AMBITOS DE CONMUTACIÓN POR FALLO PARA NODOS DE UNA AGRUPACIÓN DE ORDENADORES.
Un procedimiento en un entorno informático, que comprende: definir una pluralidad de ámbitos (302) de conmutación por fallo que son subconjuntos de nodos seleccionados dentro de una agrupación de nodos (N1 - N11);
asociar la pluralidad de ámbitos de conmutación por fallo con un grupo (RG1 - RGn) de recursos, estando ordenada la pluralidad de ámbitos de conmutación por fallo para la conmutación por fallo; y conmutar por fallo el grupo de recursos de un nodo a otro nodo que pertenece a un primer ámbito de conmutación por fallo de la pluralidad de ámbitos de conmutación por fallo asociados con el grupo de recursos según la ordenación de los ámbitos de conmutación por fallo para dicho grupo de recursos
Tipo: Patente Europea. Resumen de patente/invención. Número de Solicitud: E05108801.
Solicitante: MICROSOFT CORPORATION.
Nacionalidad solicitante: Estados Unidos de América.
Dirección: ONE MICROSOFT WAY REDMOND, WASHINGTON 98052-6399 ESTADOS UNIDOS DE AMERICA.
Inventor/es: Subbaraman,Chittur P. , Shrivastava,Sunita.
Fecha de Publicación: .
Fecha Solicitud PCT: 23 de Septiembre de 2005.
Clasificación Internacional de Patentes:
- G06F11/20P2
Clasificación PCT:
- G06F11/00 FISICA. › G06 CALCULO; CONTEO. › G06F PROCESAMIENTO ELECTRICO DE DATOS DIGITALES (sistemas de computadores basados en modelos de cálculo específicos G06N). › Detección de errores; Corrección de errores; Monitorización (detección, corrección o monitorización de errores en el almacenamiento de información basado en el movimiento relativo entre el soporte de registro y el transductor G11B 20/18; monitorización, es decir, supervisión del progreso del registro o reproducción G11B 27/36; en memorias estáticas G11C 29/00).
Clasificación antigua:
- G06F11/00 G06F […] › Detección de errores; Corrección de errores; Monitorización (detección, corrección o monitorización de errores en el almacenamiento de información basado en el movimiento relativo entre el soporte de registro y el transductor G11B 20/18; monitorización, es decir, supervisión del progreso del registro o reproducción G11B 27/36; en memorias estáticas G11C 29/00).
Países PCT: Austria, Bélgica, Suiza, Alemania, Dinamarca, España, Francia, Reino Unido, Grecia, Italia, Liechtensein, Luxemburgo, Países Bajos, Suecia, Mónaco, Portugal, Irlanda, Eslovenia, Finlandia, Rumania, Chipre, Lituania, Letonia, Ex República Yugoslava de Macedonia, Albania.
Fragmento de la descripción:
CAMPO DE LA INVENCIÓN
La invención se refiere, en general, a nodos informáticos agrupados, y más en particular al tratamiento de fallos de aplicaciones o de los nodos de una agrupación (cluster) que las alojan.
ANTECEDENTES 5
Una agrupación es un conjunto de servidores de sistema informático interconectados dispuestos como nodos que proporcionan acceso a recursos tales como programas de aplicación de servidor. Un motivo para tener una agrupación de servidores es que múltiples sistemas informáticos enlazados mejoran significativamente la disponibilidad y la fiabilidad informática, al tiempo que tienen más potencia de procesamiento, velocidad y otros recursos mediante la distribución de la carga. 10
Con respecto a la disponibilidad y la fiabilidad en una agrupación, si un nodo o una aplicación alojada falla, sus recursos se conmutan por fallo a otros nodos supervivientes, donde, en general, conmutación por fallo significa que los otros nodos proporcionan aplicaciones alojadas que corresponden a las que anteriormente proporcionaba el nodo que ahora ha fallado. Los tipos de fallos incluyen una caída de sistema informático, una interrupción en un enlace de comunicaciones entre nodos, paradas intencionadas para mantenimiento o similares, paradas 15 involuntarias tales como desconectar la potencia accidentalmente o un cable de comunicaciones, etcétera.
Para tratar los fallos de alguna manera controlada para que las aplicaciones fallidas se reinicien apropiadamente en otros nodos, se realizó un intento de conmutar por fallo grupos de recursos (denominados cada uno grupo de recursos, que es un conjunto de uno o más recursos tales como programas de aplicación y recursos relacionados tales como nombres de red, direcciones IP y similares que se gestionan como una única unidad con 20 respecto a la conmutación por fallo) a un nodo preferido basándose en una lista de nodos preferidos. Sin embargo, esto tendía a sobrecargar ciertos nodos debido a que muchos grupos de recursos tenían la misma configuración por defecto para sus nodos preferidos. Para evitar este problema, la tecnología de agrupamiento actual prevé que cuando está disponible más de un nodo superviviente, se usa un algoritmo basado en números aleatorios para elegir el nodo de destino para grupos de recursos si no se proporciona ninguna configuración para la lista de propietarios 25 preferidos para un grupo de recursos (al menos entre nodos que puede alojar los grupos), de modo no se sobrecargue ningún nodo asumiendo demasiados grupos de recursos del nodo o nodos fallidos.
Con respecto a la potencia / velocidad de computación, sistemas informáticos físicamente próximos en una agrupación están enlazados normalmente mediante conexiones de red de ancho de banda muy alto. Sin embargo, no todos los nodos de la agrupación están físicamente próximos, puesto que las empresas (particularmente las 30 empresas grandes) a menudo separan dos o más subconjuntos de tales nodos agrupados interconectados de manera próxima entre sí por distancias geográficas relativamente grandes. Una finalidad de esto es la protección frente a desastres, para tener así un cierto número de nodos en funcionamiento en caso de un huracán, incendio, terremoto o similares que pueden hacer que todo un subconjunto físicamente próximo de nodos interconectados fallen globalmente, ya sea el motivo del fallo el propio fallo de los nodos o una interrupción en el medio de 35 transmisión entre ese subconjunto de nodos y otros nodos distantes.
Un problema con la protección frente a desastres por separación geográfica es que el ancho de banda de comunicaciones entre un subconjunto de nodos interconectados de manera próxima con el de otro subconjunto es muy inferior al ancho de banda de comunicaciones dentro del subconjunto. Como resultado, algunos administradores de agrupaciones no desean necesariamente que los grupos de recursos conmuten por fallo de 40 manera automática de un subconjunto interconectado de manera próxima a otro (a menos que falle un subconjunto entero), porque el tiempo y el gasto de conmutar por fallo los recursos desde incluso un nodo es significativo, dada la conexión de ancho de banda bajo. En lugar de ello, los administradores de agrupaciones a menudo preferirían conmutar por fallo los grupos de recursos sólo a nodos interconectados de manera próxima. En el caso de que falle un subconjunto entero, algunos administradores preferirían evaluar la causa y solucionar el problema (por ejemplo, 45 un cable desconectado) si es posible, y sólo conmutar por fallo manualmente los grupos de recursos si es necesario, lo que puede requerir alguna reconfiguración del otro subconjunto para aceptar los grupos de recursos conmutados por fallo. Otros administradores desean sin embargo que la conmutación por fallo sea automática, al menos en cierta medida, si falla un subconjunto entero. Además, cuando se tratan agrupaciones de consolidación, que son agrupaciones que alojan múltiples aplicaciones, muchos administradores desearían limitar el conjunto de nodos en 50 el que puede alojarse una aplicación compuesta por diversos componentes.
Sin embargo, con el mecanismo de conmutación por fallo aleatorio descrito anteriormente que se usaba hasta ahora, así como otros mecanismos anteriores, los administradores no pueden configurar sus agrupaciones para la conmutación por fallo de la manera que se desea. De hecho, con el mecanismo aleatorio no hay distinción entre nodos físicamente próximos o físicamente distantes cuando se conmutan por fallo grupos de recursos. Lo que 55 se necesita es una manera flexible de que los administradores de agrupaciones gestionen las acciones automáticas que una agrupación adoptará en caso de fallo.
El documento US 6,718,486 B1 se refiere a un sistema informático con un marco de tolerancia a fallos en
una arquitectura informática extensible. El sistema informático está formado por agrupaciones de nodos en las que cada nodo incluye hardware informático y software de sistema operativo para ejecutar trabajos que implementan los servicios proporcionados por el sistema informático. Los trabajos se distribuyen entre los nodos bajo el control de una unidad de gestión de recursos jerárquica.
El documento US 6,178,529 B1 se refiere a un procedimiento y a un sistema en una agrupación de 5 servidores para monitorizar y controlar un objeto de recurso, tal como una aplicación o dispositivo físico. Un servicio de agrupación se conecta a un componente de monitorización de recursos para controlar y monitorizar el buen estado de uno o más objetos de recurso.
Sumario de la invención
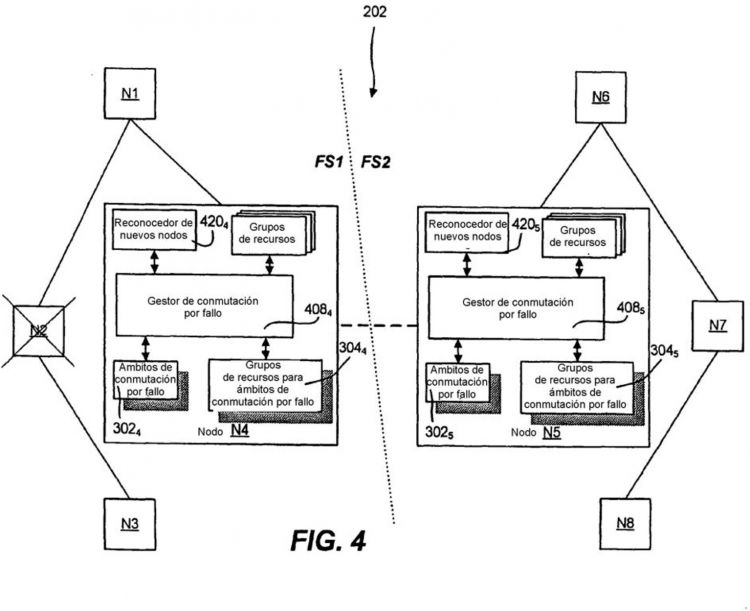
Un objeto de la presente invención es proporcionar un sistema y procedimiento mediante el cual se definen 10 ámbitos de conmutación por fallo, comprendiendo cada uno un subconjunto de nodos identificados de una agrupación, y mediante el cual los grupos de recursos pueden asociarse con una lista ordenada de uno o más ámbitos de conmutación por fallo.
Este objeto se soluciona mediante el contenido de las reivindicaciones independientes.
Se dan realizaciones en las reivindicaciones dependientes. 15
Cuando se produce una conmutación por fallo, cada grupo de recursos conmuta por fallo automáticamente a un nodo superviviente enumerado en su ámbito de conmutación por fallo. Basándose en la ordenación, hasta que tenga éxito, la conmutación por fallo se intentará en primer lugar a cada uno de los nodos dentro del ámbito de conmutación por fallo activo actual antes de intentar la conmutación por fallo a cualquier nodo en el siguiente ámbito de conmutación por fallo. 20
Si ningún nodo dentro del primer ámbito de conmutación por fallo puede aceptar la conmutación por fallo, (por ejemplo, ninguno ha sobrevivido), el grupo de recursos puede configurarse para la conmutación por fallo automática a un nodo enumerado en el siguiente ámbito de conmutación por fallo, y así sucesivamente hasta que no haya fallo. Para dar al administrador la capacidad de impedir tal conmutación por fallo automática a un nodo de otro ámbito de conmutación por fallo, se establece una configuración manual (por ejemplo, un indicador manual / 25 automática) que impide una conmutación por fallo automática a un ámbito de conmutación por fallo enumerado subsiguiente. Puede haber un indicador de este tipo por cada par de ámbitos de conmutación por fallo asociados con un grupo de recursos, (por ejemplo, dos indicadores para tres ámbitos de conmutación por fallo, una que establece transición...
Reivindicaciones:
1. Un procedimiento en un entorno informático, que comprende:
definir una pluralidad de ámbitos (302) de conmutación por fallo que son subconjuntos de nodos seleccionados dentro de una agrupación de nodos (N1 - N11);
asociar la pluralidad de ámbitos de conmutación por fallo con un grupo (RG1 - RGn) de recursos, estando ordenada la pluralidad de ámbitos de conmutación por fallo para la conmutación por fallo; y 5
conmutar por fallo el grupo de recursos de un nodo a otro nodo que pertenece a un primer ámbito de conmutación por fallo de la pluralidad de ámbitos de conmutación por fallo asociados con el grupo de recursos según la ordenación de los ámbitos de conmutación por fallo para dicho grupo de recursos.
2. El procedimiento según la reivindicación 1, en el que definir la pluralidad de ámbitos de conmutación por fallo comprende definir al menos parte de la pluralidad de ámbitos de conmutación por fallo a través de un 10 proceso automático.
3. El procedimiento según la reivindicación 1, en el que definir la pluralidad de ámbitos de conmutación por fallo comprende recibir una entrada desde un administrador con respecto a al menos parte de la pluralidad de ámbitos de conmutación por fallo.
4. El procedimiento según la reivindicación 1, en el que definir la pluralidad de ámbitos de conmutación por 15 fallo comprende definir al menos parte de la pluralidad de ámbitos de conmutación por fallo para que corresponda a un sitio.
5. El procedimiento según la reivindicación 1, que comprende además detectar la adición de un nuevo nodo, y modificar la pluralidad de ámbitos de conmutación por fallo para incluir información correspondiente al nuevo nodo. 20
6. El procedimiento según la reivindicación 1, en el que se realiza un intento de conmutar por fallo el grupo de recursos a un nodo en el ámbito de conmutación por fallo de orden más alto antes de realizar un intento de conmutar por fallo el grupo de recursos a un nodo en cualquier otro ámbito de conmutación por fallo.
7. El procedimiento según la reivindicación 6, en el que el intento de conmutar por fallo el grupo de recursos a un nodo en el ámbito de conmutación por fallo de orden más alto no tiene éxito, y que comprende además, 25 acceder a datos que indican si es necesaria una intervención manual antes de intentar conmutar por fallo el recurso a un nodo de un segundo ámbito de conmutación por fallo.
8. El procedimiento según la reivindicación 7, en el que los datos indican que es necesaria una intervención manual, y que comprende además esperar a la intervención manual antes de conmutar por fallo el recurso a un nodo del segundo ámbito de conmutación por fallo. 30
9. El procedimiento según la reivindicación 1, que comprende además impedir la intersección de nodos entre los ámbitos de conmutación por fallo asociados con el grupo de recursos.
10. El procedimiento según la reivindicación 1, en el que conmutar por fallo el grupo de recursos de un nodo a otro nodo comprende seleccionar el otro nodo de entre una pluralidad de nodos candidatos en el primer ámbito de conmutación por fallo. 35
11. El procedimiento según la reivindicación 10, en el que la selección del otro nodo de entre una pluralidad de nodos candidatos se basa en una selección aleatoria.
12. El procedimiento según la reivindicación 10, en el que la selección del otro nodo de entre una pluralidad de nodos candidatos se basa en el cumplimiento de al menos un criterio.
13. El procedimiento según la reivindicación 1, que comprende además: 40
intentar conmutar por fallo el grupo de recursos de un nodo a otro nodo del primer ámbito de conmutación por fallo, y si el intento no tiene éxito con cada nodo del primer ámbito de conmutación por fallo, conmutar por fallo el grupo de recursos a un nodo de un segundo ámbito de conmutación por fallo de la pluralidad de ámbitos de conmutación por fallo.
14. Un medio legible por ordenador que tiene instrucciones ejecutables por ordenador que, cuando se ejecutan, 45 realizan el procedimiento según una de las reivindicaciones 1 a 13.
15. Un sistema, en un entorno informático, que comprende:
una agrupación que comprende
una pluralidad de nodos (N1 - N11); y
un mecanismo que se ejecuta en al menos uno de los nodos adaptado para seleccionar un primer ámbito de conmutación por fallo entre una pluralidad de ámbitos de conmutación por fallo asociados con un grupo (RG1 - RGn) de recursos cuando es necesario conmutar por fallo el grupo de recursos de un nodo a otro nodo, estando ordenada la pluralidad de ámbitos de conmutación por fallo para la 5 conmutación por fallo, siendo el primer ámbito de conmutación por fallo un subconjunto de la pluralidad de nodos, intentando el mecanismo conmutar por fallo el grupo de recursos en primer lugar a un nodo del primer ámbito de conmutación por fallo, en el que el mecanismo selecciona el primer ámbito de conmutación por fallo según dicha ordenación de los ámbitos de conmutación por fallo para dicho grupo de recursos. 10
16. El sistema según la reivindicación 15, en el que el mecanismo no logra conmutar por fallo el grupo de recursos al ámbito de conmutación por fallo seleccionado, y en el que el mecanismo selecciona un nuevo ámbito de conmutación por fallo seleccionado de entre la pluralidad de ámbitos de conmutación por fallo e intenta conmutar por fallo a continuación el grupo de recursos a un nodo del nuevo ámbito de conmutación por fallo seleccionado. 15
17. El sistema según la reivindicación 15, en el que el mecanismo no logra conmutar por fallo el grupo de recursos al ámbito de conmutación por fallo seleccionado, y en el que el mecanismo comprueba datos para determinar si puede seleccionarse otro ámbito de conmutación por fallo para un intento automático de conmutar por fallo el grupo de recursos a un nodo del otro ámbito de conmutación por fallo.
18. El sistema según la reivindicación 15, en el que el primer ámbito de conmutación por fallo seleccionado 20 corresponde a un sitio.
Patentes similares o relacionadas:
Detección de daño de pantalla para dispositivos, del 8 de Julio de 2020, de Hyla, Inc: Un procedimiento para identificar una condición de una o más pantallas de un dispositivo electrónico, comprendiendo el procedimiento: recibir una solicitud […]
Sistema electrónico que comprende dispositivos electrónicos, disyuntor que comprende dicho sistema, procedimiento de generación de un indicador de desviación en caso de incompatibilidad entre dispositivos y producto de programa de ordenador asociado, del 15 de Enero de 2020, de SCHNEIDER ELECTRIC INDUSTRIES SAS: Sistema electrónico que comprende un conjunto de dispositivos (12A, 12B, 12C, 12D) electrónicos, comprendiendo cada dispositivo (12A, 12B, 12C, 12D) […]
UN MÉTODO Y UN DISPOSITIVO DE PROCESAMIENTO EN PARALELO DE INSTRUCCIONES DE PROGRAMA E INSTRUCCIONES DE TRAZA, del 26 de Septiembre de 2019, de UNIVERSIDAD POLITECNICA DE MADRID: Método y dispositivo de sincronización y ejecución paralela de instrucciones de traza sobre un procesador RISC segmentado. La invención consiste en un dispositivo cuya estructura […]
Sistema y método de calificación para el funcionamiento de plantas de agua helada, del 26 de Junio de 2019, de SIEMENS INDUSTRY, INC: Programa informático integrado en un medio tangible para determinar uno o más efectos de los cambios en una planta de agua helada, que consta […]
Sistema de ciberseguridad, del 29 de Mayo de 2019, de Ironnet Cybersecurity, Inc: Un sistema de ciberseguridad para procesar eventos para producir puntajes, alertas y acciones de mitigación, el sistema que comprende: una pluralidad de […]
Predicción, diagnóstico y recuperación de fallos de aplicaciones en base a patrones de acceso a recursos, del 1 de Mayo de 2019, de Microsoft Technology Licensing, LLC: Un procedimiento implementado por ordenador, para predecir una posible condición de error en un programa de aplicación que se ejecuta […]
PROCEDIMIENTO PARA CONTROL DE DISPOSITIVOS ELECTRODOMÉSTICOS E INSTALACIÓN PARA LLEVARLO A CABO, del 7 de Febrero de 2019, de NUBE PRINT, S.L: Procedimiento e instalación para el control de dispositivos electrodomésticos que emplea sólo los datos necesarios, evitando la saturación de las memorias de los elementos […]
UN MÉTODO Y UN DISPOSITIVO DE PROCESAMIENTO EN PARALELO DE INSTRUCCIONES DE PROGRAMA E INSTRUCCIONES DE TRAZA, del 24 de Enero de 2019, de UNIVERSIDAD POLITECNICA DE MADRID: Método y dispositivo de sincronización y ejecución paralela de instrucciones de traza sobre un procesador RISC segmentado. La invención consiste en un dispositivo cuya estructura […]