Equipo de audio que comprende unos medios de supresión de ruido de una señal de habla mediante filtrado de retardo fraccionario.
Un equipo de audio, que comprende:
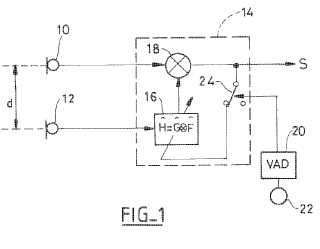
- un conjunto de dos sensores microfónicos (10,
12) aptos para recoger el habla del usuario del equipo y paraemitir unas señales de habla ruidosas respectivas;
- medios de muestreo de las señales de habla emitidas por los sensores microfónicos; y
- medios de supresión de ruido de una señal de habla, que reciben como entrada las muestras de las señalesde habla emitidas por los dos sensores microfónicos, y emiten como salida una señal de habla carente de ruidorepresentativa del habla emitida por el usuario del equipo,
en el que los medios de supresión de ruido son medios de reducción de ruido no frecuencial que comprendenun combinador de filtro adaptativo (14) de las señales emitidas por los dos sensores microfónicos, que operanmediante búsqueda iterativa con el objeto de anular el ruido captado por uno de los sensores microfónicos (10)en base a una referencia de ruido dada por la señal emitida por el otro sensor microfónico (12);
estando el equipo caracterizado por que:
- el filtro adaptativo (16) es un filtro de retardo fraccionario, apto para modelar un retardo inferior al periodo demuestreo de los medios de muestreo;
- el equipo comprende además medios de detección de actividad vocal (20, 22) aptos para emitir una señalrepresentativa de la presencia o de la ausencia de habla por el usuario del equipo; y
- el filtro adaptativo recibe igualmente como entrada la señal de presencia o de ausencia de habla para, demanera selectiva: i) o bien operar una búsqueda adaptativa de los parámetros del filtro en ausencia de habla, ii)o bien congelar estos parámetros del filtro en presencia de habla.
Tipo: Patente Europea. Resumen de patente/invención. Número de Solicitud: E12170407.
Solicitante: PARROT.
Nacionalidad solicitante: Francia.
Dirección: 174 QUAI DE JEMMAPES 75010 PARIS FRANCIA.
Inventor/es: Vitte,Guillaume, HERVE,MICHAEL.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G10L21/0208 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › G10L 21/00 Tratamiento de la señal de la voz para producir otra señal audible o no audible, p. ej. visual o táctil, con el fin de modificar su calidad o su inteligibilidad (G10L 19/00 tiene prioridad). › Filtración del ruido.
PDF original: ES-2430121_T3.pdf
Fragmento de la descripción:
Equipo de audio que comprende unos medios de supresión de ruido de una señal de habla mediante filtrado de retardo fraccionario La invención se refiere al tratamiento del habla en un medio ruidoso.
Se refiere, en particular, al tratamiento de las señales de habla captadas por unos dispositivos de telefonía de tipo “manos libres” destinados a ser utilizados en un entorno ruidoso.
Estos aparatos incorporan uno o varios micrófonos (“micros”) sensibles, que captan no solo la voz del usuario sino igualmente el ruido circundante, ruido que constituye un elemento perturbador que puede llegar en ciertos casos a convertir en ininteligible el habla del locutor. Lo mismo sucede si se quieren poner en práctica técnicas de reconocimiento de voz, pues es difícil efectuar un reconocimiento de forma sobre hablas ahogadas en un nivel de ruido elevado.
Esta dificultad unida a los ruidos circundantes es particularmente apremiante en el caso de los dispositivos “manos libres” para vehículos automóviles, ya se trata de equipos incorporados al vehículo o bien de accesorios en forma de carcasa inmóvil que integra todos los componentes y funciones de tratamiento de la señal para la comunicación telefónica.
En efecto, la importante distancia entre el micro (colocado al nivel del salpicadero o en un ángulo superior del techo del habitáculo) y el locutor (cuyo alejamiento está condicionado por la posición de la conducción) provoca la captación de un nivel de ruido relativamente elevado, que hace difícil la extracción de la señal útil, ahogada en el ruido. Así mismo, el medio muy ruidoso típico del entorno del automóvil presenta unas características espectrales no fijas, es decir que evolucionan de manera imprevisible en función de las condiciones de la conducción: paso por calzadas bacheadas o adoquinadas, la radio del vehículo en funcionamiento, etc.
Dificultades del mismo tipo se presentan en el caso de que el dispositivo consista en unos cascos de audio de tipo micro/cascos combinado utilizado para funciones de comunicación como por ejemplo funciones de telefonía “manos libres”, como complemento de la escucha de una fuente de audio (música, por ejemplo) proveniente de un aparato al que están conectados los cascos.
En este caso, se trata de utilizar una inteligibilidad suficiente de la señal captada por el micro, es decir de la señal de habla del locutor próximo (el portador de los cascos) , o bien los cascos pueden ser utilizados en un entorno ruidoso (metro, calle de mucho tránsito, tren, etc.) , de manera que el micro captará no solo el habla del portador de los cascos, sino los ruidos parásitos circundantes. El portador está ciertamente protegido de este ruido por los cascos, en especial si se trata de un modelo con auriculares cerrados que aíslen el ruido del exterior, y todavía más si los cascos están provistos de un “control activo del ruido”. Por contra, el locutor distante (el que se encuentra en el otro extremo del canal de comunicación) sufrirá ruidos parásitos captados por el micro y que vienen a interponerse y a interferir con la señal de habla del locutor próximo (el portador de los cascos) . En particular, determinados formantes del habla esenciales para la comprensión de la voz quedan a menudo ahogados en componentes de ruido que habitualmente se encuentran en los entornos habituales.
La invención se refiere, más en concreto, a técnicas de supresión de ruido que incorporan varios micros, generalmente dos micros, para combinar de manera equilibrada las señales captadas simultáneamente por estos micros con el fin de aislar los componentes del habla útiles de los componentes de ruidos parásitos.
Una técnica clásica consiste en colocar y orientar uno de los micros para que capte principalmente la voz del locutor, mientras que el otro se dispone para que capte un componente de ruido más importante que el micro principal. La comparación de los signos captados permite extraer la voz del ruido ambiental mediante el análisis de la coherencia espacial de las dos señales, con medios software relativamente simples.
El documento US 2008/0280653 A1 describe una configuración de este tipo, en la que uno de los micros (el que capta principalmente la voz) es el de un auricular inalámbrico que lleva el conductor del vehículo, mientras que el otro (el que capta principalmente el ruido) es el del aparato telefónico, situado a distancia dentro del habitáculo del vehículo, por ejemplo acoplado al salpicadero.
Esta técnica, sin embargo, tiene el inconveniente de que se necesitan dos micros distantes, de forma que la eficacia es tanto más elevada cuanto más alejados están los dos micros. Debido a ello, esta técnica no es aplicable al dispositivo en el que los dos micros están próximos, por ejemplo dos micros incorporados en el frontal de una radio de vehículo automóvil, o dos micros que estuvieran dispuestos sobre una de las carcasas de un auricular de los cascos de audio.
Otra técnica más, llamada conformación de haces, consiste en crear mediante medios software una directividad que mejore la relación señal/ruido de la red o “antena” de micros. El documento US 2007/0165879 A1 describe una técnica de este tipo, aplicada a un par de micros no direccionales colocados de espaldas. Un filtrado adaptativo de las señales captadas permite derivar de salida una señal en la que el componente de voz ha sido reforzado.
No obstante, se considera que un método de este tipo no proporciona buenos resultados más que a condición de que disponga de al menos ocho micros, resultando en prestaciones extremadamente limitadas cuando solamente se utilizan dos micros.
El problema general de la invención es, en un contexto como el referido, proceder a una reducción eficaz del ruido que permita transmitir al locutor distante una señal vocal representativa del habla emitida por el locutor próximo (conductor del vehículo o portador de los cascos) , liberando a esta señal de los componentes parásitos del ruido exterior existentes en el entorno de este locutor próximo.
El problema de la invención es igualmente, en tal situación, el de poder incorporar a la vez un conjunto de micros de un número reducido (de modo ventajoso, dos micros solamente) y relativamente próximos (típicamente una separación de solo algunos centímetros) . Otro aspecto importante del problema es la necesidad de restituir una señal de habla natural e inteligible, es decir no distorsionada y cuyo espectro de frecuencias útiles no resulte cercenado por los tratamientos de supresión de ruido.
Con este fin la invención propone un equipo de audio del tipo general divulgado por el documento US 2008/0280653 A1 precitado, es decir que comprende: un conjunto de dos sensores microfónicos aptos para recoger el habla del usuario del equipo y para emitir unas señales de habla ruidosas respectivas; unos medios de muestreo de las señales de habla emitidas por los sensores microfónicos; y unos medios de supresión de ruido de una señal de habla, que reciben como salida las muestras de las señales de habla emitidas por los dos sensores microfónicos, y emiten de salida una señal de habla sin ruidos representativa del habla emitida por el usuario del equipo. Los medios de supresión de ruido son unos medios de reducción de ruido no frecuencial que comprenden un combinador con filtro adaptativo de las señales emitidas por los dos sensores microfónicos, que operan mediante la búsqueda iterativa que tiene por objeto anular el ruido captado por uno de los sensores microfónicos en base a una referencia de ruido dada por la señal emitida por el otro sensor microfónico.
Como característica distintiva de la invención, el filtro adaptativo es un filtro de retardo fraccionario, apto para modelar un retardo inferior al periodo de muestreo de los medios de muestreo. El equipo comprende además unos medios de detección de la actividad vocal aptos para emitir una señal representativa de la presencia o ausencia de habla por el usuario del equipo, y el filtro adaptativo recibe igualmente como entrada la señal de presencia o ausencia de habla, para, de forma selectiva: i) o bien operar una búsqueda adaptativa de los parámetros de filtro en ausencia de habla, ii) o bien congelar estos parámetros del filtro en presencia de habla.
El filtro adaptativo es, en especial, apto para estimar un filtro óptimo H, como:
representando A la estimación del filtro óptimo H, la transferencia de ruido entre los dos sensores microfónicos para una respuesta de impulso incluyendo un retardo fraccionario, representando G la estimación del filtro del retardo fraccionario G entre los dos sensores microfónicos,... [Seguir leyendo]
Reivindicaciones:
1. Un equipo de audio, que comprende:
- un conjunto de dos sensores microfónicos (10, 12) aptos para recoger el habla del usuario del equipo y para
emitir unas señales de habla ruidosas respectivas;
5 - medios de muestreo de las señales de habla emitidas por los sensores microfónicos; y
- medios de supresión de ruido de una señal de habla, que reciben como entrada las muestras de las señales
de habla emitidas por los dos sensores microfónicos, y emiten como salida una señal de habla carente de ruido
representativa del habla emitida por el usuario del equipo,
en el que los medios de supresión de ruido son medios de reducción de ruido no frecuencial que comprenden
10 un combinador de filtro adaptativo (14) de las señales emitidas por los dos sensores microfónicos, que operan
mediante búsqueda iterativa con el objeto de anular el ruido captado por uno de los sensores microfónicos (10)
en base a una referencia de ruido dada por la señal emitida por el otro sensor microfónico (12) ;
estando el equipo caracterizado por que:
- el filtro adaptativo (16) es un filtro de retardo fraccionario, apto para modelar un retardo inferior al periodo de
15 muestreo de los medios de muestreo;
- el equipo comprende además medios de detección de actividad vocal (20, 22) aptos para emitir una señal
representativa de la presencia o de la ausencia de habla por el usuario del equipo; y
- el filtro adaptativo recibe igualmente como entrada la señal de presencia o de ausencia de habla para, de
manera selectiva: i) o bien operar una búsqueda adaptativa de los parámetros del filtro en ausencia de habla, ii)
20 o bien congelar estos parámetros del filtro en presencia de habla.
2. El equipo de audio según la reivindicación 1, en el que el filtro adaptativo (16) es apto para estimar un filtro
óptimo H de forma que:
con:
representando A la estimación del filtro óptimo H, la transferencia de ruido entre los dos sensores microfónicos para una respuesta de impulso que incluye un retardo fraccionario,
representando G la estimación del filtro del retardo fraccionario G entre los dos sensores microfónicos,
representando la estimación de la respuesta acústica del entorno, indicando
una convolución, siendo x (n) la serie de muestras de la señal de entrada del filtro H,
siendo x’ (n) la serie x (n) desplazada el retardo τ,
siendo Te el periodo de muestreo de la señal de entrada del filtro H, siendo τ dicho retardo fraccionario, igual a un submúltiplo de Te, e indicando sinc la función seno cardinal.
3. El equipo de audio según la reivindicación 1, en el que el filtro adaptativo es un filtro de logaritmo de predicción lineal de tipo mínimos cuadrados medios, LMS.
4. El equipo de audio según la reivindicación 1, en el que:
- el equipo comprende además una cámara de vídeo (26) dirigida hacia el usuario (30) del equipo y apta para captar una imagen de éste, y
- los medios de detección de actividad vocal (20) comprenden medios de análisis de vídeo aptos para analizar la imagen producida por la cámara y emitir como respuesta dicha señal de presencia o de ausencia de habla por dicho usuario.
5. El equipo de audio según la reivindicación 1, en el que:
- el equipo comprende además un sensor fisiológico (40) apto para situarse en contacto con la cabeza del
usuario del equipo para quedar allí acoplada con el fin de captar las vibraciones vocales acústicas transmitidas 5 por conducción ósea interna, y
- los medios de detección de actividad vocal (20) comprenden unos medios aptos para analizar la señal emitida por el sensor fisiológico y para emitir como respuesta dicha señal de presencia o de ausencia de habla por dicho usuario.
6. El equipo de audio según la reivindicación 5, en el que los medios de detección de actividad vocal comprenden 10 medios de evaluación de la energía de la señal emitida por el sensor fisiológico, y unos medios de umbral.
7. El equipo de audio según la reivindicación 6, en el que el equipo consiste en unos cascos de audio del tipo combinado micro/cascos, que comprende:
- unos auriculares (34) que incorporan cada uno un transductor de reproducción sonora de una señal de audio alojada en una carcasa (36) provista de una almohadilla (38) circumaural;
- dichos dos sensores microfónicos (10, 12) dispuestos sobre la carcasa de uno de los auriculares; y
- dicho sensor fisiológico (40) , incorporado en la almohadilla de dichos auriculares y colocado en una región de ésta apta para situarse en contacto con la mejilla o con la sien del portador de los casos.
8. El equipo de audio según la reivindicación 7, en el que los dos sensores microfónicos (10, 12) están alineados en una red lineal siguiendo una dirección principal (42) dirigida hacia la boca (44) del usuario del equipo.
Patentes similares o relacionadas:
Conformación simultánea de ruido en el dominio del tiempo y el dominio de la frecuencia para transformaciones TDAC, del 20 de Mayo de 2020, de VOICEAGE CORPORATION: Un método de conformación de ruido en el dominio de la frecuencia para interpolar una forma espectral y una envolvente en el dominio del tiempo del ruido […]
Codificador y método para codificar una señal de audio con ruido de fondo reducido que utiliza codificación predictiva lineal, del 11 de Diciembre de 2019, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Codificador para codificar una señal de audio (8') con ruido de fondo reducido utilizando codificación predictiva lineal, comprendiendo el codificador : […]
Método y aparato para la mejora multisensorial del habla en un dispositivo móvil, del 13 de Noviembre de 2019, de Zhigu Holdings Limited: Un dispositivo móvil de mano, que comprende: un micrófono de conducción de aire que está configurado para convertir ondas acústicas en una señal […]
Identificación de sonido procedente de una fuente de interés en base a múltiples suministros de audio, del 17 de Julio de 2019, de Microsoft Technology Licensing, LLC: Un sistema de procesamiento de sonido, que comprende: un primer dispositivo de captura de audio y un segundo dispositivo de captura […]
Sistemas y procedimientos de realización de filtrado para determinación de ganancia, del 6 de Junio de 2019, de QUALCOMM INCORPORATED: Un procedimiento que comprende: determinar, basándose en información espectral correspondiente a una señal de audio que incluye una parte […]
Procedimiento y sistema de escalado de atenuación de canales relevantes de voz en audio multicanal, del 16 de Abril de 2019, de DOLBY LABORATORIES LICENSING CORPORATION: Procedimiento para filtrar una señal de audio multicanal que tiene un canal de voz y al menos un canal sin voz, para mejorar la inteligibilidad de la voz […]
Corrección de pérdida de trama por inyección de ruido ponderado, del 20 de Marzo de 2019, de Orange: Procedimiento de tratamiento de una señal digital, implementado durante una decodificación de la señal para sustituir una sucesión de muestras perdida en la decodificación, […]
Aparato y procedimiento para procesamiento y señal de audio para mejora de habla mediante el uso de una extracción de característica, del 25 de Abril de 2018, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Aparato para el procesamiento de una señal de audio para obtener información de control por subbanda para un filtro de mejora de habla, que […]