Realce de voz en audio de entretenimiento.
Un método para realzar la voz en audio de entretenimiento (101),
que comprende procesar, en respuesta a uno omás controles (103), dicho audio de entretenimiento (101) para mejorar la claridad e inteligibilidad de porciones devoz del audio de entretenimiento (101), incluyendo dicho procesamiento:
- variar el nivel del audio de entretenimiento (101) en cada una de múltiples bandas de frecuencia de acuerdo conuna característica de ganancia (302, 404) que relaciona el nivel de la señal de banda (403) con la ganancia (405), y
- generar un control (103, 414) para variar dicha característica de ganancia (302, 404) en cada banda de frecuencia,incluyendo dicha generación:
caracterizar segmentos de tiempo de dicho audio de entretenimiento (101) como (a) voz o sin voz o (b) comoprobabilidad de ser voz o sin voz, en donde dicha caracterización opera sobre una única banda ancha de frecuencia,obtener, en cada una de dichas múltiples bandas de frecuencia, una estimación de la potencia de la señal (403),rastrear, en cada una de dichas múltiples bandas de frecuencia, el nivel de las señales de audio sin voz (411) en labanda, siendo el tiempo de respuesta del rastreo sensible a dicha estimación de la potencia de la señaltransformar el nivel rastreado de las señales de audio sin voz (411) en cada banda en un nivel umbral de expansiónadaptable correspondiente (306, 414), e
influir en cada uno de dichos niveles umbrales de expansión adaptables correspondientes (306, 414) con elresultado de dicha caracterización para producir dicho control (103, 414) para cada banda.
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/US2008/002238.
Solicitante: DOLBY LABORATORIES LICENSING CORPORATION.
Nacionalidad solicitante: Estados Unidos de América.
Dirección: 100 POTRERO AVENUE SAN FRANCISCO, CA 94103-4813 ESTADOS UNIDOS DE AMERICA.
Inventor/es: MUESCH,HANNES.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G10L11/02
- G10L21/02 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › G10L 21/00 Tratamiento de la señal de la voz para producir otra señal audible o no audible, p. ej. visual o táctil, con el fin de modificar su calidad o su inteligibilidad (G10L 19/00 tiene prioridad). › Mejora de la inteligibilidad de la voz, p. ej. reducción de ruido o eliminación de ecos (reducción de efectos de eco en los sistemas de transmisión en línea H04B 3/20; supresión de eco en teléfonos de manos libres H04M 9/08).
- H04R25/00 ELECTRICIDAD. › H04 TECNICA DE LAS COMUNICACIONES ELECTRICAS. › H04R ALTAVOCES, MICROFONOS, CABEZAS DE LECTURA PARA GRAMOFONOS O TRANSDUCTORES ACUSTICOS ELECTROMECANICOS ANALOGOS; APARATOS PARA SORDOS; SISTEMAS PARA ANUNCIOS EN PUBLICO (producción de sonidos cuya frecuencia no está determinada por la frecuencia de alimentación G10K). › Aparatos para sordos.
PDF original: ES-2391228_T3.pdf
Fragmento de la descripción:
Realce de voz en audio de entretenimiento
5 Campo técnico
La invención se refiere al procesamiento de señales de audio. Más específicamente, la invención se refiere al procesamiento de audio de entretenimiento, tal como audio de televisión, para mejorar la claridad e inteligibilidad de la voz, tal como audio de diálogo y narración. La invención se refiere a métodos, aparatos para realizar tales métodos, y a software almacenado en un medio legible por ordenador para hacer que un ordenador realice tales métodos.
Técnica antecedente
El entretenimiento audiovisual ha evolucionado a una secuencia apresurada de diálogo, narración, música y efectos. El elevado realismo que se puede alcanzar con las modernas tecnologías de audio de entretenimiento y los métodos de producción ha fomentado el uso de estilos de oratoria conversacional en la televisión que difieren sustancialmente de la presentación escenográfica claramente anunciada del pasado. Esta situación plantea un problema no sólo para la creciente población de espectadores de edad avanzada quienes, enfrentados con capacidades disminuidas de procesamiento sensorial y de lenguaje, deben esforzarse por seguir la programación sino también para las personas con audición normal, por ejemplo, cuando escuchan bajos niveles acústicos.
Lo bien que se entiende la voz depende de varios factores. Ejemplos son el cuidado de la producción de la voz (voz clara o conversacional) , el ritmo de la voz, y la audibilidad de la voz. El lenguaje hablado es notablemente enérgico y
puede entenderse bajo condiciones no precisamente ideales. Por ejemplo, los oyentes con problemas de audición típicamente pueden seguir una voz clara incluso cuando no pueden oír partes del discurso debido a una agudeza auditiva disminuida. Sin embargo, a medida que el ritmo de oratoria aumenta y la producción de voz se vuelve menos precisa, la escucha y la comprensión requieren mayor esfuerzo, particularmente si partes del espectro de la voz son inaudibles.
Como las audiencias televisivas no pueden hacer nada que afecte a la claridad de la voz emitida, los oyentes con problemas de audición pueden intentar compensar la audibilidad inadecuada aumentando el volumen de escucha. Aparte de resultar desagradable para las personas de audición normal que están en la misma habitación o para los vecinos, este enfoque es sólo parcialmente eficaz. Esto es así porque la mayoría de las pérdidas auditivas no son
uniformes a lo largo de la frecuencia; afectan a las altas frecuencias más que a las bajas y medias frecuencias. Por ejemplo, la capacidad típica de un varón de 70 años de oír sonidos a 6 kHz es aproximadamente 50 dB peor que la de una persona joven, a frecuencias por debajo de 1 kHz la desventaja auditiva de una persona mayor es inferior a 10 dB (ISO 7029, Acústica - Distribución estadística del umbral auditivo como una función de la edad) . Aumentar el volumen eleva los sonidos de baja y media frecuencia sin aumentar significativamente su contribución a la inteligibilidad porque para esas frecuencias la audibilidad ya es adecuada. Aumentar el volumen tampoco hace mucho por vencer la pérdida auditiva significativa a altas frecuencias. Una corrección más apropiada es un control de tono, como el proporcionado por un ecualizador gráfico.
Aunque es una opción mejor que simplemente aumentar el control de volumen, un control de tono aún es
45 insuficiente para la mayoría de las pérdidas auditivas. La gran ganancia de alta frecuencia requerida para hacer que los pasajes tenues resulten audibles para el oyente con problemas de audición es probable que sea incómodamente alta durante los pasajes de nivel alto e incluso puede sobrecargar la cadena de reproducción de audio. Una solución mejor es amplificar dependiendo del nivel de la señal, proporcionando mayores ganancias a porciones de señal de nivel bajo y menores ganancias (o ninguna ganancia en absoluto) a porciones de nivel alto. Tales sistemas, conocidos como controles automáticos de ganancia (AGC) o compresores de rango dinámico (DRC) se usan en ayudas auditivas y se ha propuesto su uso para mejorar la inteligibilidad para las personas con problemas de audición en los sistemas de telecomunicación (por ejemplo, la patente de EE.UU. 5.388.185, la patente de EE.UU. 5.539.806, y la patente de EE.UU. 6.061.431) .
55 Como la pérdida auditiva generalmente se desarrolla gradualmente, la mayoría de los oyentes con dificultades auditivas han crecido acostumbrados a sus pérdidas. Como resultado, a menudo ponen objeciones a la calidad del audio de entretenimiento cuando es procesado para compensar sus problemas de audición. Es más probable que las audiencias con problemas de audición acepten la calidad de sonido del audio compensado cuando les proporciona un beneficio tangible, como cuando aumenta la inteligibilidad del diálogo y la narración o reduce el esfuerzo mental requerido para la comprensión. Por lo tanto, es ventajoso limitar la aplicación de la compensación de pérdida auditiva a aquellas partes del programa de audio que están dominadas por voz. Hacerlo así optimiza el compromiso entre las modificaciones de calidad de sonido potencialmente desagradables de la música y los sonidos ambiente por una parte, y los beneficios de inteligibilidad deseables por otra.
65 El documento US 6198830 describe un método y circuito para la amplificación de señales de entrada de una ayuda auditiva, en el que una compresión de las señales captadas por la ayuda auditiva sucede en un circuito AGC dependiente del nivel de señal adquirible. Para asegurar una compresión de dinámica, el método y circuito implementan un análisis de señal para el reconocimiento de la situación acústica además de la adquisición del nivel de señal de la señal de entrada, y el comportamiento de la compresión de dinámica se varía de manera adaptativa basándose en el resultado del análisis de la señal.
Exposición de la invención
Según un aspecto de la invención tal como se define en las reivindicaciones independientes, la voz en el audio de entretenimiento puede realzarse procesando, en respuesta a uno o más controles, el audio de entretenimiento para mejorar la claridad e inteligibilidad de porciones de voz del audio de entretenimiento, y generando un control para el procesamiento, incluyendo la generación la caracterización de segmentos de tiempo del audio de entretenimiento como (a) voz o sin voz o (b) como probabilidad de ser voz o sin voz, y la respuesta a los cambios en el nivel del audio de entretenimiento para proporcionar un control para el procesamiento, en el que a tales cambios se les responde dentro de un periodo de tiempo más corto que los segmentos de tiempo, y un criterio de decisión de la
respuesta es controlado por la caracterización. El procesamiento y la respuesta pueden operar cada uno en múltiples bandas de frecuencia correspondientes, proporcionando la respuesta un control para el procesamiento para cada una de las múltiples bandas de frecuencia.
Algunos aspectos de la invención pueden operar de una manera “anticipada” de manera que cuando hay acceso a una evolución de tiempo del audio de entretenimiento antes y después de un punto de procesamiento, y en la que la generación de un control responde a al menos algún audio después del punto de procesamiento.
Algunos aspectos de la invención pueden emplear separación temporal y / o espacial de manera que alguno del procesamiento, la caracterización o la respuesta se realicen en momentos diferentes o en lugares diferentes. Por
ejemplo, la caracterización puede realizarse en un primer momento o lugar, el procesamiento y la respuesta pueden realizarse en un segundo momento o lugar, y la información acerca de la caracterización de los segmentos de tiempo puede almacenarse o transmitirse para controlar los criterios de decisión de la respuesta.
Algunos aspectos de la invención también pueden incluir la codificación del audio de entretenimiento de acuerdo con un esquema de codificación perceptiva o un esquema de codificación sin pérdidas, y la descodificación del audio de entretenimiento de acuerdo con el mismo esquema de codificación empleado por la codificación, en la que alguno del procesamiento, la caracterización, y la respuesta se realizan junto con la codificación o la descodificación. La caracterización puede realizarse junto con la codificación y el procesamiento y / o la respuesta pueden realizarse junto con... [Seguir leyendo]
Reivindicaciones:
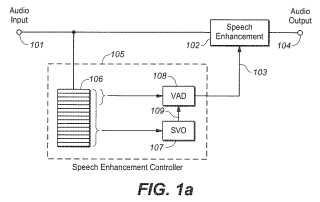
1. Un método para realzar la voz en audio de entretenimiento (101) , que comprende procesar, en respuesta a uno o
más controles (103) , dicho audio de entretenimiento (101) para mejorar la claridad e inteligibilidad de porciones de 5 voz del audio de entretenimiento (101) , incluyendo dicho procesamiento:
- variar el nivel del audio de entretenimiento (101) en cada una de múltiples bandas de frecuencia de acuerdo con una característica de ganancia (302, 404) que relaciona el nivel de la señal de banda (403) con la ganancia (405) , y
- generar un control (103, 414) para variar dicha característica de ganancia (302, 404) en cada banda de frecuencia, incluyendo dicha generación:
caracterizar segmentos de tiempo de dicho audio de entretenimiento (101) como (a) voz o sin voz o (b) como probabilidad de ser voz o sin voz, en donde dicha caracterización opera sobre una única banda ancha de frecuencia, 15 obtener, en cada una de dichas múltiples bandas de frecuencia, una estimación de la potencia de la señal (403) ,
rastrear, en cada una de dichas múltiples bandas de frecuencia, el nivel de las señales de audio sin voz (411) en la banda, siendo el tiempo de respuesta del rastreo sensible a dicha estimación de la potencia de la señal,
transformar el nivel rastreado de las señales de audio sin voz (411) en cada banda en un nivel umbral de expansión adaptable correspondiente (306, 414) , e
influir en cada uno de dichos niveles umbrales de expansión adaptables correspondientes (306, 414) con el 25 resultado de dicha caracterización para producir dicho control (103, 414) para cada banda.
2. Un método para realzar la voz en audio de entretenimiento (101) , que comprende procesar, en respuesta a uno o más controles (103) , dicho audio de entretenimiento (101) para mejorar la claridad e inteligibilidad de porciones de voz del audio de entretenimiento (101) , incluyendo dicho procesamiento:
- variar el nivel del audio de entretenimiento (101) en cada una de múltiples bandas de frecuencia de acuerdo con una característica de ganancia (302, 404) que relaciona el nivel de la señal de banda (403) con la ganancia (405) , y
- generar un control (103, 414) para variar dicha característica de ganancia (302, 404) en cada banda de frecuencia, 35 incluyendo dicha generación:
recibir caracterizaciones de segmentos de tiempo de dicho audio de entretenimiento (101) como (a) voz o sin voz o
(b) como probabilidad de ser voz o sin voz, en donde dichas caracterizaciones se refieren a una única banda ancha de frecuencia,
obtener, en cada una de dichas múltiples bandas de frecuencia, una estimación de la potencia de la señal (403) ,
rastrear, en cada una de dichas múltiples bandas de frecuencia, el nivel de las señales de audio sin voz (411) en la banda, siendo el tiempo de respuesta del rastreo sensible a dicha estimación de la potencia de la señal,
45 transformar el nivel rastreado de las señales de audio sin voz (411) en cada banda en un nivel umbral de expansión adaptable correspondiente (306, 414) , e
influir en cada uno de dichos niveles umbrales de expansión adaptables correspondientes (306, 414) con el resultado de dicha caracterización para producir dicho control (103, 414) para cada banda.
3. Un método según la reivindicación 1 o la reivindicación 2 en el que existe acceso a una evolución temporal del audio de entretenimiento antes y después de un punto de procesamiento, y en el que dicha generación de un control responde a al menos algún audio después del punto de procesamiento.
4. Un método según una cualquiera de las reivindicaciones 1 - 3 en el que dicho procesamiento opera de acuerdo con uno o más parámetros de procesamiento.
5. Un método según la reivindicación 4 en el que el ajuste de uno o más parámetros es sensible al audio de entretenimiento de manera que una métrica de inteligibilidad de la voz del audio procesado se maximiza o se impulsa por encima de un nivel umbral deseado.
6. Un método según la reivindicación 5 en el que el audio de entretenimiento comprende múltiples canales de audio en los que un canal es fundamentalmente voz y el otro canal o los demás canales son fundamentalmente sin voz, en
65 los que la métrica de inteligibilidad de la voz está basada en el nivel del canal de voz y el nivel en el otro canal o los demás canales.
7. Un método según la reivindicación 5 o la reivindicación 6 en el que la métrica de inteligibilidad de la voz también está basada en el nivel de ruido en un ambiente de escucha en el que se reproduce el audio procesado.
8. Un método según una cualquiera de las reivindicacione.
4. 7 en el que el ajuste de uno o más parámetros es sensible a uno o más descriptores a largo plazo del audio de entretenimiento.
9. Un método según la reivindicación 8 en el que un descriptor a largo plazo es el nivel medio de diálogo del audio
de entretenimiento. 10
10. Un método según la reivindicación 8 o la reivindicación 9 en el que un descriptor a largo plazo es una estimación del procesamiento ya aplicado al audio de entretenimiento.
11. Un método según la reivindicación 4 en el que el ajuste de uno o más parámetros es de acuerdo con una fórmula
prescriptiva, en el que la fórmula prescriptiva relaciona la agudeza auditiva de un oyente o grupo de oyentes con el uno o más parámetros.
12. Un método según la reivindicación 4 en el que el ajuste de uno o más parámetros es de acuerdo con las
preferencias de uno o más oyentes. 20
13. Un método según una cualquiera de las reivindicaciones 1 -12 en el que dicho procesamiento proporciona control de rango dinámico, ecualización dinámica, agudización espectral, extracción de voz, reducción de ruido, u otra acción de realce de voz.
14. Un método según la reivindicación 13 en el que el control de rango dinámico se proporciona mediante una función de compresión / expansión de rango dinámico.
15. Aparato que comprende medios adaptados para realizar el método de una cualquiera de las reivindicaciones 1 a
14. 30
16. Un programa informático, almacenado en un medio legible por ordenador para hacer que un ordenador realice el método de una cualquiera de las reivindicaciones 1 a 14.
17. Un medio legible por ordenador que almacena en el mismo el programa informático que realiza el método de una 35 cualquiera de las reivindicaciones 1 - 14.
Patentes similares o relacionadas:
SISTEMA Y DISPOSITIVO INALÁMBRICO Y PONIBLE PARA REGISTRO, PROCESAMIENTO Y REPRODUCCIÓN DE SONIDOS EN PERSONAS CON DISTROFIA EN EL SISTEMA RESPIRATORIO, del 5 de Marzo de 2020, de ARAGÓN HAN, Daniel: La invención se refiere a un sistema y dispositivo para el registro, procesamiento y reproducción de sonidos en personas con distrofia en el […]
Métodos, aparatos y sistema para codificar y decodificar una señal, del 8 de Enero de 2020, de HUAWEI TECHNOLOGIES CO., LTD.: Un método para codificar una señal, que comprende: realizar un proceso de decisión de clasificación sobre una señal de banda de alta frecuencia de una señal […]
Métodos para codificar y decodificar una señal de audio, decodificador de audio y codificador de audio, del 1 de Enero de 2020, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un método para codificar una señal de audio, comprendiendo el método: (a) recibir una señal de audio ; (b) generar una señal de audio codificada; […]
Método y aparato para la mejora multisensorial del habla en un dispositivo móvil, del 13 de Noviembre de 2019, de Zhigu Holdings Limited: Un dispositivo móvil de mano, que comprende: un micrófono de conducción de aire que está configurado para convertir ondas acústicas en una señal […]
Método y dispositivo de enriquecimiento espectral, del 14 de Junio de 2019, de Orange: Procedimiento de enriquecimiento del contenido espectral de una señal que tiene un espectro incompleto incluyendo una primera banda espectral, comprendiendo […]
Transposición armónica basada en bloque de sub bandas mejorada, del 22 de Mayo de 2019, de DOLBY INTERNATIONAL AB: Un sistema configurado para generar una señal transpuesta en frecuencia y/o extendida en el tiempo a partir de una señal de entrada de audio, […]
Procedimiento y aparato de procesamiento de señales de voz/audio, del 15 de Mayo de 2019, de HUAWEI TECHNOLOGIES CO., LTD.: Un procedimiento de procesamiento de señales de voz/audio, que comprende: cuando una señal de voz/audio conmuta desde una señal de frecuencia ancha a una […]
Sistema y método para emitir y controlar especialmente una señal de audio en un entorno usando una medida de inteligibilidad objetivo, del 27 de Marzo de 2019, de ROBERT BOSCH GMBH: Sistema para emitir una senal de audio en un entorno , comprendiendo el sistema : una fuente de audio para proporcionar la senal de audio, […]