PROCEDIMIENTO DE CUANTIFICACION DE UN CODIFICADOR DE PALABRA DE FLUJO MUY BAJO.
Procedimiento de codificado y de decodificado de la palabra para las comunicaciones por voz que utilizan un codificador de voz de flujo muy bajo,
600 bitios por segundo, que comprende una parte de análisis para el codificado y la transmisión de los parámetros de la señal de palabra, tales como la información de sonorización por sub-banda, el paso, las ganancias, los parámetros espectrales LSF y una parte de síntesis para la recepción y el decodificado de los parámetros transmitidos y la reconstrucción de la señal de palabra caracterizado porque comprende al menos las etapas siguientes:
reagrupar los parámetros de sonorización, paso, ganancias, coeficientes LSF en N tramas consecutivas para formar una super-trama, con N = 4,
realizar una cuantificación vectorial de la información de sonorización para cada super-trama elaborando una clasificación que utiliza las informaciones sobre el encadenamiento en términos de sonorización existente en 2, tramas elementales consecutivas, la información de sonorización permite en efecto identificar clases de sonidos para los cuales la asignación del flujo y los diccionarios asociados se optimiza- rán,
las clases se encuentran en número de 6 y se definen de la forma siguiente:
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/EP2005/051661.
Solicitante: THALES.
Nacionalidad solicitante: Francia.
Dirección: 45 RUE DE VILLIERS,92200 NEUILLY SUR SEINE.
Inventor/es: CAPMAN, FRANCOIS.
Fecha de Publicación: .
Fecha Concesión Europea: 30 de Diciembre de 2009.
Clasificación Internacional de Patentes:
- G10L19/08M
Clasificación PCT:
- G10L19/08 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › G10L 19/00 Técnicas de análisis-síntesis de la voz o de señales de audio para la reducción de la redundancia, p. ej. en codificadores vocales; Codificación o decodificación de la voz o de señales de audio, utilizando modelos filtro-fuente o el análisis psicoacústico (en instrumentos musicales G10H). › Determinación o codificación de la función de excitación; Determinación de los parámetros de predicción a largo plazo.
Clasificación antigua:
- G10L19/08 G10L 19/00 […] › Determinación o codificación de la función de excitación; Determinación de los parámetros de predicción a largo plazo.
Fragmento de la descripción:
Procedimiento de cuantificación de un codificador de palabra de flujo muy bajo.
La invención se refiere a un procedimiento de codificado de la palabra. La misma se aplica particularmente en la realización de codificadores de voz de cadencia muy baja, del orden de los 600 bitios por segundo.
La invención se utiliza por ejemplo para el codificador MELP, (codificador de excitación mixta en anglosajón Mixed Excitation Linear Prediction) descrito por ejemplo en una de las referencias [1, 2, 3, 4].
El procedimiento es por ejemplo utilizado en las comunicaciones por satélite, la telefonía en Internet, los respondedores estáticos, los paginadores con voz, etc.
El objetivo de estos codificadores de voz es reconstruir una señal que sea lo más parecida posible, al sentido de la percepción por el oído humano, de la señal de palabra original, utilizando un flujo binario lo más bajo posi- ble.
Para conseguir este objetivo, la mayoría de los codificadores de voz utilizan un modelo totalmente parametrado de la señal de palabra. Los parámetros utilizados se refieren a: la sonorización que describe el carácter armónico de los sonidos con voz o el carácter estocástico de los sonidos sin voz, la frecuencia fundamental de los sonidos con voz también conocida bajo el vocablo anglosajón "PITCH", la evolución temporal de la energía así como la envoltura espectral de la señal para excitar y parametrar los filtros de síntesis.
En el caso del codificador MELP, los parámetros espectrales utilizados son los coeficientes LSF (en anglosajón Line Spectral Frequencies) derivados de un análisis por predicción lineal, LPC codificado predictivo lineal (en anglosajón Linear Predictive Coding). El análisis se realiza para un flujo clásico de 2400 bitios/seg cada 22.5 ms.
Las informaciones suplementarias extraídas en la modelización son:
El documento de ULPU SINERVO et al. describe un método que permite cuantificar los coeficientes espectrales. En el método propuesto, un cuantificador de matriz de tramas múltiples se utiliza para explotar la correlación entre los parámetros LSF de las tramas adyacentes.
El documento de STACHURSKI se refiere a una técnica de codificado para flujos de alrededor de 4 kbitios/s. La técnica de codificado utiliza un modelo MELP en el cual los coeficientes complejos se utilizan en la síntesis de la palabra. En este documento se analiza la importancia de los parámetros.
El objeto de la presente invención es, particularmente, ampliar el modelo MELP al flujo de 600bitios/seg. Los parámetros retenidos son por ejemplo, el paso, los coeficientes espectrales LSF, las ganancias y la sonorización. Las tramas se reagrupan por ejemplo en una super trama de 90 ms, es decir 4 tramas consecutivas de 22.5 ms del esquema inicial (esquema habitualmente utilizado).
Un flujo de 600 bitios/seg se obtiene a partir de una optimización del esquema de cuantificación de los diferentes parámetros (paso, coeficiente LSF, ganancia, sonorización).
La invención como se ha definido en la reivindicación 1, se refiere a un procedimiento de codificado y decodificado de la palabra para las comunicaciones con voz que utilizan un codificador de voz de flujo muy bajo, 600 bitios por segundo, que comprende una parte de análisis para el codificado y la transmisión de los parámetros de la señal de palabra, tales como la información de sonorización por sub-banda, el paso, las ganancias, los parámetros espectrales LSF y una parte de síntesis para la recepción y el decodificado de los parámetros transmitidos y la reconstrucción de la señal de palabra. Se caracteriza porque comprende al menos las etapas siguientes:
La clasificación es por ejemplo elaborada utilizando las informaciones sobre el encadenamiento en términos de sonorización existente en 2 tramas elementales consecutivas.
El procedimiento según la invención permite ventajosamente ofrecer un codificado fiable para flujos bajos.
Otras características y ventajas de la presente invención aparecerán mejor con la lectura de la descripción de un ejemplo de realización dado a título ilustrativo, anexado con figuras que representan:
El ejemplo detallado dado a continuación, a título ilustrativo y en modo alguno limitativo, se refiere a un codificador MELP adaptado al flujo de 600 bitios/seg.
El procedimiento según la invención se refiere particularmente al codificado de los parámetros que permiten reproducir lo mejor posible con un mínimo de flujo toda la complejidad de la señal de palabra. Los parámetros retenidos son por ejemplo: el paso, los coeficientes espectrales LSF, las ganancias y la sonorización. El procedimiento recurre particularmente a un procedimiento de cuantificación vectorial con clasificación.
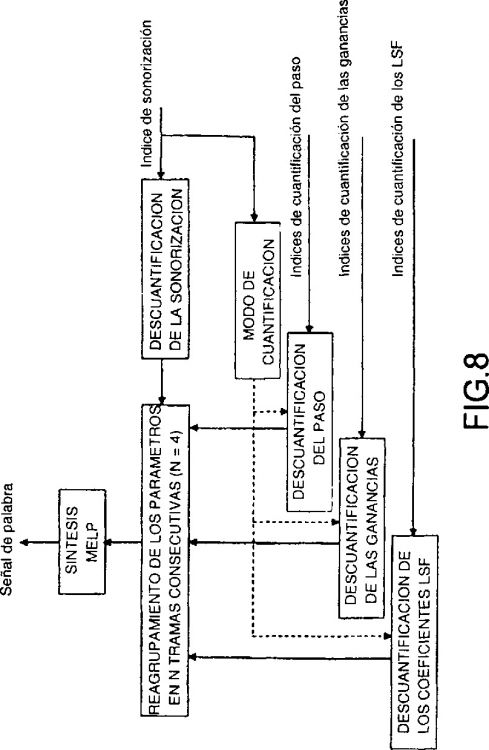
La figura 1 esquematiza globalmente las diferentes realizaciones a nivel de un codificador de la palabra. El procedimiento según la invención se desarrolla en 7 etapas principales.
Etapa de análisis de la señal de palabra
La etapa 1 analiza la señal por medio de un algoritmo de tipo MELP conocido por el experto en la materia. En el modelo MELP, una decisión de sonorización es tomada para cada trama de 22.5 ms y para 5 sub-bandas de frecuencias predefinidas.
Etapa de reagrupamiento de los parámetros
Para la etapa 2, el procedimiento reagrupa los parámetros seleccionados: sonorización, paso, ganancias y coeficientes LSF en N tramas consecutivas de 22.5 ms para formar una supertrama de 90 ms. El valor N=4 es elegido por ejemplo para formar un compromiso entre la reducción posible del flujo binario y el retardo introducido por el procedimiento de
Etapa de cuantificación de la información de sonorización - detallada en la figura 2
En la horizontal de una supertrama, la información de sonorización se representa por consiguiente por una matriz de componentes binarios (0: sin voz; 1: con voz) de tamaño (5*4), 5 sub-bandas MELP, 4 tramas.
El procedimiento utiliza un procedimiento de cuantificación vectorial sobre n bitios, con por ejemplo n=5. La distancia utilizada es una distancia euclidiana ponderada con el fin de favorecer las bandas situadas en bajas frecuencias. Se utiliza por ejemplo como vector de ponderación [1.0; 1.0; 0.7; 0.4; 0.1].
La información de sonorización cuantificada permite identificar clases de sonidos para los cuales la asignación del flujo y los diccionarios...
Reivindicaciones:
1. Procedimiento de codificado y de decodificado de la palabra para las comunicaciones por voz que utilizan un codificador de voz de flujo muy bajo, 600 bitios por segundo, que comprende una parte de análisis para el codificado y la transmisión de los parámetros de la señal de palabra, tales como la información de sonorización por sub-banda, el paso, las ganancias, los parámetros espectrales LSF y una parte de síntesis para la recepción y el decodificado de los parámetros transmitidos y la reconstrucción de la señal de palabra caracterizado porque comprende al menos las etapas siguientes:
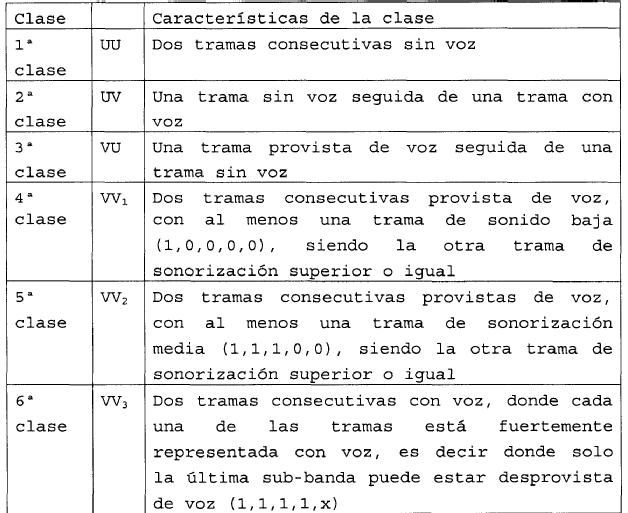
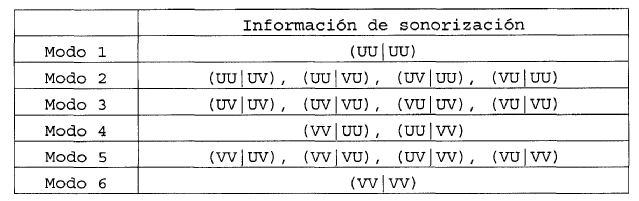
2. Procedimiento según la reivindicación 1, caracterizado porque define 6 modos de cuantificación según el encadenamiento de las clases de sonorización.
3. Procedimiento según la reivindicación 2, caracterizado porque N=4 y los modos de cuantificación son los siguientes:
4. Procedimiento según una de las reivindicaciones 1 a 3, caracterizado porque utiliza un método de cuantificación de tipo etapas múltiples para limitar el tamaño de los diccionarios y reducir la complejidad de búsqueda.
5. Procedimiento según la reivindicación 1, caracterizado porque para cuantificar los parámetros espectrales LSF, el flujo es asignado prioritariamente a la clase de sonido superior.
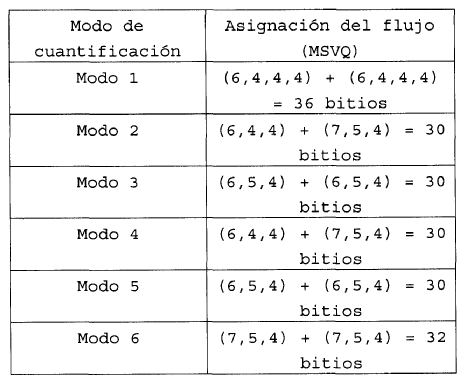
6. Procedimiento según la reivindicación 3, caracterizado porque la asignación del flujo para cada uno de los modos de cuantificación es el siguiente:
7. Procedimiento según la reivindicación 1, caracterizado porque para cuantificar el parámetro de ganancia un vector de al menos 8 ganancias es calculado para cada super trama.
8. Procedimiento según la reivindicación 7, caracterizado porque la asignación del flujo para un codificador de tipo MELP a 600 bitio/s y para una super trama de 54 bitios es el siguiente:

9. Procedimiento según la reivindicación 1, caracterizado porque para la cuantificación del paso, comprende al menos las etapas siguientes:
10. Procedimiento según la reivindicación 9, caracterizado porque se determina el valor de paso transmitido, su posición y el perfil de evolución utilizando un criterio de los menores cuadrados en la trayectoria de paso estimada en el análisis.
11. Procedimiento según la reivindicación 10, caracterizado porque se determinan las trayectorias por interpolación lineal entre el último valor de paso de la super trama precedente y el valor de paso que se transmitirá, si el valor de paso transmitido no está posicionado en la última trama, entonces se completa la trayectoria manteniendo el valor alcanzado o bien volviendo al último valor de paso de la super trama precedente.
12. Utilización del procedimiento según una de las reivindicaciones 1 a 11 en un codificador de palabra de tipo MELP a 600 bitios/s.
Patentes similares o relacionadas:
Método de codificación de impulsos de las señales de excitación, del 29 de Julio de 2020, de HUAWEI TECHNOLOGIES CO., LTD.: Un método para codificar una señal de voz, que comprende: la obtención de la distribución de impulsos de la señal de voz, en una pista, de los impulsos a codificarse […]
Método de predicción y dispositivo de decodificación para la señal de la banda de expansión del ancho de banda, del 24 de Junio de 2020, de Crystal Clear Codec, LLC: Un método para predecir una señal de banda de frecuencia de extensión del ancho de banda, que comprende: demultiplexación de un flujo de bits recibido y […]
Mejora del contenido insonoro para decodificador CELP de tasa baja, del 17 de Junio de 2020, de VoiceAge EVS LLC: Un dispositivo para modificar, durante la decodificación de una señal de sonido, una síntesis de una excitación de dominio de tiempo decodificada […]
Decodificador de audio y método para proporcionar una información de audio decodificada usando un ocultamiento de errores en base a una señal de excitación de dominio de tiempo, del 29 de Abril de 2020, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un decodificador de audio para proporcionar una información de audio decodificada en base a una información de audio codificada , comprendiendo […]
Método de generación y procesado de señal de ruido, codificador/decodificador y sistema de codificación/decodificación, del 22 de Abril de 2020, de HUAWEI TECHNOLOGIES CO., LTD.: Un método de procesado de señal de ruido basado en predicción lineal, en donde el método comprende: adquirir (S51) una señal de ruido, y obtener un coeficiente de predicción […]
Método y disposición para suavizar ruido estacionario de fondo, del 25 de Diciembre de 2019, de TELEFONAKTIEBOLAGET LM ERICSSON (PUBL): Un método para suavizar ruido de fondo, comprendiendo el método: recibir y decodificar (S10) una señal codificada que comprende tanto una componente de voz […]
Aparato y método para la renderización de audio empleando una definición de distancia geométrica, del 25 de Diciembre de 2019, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Aparato para reproducir un objeto de audio asociado con una posición, que comprende: un calculador de distancia para calcular distancias de la […]
Decodificador de audio y método para proporcionar una información de audio decodificada usando un ocultamiento de error que modifica una señal de excitación de dominio de tiempo, del 4 de Diciembre de 2019, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un decodificador de audio para proporcionar una información de audio decodificada basándose en una información de audio […]