Método de y aparato para evaluar inteligibilidad de una señal de voz degradada.
Método para evaluar inteligibilidad de una señal de voz degradada recibida desde un sistema de transmisión de audio,
al transmitir a través de dicho sistema de transmisión de audio una señal de voz de referencia con el fin de proporcionar dicha señal de voz degradada, en donde el método comprende:
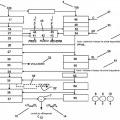
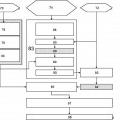
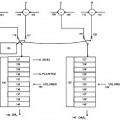
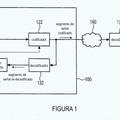
- muestrear dicha señal de voz de referencia en una pluralidad de tramas de señal de referencia, muestrear dicha señal de voz degradada en una pluralidad de tramas de señal degradadas, y formar pares de tramas al asociar dichas tramas de señal de referencia y dichas tramas de señal degradadas entre sí;
- para cada par de tramas procesar previamente dichas tramas de señal de referencia y dichas tramas de señal degradadas para permitir una comparación entre dichas tramas de cada par de tramas;
El método se caracteriza adicionalmente por:
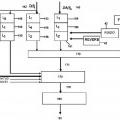
- proporcionar para cada par de tramas una o más funciones de diferencia que representan una diferencia entre dicha trama de señal degradada y dicha trama de señal de referencia asociada;
- seleccionar por lo menos una de dichas funciones de diferencia para compensar dicha por lo menos una de dichas funciones de diferencia para uno o más tipos de perturbaciones, tales como proporcionar para cada par de tramas una o más funciones de densidad de perturbación adaptadas a un modelo de percepción auditivo humano, en donde dicha selección se realiza al comparar un nivel de perturbación de dicha señal degradada con un nivel de perturbación umbral;
y
- derivar de dichas funciones de densidad de perturbación de una pluralidad de pares de tramas un parámetro de calidad completo, dicho parámetro de calidad es por lo menos indicador de dicha inteligibilidad de dicha señal de voz degradada;
en donde dicho método comprende una etapa de determinar por lo menos un parámetro de conmutación indicador de un nivel de potencia de audio de dicha señal degradada, y utilizar dicho por lo menos un parámetro de conmutación para determinar o adaptar dicho nivel de perturbación umbral que se utiliza en la realización de dicha selección de dicha por lo menos una de dichas funciones de diferencia para optimizar dicho método para las condiciones de nivel de potencia de audio de dicha señal degradada para evaluación de dicha inteligibilidad de dicha señal de voz degradada para dicha evaluación.
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/NL2012/050807.
Solicitante: NEDERLANDSE ORGANISATIE VOOR TOEGEPAST-NATUURWETENSCHAPPELIJK ONDERZOEK TNO.
Nacionalidad solicitante: Países Bajos.
Dirección: Anna van Buerenplein 1 2595 DA 's-Gravenhage PAISES BAJOS.
Inventor/es: BEERENDS, JOHN GERARD.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G10L25/69 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › G10L 25/00 Técnicas de análisis del habla o voz no restringidos a un solo de los grupos G10L 15/00 - G10L 21/00 (silenciar los amplificadores basados en semiconductores, cuando algunas de las características especiales de una señal son detectadas por un detector de voz, p. ej. detectar cuando no hay ninguna señal, H03G 3/34). › para evaluar señales de voz sintéticas o decodificadas.
PDF original: ES-2553462_T3.pdf

Patentes similares o relacionadas:
Estimación de audibilidad de muestras de audio, del 12 de Noviembre de 2019, de BMAT LICENSING, S.L.U: Un procedimiento para estimar la audibilidad de una muestra de audio en una mezcla de audio de un programa de medio de radio difusión, que comprende: […]
Determinar la distancia y/o calidad acústica entre un dispositivo móvil y una unidad de base, del 2 de Agosto de 2017, de KONINKLIJKE PHILIPS N.V: Un método de determinación de la distancia y/o calidad acústica entre un dispositivo móvil que tiene un micrófono y un altavoz y una unidad de base que […]
 Método y aparato para evaluar la inteligibilidad de una señal de voz degradada, del 19 de Enero de 2016, de NEDERLANDSE ORGANISATIE VOOR TOEGEPAST-NATUURWETENSCHAPPELIJK ONDERZOEK TNO: Método para evaluar la inteligibilidad de una señal de voz degradada recibida de un sistema de transmisión de audio, al transportar a través de dicho […]
Método y aparato para evaluar la inteligibilidad de una señal de voz degradada, del 19 de Enero de 2016, de NEDERLANDSE ORGANISATIE VOOR TOEGEPAST-NATUURWETENSCHAPPELIJK ONDERZOEK TNO: Método para evaluar la inteligibilidad de una señal de voz degradada recibida de un sistema de transmisión de audio, al transportar a través de dicho […]
 Aparato, método y programa informático para evitar artefactos de recorte, del 13 de Enero de 2016, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un aparato de codificación de audio que comprende:
un codificador para codificar un segmento de tiempo de una señal de audio de entrada a codificar para […]
Aparato, método y programa informático para evitar artefactos de recorte, del 13 de Enero de 2016, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un aparato de codificación de audio que comprende:
un codificador para codificar un segmento de tiempo de una señal de audio de entrada a codificar para […]
 Método, producto de programa de ordenador y sistema para determinar una calidad percibida de un sistema de audio, del 24 de Diciembre de 2014, de KONINKLIJKE KPN N.V.: Un método para determinar un indicador de calidad que representa una calidad percibida de una señal de salida de un sistema de audio con respecto a una señal de referencia, […]
Método, producto de programa de ordenador y sistema para determinar una calidad percibida de un sistema de audio, del 24 de Diciembre de 2014, de KONINKLIJKE KPN N.V.: Un método para determinar un indicador de calidad que representa una calidad percibida de una señal de salida de un sistema de audio con respecto a una señal de referencia, […]
Aparato y método para modificar una señal de audio de entrada, del 3 de Diciembre de 2014, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un aparato para modificar una señal de audio de entrada, que comprende: un determinador de la excitación configurado para determinar un valor de un parámetro […]
Método, producto de programa informático y sistema para determinar una calidad percibida de un sistema de audio, del 8 de Octubre de 2014, de KONINKLIJKE KPN N.V.: Método para determinar un indicador de calidad que representa una calidad percibida de una señal de salida de un dispositivo de audio, con respecto a una señal de referencia, […]