Puesta en correspondencia de plantillas para codificación de vídeo.
Un procedimiento de codificación de vídeo para la codificación de un bloque de vídeo actual de una unidad de vídeo actual,
comprendiendo el procedimiento:
la generación de un primer conjunto de hipótesis para una codificación de vídeo predictiva de puesta en correspondencia de plantillas, en el que las hipótesis del primer conjunto se basan en tramas individuales de datos procedentes de al menos una lista que contiene tramas anteriores en orden de representación y una lista que contiene tramas futuras en orden de representación;
la generación de un segundo conjunto de hipótesis para una codificación de vídeo predictiva de puesta en correspondencia de plantillas, en el que las hipótesis del segundo conjunto están formadas a partir de la predicción de movimientos bidireccionales entre pares de tramas, en el que cada par de tramas comprende una trama procedente de la lista que contiene las tramas anteriores en orden de representación y una trama de la lista que contiene tramas futuras en orden de representación;
en el que cada una de las hipótesis de los primero y segundo conjuntos de hipótesis comprende datos de vídeo correspondientes a una forma de plantilla definida con respecto a un emplazamiento de bloque de vídeo;
la aplicación de las técnicas para la selección de las hipótesis entre los primero y segundo conjuntos de hipótesis; y
la codificación, por medio de un codificador de vídeo, del bloque de vídeo actual utilizando los datos de vídeo predictivos procedentes de las hipótesis seleccionadas.
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/US2010/040475.
Solicitante: QUALCOMM INCORPORATED.
Nacionalidad solicitante: Estados Unidos de América.
Dirección: International IP Administration 5775 Morehouse Drive San Diego, CA 92121-1714 ESTADOS UNIDOS DE AMERICA.
Inventor/es: KARCZEWICZ, MARTA, CHIEN,WEI-JUNG.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- H04N7/36
PDF original: ES-2452866_T3.pdf
Fragmento de la descripción:
Puesta en correspondencia de plantillas para codificación de vídeo
Campo técnico
La presente divulgación se refiere a la codificación de vídeo y, más en concreto, a las técnicas de codificación de vídeo que utilizan la predicción de movimientos de puesta en correspondencia de plantillas.
Antecedentes Las capacidades multimedia digitales pueden ser incorporadas en una amplia gama de dispositivos incluyendo televisiones digitales, sistemas digitales de difusión directa, dispositivos de comunicaciones inalámbricas, sistemas de difusión inalámbrica, asistentes personales digitales (PDAs) , computadoras portátiles o de escritorio, cámaras digitales, dispositivos de registro digitales, dispositivos de videojuegos, consolas de videojuegos, radioteléfonos celulares o por satélite, reproductores de medios digitales, y similares. Los dispositivos multimedia digitales pueden implementar técnicas de comunicación de vídeo, como por ejemplo MPEG-2, ITU -H.263, MPEG 4 o ITU-H. 264 / MPEG-4 Parte 10, Codificación de Vídeo Avanzada (AVC) , para transmitir y recibir o almacenar y recuperar de manera más eficiente datos de vídeo digitales. Las técnicas de codificación de vídeo pueden llevar a cabo una compresión de vídeo por medio de una predicción espacial y temporal para reducir o eliminar la redundancia inherente en las secuencias de vídeo.
En la codificación de vídeo, la compresión a menudo incluye la predicción espacial, la estimación de movimientos y la compensación de movimientos. La intracodificación se basa en la predicción espacial y en la codificación por transformación, como por ejemplo una transformación cosenoidal discreta (DCT) , para reducir o eliminar la redundancia espacial entre los bloques de vídeo dentro de una trama de vídeo determinada. La intercodificación se basa en la predicción temporal y en la codificación por transformación para reducir o eliminar la redundancia temporal entre bloques de vídeo de tramas de vídeo sucesivas de una secuencia de vídeo. Las tramas intracodificadas (“tramas -I”) a menudo se utilizan como puntos de acceso aleatorios así como referencias para la intercodificación de otras tramas. Las tramas -I, sin embargo, típicamente muestran una compresión menor que las demás tramas. El término unidades -I puede referirse a las tramas -I, a las rebanadas -I o a otras porciones independientemente descodificables de una trama -I.
Para la intercodificación, un codificador de vídeo lleva a cabo una estimación de movimientos para rastrear el movimiento de los bloques de vídeo en correspondencia entre dos o más tramas adyacentes u otras unidades codificadas, como por ejemplo rebanadas de tramas. Las tramas intercodificadas pueden incluir tramas predictivas (“tramas -P”) , las cuales pueden incluir bloques previstos a partir de una trama anterior, y tramas predictivas bidireccionales (“tramas -B”) las cuales pueden incluir bloques previstos procedentes de una trama anterior y de una trama posterior de una secuencia de vídeo. Las técnicas de codificación de vídeo convencionales de movimientos compensados comparan un bloque de vídeo con otros bloques de vídeo de una trama de vídeo anterior o posterior con el fin de identificar los datos de vídeo predictivos que pueden ser utilizados para codificar el bloque de vídeo actual. Un bloque de vídeo puede desglosarse en particiones sub-bloque para facilitar una codificación de mayor calidad.
Un bloque de vídeo codificado puede ser representado por una información de predicción que pueda ser utilizada para crear o identificar un bloque predictivo, y un bloque residual de datos indicativo de las diferencias entre el bloque que está siendo codificado y el bloque predictivo. La información de predicción puede comprender los uno o más vectores de movimiento que son utilizados para identificar el bloque de datos predictivo. Dados los vectores de movimiento, el descodificador es capaz de reconstruir los bloques predictivos que fueron utilizados para codificar el residual. Así, dado un conjunto de bloques residuales y un conjunto de vectores de movimiento (y posiblemente alguna sintaxis adicional) , el descodificador puede ser capaz de reconstruir una trama de vídeo que fue originalmente codificada. Una secuencia de vídeo codificada puede comprender bloques de datos residuales, vectores de movimiento y posiblemente otros tipos de sintaxis.
La puesta en correspondencia de plantillas es una técnica que puede ser utilizada para eliminar los vectores de movimiento, pero que al mismo tiempo pueda seguir proporcionando las ventajas de la codificación de vídeo de movimientos compensados. En la puesta de correspondencia de plantillas, los píxeles vecinos con respecto al bloque de vídeo que está siendo codificado pueden definir una plantilla, y esta plantilla (más que el bloque de vídeo que está siendo codificado) puede ser comparada con los datos de una trama de vídeo anterior o posterior. Tanto el codificador de vídeo como el descodificador de vídeo pueden llevar a cabo el proceso de puesta en correspondencia de plantillas para identificar el movimiento sin el uso de vectores de movimiento. Así, con la puesta en correspondencia de plantillas, los vectores de movimiento no son codificados en un flujo de bits. Por el contrario, los vectores de movimiento son derivados esencialmente del proceso de puesta en correspondencia de plantillas a medida que la trama es codificada y descodificada.
El documento “Procedimiento multihipótesis que utiliza una derivación de vectores del lado del movimiento del descodificador en una codificación de vídeo intertramas” [“Multhypothesis prediction using decoder side-motion vector derivation in inter-frame vídeo coding”], Kamp S. et al, Visual Communications and Imagen Processing, 20-01
2009 a , San José, 20 de enero de 2009, XP030081712 divulga un procedimiento de codificador de vídeo en el que un conjunto de hipótesis son generadas para una codificación predictiva de puesta en correspondencia de plantillas, siendo el bloque de vídeo actual codificado utilizando datos de vídeo procedentes del conjunto de hipótesis.
Sumario En general, la presente divulgación describe técnicas de codificación de vídeo aplicables a la codificación de predicción de movimiento de puesta en correspondencia de plantillas de bloques de vídeo dentro de unidades de vídeo. Una unidad de vídeo puede comprender una trama de vídeo o una rebanada de una trama de vídeo. En la predicción de movimiento de la puesta en correspondencia de plantillas, un bloque de vídeo es codificado de manera predictiva y descodificado en base a una o más listas de datos de referencia predictivos sin basarse en vectores de movimiento, proporcionando sin embargo al tiempo las ventajas de la codificación de vídeo de compensación de movimiento compensado. En particular, los píxeles vecinos con respecto al bloque de vídeo que está siendo codificado pueden definir una plantilla y esta plantilla, y no el bloque de vídeo que está siendo codificado, puede ser comparada con los datos almacenados en las listas de los datos de referencia predictivos. Los datos de referencia predictivos son generados en base a una o más tramas que pueden producirse antes o después de una trama destinaria.
De acuerdo con un primer aspecto de la primera invención, se proporciona un procedimiento de codificación de vídeo para la codificación de un bloque de vídeo actual de una unidad de vídeo actual que comprende la generación de un primer conjunto de hipótesis para la codificación de vídeo predictiva de puesta en correspondencia de plantillas, en el que las hipótesis del primer conjunto se basan en tramas individuales de datos procedentes de al menos una lista que contiene tramas anteriores en orden de representación y una trama procedente de una lista que contiene tramas futuras en orden de representación;
la generación de un segundo conjunto de hipótesis para la codificación de vídeo predictiva de puesta en correspondencia de plantillas, en el que las hipótesis del segundo conjunto están formadas a partir de una predicción de movimientos bidireccionales entre pares de tramas, en el que cada par de tramas comprende una trama procedente de la lista que contiene las tramas anteriores en orden de representación y una trama procedente de la lista que contiene tramas futuras en orden de representación; en el que cada una de las hipótesis de los primero y segundo conjuntos de hipótesis comprende unos datos de vídeo correspondientes a una forma de plantilla definida con respecto a un emplazamiento del bloque;
la aplicación de técnicas para la aplicación de hipótesis entre los primero y segundo conjuntos de hipótesis;... [Seguir leyendo]
Reivindicaciones:
1. Un procedimiento de codificación de vídeo para la codificación de un bloque de vídeo actual de una unidad de vídeo actual, comprendiendo el procedimiento:
la generación de un primer conjunto de hipótesis para una codificación de vídeo predictiva de puesta en correspondencia de plantillas, en el que las hipótesis del primer conjunto se basan en tramas individuales de datos procedentes de al menos una lista que contiene tramas anteriores en orden de representación y una lista que contiene tramas futuras en orden de representación;
la generación de un segundo conjunto de hipótesis para una codificación de vídeo predictiva de puesta en correspondencia de plantillas, en el que las hipótesis del segundo conjunto están formadas a partir de la predicción de movimientos bidireccionales entre pares de tramas, en el que cada par de tramas comprende una trama procedente de la lista que contiene las tramas anteriores en orden de representación y una trama de la lista que contiene tramas futuras en orden de representación;
en el que cada una de las hipótesis de los primero y segundo conjuntos de hipótesis comprende datos de vídeo correspondientes a una forma de plantilla definida con respecto a un emplazamiento de bloque de vídeo;
la aplicación de las técnicas para la selección de las hipótesis entre los primero y segundo conjuntos de hipótesis; y
la codificación, por medio de un codificador de vídeo, del bloque de vídeo actual utilizando los datos de vídeo predictivos procedentes de las hipótesis seleccionadas.
2. El procedimiento de codificación de vídeo de la reivindicación 1, en el que el codificador de vídeo comprende un descodificador de vídeo, en el que el procedimiento comprende también:
el cálculo de un primer coste asociado con la codificación del bloque de vídeo actual, en el que el primer coste se calcula mediante la adición de una distorsión más un producto de un multiplicador de Lagrange por una tasa de codificación para el primer conjunto de hipótesis;
el cálculo de un segundo coste asociado con la codificación de bloque de vídeo actual, en el que el segundo coste se calcula mediante la adición de una distorsión más un producto de un multiplicador de Lagrange por una tasa de codificación para el segundo conjunto de hipótesis;
la determinación del coste más bajo asociado con la codificación del bloque de vídeo actual entre el primer coste y el segundo coste; y
el establecimiento de un elemento sintáctico para señalar si el primer conjunto de hipótesis o el segundo conjunto de hipótesis deben ser utilizados por un descodificador.
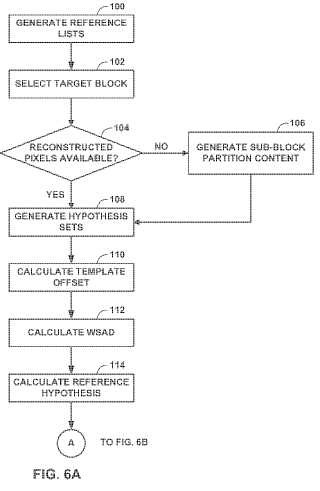
3. El procedimiento de codificación de vídeo de la reivindicación 1, en el que la generación de los conjuntos de hipótesis comprende el cálculo de una suma ponderada de diferencias absolutas, en el que el cálculo de la suma ponderada incluye la división de una plantilla asociada con el bloque de vídeo actual en una pluralidad de particiones y la multiplicación de una suma de las diferencias absolutas de cada partición de la pluralidad de particiones por un valor que disminuye a medida que aumenta una distancia de la partición sometida a consideración a partir del bloque de vídeo actual.
4. El procedimiento de codificación de vídeo de la reivindicación 1, en el que la generación de los conjuntos de hipótesis comprende:
el cálculo de un desplazamiento de plantilla, en el que el cálculo comprende el cálculo de la diferencia media en valores de píxeles de una plantilla definida con respecto al bloque de vídeo actual y en valores de píxeles de una primera hipótesis del conjunto de hipótesis; y
la aplicación del desplazamiento de la plantilla a la diferencia entre cada uno de los valores de píxeles de la primera hipótesis y cada uno de los valores de píxeles de la plantilla definida con respecto al bloque de vídeo actual.
5. Un aparato de codificación de vídeo que codifica un bloque de vídeo actual, comprendiendo el aparato:
una unidad de predicción que genera un primer conjunto de hipótesis y un segundo conjunto de hipótesis para la codificación de vídeo predictiva de puesta en correspondencia de plantillas, en el que las hipótesis del primer conjunto se basan en tramas individuales de datos procedentes de al menos una lista que contiene tramas anteriores en orden de representación y una lista que contiene tramas futuras en orden de representación, y las hipótesis del segundo conjunto se forman a partir de una predicción de movimientos bidireccionales entre partes de tramas, en el que cada par de tramas comprende una trama procedente de
una lista que contiene tramas anteriores en orden de representación y una trama procedente de la lista que contiene tramas futuras en orden de representación, en el que cada una de las hipótesis de los primero y segundo conjuntos de hipótesis comprende datos de vídeo correspondientes a una forma de plantilla con respecto a un emplazamiento de bloque de vídeo y aplica unas técnicas para la selección de hipótesis entre los primero y segundo conjuntos de hipótesis; y
una unidad de codificación de vídeo que codifica el bloque de vídeo actual utilizando los datos de vídeo predictivos procedentes de las hipótesis seleccionadas.
6. El aparato de codificación de vídeo de la reivindicación 5, en el que la unidad de codificación de vídeo es un codificador de vídeo, y en el que la unidad de predicción calcula un primer coste asociado con la codificación del bloque de vídeo actual, el primer coste es calculado mediante la adición de una distorsión más un producto de un multiplicador de Lagrange por una tasa de codificación para el primer conjunto de hipótesis, calcula un segundo coste asociado con la codificación del bloque de vídeo actual, el segundo coste es calculado mediante la adición de una distorsión más un producto de un multiplicador de Lagrange por una tasa de codificación del segundo conjunto de hipótesis, determina el coste más bajo asociado con la codificación del bloque de vídeo actual entre el primer coste y el segundo coste, y establece un elemento sintáctico para señalar si el primer conjunto de hipótesis o el segundo conjunto de hipótesis deben ser utilizados por un descodificador.
7. El aparato de codificación de vídeo de la reivindicación 5, en el que la unidad de predicción genera los conjuntos de hipótesis calculando, al menos, una suma ponderada de diferencias absolutas, en el que la suma ponderada de diferencias absolutas se calcula al menos dividiendo una plantilla asociada con el bloque de vídeo actual en una pluralidad de particiones y multiplicando una suma de las diferencias absolutas de cada partición de la pluralidad de particiones por un valor que disminuye a medida que aumenta una distancia de la partición respecto del bloque de vídeo actual
8. El aparato de codificación de vídeo de la reivindicación 5, en el que la unidad de predicción genera los conjuntos de hipótesis calculando al menos un desplazamiento de plantilla mediante el cálculo de al menos la diferencia media de valores de píxeles de una plantilla definida con respecto al bloque de vídeo actual y en valores de píxeles de una primera hipótesis del conjunto de hipótesis, y la aplicación de un desplazamiento de plantilla a la diferencia entre cada uno de los valores de píxeles de la primera hipótesis y cada uno de los valores de píxeles de la plantilla definida con respecto al bloque de vídeo actual.
9. El aparato de codificación de vídeo de la reivindicación 5, en el que el aparato de codificación de vídeo comprende un circuito integrado.
10. El aparato de codificación de vídeo de la reivindicación 5, en el que el aparato de codificación de vídeo comprende un microprocesador.
11. El aparato de codificación de vídeo de la reivindicación 5, en el que el aparato de codificación de vídeo comprende un dispositivo de comunicación inalámbrico que incluye un codificador de vídeo.
12. Un medio de almacenamiento legible por computadora codificado con instrucciones para hacer que uno o más procesadores programables:
generen un primer conjunto de hipótesis para la codificación de vídeo predictiva de puesta en correspondencia de plantillas, en el que las hipótesis del primer conjunto se basan en tramas individuales de datos procedentes de al menos una lista que contiene tramas anteriores en orden de representación y una lista que contiene tramas futuras en orden de representación;
generen un segundo conjunto de hipótesis para la codificación de vídeo predictiva de puesta en correspondencia de plantillas, en el que las hipótesis del segundo conjunto están formadas a partir de la predicción de movimientos bidireccionales entre pares de tramas, en el que cada par de tramas comprende una trama procedente de la lista que contiene tramas anteriores en orden de representación y una trama procedente de la lista que contiene tramas futuras en orden de representación;
en el que cada una de las hipótesis de los primero y segundo conjuntos de hipótesis comprende unos datos de vídeo correspondientes a una forma de plantilla definida con respecto a un emplazamiento de bloque de vídeo;
apliquen unas técnicas para la selección de hipótesis entre los primero y segundo conjuntos de hipótesis; y
codifiquen el bloque de vídeo actual utilizando datos de vídeo predictivos procedentes de las hipótesis seleccionadas.
13. El medio de almacenamiento legible por computadora de la reivindicación 12, en el que las instrucciones que hacen los uno o más procesadores programables codifiquen el bloque de vídeo actual comprenden también instrucciones para hacer que los uno o más procesadores programables:
calculen un primer coste asociado con la codificación del bloque de vídeo actual, en el que el primer coste se calcula mediante la adición de una distorsión más un producto de un multiplicador de Lagrange por una tasa de codificación para el primer conjunto de hipótesis;
calculen un segundo coste asociado con la codificación de bloque de vídeo actual, en el que el segundo 5 coste se calcula mediante la adición de una distorsión más un producto de un multiplicador de Lagrange con una tasa de codificación para el subconjunto del conjunto de hipótesis;
determinen el coste más bajo asociado con la codificación del bloque de vídeo actual entre el primer coste y el segundo coste; y
establezcan un valor sintáctico para señalar si el primer subconjunto de hipótesis o el segundo conjunto de 10 hipótesis deben ser utilizados por un descodificador.
Patentes similares o relacionadas:
Interpolación mejorada de cuadros de compresión de vídeo, del 4 de Diciembre de 2019, de DOLBY LABORATORIES LICENSING CORPORATION: Un método para compresión de imágenes de video usando predicción en modo directo, que incluye: proporcionar una secuencia de cuadros predichos […]
Interpolación mejorada de cuadros de compresión de vídeo, del 4 de Diciembre de 2019, de DOLBY LABORATORIES LICENSING CORPORATION: Un método de compresión de imágenes de video que comprende: proporcionar una secuencia de cuadros referenciables (I, P) y predichos bidireccionales […]
Transformación solapada condicional, del 20 de Noviembre de 2019, de Microsoft Technology Licensing, LLC: Un método para codificar un flujo de bits de vídeo utilizando una transformación solapada condicional, en donde el método comprende: la señalización de un modo de filtro […]
 Procedimiento de compresión de información de vídeo, del 30 de Octubre de 2019, de Broadmedia GC Corporation: Un procedimiento de compresión de información de vídeo, que comprende las etapas de:
- proyectar puntos de una imagen siguiente en puntos proyectados […]
Procedimiento de compresión de información de vídeo, del 30 de Octubre de 2019, de Broadmedia GC Corporation: Un procedimiento de compresión de información de vídeo, que comprende las etapas de:
- proyectar puntos de una imagen siguiente en puntos proyectados […]
Método de cálculo de vectores de movimiento, del 12 de Junio de 2019, de Panasonic Intellectual Property Corporation of America: Un sistema de codificación y descodificación de imágenes que incluye un aparato de codificación de imágenes que codifica un bloque actual incluido en una imagen actual […]
Método de cálculo de vectores de movimiento, del 12 de Junio de 2019, de Panasonic Intellectual Property Corporation of America: Un método de codificación de imágenes para codificar un bloque actual incluido en una imagen actual en modo directo, comprendiendo el método de codificación de imágenes: […]
Método de cálculo de vectores de movimiento, del 12 de Junio de 2019, de Panasonic Intellectual Property Corporation of America: Un sistema de codificación y descodificación de imágenes que incluye un aparato de codificación de imágenes que codifica un bloque actual incluido en una […]
Procedimiento de cálculo de vectores de movimiento, del 12 de Junio de 2019, de Panasonic Intellectual Property Corporation of America: Un procedimiento de codificación de imágenes para codificar un bloque actual incluido en una imagen actual, comprendiendo el procedimiento […]