PROCEDIMIENTO DE CODIFICADO DE LA PROSODIA PARA UN CODIFICADOR DE PALABRA CON CADENCIA MUY BAJA.
Procedimiento de codificado-decodificado de la palabra utilizando un codificador de cadencia muy baja que comprende una etapa de reconocimiento que permite identificar los "representantes" de la señal de palabra y una etapa de codificado para segmentar la señal de palabra y determinar el "mejor representante" asociado con cada segmento reconocido,
caracterizado porque comprende al menos:
una etapa de codificado-decodificado de uno de los parámetros al menos de la prosodia de los segmentos reconocidos, del cual el paso, utiliza una información de prosodia de los "mejores representantes",
una etapa de codificado del paso de los segmentos reconocidos que consiste en:
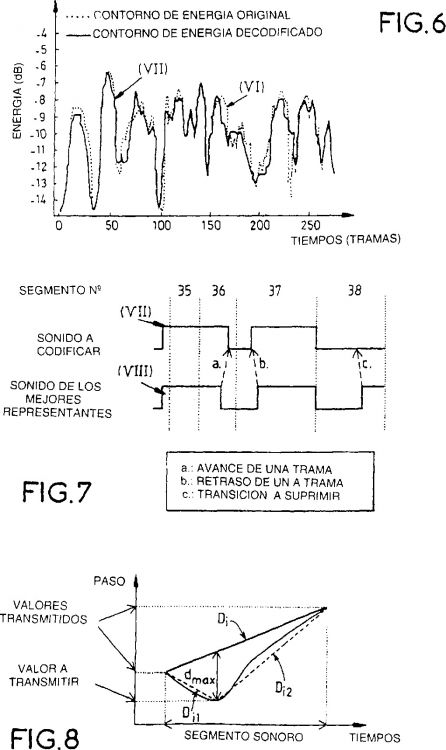
transmitir los valores de paso al comienzo y al final de la zona sonora,
partiendo de una recta Di que une los valores del paso en los dos extremos de la indicada zona sonora, el procedimiento busca el comienzo de segmento cuyo valor de paso es el más alejado de esta recta, lo cual corresponde a un distancia dmax.
luego comparar este valor dmax con un valor umbral dumbral.
circ Si la distancia dmax es superior a dumbral, descomponer la recta inicial Di en dos rectas Di1 y Di2 tomando el comienzo del segmento encontrado Di2 como nuevo valor de paso a transmitir,
circ reiterar la operación de descomposición sobre estas dos nuevas zonas sonoras delimitadas por las rectas Di1 y Di2 hasta que la distancia dmax encontrada sea inferior a la distancia dumbral
Tipo: Patente Europea. Resumen de patente/invención. Número de Solicitud: E01402684.
Solicitante: THALES.
Nacionalidad solicitante: Francia.
Dirección: 173, BOULEVARD HAUSSMANN,75008 PARIS.
Inventor/es: GOURNAY,PHILIPPE,THALES,INTELLECTUAL PROPERTY, NAKACHE,YVES-PAUL,THALES,INTELLECTUAL PROPERTY.
Fecha de Publicación: .
Fecha Solicitud PCT: 17 de Octubre de 2001.
Fecha Concesión Europea: 2 de Diciembre de 2009.
Clasificación Internacional de Patentes:
- G10L19/00S
Clasificación PCT:
- G10L19/00 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › Técnicas de análisis-síntesis de la voz o de señales de audio para la reducción de la redundancia, p. ej. en codificadores vocales; Codificación o decodificación de la voz o de señales de audio, utilizando modelos filtro-fuente o el análisis psicoacústico (en instrumentos musicales G10H).
Clasificación antigua:
- G10L19/00 G10L […] › Técnicas de análisis-síntesis de la voz o de señales de audio para la reducción de la redundancia, p. ej. en codificadores vocales; Codificación o decodificación de la voz o de señales de audio, utilizando modelos filtro-fuente o el análisis psicoacústico (en instrumentos musicales G10H).
Países PCT: Austria, Bélgica, Suiza, Alemania, Dinamarca, España, Francia, Reino Unido, Grecia, Italia, Liechtensein, Luxemburgo, Países Bajos, Suecia, Mónaco, Portugal, Irlanda, Eslovenia, Finlandia, Rumania, Chipre, Lituania, Letonia, Ex República Yugoslava de Macedonia, Albania.
Fragmento de la descripción:
Procedimiento de codificado de la prosodia para un codificador de palabra con cadencia muy baja.
La presente invención se refiere a un procedimiento de codificado de la palabra con cadencia muy baja y al sistema asociado. La misma se aplica particularmente para sistemas de codificado-decodificado de la palabra por indexación de unidades de tamaño variable.
El procedimiento de codificado de la palabra realizado a baja cadencia, por ejemplo del orden de 2400 bitios/s, es generalmente el del codificador de voz que utiliza un modelo totalmente paramétrico de la señal de palabra. Los parámetros utilizados se refieren al sonido que describe el carácter periódico o aleatorio de la señal, la frecuencia fundamental de los sonidos vocales también conocida bajo el vocablo anglosajón "PITCH", la evolución temporal de la energía, así como la envoltura espectral de la señal generalmente modelizada por un filtro LPC (abreviatura anglosajona de Lineal Predictive Coding).
Estos diferentes parámetros son tenidos en cuenta periódicamente sobre la señal de palabra, típicamente cada 10 a 30 ms. Son elaborados a nivel de un dispositivo de análisis y son generalmente transmitidos a distancia en dirección a un dispositivo de síntesis que reproduce la señal de palabra a partir del valor cuantificado de los parámetros del modelo.
Hasta ahora, la cadencia más baja normalizada para un codificador de palabra que utiliza esta técnica es de 800 bitios/s. Este codificador, normalizado en 1994 está descrito por el standard OTAN STANAG 4479 y en el artículo titulado "NATO STANAG 4479: A standard for an 800 bps vocoder and channel coding in HF-ECCM system", IEEE Int. Conf. on ASSP, Detroit, páginas 480-483, Mayo 1995 que tiene por autores Mouy, B., De La Noue, P., y Goudezeune, G. Se basa en una técnica de análisis de trama por trama (22.5 ms) de tipo LPC 10 y explota al máximo la redundancia temporal de la señal de palabra reagrupando las tramas 3 por 3 antes del codificado de los parámetros.
Aunque se pueda entender, la palabra reproducida por estas técnicas de codificado es de bastante mala calidad y no es ya aceptable a partir del momento en que la cadencia es inferior a los 600 bitios/s.
Una manera de reducir la cadencia es utilizar los codificadores de voz por segmentos de tipo fonético con segmentos de duración variable que combinan principios de reconocimiento y de síntesis de la palabra, ver por ejemplo "very low bit rate speech coding using a diphone-based recognition and synthesis approach" de Felici et al. In Electronics letters vol. 34 no. 9, 1998.
El procedimiento de codificado utiliza esencialmente un sistema de reconocimiento automático de la palabra en flujo continuo, que segmenta y "etiqueta" la señal de palabra según un número de unidades de palabra de tamaño variable. Estas unidades fonéticas se codifican por indexación en un pequeño diccionario. El decodificado se basa en el principio de la síntesis de la palabra por concatenación a partir del índice de las unidades fonéticas y de la prosodia. El término "prosodia" reagrupa principalmente los parámetros siguientes: la energía de la señal, el paso, una información de sonido y eventualmente el ritmo temporal.
Sin embargo, el desarrollo de los codificadores fonéticos necesita conocimientos importantes en fonética y en lingüística, así como una fase de transcripción fonética de una base de datos de aprendizaje que es costosa y que puede ser la fuente de errores. Además, los codificadores fonéticos se adaptan difícilmente a una nueva lengua o a un nuevo locutor.
Otra técnica, descrita por ejemplo en la tesis de J. Cernocky, titulada "Speech Processing Using Automatically Derived Segmental Units: Applications to very Low Rate Coding and Speaker Verification" de l'Université Paris Xl Orsay, Diciembre 1998 permite eludir los problemas relacionados con la transcripción fonética de la base de datos de aprendizaje determinando las unidades de palabra de forma automática e independientemente de la lengua.
El funcionamiento de este tipo de codificador se descompone principalmente en dos etapas: una etapa de aprendizaje y una etapa de codificado-decodificado descritas en la figura 1.
En la etapa de aprendizaje (figura 1), un procedimiento automático determina por ejemplo después de un análisis paramétrico 1 y una etapa de segmentación 2, un conjunto de 64 clases de unidades acústicas designadas "UA". Con cada una de estas clases de unidades acústicas está asociado un modelo estadístico 3, de tipo modelo de Markov (HMM abreviatura anglosajona de Hidden Markov Model), así como un pequeño número de unidades representantes de una clase, designadas bajo el término "representantes" 4. En el sistema actual, los representantes son simplemente las 8 unidades más largas pertenecientes a una misma clase acústica. Pueden igualmente determinarse como siendo las N unidades más representativas de la unidad acústica. En el codificado de una señal de palabra después de una etapa de análisis paramétrico 5 que permite obtener particularmente los parámetros espectrales, las energías, el paso, un procedimiento de reconocimiento (6, 7), con la ayuda de un algoritmo de Viterbi, determina la sucesión de unidades acústicas de la señal de palabra e identifica el "mejor representante" a utilizar para la síntesis de la palabra. Esta elección se realiza por ejemplo utilizando un criterio de distancia espectral, tal como el algoritmo de DTW (abreviatura anglosajona de Dynamic Time Warping).
El número de la clase acústica, el índice de esta unidad representante, la longitud del segmento, el contenido de DTW y las informaciones prosódicas procedentes del análisis paramétrico se transmiten al decodificador. La síntesis de la palabra se realiza por concatenación de los mejores representantes, eventualmente utilizando un sintetizador paramétrico de tipo LPC.
Para concatenar los representantes en el decodificado de la palabra, se recurre, por ejemplo, a un procedimiento de análisis/síntesis paramétrico de la palabra. Este procedimiento paramétrico permite particularmente modificaciones prosodia tales como la evolución temporal, la frecuencia fundamental o paso, con relación a una simple concatenación de formas de onda.
El modelo paramétrico de palabra utilizado por el procedimiento de análisis/síntesis puede ser por excitación binaria vocalizada/sin vocalizar de tipo LPC 10 tal como se describe en el documento titulado "The government standard linear predictive coding algorithm: LPC-10" de T. Tremain publicado en la revista Speech Technology, vol. 1, nº 2, páginas 40-49.
Esta técnica permite codificar la envoltura espectral de la señal en 185 bitios/s aproximadamente para un sistema monolocutor, para una media de aproximadamente 21 segmentos por segundo.
En lo que sigue de la descripción los términos dados a continuación tienen los significados siguientes:
El objeto de la presente invención se refiere a un procedimiento de codificado, decodificado de la prosodia para un codificador de palabra de cadencia muy baja que utiliza particularmente los mejores representantes.
Se refiere también a la compresión de datos.
La invención tal como se define por la reivindicación 1, se refiere a un procedimiento de codificado-decodificado de la palabra utilizando un codificador de cadencia muy baja que comprende una etapa de aprendizaje que permite identificar "representantes" de la señal de palabra y una etapa de codificado para segmentar la señal de palabra y determinar el "mejor representante" asociado con cada segmento reconocido.
La información de prosodia de los representantes utilizada es por ejemplo el contorno de energía o el sonido o la longitud de los segmentos o el paso.
Según un modo de realización, comprende una etapa de codificado del alineamiento temporal de los mejores representantes utilizando la vía de DTW y buscando la proximidad más cercana...
Reivindicaciones:
1. Procedimiento de codificado-decodificado de la palabra utilizando un codificador de cadencia muy baja que comprende una etapa de reconocimiento que permite identificar los "representantes" de la señal de palabra y una etapa de codificado para segmentar la señal de palabra y determinar el "mejor representante" asociado con cada segmento reconocido, caracterizado porque comprende al menos:
una etapa de codificado-decodificado de uno de los parámetros al menos de la prosodia de los segmentos reconocidos, del cual el paso, utiliza una información de prosodia de los "mejores representantes",
una etapa de codificado del paso de los segmentos reconocidos que consiste en:
2. Procedimiento según la reivindicación 1, caracterizado porque comprende una etapa de codificado del alineamiento temporal de los mejores representantes utilizando la vía de DTW y buscando la proximidad más inmediata en una tabla de formas.
3. Procedimiento según la reivindicación 1, caracterizado porque la etapa de decodificado de la energía comprende para cada segmento reconocido, una primera etapa que consiste en trasladar el contorno de energía del mejor representante una cantidad ?E(j) para hacer coincidir la primera energía Erd(j) del "mejor representante" con la primera energía Esd(j+1) del segmento reconocido de índice j+1.
4. Procedimiento según una de las reivindicaciones 1 a 2, caracterizado porque la etapa de codificado del paso se realiza por medio de un cuantificador escalar predictivo.
5. Procedimiento según la reivindicación 4, caracterizado porque la predicción es el primer valor del paso del mejor representante que corresponde a la posición del paso a decodificar, multiplicado por un factor de predicción.
6. Procedimiento según la reivindicación 4, caracterizado porque la predicción es el valor mínimo del registro de palabra a codificar.
7. Sistema de codificado-decodificado de la palabra comprendiendo al menos una memoria para almacenar un diccionario que comprende un conjunto de representantes de la señal de palabra, un microprocesador adaptado para determinar los segmentos reconocidos, para reconstruir la palabra a partir de los "mejores representantes" y para realizar las etapas del procedimiento según una de las reivindicaciones 1 a 6.
8. Sistema según la reivindicación 7, caracterizado porque el diccionario de los representantes es común al codificador y al decodificador del sistema codificado-decodificado.
9. Utilización del procedimiento según una de las reivindicaciones 1 a 6 o del sistema según una de las reivindicaciones 7 y 8 en el codificado-decodificado de la palabra para cadencias inferiores a 800 bitios/s y de preferencia inferiores a 400 bitios/s.
Patentes similares o relacionadas:
Almacenamiento eficiente de registros de códigos cifrados estructurados múltiples, del 22 de Julio de 2020, de Nokia Technologies OY: Un aparato que comprende: medios para formar un vector de código base combinando componentes 5 de vector de un sub-vector señalado por […]
Sistema decodificador, método de decodificación y programa informático respectivo, del 15 de Julio de 2020, de DOLBY INTERNATIONAL AB: Un sistema decodificador para proporcionar una señal estéreo mediante codificación estéreo de predicción compleja, comprendiendo el sistema decodificador: […]
Codificación de las posiciones de los picos espectrales, del 27 de Mayo de 2020, de TELEFONAKTIEBOLAGET LM ERICSSON (PUBL): Un método de codificación de las posiciones de los picos espectrales de un segmento de una señal de audio, comprendiendo el método: - determinar cuál […]
Conformación simultánea de ruido en el dominio del tiempo y el dominio de la frecuencia para transformaciones TDAC, del 20 de Mayo de 2020, de VOICEAGE CORPORATION: Un método de conformación de ruido en el dominio de la frecuencia para interpolar una forma espectral y una envolvente en el dominio del tiempo del ruido […]
Procesamiento avanzado basado en un banco de filtros con modulación exponencial compleja y métodos para señalizar el tiempo adaptativos, del 8 de Abril de 2020, de DOLBY INTERNATIONAL AB: Aparato para generar una señal de decorrelación que usa una señal de entrada, comprendiendo: un banco de filtros de sub-banda complejo para filtrar […]
Procesamiento avanzado basado en un banco de filtros con modulación exponencial compleja, del 8 de Abril de 2020, de DOLBY INTERNATIONAL AB: Aparato para generar una señal de decorrelación que usa una señal de entrada, comprendiendo: un banco de filtros de sub-banda complejo para filtrar […]
Procesamiento avanzado basado en un banco de filtros con modulación exponencial compleja, del 8 de Abril de 2020, de DOLBY INTERNATIONAL AB: Aparato para generar una señal de decorrelación que usa una señal de entrada, comprendiendo: un banco de filtros de sub-banda para proporcionar una […]
Códec de audio multicanal sin pérdida que usa segmentación adaptativa con capacidad de conjunto de parámetros de predicción múltiple (MPPS), del 11 de Marzo de 2020, de DTS, INC: Un método de codificación de audio multicanal, en un flujo de datos de audio de tasa de bits variable sin pérdida, VBR, que comprende: bloquear […]