junio de 2014, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un aparato para el re-muestreo de una señal de audio procesada (SA) que comprende: un primer procesador de señales de audio configurable para procesar una señal […]