Indexación escalable en una memoria de acceso no uniforme.
Un método de adaptar un proceso de indexación de acceso uniforme con una memoria flash NAND de acceso no uniforme (26,
235), incluyendo el método:
a) almacenar un diccionario de registros de índice en la memoria de acceso no uniforme (26), incluyendo los registros de índice claves de índice;
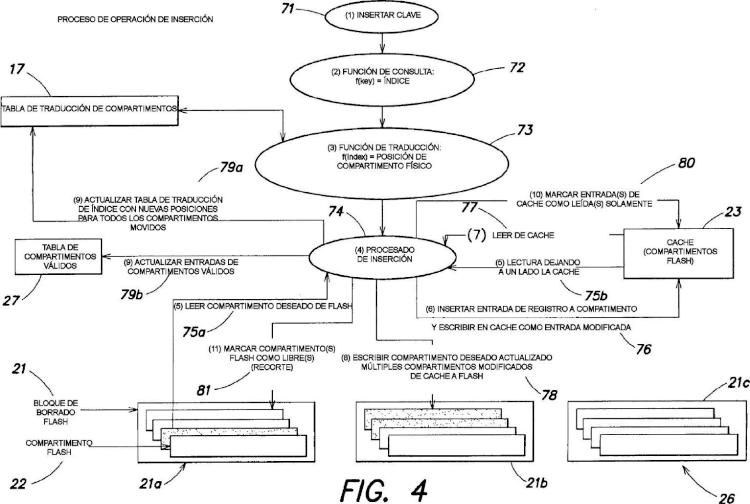
b) mantener una tabla de traducción de compartimentos (17, 300) para mapear identificadores de compartimento lógicos a posiciones de compartimento físico de la memoria (26) incluyendo generar un identificador de compartimento lógico por el hashing de desplazamiento de una clave de índice (141) e incluyendo la tabla un mapeado del identificador de compartimento lógico a una posición de compartimento físico (22, 309) de la memoria (26) donde se almacena el registro de índice asociado (310, 311, 312);
c) recoger en cache (23) una pluralidad de compartimentos, donde cada compartimento incluye un conjunto de registros de índice que tiene el mismo identificador de compartimento lógico antes de escribir la colección de compartimentos de la cache en posiciones de compartimento físico contiguas de la memoria (26) como una escritura secuencial; y
d) actualizar la tabla de traducción de compartimentos (17) con las posiciones de compartimento físico para los compartimentos de la colección escrita desde la cache a la memoria (26).
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/US2010/039966.
Solicitante: Simplivity Corporation.
Nacionalidad solicitante: Estados Unidos de América.
Dirección: 8 Technology Drive Westborough, MA 01581-1756 ESTADOS UNIDOS DE AMERICA.
Inventor/es: BOWDEN,PAUL, BEAVERSON,ARTHUR J.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G06F12/02 FISICA. › G06 CALCULO; CONTEO. › G06F PROCESAMIENTO ELECTRICO DE DATOS DIGITALES (sistemas de computadores basados en modelos de cálculo específicos G06N). › G06F 12/00 Acceso, direccionamiento o asignación en sistemas o arquitecturas de memoria (entrada digital a partir de, o salida digital hacia soportes de registro, p. ej. hacia unidades de almacenamiento de disco G06F 3/06). › Direccionamiento o asignación; Traslado (secuenciación de direcciones de programa G06F 9/00; disposiciones para seleccionar una dirección en una memoria digital G11C 8/00).
- G06F12/08 G06F 12/00 […] › en sistemas de memorias jerárquicas, p. ej. sistemas de memoria virtual.
- G06F12/10 G06F 12/00 […] › Traducción de direcciones.
- G06F17/30
PDF original: ES-2548194_T3.pdf
Fragmento de la descripción:
Indexación escalable en una memoria de acceso no uniforme Campo de la invención La presente invención se refiere a métodos y aparatos para la construcción de un índice que escala a gran número de registros y proporciona una alta tasa de transacciones.
Antecedentes Algunos sistemas de archivo modernos usan objetos para almacenar datos de archivo y otras estructuras internas del sistema de archivo ("metadatos") . Un archivo se descompone en muchos objetos pequeños, tal vez de sólo 4 KB (2^12 bytes) . Para un sistema de archivo que abarca 64 TB (2^46 bytes) , por ejemplo, esto da lugar a más de 2^ (4612) = 2^34, o aproximadamente 16 miles de millones de objetos cuya pista seguir.
En este contexto un objeto es una secuencia de datos binarios y tiene un nombre de objeto, a menudo una GUID (ID globalmente única) , o un hash criptográfico del contenido, aunque otras convenciones de denominación son posibles a condición de que cada objeto único tenga un nombre único. Los nombres de objeto suelen ser cadenas binarias de longitud fija destinadas al uso por programas, en contraposición a personas. Los tamaños de objeto son arbitrarios, pero en la práctica son normalmente potencias de 2 y son del rango de 512 bytes (2^9) hasta 1MB (2^20) . En este contexto los objetos no deberán confundirse con los objetos usados en lenguajes de programación tal como Java y C++.
El sistema de archivo necesita un índice (a veces denominado un diccionario o catálogo) de todos los objetos. Cada registro en el índice puede contener el nombre de objeto, la longitud, la posición y otra información variada. El índice puede tener como su clave primaria el nombre de objeto, la posición del objeto, o posiblemente ambos. Un registro es del orden de unas pocas decenas de bytes, siendo 32 bytes un ejemplo.
Las operaciones en este índice incluyen añadir una entrada, consultar una entrada, hacer modificaciones en la entrada, y borrar una entrada. Todas éstas son operaciones normales realizadas en cualquier índice.
Dado que estos sistemas de archivo operan con objetos, para que el sistema de archivo logre niveles de rendimiento aceptables, una solución de indexación tiene dos retos que no se cumplen fácilmente:
1) El número de entradas en el índice puede ser muy grande. En el ejemplo enumerado anteriormente, si cada entrada de índice es 32 (2^5) bytes, entonces el índice ocupa 2^ (5+34) = 2^39, o 512 GB de memoria. Esto no encaja en el costo efectivamente de las tecnologías de memoria actuales.
2) Las operaciones contra el índice son grandes. Un sistema de almacenamiento comercialmente viable puede tener que funcionar a, por ejemplo, 256 MB/s (2^28 bytes/segundo) . En tamaños de objeto de 4 KB, eso es 2^28-12) = 2^16, o 64 mil operaciones por segundo. Dado que los sistemas de archivo generan y referencian normalmente otros datos (objetos) internamente, la tasa operativa del índice puede exceder fácilmente de 100 mil operaciones/segundo. Como punto de comparación, un disco del estado actual de la técnica puede efectuar a lo sumo 400 operaciones por segundo.
Lograr los niveles necesarios de rendimiento y capacidad no es posible usando tecnología de memoria DRAM, o tecnología de disco, solas. La memoria DRAM es suficientemente rápida, pero no suficientemente densa. Los discos tienen la densidad, pero no el rendimiento. Escalar uno (la memoria DRAM o los discos) para lograr las características deseadas es demasiado caro.
Los nombres de objeto son a menudo uniformes tanto en su distribución como en sus configuraciones de acceso, de modo que los esquemas de cache normales, que dependen de localidad espacial y temporal, tienen un efecto limitado. Así, el problema de la indexación es difícil tanto en el tamaño como en las tasas de operación.
Un documento titulado: "An efficient Hash Index Structure for Solid State Disks", del que son autores Hongehan Roh y Sanghyun Park, propone una estructura de índice hash eficiente para SSDs que resuelve los inconvenientes SSDs y mejora su rendimiento. Una memoria intermedia que está estrechamente acoplada con el índice hash acumula peticiones de actualización de índice y se aplica una política de borrado de base log al índice.
Resumen de la invención Un método de adaptar un acceso uniforme y su proceso de indexación con una memoria flash NAND de acceso no uniforme se reivindica en la reivindicación independiente 1. Un sistema informático se reivindica en la reivindicación independiente 19.
En una realización, el método incluye: leer una o más entradas de datos de registro secuenciales de la memoria a la cache;
designar como libres las posiciones físicas en memoria de la que se leyó la una o más entradas. En una realización, el método incluye: presentar una pluralidad de posiciones de compartimento físico secuenciales en la memoria como un bloque libre leyendo cualesquiera entradas válidas en el bloque a la cache y designar como libres las posiciones físicas en memoria de la que se leyeron tales entradas. En una realización: 15 el proceso de indexación genera peticiones de acceso aleatorio al índice en base a claves de índice uniformemente distribuidas y únicas. En una realización: 20 las claves incluyen compendios de hash criptográfico. En una realización: el proceso de indexación incluye un proceso de hashing de desplazamiento. 25 En una realización: el hashing de desplazamiento incluye un proceso de hashing de Cuckoo.
En una realización: la memoria está limitada por uno o varios del tiempo de acceso a escritura aleatorio, tiempo de acceso a lecturamodificación-escritura aleatorio, escritura secuencial, restricciones de alineación, tiempo de borrado, límites y desgaste de bloque de borrado.
En una realización: un tamaño del compartimento físico incluye un tamaño de escritura mínimo de la memoria. 40 En una realización: el tamaño del compartimento físico incluye una página o página parcial. En una realización: 45 la memoria tiene un bloque de borrado incluyendo una pluralidad de páginas. En una realización el método incluye: 50 mantener una tabla de compartimentos válidos para hacer el seguimiento de qué posiciones de compartimento en la memoria son válidas. En una realización: 55 un compartimento en memoria incluye un conjunto de una o más entradas de datos de registro y un autoíndice a la tabla de traducción de compartimentos. En una realización: 60 las entradas de datos de registro en el compartimento no están ordenadas. En una realización: la entrada de datos de registro incluye campos para una clave, un recuento de referencias y una dirección de bloque 65 físico.
En una realización: la clave incluye un compendio de datos de hash criptográfico; el campo de dirección de bloque físico contiene un indicador a la dirección de bloque físico de los datos almacenados en un dispositivo de almacenamiento. En una realización: las posiciones de compartimento lógicas son generadas por una pluralidad de funciones hash. En una realización: la memoria incluye una pluralidad de bloques de borrado, cada bloque de borrado incluye una pluralidad de páginas, y cada página incluye una pluralidad de compartimentos.
Según otra realización de la invención, se facilita un producto de programa de ordenador incluyendo un medio de código de programación que, cuando es ejecutado por un procesador, realiza los pasos del método anterior. En una realización el método incluye: designar como leídas solamente en cache las entradas de datos de registro escritas secuencialmente en la memoria. En una realización: la tabla de traducción de compartimentos se almacena en memoria persistente. En una realización, el método incluye: rastrear el número de compartimentos libres en un bloque de borrado e implementar un proceso para generar un bloque de borrado libre cuando se cumple un umbral de compartimentos libres. En una realización: el proceso de indexación realiza operaciones de indexación en base a peticiones de que los registros sean insertados, borrados, consultados y/o modificados. En una realización: el proceso de indexación presenta operaciones de compartimento lógico para leer y escribir a compartimentos físicos que almacenan los registros del índice. En una realización: las operaciones de compartimento físico incluyen lecturas aleatorias y escrituras secuenciales. En una realización: las operaciones de compartimento físico incluyen además órdenes de recorte. En una realización: la memoria incluye una capa de dispositivo físico caracterizada por acceso de lectura y escritura no uniforme e inmutabilidad con respecto al tamaño, la alineación y la temporización.
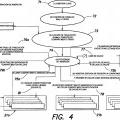
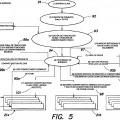
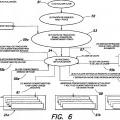
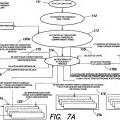
Breve descripción de los dibujos La invención se entenderá más plenamente por referencia... [Seguir leyendo]
Reivindicaciones:
1. Un método de adaptar un proceso de indexación de acceso uniforme con una memoria flash NAND de acceso no uniforme (26, 235) , incluyendo el método:
a) almacenar un diccionario de registros de índice en la memoria de acceso no uniforme (26) , incluyendo los registros de índice claves de índice;
b) mantener una tabla de traducción de compartimentos (17, 300) para mapear identificadores de compartimento lógicos a posiciones de compartimento físico de la memoria (26) incluyendo generar un identificador de compartimento lógico por el hashing de desplazamiento de una clave de índice (141) e incluyendo la tabla un mapeado del identificador de compartimento lógico a una posición de compartimento físico (22, 309) de la memoria (26) donde se almacena el registro de índice asociado (310, 311, 312) ;
c) recoger en cache (23) una pluralidad de compartimentos, donde cada compartimento incluye un conjunto de registros de índice que tiene el mismo identificador de compartimento lógico antes de escribir la colección de compartimentos de la cache en posiciones de compartimento físico contiguas de la memoria (26) como una escritura secuencial; y d) actualizar la tabla de traducción de compartimentos (17) con las posiciones de compartimento físico para los compartimentos de la colección escrita desde la cache a la memoria (26) .
2. El método de la reivindicación 1, incluyendo: leer uno o más registros de índice secuenciales desde la memoria (26, 23) a la cache; designar como libres las posiciones físicas en memoria (26) de la que se lee el uno o varios registros de índice.
3. El método de la reivindicación 1, incluyendo:
presentar una pluralidad de posiciones de compartimento físico secuenciales (22, 309) de la memoria como un bloque libre leyendo cualesquiera registros de índice válidos en el bloque a la cache y designar como libres las posiciones físicas de la memoria de la que se leyeron tales registros de índice.
4. El método de la reivindicación 1, donde:
generar una pluralidad de identificadores de compartimento lógicos para la clave de índice, donde la función hashing de desplazamiento selecciona de entre la pluralidad de identificadores de compartimento lógicos generados.
5. El método de la reivindicación 1, donde:
la memoria está limitada por uno o varios de tiempo de acceso a escritura aleatorio, tiempo de acceso de lecturamodificación-escritura aleatorio, escritura secuencial, restricciones de alineación, tiempo de borrado, límites y desgaste de bloque de borrado.
6. El método de la reivindicación 1, donde:
el tamaño de compartimento es una función del tamaño de escritura mínimo de la memoria tal como una página o página parcial.
7. El método de la reivindicación 6, donde: la memoria tiene un bloque de borrado incluyendo una pluralidad de páginas.
8. El método de la reivindicación 1, incluyendo:
mantener una tabla de compartimentos válidos (271) para rastrear qué posiciones de compartimento físico de la memoria son válidas.
9. El método de la reivindicación 1, donde:
cada posición de compartimento físico (23) de la memoria incluye con el conjunto de registros de índice un autoíndice en la tabla de traducción de compartimentos.
10. El método de cualquier reivindicación precedente, donde:
los registros de índice del compartimento no están ordenados.
11. El método de la reivindicación 1, donde: la tabla de traducción de compartimentos está almacenada en una memoria persistente.
12. El método de la reivindicación 1, incluyendo:
rastrear el número de posiciones de compartimento físico libres en un bloque de borrado e implementar un proceso para generar un bloque de borrado libre cuando se encuentra un umbral de posiciones de compartimento libres.
13. El método de la reivindicación 1, donde:
el proceso de indexación realiza operaciones de indexación en base a peticiones de que los registros de índice sean insertados, borrados, consultados y/o modificados.
14. El método de la reivindicación 1, donde:
el proceso de indexación presenta operaciones de compartimento lógico para leer y escribir a posiciones de compartimento físico que almacenan los registros de índice.
15. El método de la reivindicación 1, donde:
la memoria flash NAND (26) incluye una pluralidad de bloques de borrado, incluyendo cada bloque de borrado una pluralidad de páginas, e incluyendo cada página una pluralidad de compartimentos.
16. El método de la reivindicación 15, incluyendo:
generar bloques de borrado libres leyendo compartimentos adicionales en la cache en respuesta a operaciones de lectura aleatorias.
17. El método de la reivindicación 15, incluyendo:
realizar un proceso de rebusca (114) para generar bloques de borrado libres leyendo bloques de borrado en la cache.
18. Un producto de programa de ordenador incluyendo un medio de código de programa que, cuando es ejecutado por un procesador, realiza los pasos de método de la reivindicación 1.
19. Un sistema informático incluyendo:
una memoria flash NAND de acceso no uniforme (26) conteniendo un diccionario de registros de índice almacenados en posiciones de compartimento físico de la memoria;
una tabla de traducción de compartimentos (17) que mapea un identificador de compartimento lógico, generado por hashing de desplazamiento de una clave de índice del diccionario, a una posición de compartimento físico de la memoria (26) donde está almacenado un registro de índice (310, 311, 312) asociado con la clave de índice;
una cache (23) para recoger compartimentos, incluyendo cada compartimento un conjunto de registros de índice que tiene el mismo identificador de compartimento lógico a escribir a la memoria;
un medio para acceder a (18) posiciones de compartimento físico de la memoria (26) mapeadas a identificadores de compartimento lógicos suministrados a la tabla de traducción de compartimentos por un proceso de indexación de acceso uniforme;
un medio para escribir (24) secuencialmente una colección de los compartimentos de la cache en posiciones de compartimento físico contiguas de la memoria (26) ; y un medio para actualizar (19) la tabla de traducción de compartimentos (17) con las posiciones de compartimento físico para los compartimentos de la colección.
20. El sistema de la reivindicación 19, donde:
la memoria (26) que guarda el índice incluye una capa de dispositivo físico caracterizado por acceso de lectura y escritura no uniforme e inmutabilidad con respecto al tamaño, la alineación y la temporización.
21. El sistema de la reivindicación 19, donde:
la memoria flash NAND (26) que guarda el índice incluye una pluralidad de bloques de borrado, cada bloque de borrado incluye una pluralidad de páginas, y cada página incluye una pluralidad de compartimentos.
Patentes similares o relacionadas:
Almacenamiento de datos gráficos comprimidos en ancho de banda, del 6 de Noviembre de 2019, de QUALCOMM INCORPORATED: Un procedimiento, que comprende: almacenar, mediante al menos un procesador, una pluralidad de datos gráficos comprimidos en ancho de banda en una pluralidad respectiva […]
Método de procesado de datos, aparato de almacenamiento, disco de estado sólido y sistema de almacenamiento, del 28 de Agosto de 2019, de HUAWEI TECHNOLOGIES CO., LTD.: Un método de procesado de datos, aplicado a un sistema de almacenamiento, en donde el sistema de almacenamiento comprende un anfitrión, un controlador y un […]
Gestión de memoria automática que usa una unidad de gestión de memoria, del 24 de Julio de 2019, de aicas GmbH: Método implementado por ordenador , para actuar sobre un módulo automático de gestión de memoria en un sistema informático que tiene una memoria de acceso […]
Uso de compresión de memoria para reducir la carga de compromiso de memoria, del 6 de Mayo de 2019, de Microsoft Technology Licensing, LLC: Un método de reducir una cantidad de compromiso de memoria para un programa en un dispositivo de cálculo , comprendiendo el método: determinar […]
Controlador de acceso a memoria, sistemas y procedimientos para optimizar los tiempos de acceso a memoria, del 9 de Enero de 2019, de QUALCOMM INCORPORATED: Un controlador de memoria , que comprende: un controlador configurado para acceder al menos a una ubicación de memoria correspondiente […]
Sistema de gestión de datos y método, del 30 de Noviembre de 2018, de LIFESCAN SCOTLAND LIMITED: Un sistema de gestión de datos que comprende: - una primera sección de memoria no volátil dividida en una pluralidad de ubicaciones […]
Método de obtención anticipada de datos para un sistema de almacenamiento de tabla hash distribuida DHT, nodo y sistema, del 21 de Noviembre de 2018, de HUAWEI TECHNOLOGIES CO., LTD.: Un método de obtención anticipada de datos para un sistema de almacenamiento de tabla hash distribuida DHT que comprende un primer nodo de almacenamiento y un segundo […]
Método de gestión de la asignación de memoria flash en un token electrónico, del 27 de Diciembre de 2017, de GEMALTO SA: Un método para gestionar la asignación de memoria flash en un token electrónico (ET), disponiendo dicho token (ET) de una memoria (ME) que comprende […]