PROCEDIMIENTO Y DISPOSITIVO DE CLASIFICACIÓN PARA GRANDES VOLÚMENES DE DATOS.
La presente invención muestra un novedoso método y dispositivo para la clasificación de grandes volúmenes de datos,
utilizando una o varias Máquinas de Vectores Soporte (MVS) que pueden trabajar en paralelo.
El proceso de clasificación se realiza en dos etapas, una primera donde se "entrena" el dispositivo: se suministra un conjunto de datos (11), se les asigna un clase (12), se seleccionan parejas representativas de cada grupo (14) y se procesan en las MVS (15). Una vez realizado el "entrenamiento" se clasifican nuevos elementos: para ello cada vez que llega uno nuevo, cada MVS asigna el dato a una clase (22), se ponderan todos los votos (23) y se suman las votaciones (24), el resultado será la clase a la que se asigna el nuevo dato.
Tipo: Patente de Invención. Resumen de patente/invención. Número de Solicitud: P201230903.
Solicitante: UNIVERSIDAD REY JUAN CARLOS.
Nacionalidad solicitante: España.
Inventor/es: CASTILLO VILLAR,JAVIER, MARTINEZ MOGUERZA,Javier, MARTINEZ TORRE,José Ignacio, RIOS INSUA,David, CANO MONTERO,Javier.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G06K9/62 FISICA. › G06 CALCULO; CONTEO. › G06K RECONOCIMIENTO DE DATOS; PRESENTACION DE DATOS; SOPORTES DE REGISTROS; MANIPULACION DE SOPORTES DE REGISTROS (impresión per se B41J). › G06K 9/00 Métodos o disposiciones para la lectura o el reconocimiento de caracteres impresos o escritos o el reconocimiento de formas, p. ej. de huellas dactilares (métodos y disposiciones para la lectura de grafos o para la conversión de patrones de parámetros mecánicos, p.e. la fuerza o la presencia, en señales eléctricas G06K 11/00; reconocimiento de la voz G10L 15/00). › Métodos o disposiciones para el reconocimiento que utilizan medios electrónicos.
Fragmento de la descripción:
PROCEDIMIENTO Y DISPOSITIVO DE CLASIFICACIÓN PARA GRANDES VOLÚMENES
DE DATOS
Campo de la técnica al que pertenece la invención La presente invención se engloba en el campo de los sistemas de clasificación para grandes volúmenes de datos. Más específicamente describe un nuevo método y dispositivo que reduce el tiempo de clasificación sustancialmente a partir del uso de Maquinas de Vectores Soporte (SVM) .
Estado de la técnica Las técnicas de clasificación y de reconocimiento de patrones tienen un amplio campo de aplicaciones. En los últimos años algunas áreas de la técnica, tales como las ciencias de la vida, la meteorología o el análisis financiero, han comenzado a usar estas técnicas para estudiar estadísticamente grupos de interés dentro de grandes conjunto de datos.
En el campo de la medicina, por citar uno, la búsqueda de determinados marcadores proteínicos en pacientes con cáncer de mama, el estudio del ADN o la diabetes han encontrado en estas técnicas una potente herramienta de trabajo para la investigación. En el primer caso, por ejemplo, el problema radica en la necesidad, durante la fase de pruebas clínicas, de probar la eficacia de un medicamento para curar el cáncer, mientras este está en una fase inicial. Para ello es necesario identificar que paciente lo está desarrollando lo antes posible.
Otro campo de la técnica es la minería de textos, donde analizar textos en varios documentos simultáneamente representa una altísima carga computacional. En este caso aparecen matrices cuyas dimensiones son el producto del número de documentos por el vocabulario total que aparece en cada documento. Así se generan matrices enormes resultado del producto cartesiano de estas dos magnitudes. Este es, por ejemplo, el caso de las búsquedas no dirigidas en la web.
Varias son las técnicas de análisis de datos que se están utilizando actualmente para atacar este tipo de problemas: árboles de decisión, análisis de componentes principales (ACP) , análisis Bayesiano o las redes neuronales. Estas técnicas producen muchas “falsas alarmas” o errores en la clasificación. Esto supone, en casos como el análisis del cáncer, que las falsas alarmas provoquen mucha ansiedad en los pacientes y un uso innecesario de biopsias o, en el lado contrario, la no detección de la enfermedad en pacientes que la están desarrollando.
Una novedosa alternativa son las Máquinas de Vector Soporte, SVM a partir de ahora, que ofrecen una nueva aproximación a estos problemas de clasificación de patrones, siendo especialmente robustas para datos de altas dimensiones, donde otros sistemas de clasificación se colapsan, debido a los elevados recursos computacionales que necesitan.
Para un conjunto de datos, subconjunto de otro mayor (espacio) , en el que cada uno de los datos pertenece a una de dos posibles categorías, la SVM es capaz de predecir si un punto nuevo, cuya categoría desconocemos, pertenece a una u otra. Antes de llevar a cabo esta clasificación es necesario entrenar al sistema, a partir de unos datos de control. Una vez realizado el entrenamiento, la SVM busca una línea, más correctamente un hiperplano, que separa de forma óptima los puntos de cada una de las clases. Este concepto de separación óptima es donde reside la característica fundamental del uso de las SVM.
En la literatura técnica se ha comenzado a describir el uso de varias SVM que procesan la información de forma simultánea, como se describe en las patentes US7519563 y US7865898, donde se habla de la posibilidad de fraccionar los datos que se le suministran al sistema para que sea más efectivo, computacionalmente hablando, pero no resuelven el problema de cómo clasificar información con esta arquitectura.
Problema técnico a resolver
En la actualidad cuando se quiere clasificar un volumen de datos muy elevado, del orden de 10 millones o superior, las técnicas que se pueden utilizar son la de vecinos más próximos o los métodos de inferencia bayesiana, cuyo coste computacional es muy elevado. El tiempo necesario para resolverl estos problemas es de varias horas, no siendo posible en ocasiones hallar una solución al problema planteado debido al colapso del sistema de computación. En el 2010 se propuso una técnica basada en el uso de árboles de decisión [Chang, Fu. Guo, Chien-Yanh, et al. Tree descomposition for large-scale SVM problems, Journal of Machine Learning Research 11 (2010) 2855-2892] que puede resolver alguno de estos problemas pero con dimensiones mucho menores.
Es por esto que el problema técnico que resuelve esta invención es el desarrollo de un nuevo método, y de un dispositivo electrónico, capaz de resolver problemas de clasificación, en conjuntos de datos muy elevados -del orden de millones de datos-en espacios de tiempo muy cortos -del orden de segundos o minutos, dependiendo del volumen de información-y utilizando sistemas de computación de uso corrientes.
Descripción detallada de la invención Las máquinas de vector soporte se han convertido en una novedosa herramienta para el reconocimiento de patrones. La aplicación más sencilla de esta técnica es el problema de clasificación binaria, aquel en el que únicamente hay dos clases definidas. La idea subyacente es encontrar una función de separación de las dos clases cuya probabilidad de error empírico sea mínima. Esta función, utilizando las transformaciones adecuadas, se puede representar como un hiperplano.
La presente solicitud de patente muestra un novedoso método para la clasificación de nuevos datos, dentro de un grupo muy grande, utilizando una o varias Maquinas de Vectores Soporte que pueden trabajan en paralelo.
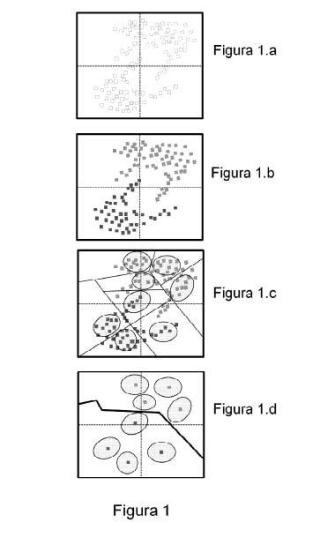
Este proceso de clasificación se realiza en dos etapas: una primera de “entrenamiento” del dispositivo y una segunda de clasificación. En la primera de ellas, a partir de una población inicial que se utiliza como muestra de entrenamiento (figura 1.a) se dividen los datos en dos categorías (figura 1.b) . Esta primera separación en dos clases se puede realizar por cualquier método estadístico conocido que agrupe datos que tienen cierta similitud. Uno posible es k-medias, que permite particionar un conjunto grande de datos en k-conjuntos más pequeños. Cada uno de estos conjuntos engloba a los datos que tienen una media más cercana entre ellos. Aunque este es un método adecuado, se puede utilizar cualquiera otro que separe los datos en dos clases adecuadas para el análisis que se va a realizar.
El proceso de entrenamiento completo se muestra esquemáticamente en el diagrama de flujo de la figura 2. Una vez que todos los individuos del conjunto de entrenamiento están asociados a una única clase (11) , se asigna el número de grupos en los que se dividirá el conjunto de datos (12) . Esto tiene por objetivo fraccionar cada una de las clases en grupos más pequeños que permitirá su procesamiento en paralelo posteriormente.
Esta asignación de grupos se puede realizar tanto manualmente como a través de un método estadístico, de nuevo se puede utilizar k-medias u otras técnicas de estimación de densidades o, incluso, métodos de estimación de modas basados en mixturas y simulación Montecarlo. Se utilizará el método que en ese modelo de datos se adecue más a la distribución dada. La decisión de utilizar un mecanismo u otro estará en función, o bien, de la persona responsable de la clasificación, o bien, del número de datos y la cantidad que se quiere cargar en cada memoria.
Cada uno de estos grupos tendrá asignado un centroide (13) que servirá de referencia para posteriormente calcular las áreas de influencia de estos grupos, esto es, la pertenencia de los datos a estos grupos. Para ello se calculan las regiones de Voronoi asociadas a estos grupos (figura 1.c) . Las regiones de Voronoi son un método de interpolación muy simple basado en el cálculo de la distancia euclídea entre datos. Cuando se calculan sobre muchos puntos, el área se divide en una serie de polígonos de manera que su perímetro equidista de los puntos vecinos. Esto permite subdividir la clase en una serie de conjuntos que tienen las mismas características que la clase a la que pertenece. Se hace de esta forma, utilizando los grupos anteriores, porque si se quisiera calcular las regiones de Voronoi sobre todos los datos de la clase completa el coste computacional sería elevadísimo. La división en regiones para su posterior paralelización es la clave de éxito de este método.
Se seleccionan aleatoriamente pares de regiones de Voronoi, una de cada una de las dos clases (14) , y se comienza el entrenamiento de las SVM (15a, 15i) . El número de SVM dependerá de la arquitectura electrónica elegida para ejecutar este método....
Reivindicaciones:
REIVINDICACIONES?
1. Procedimiento para la clasificación de grandes volumenes de datos, que utiliza
Maquinas de Vectores Soporte, que consta primero de un procedimiento de
5 entrenamiento del sistema para la clasificación de nuevos individuos, en un conjunto
de datos, donde el entrenamiento de las Maquinas de Vectores Soporte (SVM) que
realizaran la clasificación, esta caracterizado por constar de las siguientes etapas:
a. a cada dato de la muestra de entrenamiento se le asigna la pertenencia a una
clase determinada, dentro de un grupo de dos clases;
10 b. se asigna el numero de grupos que habra en cada una de las clases de la
muestra de datos de entrenamiento;
c. para cada clase se forman tantos grupos como se hayan asignado en el
punto b, agrupando todos los datos de la muestra en alguno de estos grupos;
d. se seleccionan parejas de grupos, donde cada uno de los miembros de la
15 pareja pertenece una clase diferente;
e. se entrena la Maquina de Vectores Soporte (SVM) .
Y segundo, de un procedimiento para la clasificación de nuevos individuos, dentro
del conjunto de datos, caracterizado porque consta de los siguientes pasos:
20 a. cada Maquina de Vectores Soporte (SVM) vota en que clase esta el nuevo
dato;
b. una vez que todas las Maquinas de Vectores Soporte (SVM) ha votado a que
clase pertenece el nuevo dato se suman todos los resultados de las
votaciones;
25 c. El nuevo dato se asigna la clase mas votada.
2. Procedimiento para la clasificación de grandes volumenes de datos, donde el
entrenamiento de las Maquinas de Vectores Soporte (SVM) que realizaran la
clasificación, de acuerdo con la reivindicación 1, esta caracterizado porque la
30 asignación del numero de grupos se puede hacer tanto de forma manual como en
función del numero de datos y el tamafo maximo de cada grupo.
3. Procedimiento para la clasificación de grandes volumenes de datos, donde el
entrenamiento de las Maquinas de Vectores Soporte (SVM) que realizaran la
35 clasificación, de acuerdo con la reivindicación 1, esta caracterizado porque la
posición de los centroides de cada uno de los grupos se calcula utilizando el
algoritmo de k-medias.
4. Procedimiento para la clasificación de grandes volumenes de datos, donde el
40 entrenamiento de las Maquinas de Vectores Soporte (SVM) que realizaran la
clasificación, de acuerdo con la reivindicación 1, esta caracterizado porque la
agrupación de los datos en cada clase se hace utilizando regiones de Voronoi.
5. Procedimiento para la clasificación de grandes volumenes de datos, donde el
45 entrenamiento de las Maquinas de Vectores Soporte (SVM) que realizaran la
clasificación, de acuerdo con la reivindicación 1, esta caracterizado porque el entrenamiento de las diferentes SVM se hace en paralelo en todas ellas a la vez.
6. Procedimiento para la clasificación de grandes volumenes de datos, de acuerdo con la reivindicación 1, caracterizado porque el voto que realiza cada Maquina de Vectores Soporte (SVM) puede ser ponderado de acuerdo a un criterio predeterminado.
7. Procedimiento para la clasificación de grandes volumenes de datos, de acuerdo con la reivindicación 1, caracterizado porque el voto se realiza simultaneamente en todas las Maquinas de Vectores Soporte (SVM) .
8. Dispositivo electrónico para la clasificación de grandes volumenes de datos que comprende al menos:
a. una memoria de almacenamiento, para información de cada conglomerado, las matrices de individuos, la matrices de distancias y sus variables asociadas y los datos intermedios necesarios para el calculo final;
b. una unidad de proceso de los datos, donde las Maquinas de Vectores Soporte reciben el flujo de datos de las memorias y los clasifican;
c. un bus de comunicaciones que permite tanto enviar los datos de las memorias a la unidad de proceso de datos como enviar lo datos clasificados a los diferentes dispositivos que se utilicen para la comprobación del resultado y
d. un interface de entrada/salida que permite tanto la recepción de los datos de partida, ya vengan a traves de una red de datos cableada o inalambrica, un fichero de texto u otro dispositivo de entrada, como el envio de la información ya procesada a dispositivos externos al sistema.
9. Dispositivo electrónico, segun la reivindicación 8, caracterizado porque la unidad de proceso de los datos puede ser una FPGA, un circuito integrado disefado especificamente para esta labor (ASIC) , un microprocesador u otra tecnologia electrónica capaz de realizar la labor de clasificación.
PCI - E
Microblaze
Figura 4
Memoria cache 4kB Memoria cache 4kB Instrucciones Instrucciones
Microblaze Memoria DDR 256 MB
Memoria cache 4kB Memoria cache 4kB Instrucciones Instrucciones
PCI - E
Microblaze PLB
Figura 5
Patentes similares o relacionadas:
Dispositivo de procesamiento de imágenes, método de procesamiento de imágenes y programa, del 29 de Julio de 2020, de RAKUTEN, INC: Dispositivo de procesamiento de imágenes, que comprende: medios de obtención de imágenes captadas para la lectura de datos […]
PROCEDIMIENTO DE IDENTIFICACIÓN DE IMÁGENES ÓSEAS, del 2 de Julio de 2020, de UNIVERSIDAD DE GRANADA: La presente invención tiene por objeto un procedimiento para asistir en la toma de decisiones a un experto forense de cara a la identificación de […]
MÉTODO PARA LA ELIMINACIÓN DEL SESGO EN SISTEMAS DE RECONOCIMIENTO BIOMÉTRICO, del 2 de Julio de 2020, de UNIVERSIDAD AUTONOMA DE MADRID: Método para eliminación del sesgo (por edad, etnia o género) en sistemas de reconocimiento biométrico, que comprende definir un conjunto de M muestras de Y personas […]
Sistema y método para la autenticación biométrica en conexión con dispositivos equipados con cámara, del 19 de Febrero de 2020, de Element, Inc: Un sistema antisuplantación para detectar y usar características tridimensionales de una huella de la palma humana con el fin de proporcionar acceso selectivo a los […]
Detección y seguimiento de objetos en imágenes, del 19 de Febrero de 2020, de QUALCOMM INCORPORATED: Un procedimiento implementado por ordenador que comprende: detectar, dentro de una imagen, un objeto cerca de una superficie usando […]
Caracterización de una colisión de vehículo, del 1 de Enero de 2020, de GEOTAB Inc: Un método que comprende: en respuesta a la obtención de información con respecto a una colisión potencial entre un vehículo y un objeto, obtener, durante un periodo de […]
Un sistema de visualización de información personal y método asociado, del 11 de Diciembre de 2019, de AMADEUS S.A.S.: Un sistema para identificación y/o autenticación de un usuario en una terminal de viaje, comprendiendo el sistema: una base de datos […]
Procedimiento de procesamiento de una señal asíncrona, del 16 de Octubre de 2019, de Sorbonne Université: Procedimiento de reconocimiento de formas en una señal asíncrona producida por un sensor de luz, teniendo el sensor una matriz de píxeles dispuesta frente […]