USO DE AGRUPAMIENTO SECUENCIAL PARA SELECCION DE INSTANCIAS EN MONITORIZACION DE ESTADOS DE MAQUINA.
Procedimiento para seleccionar un conjunto de datos de entrenamiento a partir de un conjunto S de muestras de un sistema de monitorización de estados de máquina,
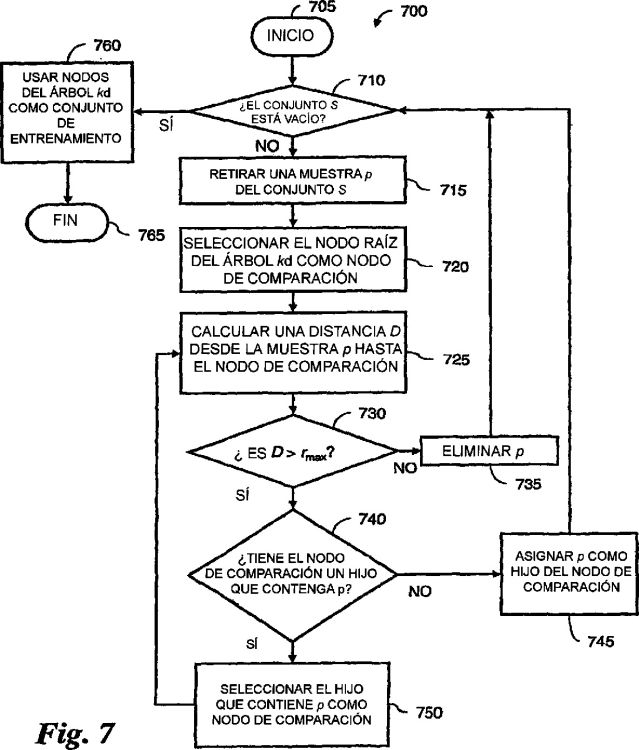
siendo el conjunto seleccionado de datos de entrenamiento para su uso en el entrenamiento de un modelo estadístico para evaluar mediciones en el sistema de monitorización de estados de máquina, comprendiendo el procedimiento las etapas de: realizar las siguientes etapas para cada muestra p del conjunto S: calcular una distancia desde la muestra p hasta un nodo de un árbol kd, en la que cada nodo del árbol kd está vacío o representa otra muestra retirada del conjunto S; si la distancia calculada es mayor que un umbral de distancia rmax, y el nodo del árbol kd tiene hijos, calcular una distancia desde la muestra p hasta un hijo del nodo seleccionado según una clasificación de p en el árbol kd; repetir la etapa anterior hasta que o bien la distancia calculada está por debajo del umbral de distancia rmax, o bien el nodo del árbol kd no tiene hijos; y si ninguna distancia calculada está por debajo del umbral de distancia rmax, entoncesllenar una hoja siguiente en el árbol kd con p; y usar los nodos del árbol kd como el conjunto de datos de entrenamiento
Tipo: Resumen de patente/invención. Número de Solicitud: W06046361US.
Solicitante: SIEMENS CORPORATION.
Nacionalidad solicitante: Estados Unidos de América.
Dirección: 170 WOOD AVENUE SOUTH,ISELIN, NJ 08830.
Inventor/es: NEUBAUER, CLAUS, BALDERER,CHRISTIAN, YUAN,CHAO.
Fecha de Publicación: .
Fecha Concesión Europea: 14 de Octubre de 2009.
Clasificación Internacional de Patentes:
- G05B17/02 FISICA. › G05 CONTROL; REGULACION. › G05B SISTEMAS DE CONTROL O DE REGULACION EN GENERAL; ELEMENTOS FUNCIONALES DE TALES SISTEMAS; DISPOSITIVOS DE MONITORIZACION O ENSAYOS DE TALES SISTEMAS O ELEMENTOS (dispositivos de maniobra por presión de fluido o sistemas que funcionan por medio de fluidos en general F15B; dispositivos obturadores en sí F16K; caracterizados por particularidades mecánicas solamente G05G; elementos sensibles, ver las subclases apropiadas, p. ej. G12B, las subclases de G01, H01; elementos de corrección, ver las subclases apropiadas, p. ej. H02K). › G05B 17/00 Sistemas que implican el uso de modelos o de simuladores de dichos sistemas (G05B 13/00, G05B 15/00, G05B 19/00 tienen prioridad; computadores analógicos para procedimientos, sistemas o dispositivos específicos, p. ej. simuladores, G06G 7/48). › eléctricos.
- G05B23/02 G05B […] › G05B 23/00 Ensayo o monitorización de sistemas de control o de sus elementos (monitorización de sistemas de control por programa G05B 19/048, G05B 19/406). › Ensayo o monitorización eléctrico.
Clasificación PCT:
Fragmento de la descripción:
Uso de agrupamiento secuencial para selección de instancias en monitorización de estados de máquina.
Referencia cruzada a solicitudes relacionadas
Esta solicitud reivindica el beneficio de la solicitud de patente provisional estadounidense número de serie 60/742.505 titulada "Use of Sequential Clustering for Instance Selection in Machine Condition Monitoring", ("Uso de agrupamiento secuencial para selección de instancias en monitorización de estados de máquina") presentada el 5 de diciembre de 2005.
Campo de la invención
La presente invención se refiere en general al campo de la monitorización de estados de máquina, y más en particular, a técnicas y sistemas para seleccionar instancias de entrenamiento representativas para su uso en el entrenamiento de un modelo estadístico para monitorización de estados de máquina.
El documento "Monitorización de estados con análisis de componentes independientes de campo medio" ("Condition monitoring with mean field independent components analysis") trata un procedimiento para seleccionar un conjunto de datos de entrenamiento a partir de un conjunto de muestras de un sistema de monitorización de estados de máquina.
Antecedentes de la invención
Muchas instalaciones de equipos de servicio y fabricación actuales incluyen, además de sistemas para controlar máquinas y procesos, sistemas para monitorización de estados de máquina. Los sistemas de monitorización de estados de máquina incluyen una disposición de sensores instalados en el equipo, una red de comunicaciones que enlaza esos sensores y un procesador conectado a la red para recibir señales desde los sensores y realizar determinaciones sobre estados de máquina a partir de esas señales.
El propósito de la monitorización de estados de máquina es detectar averías lo antes posible para evitar un daño adicional de las máquinas. Normalmente, se empleaban modelos físicos para describir la relación entre sensores que miden el rendimiento de una máquina. El incumplimiento de esas relaciones físicas podría indicar averías. Sin embargo, a menudo es difícil adquirir modelos físicos precisos.
Una alternativa al uso de modelos físicos es el uso de modelos estadísticos basándose en técnicas de aprendizaje asistido por ordenador. Ese enfoque ha adquirido un interés aumentado en las últimas décadas. A diferencia de un modelo físico, que supone relaciones de sensores conocidas, un modelo estadístico aprende las relaciones entre sensores a partir de datos históricos. Esa característica de los modelos estadísticos es una gran ventaja porque el mismo modelo genérico puede aplicarse a diferentes máquinas. Los modelos aprendidos difieren sólo en sus parámetros.
Hay dos tipos básicos de modelos estadísticos usados en monitorización de estados de máquina: un modelo basado en regresión y un modelo basado en clasificación. En un modelo de regresión, se usa un conjunto de sensores para predecir (o estimar) otro sensor. Puesto que un modelo de regresión puede producir una estimación continua, la desviación del valor real respecto a la estimación puede usarse directamente para el diagnóstico de averías. Por ejemplo, una lógica sencilla puede construirse como "cuanto mayor la desviación, mayor la posibilidad de una avería".
En un modelo basado en clasificación, la salida es discreta. Una aplicación de un modelo basado en clasificación es un detector fuera de intervalo, en el que a menudo se emplea un clasificador de una clase. Una salida de clasificador de una clase indica si hay un estado de fuera de intervalo o no.
Para poder usar modelos estadísticos para monitorización de estados de máquina, es necesario entrenar el modelo basándose en datos históricos etiquetados. En un modelo basado en clasificación, una etiqueta de punto de datos puede ser o bien "normal" (representando datos buenos) o bien "anómala" (representando datos que indican una avería).
Un enfoque de entrenamiento es incluir todos los datos disponibles en el conjunto de entrenamiento. La ventaja de un enfoque con todo incluido es que se espera que el modelo estadístico entrenado generalice bien, porque los datos de entrenamiento cubren la mayor parte de las variaciones que pueden producirse en el futuro. Sin embargo, en ese enfoque existen dos problemas. En primer lugar, puede haber demasiados datos de entrenamiento, haciendo que el proceso de entrenamiento requiera mucho tiempo o que incluso sea incontrolable. En segundo lugar, muchos de los datos pueden ser muy similares. No es necesario usar muestras de entrenamiento similares. Además, los datos similares pueden provocar un sobreentrenamiento si, durante el periodo de entrenamiento seleccionado, resulta que la máquina está funcionando en el mismo modo durante la mayor parte del tiempo. Un submuestreo sencillo puede solucionar el primero de los problemas anteriores, pero no el segundo. El submuestreo puede provocar también una pérdida de puntos de datos útiles. Un operario humano puede seleccionar manualmente instancias de entrenamiento; sin embargo, un proceso de este tipo es tedioso y también incontrolable si en un modelo están presentes múltiples sensores.
Por tanto existe una necesidad de un procedimiento mejorado para seleccionar datos de entrenamiento. Un procedimiento mejorado de este tipo encontraría instancias de entrenamiento representativas y al mismo tiempo reduciría la redundancia de datos.
Un enfoque puede ser usar técnicas de agrupamiento convencionales para agrupar los datos de entrenamiento, y a continuación usar cada centro de grupo como una instancia seleccionada. Los dos algoritmos de agrupamiento usados con mayor frecuencia son el algoritmo de k-medias y el algoritmo de agrupamiento ISODATA. Ambos algoritmos son procedimientos iterativos. Para el algoritmo de k-medias en un inicio se seleccionan aleatoriamente k centros de grupo. Cada muestra de entrenamiento se asigna al grupo más próximo basándose en la distancia desde la muestra hasta el centro de grupo. Entonces se actualizan todos los centros de grupo basándose en las asignaciones nuevas. El proceso se repite hasta que converge.
El algoritmo ISODATA está más avanzado porque puede dividir y fusionar grupos. Un grupo se fusiona con otro grupo si el grupo es demasiado pequeño o muy próximo a otro grupo. Un grupo se divide si es demasiado grande o su desviación estándar supera un valor predefinido.
Sin embargo, ningún algoritmo es apropiado para su uso en la selección de datos de entrenamiento en la presente solicitud, por al menos dos razones. En primer lugar, tanto los algoritmos ISODATA como los de k-medias crean un punto de datos virtual, mientras que la presente solicitud requiere seleccionar un punto de datos real. En segundo lugar, ambos procedimientos de agrupamiento carecen de un control preciso del tamaño geométrico de cada grupo. Por ejemplo, la técnica puede producir una serie de grupos grandes. El centro de un grupo grande no es representativo de todos sus elementos, porque la distancia entre los elementos es demasiado grande.
Por tanto, actualmente existe la necesidad de un procedimiento para seleccionar datos de entrenamiento a partir de un conjunto de datos amplio. Ese procedimiento debería limitar el número de muestras de entrenamiento, mientras que garantiza que las muestras seleccionadas son representativas de los datos.
Sumario de la invención
La presente invención trata las necesidades descritas anteriormente proporcionando un procedimiento para seleccionar un conjunto de datos de entrenamiento a partir de un conjunto S de muestras de un sistema de monitorización de estados de máquina. El conjunto seleccionado de datos de entrenamiento es para su uso en el entrenamiento de un modelo estadístico para evaluar mediciones en el sistema de monitorización de estados de máquina.
Inicialmente el procedimiento realiza las siguientes etapas para cada muestra p del conjunto S: calcular una distancia desde la muestra p hasta un nodo de un árbol kd, en la que cada nodo del árbol kd está vacío o representa otra muestra retirada del conjunto S; si la distancia calculada es mayor que un umbral de distancia rmax, y el nodo del árbol kd tiene hijos, calcular una distancia desde la muestra p hasta un hijo del nodo seleccionado según una clasificación de p en el árbol kd; repetir la etapa anterior hasta que o bien la distancia calculada está por debajo del umbral de distancia rmax,...
Reivindicaciones:
1. Procedimiento para seleccionar un conjunto de datos de entrenamiento a partir de un conjunto S de muestras de un sistema de monitorización de estados de máquina, siendo el conjunto seleccionado de datos de entrenamiento para su uso en el entrenamiento de un modelo estadístico para evaluar mediciones en el sistema de monitorización de estados de máquina, comprendiendo el procedimiento las etapas de:
realizar las siguientes etapas para cada muestra p del conjunto S:
usar los nodos del árbol kd como el conjunto de datos de entrenamiento.
2. Procedimiento según la reivindicación 1, que comprende además la etapa de:
aleatorizar un orden de las muestras p en el conjunto de entrenamiento S.
3. Procedimiento según la reivindicación 1, en el que la distancia rmax se determina como
donde r0 es una constante predeterminada y d es un número de sensores representados por la muestra s.
4. Procedimiento según la reivindicación 3, en el que r0 se ajusta a 1/33.
5. Procedimiento según la reivindicación 1, la etapa de realizar las etapas para cada muestra p del conjunto S comprende además:
retroceder en el árbol kd si un centro de grupo más próximo para una muestra p no está ubicado en un hipercubo del árbol kd especificado por el centro de grupo.
6. Procedimiento para entrenar un modelo estadístico para evaluar mediciones en un sistema de monitorización de estados de máquina, usando un conjunto S de muestras de datos del sistema de monitorización de estados de máquina, comprendiendo el procedimiento las etapas de:
agrupar las muestras en S en una pluralidad de grupos comparando cada muestra p con un subconjunto de las demás muestras de S, seleccionándose el subconjunto de las demás muestras de S usando un árbol kd que tiene nodos correspondientes a muestras de datos de S; y
entrenar el modelo estadístico usando un valor único a partir de cada grupo de la pluralidad de grupos.
7. Procedimiento según la reivindicación 6, en el que el valor único es una muestra de datos a partir del grupo.
8. Procedimiento según la reivindicación 6, en el que la etapa de agrupar las muestras en S en una pluralidad de grupos comprende además la etapa de:
eliminar las muestras de datos que se encuentra que pertenecen a un grupo que ya tiene un elemento, por lo que cada grupo tiene un elemento.
9. Procedimiento según la reivindicación 6, que comprende además la etapa de:
aleatorizar un orden de las muestras de datos en el conjunto de entrenamiento S.
10. Procedimiento según la reivindicación 6, en el que la etapa de agrupar las muestras en S en una pluralidad de grupos comprende además la etapa de:
calcular una distancia desde cada muestra p hasta cada elemento del subconjunto de las demás muestras de S; y
comparar cada distancia con un umbral de distancia rmax.
11. Procedimiento según la reivindicación 10, en el que la distancia rmax se determina como
donde r0 es una constante predeterminada y d es un número de sensores representados por la muestra s.
12. Procedimiento según la reivindicación 11, en el que r0 se ajusta a 1/33.
13. Medio que puede utilizarse en un ordenador que tiene instrucciones legibles por ordenador almacenadas en el mismo para la ejecución por un procesador para realizar un procedimiento para seleccionar un conjunto de datos de entrenamiento a partir de un conjunto S de muestras de un sistema de monitorización de estados de máquina, siendo el conjunto seleccionado de datos de entrenamiento para su uso en el entrenamiento de un modelo estadístico para evaluar mediciones en el sistema de monitorización de estados de máquina, comprendiendo el procedimiento las etapas de:
realizar las siguientes etapas para cada muestra p del conjunto S:
usar los nodos del árbol kd como el conjunto de datos de entrenamiento.
14. Medio que puede utilizarse en un ordenador según la reivindicación 13, que comprende además la etapa de:
aleatorizar un orden de las muestras p en el conjunto de entrenamiento S.
15. Medio que puede utilizarse en un ordenador según la reivindicación 13, en el que la distancia rmax se determina como
donde r0 es una constante predeterminada y d es un número de sensores representados por la muestra s.
16. Medio que puede utilizarse en un ordenador según la reivindicación 15, en el que r0 se ajusta a 1/33.
17. Medio que puede utilizarse en un ordenador según la reivindicación 13, la etapa de realizar las siguientes etapas para cada muestra p del conjunto S comprende además:
retroceder en el árbol kd si un centro de grupo más próximo para una muestra p no está ubicado en un hipercubo del árbol kd especificado por el centro de grupo.
Patentes similares o relacionadas:
Sistemas y métodos para la predicción rápida del agrietamiento inducido por hidrógeno (HIC) en tuberías, recipientes de presión y sistemas de tuberías, y para tomar medidas en relación con el mismo, del 13 de Mayo de 2020, de SAUDI ARABIAN OIL COMPANY: Un metodo para llevar a cabo evaluaciones de idoneidad para el servicio para una region de un activo que tiene una tasa de crecimiento de dano inducido por hidrogeno, el […]
Método y sistema para proporcionar resultados de analítica de datos, del 8 de Enero de 2020, de SIEMENS AKTIENGESELLSCHAFT: Método para proporcionar resultados de analítica de datos para un procedimiento realizado en una planta industrial, comprendiendo dicho método: (a) proporcionar […]
Procedimiento combinado para detectar anomalías en un sistema de distribución de agua, del 8 de Enero de 2020, de SUEZ Groupe: Un procedimiento para detectar anomalías en un sistema de distribución de agua compuesto por una red de nodos, comprendiendo dicho […]
Desarrollo de un modelo superior para el control y/o monitorización de una instalación de compresor, del 25 de Diciembre de 2019, de KAESER KOMPRESSOREN SE: Procedimiento para el control y/o monitorización de una instalación de compresor que comprende uno o varios compresores y uno o varios dispositivos periféricos […]
Desarrollo de un modelo superior, del 25 de Diciembre de 2019, de KAESER KOMPRESSOREN SE: Procedimiento para el control y/o monitorización de una instalación de compresor que comprende uno o varios compresores y uno o varios dispositivos […]
Entrada de diagrama de tuberías e instrumentación para un proceso de control y/o supervisión de un sistema de compresor, del 6 de Noviembre de 2019, de KAESER KOMPRESSOREN SE: Procedimiento para el control y/o supervisión de una instalación de compresores que comprende uno o varios compresores y uno o varios […]
Procedimiento para la resolución de una tarea de control en una instalación de proceso, del 16 de Octubre de 2019, de Z & J Technologies GmbH: Procedimiento para la resolución de una tarea de control en una instalación de proceso, en particular para el paso de la instalación de proceso de un estado […]
Sistema de monitorización, del 12 de Junio de 2019, de BAE SYSTEMS PLC: Un método implementado por ordenador para diseñar un sistema de gestión de la salud para la monitorización del estado de una plataforma, […]