PROCEDIMIENTO PARA GENERAR UN FICHERO DELTA OPTIMIZADO EN TAMAÑO.
Procedimiento para generar un fichero delta que codifica la diferencia entre un primer fichero de datos y un segundo fichero de datos,
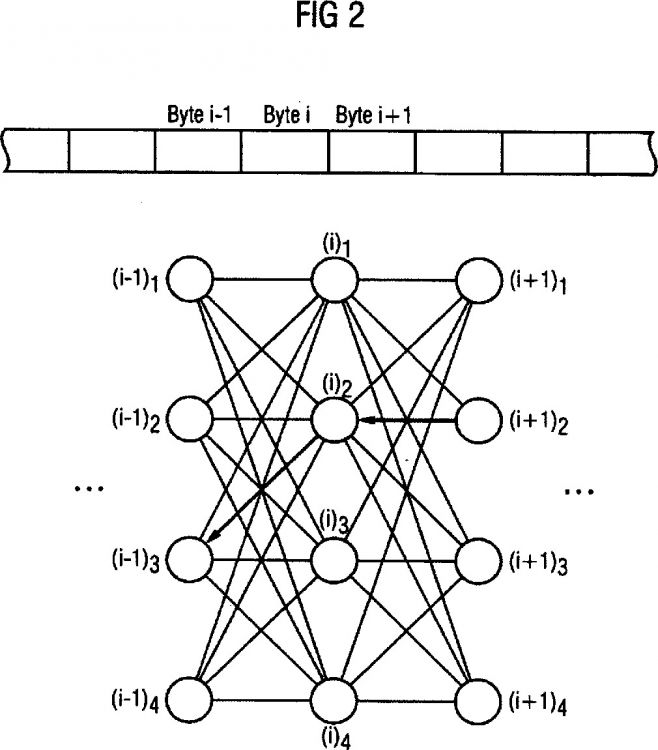
determinándose en este procedimiento un conjunto de cadenas parciales de datos existentes en ambos ficheros de datos que coinciden parcialmente ("pseudomatches") y modelándose un gráfico en el que cada nodo de red representa una etapa de procesamiento de datos basada en el primer fichero de datos para generar un byte de datos del segundo fichero de datos, uniéndose en el gráfico mediante líneas de red cada nodo de red asociado a un byte de datos del segundo fichero de datos con todos los nodos de red asociados a un byte de datos inmediatamente precedente del segundo fichero de datos y asignándose a los nodos de red y líneas de red en cada caso un valor de coste, calculándose en el procedimiento una ruta optimizada en costes en el gráfico que contiene para todos los bytes de datos del segundo fichero de datos sólo un nodo de red por cada byte de datos, y generándose en base a la ruta optimizada en costes un fichero delta que contiene una secuencia de etapas de procesamiento de datos y sus campos de datos correspondiente a la sucesión de nodos de red en la ruta optimizada en costes
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/EP2007/058775.
Solicitante: SIEMENS AKTIENGESELLSCHAFT.
Nacionalidad solicitante: Alemania.
Dirección: WITTELSBACHERPLATZ 2,80333 MUNCHEN.
Inventor/es: LAUTHER, ULRICH.
Fecha de Publicación: .
Fecha Concesión Europea: 13 de Enero de 2010.
Clasificación Internacional de Patentes:
- G06F9/44G4C
- H03M7/30 ELECTRICIDAD. › H03 CIRCUITOS ELECTRONICOS BASICOS. › H03M CODIFICACION, DECODIFICACION O CONVERSION DE CODIGO, EN GENERAL (por medio de fluidos F15C 4/00; convertidores ópticos analógico/digitales G02F 7/00; codificación, decodificación o conversión de código especialmente adaptada a aplicaciones particulares, ver las subclases apropiadas, p. ej. G01D, G01R, G06F, G06T, G09G, G10L, G11B, G11C, H04B, H04L, H04M, H04N; cifrado o descifrado para la criptografía o para otros fines que implican la necesidad de secreto G09C). › H03M 7/00 Conversión de un código, en el cual la información está representada por una secuencia dada o por un número de dígitos, en un código en el cual la misma información está representada por una secuencia o por un número de dígitos diferentes. › Compresión (análisis-síntesis de la voz para reducción de redundancia G10L 19/00; para transmisión de imágenes H04N ); Expansión; Supresión de datos innecesarios, p. ej. reducción de redundancia.
Clasificación PCT:
- G06F9/44 FISICA. › G06 CALCULO; CONTEO. › G06F PROCESAMIENTO ELECTRICO DE DATOS DIGITALES (sistemas de computadores basados en modelos de cálculo específicos G06N). › G06F 9/00 Disposiciones para el control por programa, p. ej. unidades de control (control por programa para dispositivos periféricos G06F 13/10). › Disposiciones para ejecutar programas específicos.
Fragmento de la descripción:
Procedimiento para generar un fichero delta optimizado en tamaño.
Hoy en día es necesario a menudo modificar software o datos de servicio para realizar una aplicación o para operar aparatos, como por ejemplo aparatos de telefonía móvil o equipos automáticos de detección de peajes conducidos en vehículos, para de esta manera por ejemplo eliminar faltas e implementar funciones mejoradas o adicionales ("software-upgrade" o modernización de software, o "software-update" o actualización de software).
En particular para el caso de que la versión actual del software o datos de servicio tengan que transmitirse a través de una interfaz con una transmisión de datos comparativamente lenta y/o cara (por ejemplo una interfaz de aire en telefonía móvil), es razonable en determinadas circunstancias no transmitir el bloque de datos completo, sino elegir otra forma de proceder en la que solamente se transmita la "diferencia" entre la versión más antigua y la versión más moderna y a continuación, con la ayuda de la diferencia transmitida, generar la versión más moderna a partir de la versión más antigua ya existente.
Para este fin se conoce por ejemplo por la patente US núm. 6,401,239 la generación de un fichero delta (Delta-File) mediante un generador de ficheros delta de un primer ordenador (servidor). El fichero delta, que codifica la diferencia entre la primera versión y la segunda versión de un fichero de datos, se transmite a un segundo ordenador (cliente), en el que está memorizada la primera versión del fichero de datos, generándose mediante un equipo de reconstrucción la segunda versión del fichero de datos a partir de su primera versión y del fichero delta.
Un problema central es entonces la generación de un fichero delta de un tamaño lo menor posible, para así minimizar el tiempo de transmisión necesario para la transmisión del fichero delta o bien los costes de transmisión que entonces se originan.
La generación de un fichero delta se describe por ejemplo en Walter F. Tichy, "The String-to-String Correction Problem with Block Moves" (El problema de la corrección cadena-a-cadena con movimiento de bloques), ACM Trans. on Computer Systems, vol. 2, núm. 4, nov. 1984, páginas 309-321.
El documento US 2006/0107260 A1 da a conocer un procedimiento para generar un fichero delta que codifica la diferencia entre un primer fichero de datos y un segundo fichero de datos, determinándose en este procedimiento un conjunto de cadenas parciales de datos existentes en ambos ficheros de datos que coinciden parcialmente y modelándose un gráfico en el que cada nodo de red representa una etapa de procesamiento de datos basada en el primer fichero de datos, en cuyo procedimiento se genera un fichero delta que contiene una sucesión de etapas de procesamiento de datos y sus campos de datos.
Para aclarar el procedimiento allí descrito, refirámonos a la figura 1. Según la misma, se incluyen dos ficheros de datos distintos, uno de los cuales (por ejemplo una versión más moderna de un fichero de datos) ha de generarse a partir del otro (por ejemplo una versión más antigua del fichero de datos) mediante un fichero delta, como dos cadenas de datos, denominadas S0 y S1. Para generar un fichero delta, se busca primeramente un conjunto de "matches" (coincidencias) máximo (exacto) que no se solapen, es decir, cadenas parciales de datos con idénticos caracteres y la longitud máxima, que están presentes tanto en S0 como también en S1, aún cuando en distintas posiciones de la correspondiente cadena de datos.
El resultado es una secuencia de coincidencias (matches) y huecos, que a modo de ejemplo se representa en la figura 1 para S1 (en la figura 1 arriba) y para S0 (en la figura 1 abajo). Mediante ambas flechas dibujadas en la figura 1, se designan como ejemplo dos cadenas parciales de datos exactamente coincidentes.
A continuación, en base a las cadenas parciales de datos encontradas que coinciden exactamente, se genera un fichero delta, compuesto por una secuencia de etapas de procesamiento de datos (operaciones u órdenes) a ejecutar sucesivamente en el primer fichero de datos S0, aquí operaciones COPY (copiar) y ADD (añadir), resultando una operación COPY de las zonas de datos que coinciden exactamente en cada caso y una operación ADD en cada caso de los huecos que se encuentran entre las zonas de datos que coinciden exactamente.
Una orden COPY, que en el ejemplo representado típicamente tiene la sintaxis "COPY <longitud> <Offset en S0> <Offset en S1>", provoca el copiado de una zona de datos que coincide exactamente, que se encuentra en la cadena de datos S0 en la posición <Offset en S0> y que tiene la longitud <longitud> tras S1, y precisamente en la posición <Offset en S1>. Por otro lado, provoca una orden ADD, que típicamente presenta la sintaxis "ADD <longitud> <datos de S1>" que se añadan datos de la longitud <longitud>, que deben arrastrarse en el fichero delta, en los huecos entre las zonas de datos que coinciden exactamente en S1. De esta manera puede generarse el segundo fichero de datos S1 mediante "procesamiento" de la secuencia de sucesivas operaciones COPY y ADD a partir del primer fichero de datos.
En el procedimiento representado se determina a partir del tamaño de las zonas de datos que coinciden exactamente el tamaño del fichero delta, reduciendo mayores coincidencias el volumen de los datos a transportar en el fichero delta. El cálculo de una cobertura con la máxima coincidencia puede realizarse hoy día de una manera muy eficiente con ayuda de modernas estructuras de datos, tal como las que se conocen por ejemplo por la bioinformática para el cálculo de cadenas ADN muy largas. El fichero delta generado se comprime antes de una transmisión típicamente y se descomprime antes del proceso de actualización (update) o modernización (upgrade).
El procedimiento mostrado tiene el inconveniente de que en determinadas circunstancias han de estar incluidas en el fichero delta muchas etapas de procesamiento de datos a procesar sucesivamente, para generar un segundo fichero de datos a partir de un primer fichero de datos.
Este inconveniente puede eliminarse si en lugar de con zonas parciales de datos que coinciden exactamente en ambos ficheros de datos se trabaja con zonas de datos sólo aproximadamente iguales o bien ligeramente distintas entre sí, las llamadas "pseudos-matches" ("pseudoiguales").
En este caso se memoriza en un fichero delta para cada pseudomatch byte a byte la diferencia de las zonas parciales de datos poco diferentes, siendo cero los bytes-diferencia que resultan de los datos que coinciden exactamente de un pseudomatch, mientras que los bytes-diferencia que resultan de los datos diferentes entre sí de un pseudomatch, en general son distintos de cero. La diferencia para un pseudoigual está compuesta en gran medida por ceros (bytes cero) y puede por ello comprimirse fuertemente.
En base a las cadenas parciales de datos pseudoiguales, se genera a continuación de ello un fichero delta, compuesto por una secuencia de etapas de procesamiento de datos a ejecutar sucesivamente en el primer fichero de datos, a saber, operaciones DIFF y ADD, resultando una operación DIFF en cada caso de las zonas de datos que coinciden aproximadamente y una orden ADD en cada caso de los huecos que se encuentran entre las mismas.
Una orden DIFF provoca mediante adición byte a byte de sus bytes a los correspondientes valores del primer fichero de datos, cuando existe un byte cero en la diferencia, un copiado de datos del primer fichero de datos (desde la posición correspondiente al byte cero del primer fichero de datos a la correspondiente posición del segundo fichero de datos) y cuando existe un byte no-cero, un copiado de la suma del byte del primer fichero de datos y de los datos de la orden DIFF en la correspondiente posición en el segundo fichero de datos.
En comparación con ficheros delta que se basan en zonas de datos exactamente coincidentes (matches), puede reducirse claramente, utilizando zonas de datos sólo aproximadamente coincidentes (pseudoiguales), la cantidad de pseudoiguales (pseudomatches) y con ello la cantidad de operaciones de procesamiento de datos a transmitir en el fichero delta.
La utilización de pseudoiguales puede tomarse del código de programa de la herramienta de software "bsdiff" de libre disponibilidad, que no obstante no está más documentada.
Básicamente, cuando se utilizan pseudoiguales ha de encontrarse un trade-off (compromiso) entre pocos pseudoiguales largos...
Reivindicaciones:
1. Procedimiento para generar un fichero delta que codifica la diferencia entre un primer fichero de datos y un segundo fichero de datos, determinándose en este procedimiento un conjunto de cadenas parciales de datos existentes en ambos ficheros de datos que coinciden parcialmente ("pseudomatches") y modelándose un gráfico en el que cada nodo de red representa una etapa de procesamiento de datos basada en el primer fichero de datos para generar un byte de datos del segundo fichero de datos, uniéndose en el gráfico mediante líneas de red cada nodo de red asociado a un byte de datos del segundo fichero de datos con todos los nodos de red asociados a un byte de datos inmediatamente precedente del segundo fichero de datos y asignándose a los nodos de red y líneas de red en cada caso un valor de coste, calculándose en el procedimiento una ruta optimizada en costes en el gráfico que contiene para todos los bytes de datos del segundo fichero de datos sólo un nodo de red por cada byte de datos, y generándose en base a la ruta optimizada en costes un fichero delta que contiene una secuencia de etapas de procesamiento de datos y sus campos de datos correspondiente a la sucesión de nodos de red en la ruta optimizada en costes.
2. Procedimiento según la reivindicación 1, en el que las etapas de procesamiento de datos basadas en el primer fichero de datos para generar un byte de datos del segundo fichero de datos, están referidas en cada caso a un pseudomatch.
3. Procedimiento según la reivindicación 2, en el que las etapas de procesamiento de datos basadas en el primer fichero de datos para generar un byte de datos del segundo fichero de datos incluyen operaciones ADD y operaciones DIFF, provocándose mediante una operación ADD la lectura de un campo de datos del fichero delta asociado a esta operación ADD y su memorización en una posición del segundo fichero de datos que corresponde a la posición del byte de datos asociado a la operación ADD, y en el que mediante una operación DIFF referida a un pseudomatch se provoca la memorización de un byte de datos-suma, sumado a partir de un campo de datos de la operación DIFF y el correspondiente byte de datos del pseudomatch del primer fichero de datos, en una posición del segundo fichero de datos que corresponde a la posición del byte de datos asociado a la operación DIFF.
4. Procedimiento según una de las reivindicaciones 1 a 3, en el que se modela un gráfico con forma de matriz que incluye filas y columnas, asociándose las sucesivas columnas del gráfico a los sucesivos bytes de datos del segundo fichero de datos.
5. Procedimiento según una de las reivindicaciones 1 a 4, en el que a cada nodo de red se le asigna un valor de coste, que es distinto de cero cuando el estado asociado al nodo de red genera un byte de datos distinto de cero en el fichero delta y que es cero cuando el estado
6. Procedimiento según una de las reivindicaciones 1 a 5, en el que a cada línea de red se le asigna un valor de coste, que es cero cuando los nodos de red unidos mediante una línea de red pertenecen a pseudomatches iguales o compatibles, y que es distinto de cero cuando los nodos de red unidos mediante una línea de red pertenecen a distintos pseudomatches.
7. Procedimiento según una de las reivindicaciones 1 a 6, en el que la generación de los pseudomatches incluye las siguientes etapas:
8. Procedimiento según una de las reivindicaciones 1 a 7, en el que se realiza una reducción de pseudomatches en base a una comparación de los costes que se presentan cuando se utiliza o se ignora un match dentro del hueco de un pseudomatch.
9. Procedimiento según una de las reivindicaciones 1 a 8, en el que de entre los pseudomatches se elige un conjunto de pseudomatches que no se solapan, que maximiza la cobertura del segundo fichero de datos con matches exactos.
10. Procedimiento según una de las reivindicaciones 1 a 9, en el que se comprime el fichero delta.
11. Código de programa legible por máquina para un equipo electrónico de procesamiento de datos, que contiene órdenes de control que dan lugar a que el equipo electrónico de procesamiento de datos realice un procedimiento según una de las reivindicaciones 1 a 10.
12. Medio de memoria con un código de programa legible por máquina memorizado en el mismo según la reivindicación 11.
Patentes similares o relacionadas:
Método de codificación de impulsos de las señales de excitación, del 29 de Julio de 2020, de HUAWEI TECHNOLOGIES CO., LTD.: Un método para codificar una señal de voz, que comprende: la obtención de la distribución de impulsos de la señal de voz, en una pista, de los impulsos a codificarse […]
Almacenamiento eficiente de registros de códigos cifrados estructurados múltiples, del 22 de Julio de 2020, de Nokia Technologies OY: Un aparato que comprende: medios para formar un vector de código base combinando componentes 5 de vector de un sub-vector señalado por […]
Codificación de las posiciones de los picos espectrales, del 27 de Mayo de 2020, de TELEFONAKTIEBOLAGET LM ERICSSON (PUBL): Un método de codificación de las posiciones de los picos espectrales de un segmento de una señal de audio, comprendiendo el método: - determinar cuál […]
Método de transición de estado y aparato basado en ROHC y medio de almacenamiento, del 8 de Abril de 2020, de ZTE CORPORATION: Un método de transición de estado, que se aplica en una máquina de estado de un compresor, en donde la compresión es para la compresión de cabecera en comunicación inalámbrica […]
 Filtro de desbloqueo condicionado por el brillo de los píxeles, del 25 de Marzo de 2020, de DOLBY INTERNATIONAL AB: Método para desbloquear datos de píxeles procesados con compresión de vídeo digital basado en bloque, incluyendo los pasos:
- recibir […]
Filtro de desbloqueo condicionado por el brillo de los píxeles, del 25 de Marzo de 2020, de DOLBY INTERNATIONAL AB: Método para desbloquear datos de píxeles procesados con compresión de vídeo digital basado en bloque, incluyendo los pasos:
- recibir […]
Búsqueda de forma de cuantificador de vector en pirámide, del 22 de Enero de 2020, de TELEFONAKTIEBOLAGET LM ERICSSON (PUBL): Un método para búsqueda de forma de Cuantificador de Vector en Pirámide, PVQ, realizada por un procesador de señal digital, tomando el PVQ […]
Métodos y dispositivos para la segmentación de vectores para codificación, del 15 de Enero de 2020, de TELEFONAKTIEBOLAGET LM ERICSSON (PUBL): Un método de codificación de audio que comprende la partición de vectores de entrada de coeficientes que se originan a partir de la señal de audio […]
Método de procesamiento de señal de voz/audio y aparato de codificación, del 8 de Enero de 2020, de HUAWEI TECHNOLOGIES CO., LTD.: Un método de procesamiento de señal de voz/audio, que comprende: si una primera señal de voz/audio de banda ancha es una señal armónica, ajustar una condición determinante […]