Encaminamiento de consulta en un sistema de base de datos distribuida.
Método, que comprende:
recibir (S221; S331) un mensaje de consulta en un primer servidor de una pluralidad de servidores de unprimer tipo de servidor;
transformar (S222; S332) al menos parte de los datos contenidos en el mensaje de consulta en unresultado de transformación;
determinar (S223; S333), basándose en el resultado de transformación y en una primera tabla de búsquedaen dicho primer servidor, una ubicación de almacenamiento de una respectiva segunda tabla de búsquedaen uno de dicha pluralidad de servidores de dicho primer tipo,
acceder (S225, S228; S335, S338) a la respectiva segunda tabla de búsqueda en la ubicación dealmacenamiento determinada de la respectiva segunda tabla de búsqueda en uno de dicha pluralidad deservidores de dicho primer tipo, y
recuperar (S225, S228; S335, S338) un indicador que indica una ubicación de almacenamiento de los datossolicitados por el mensaje de consulta a partir de la respectiva segunda tabla de búsqueda,indicando la primera tabla de búsqueda, para cada resultado de transformación, cuál de dicha pluralidad deservidores de dicho primer tipo es responsable de los datos solicitados por el mensaje de consulta,comprendiendo la respectiva segunda tabla de búsqueda en un servidor del primer tipo de servidor almenos un par de datos, que incluyen, para cada resultado de transformación, un puntero que indica unaubicación de los datos almacenados en un servidor de un segundo tipo de servidor, siendo la respectivasegunda tabla de búsqueda en un servidor del primer tipo de servidor, parte de una segunda tabla debúsqueda completa, y
siendo los servidores del primer tipo de servidor, servidores front-end que no almacenan los datossolicitados por el mensaje de consulta, y siendo los servidores del segundo tipo de servidor, servidoresback-end que almacenan los datos solicitados por el mensaje de consulta.
Tipo: Patente Europea. Resumen de patente/invención. Número de Solicitud: E07150067.
Solicitante: NOKIA SIEMENS NETWORKS OY.
Nacionalidad solicitante: Finlandia.
Dirección: KARAPORTTI 3 02610 ESPOO FINLANDIA.
Inventor/es: ANDERSEN, FRANK-UWE, SCHEIDL, WOLFGANG, Hoßfeld,Tobias, Neitzert,Gerald, Oechsner,Simon, Schoen,Hans-Ulrich, Tran-Gia,Phuoc, Tutschku,Kurt.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- H04L29/08 ELECTRICIDAD. › H04 TECNICA DE LAS COMUNICACIONES ELECTRICAS. › H04L TRANSMISION DE INFORMACION DIGITAL, p. ej. COMUNICACION TELEGRAFICA (disposiciones comunes a las comunicaciones telegráficas y telefónicas H04M). › H04L 29/00 Disposiciones, aparatos, circuitos o sistemas no cubiertos por uno solo de los grupos H04L 1/00 - H04L 27/00. › Procedimiento de control de la transmisión, p. ej. procedimiento de control del nivel del enlace.
- H04L29/12 H04L 29/00 […] › caracterizados por el terminal de datos.
PDF original: ES-2387625_T3.pdf
Fragmento de la descripción:
Encaminamiento de consulta en un sistema de base de datos distribuida.
Campo de la invención
La presente invención se refiere a métodos y servidores aplicables en sistemas de servidor de aplicación o base de datos distribuida, en particular en una capa front-end de tales sistemas.
Antecedentes de la invención
En un sistema de base de datos distribuida los datos se ubican no sólo en uno sino en varios servidores de base de datos diferentes. Se requiere un sistema de búsqueda con el fin de poder encaminar las consultas para un elemento de datos específico a un servidor de base de datos denominado servidor de base de datos back-end que almacena este elemento. Los punteros a estos servidores de base de datos back-end se almacenan en el sistema de búsqueda que también se denomina sistema front-end. Estos punteros son generalmente del formato <clave, valor>, donde la clave es una clave de búsqueda válida para un servidor de base de datos back-end, y el valor es una dirección del servidor de base de datos back-end en la que se ubica el correspondiente elemento de datos. Por tanto, cuando se emite una consulta, por ejemplo, una orden de LDAP (protocolo ligero de acceso al directorio) , a un sistema de base de datos distribuida, se resuelve en primer lugar en el sistema front-end (que está constituido por servidores front-end, también denominados a continuación en el presente documento servidores de un primer tipo de servidor) , y luego se reenvían a la dirección correcta en el sistema back-end (que está constituido por servidores back-end, también denominados a continuación en el presente documento servidores de un segundo tipo de servidor) , donde puede procesarse.
Recientemente, existe la tendencia en el diseño de sistemas de bases de datos de redes móviles de crear una sola base de datos lógica que físicamente se ejecuta en múltiples servidores y también unifica diferentes tipos de bases de datos, por ejemplo, HLR (registro de ubicación local) , RADIUS (servidor de autenticación remota de marcación de usuario) , DB de OAM (base de datos de operación y mantenimiento) , DB de NM (base de datos de gestión de red) , etc.
En los sistemas front-end de base de datos distribuida convencionales, los punteros descritos anteriormente se guardan en todos los nodos que constituyen el sistema front-end.
El documento US 6.351.775 B1 da a conocer un equilibrio de carga por los servidores en una red informática, en la que, para el encaminamiento dinámico de peticiones de objeto, un método de partición puede mapear los identificadores de objeto con clases y los nodos solicitantes mantienen una tabla de asignación de servidor para mapear cada clase con una selección de servidor.
Sumario de la invención
La invención pretende proporcionar un encaminamiento de consultas de base de datos eficaz en memoria, en un sistema de base de datos distribuida.
Esto se logra mediante métodos y servidores tal como se definen en las reivindicaciones adjuntas. La invención también puede implementarse como un producto de programa informático.
Según la invención, en lugar de almacenar una tabla de búsqueda completa (es decir, una recopilación de punteros, que indiquen dónde se ubican los elementos de datos en dispositivos de servidor back-end) en cada dispositivo de servidor front-end, cada dispositivo de servidor front-end sólo necesita mantener una parte de la tabla de búsqueda (denominada una respectiva segunda tabla de búsqueda) y una “tabla de partición” (denominada una primera tabla de búsqueda) que indica qué dispositivo de servidor front-end es responsable de qué sección de datos almacenada en los dispositivos de servidor back-end, es decir, qué parte de la tabla de búsqueda se ubica en qué dispositivo de servidor front-end.
Según una realización de la invención, se recibe un mensaje de consulta por un dispositivo de servidor front-end que se denomina un primer dispositivo. A parte de los datos en el mensaje de consulta se les aplica un hash en el primer dispositivo de servidor. Comparando el resultado de la aplicación de un hash y la tabla de partición (primera tabla de búsqueda) , el primer dispositivo de servidor detecta dónde se ubica un puntero de datos solicitados.
Si el puntero de los datos solicitados se ubica en el primer dispositivo de servidor, envía una petición a un dispositivo de servidor back-end indicado por el puntero para extraer los datos.
Si el puntero de los datos solicitados no está ubicado en el primer dispositivo de servidor, según la tabla de partición, el primer dispositivo conoce el dispositivo de servidor front-end correcto (segundo dispositivo de servidor) que contiene el puntero de los datos solicitados. El primer dispositivo de servidor en tal caso reenvía el mensaje de consulta al segundo dispositivo de servidor.
El segundo dispositivo de servidor resuelve el mensaje de consulta sustancialmente de la misma forma que el primer dispositivo (pero sin consultar la primera tabla de búsqueda en el segundo servidor) y devuelve el puntero de los datos solicitados al primer dispositivo.
El primer dispositivo de servidor envía entonces una petición a un servidor back-end indicado por el puntero y extrae los datos.
El primer dispositivo de servidor contesta al mensaje de consulta con los datos solicitados.
Según la presente invención, en el peor de los casos, sólo se necesita un reenvío para ubicar los datos solicitados. Cada dispositivo de servidor front-end sólo necesita almacenar la tabla de partición y una parte de la tabla de búsqueda en lugar de la totalidad de la tabla de búsqueda, lo que ahorra bastante memoria.
La presente invención es útil especialmente en grandes escenarios de despliegue, en los que existe una gran cantidad de dispositivos de servidor front-end.
La presente invención puede aplicarse a una capa front-end de servicios o aplicaciones de base de datos a gran escala. Las consultas de aplicación destinadas a una capa back-end que contiene conjuntos de datos solicitados o una lógica de servicio se envían a través de la capa front-end con el fin de distribuir la carga, procesar previamente los datos o encaminar consultas según la disposición física del sistema back-end.
En una aplicación crítica en el tiempo, por ejemplo, el acceso a datos de usuario móvil como un proveedor, la cantidad de tiempo invertido en los dispositivos de servidor de la capa front-end debe ser lo más corta posible. Por tanto, los datos de búsqueda (contenidos en la primera y/o respectiva segunda tabla de búsqueda) se almacenan en la memoria de acceso aleatorio (RAM) de un respectivo dispositivo de servidor front-end, desde la que puede accederse más rápido en comparación con un escenario en el que se almacenan en un disco duro.
Esto hace que las limitaciones de hardware, es decir, con cuánta memoria puede equiparse un servidor, sean un problema. Con la cantidad de datos almacenada en el back-end, el número de entradas de búsqueda en el front-end también aumenta. Lo mismo se aplica para un número superior de claves de búsqueda. Por tanto, la cantidad de datos de búsqueda puede volverse demasiado grande para su almacenamiento en un único servidor.
Un servidor front-end según la presente invención sólo necesita almacenar una pequeña tabla, es decir, una primera tabla de búsqueda que indique qué servidor front-end es responsable de qué sección de datos almacenada en los servidores back-end, y una parte de los datos de búsqueda en una respectiva segunda tabla de búsqueda. Por tanto, la invención puede hacer frente a aplicaciones críticas en el tiempo en grandes escenarios de despliegue.
Breve descripción de los dibujos
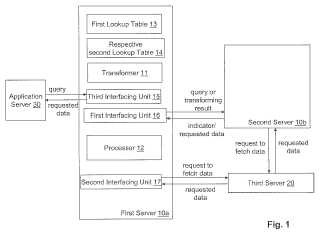
La figura 1 muestra un diagrama de bloques esquemático que ilustra una disposición de un sistema según una realización de la invención.
La figura 2 que consiste en las figuras 2A y 2B muestra un diagrama de flujo que ilustra un método de consulta de base de datos según una realización de la invención.
La figura 3 muestra un diagrama de flujo que ilustra un método de consulta de base de datos según otra realización de la invención.
La figura 4 muestra el mapeo entre secciones de datos almacenados en dispositivos de servidor back-end y dispositivos de servidor front-end según una realización de la invención.... [Seguir leyendo]
Reivindicaciones:
1. Método, que comprende:
recibir (S221; S331) un mensaje de consulta en un primer servidor de una pluralidad de servidores de un primer tipo de servidor;
transformar (S222; S332) al menos parte de los datos contenidos en el mensaje de consulta en un resultado de transformación;
determinar (S223; S333) , basándose en el resultado de transformación y en una primera tabla de búsqueda en dicho primer servidor, una ubicación de almacenamiento de una respectiva segunda tabla de búsqueda en uno de dicha pluralidad de servidores de dicho primer tipo,
acceder (S225, S228; S335, S338) a la respectiva segunda tabla de búsqueda en la ubicación de almacenamiento determinada de la respectiva segunda tabla de búsqueda en uno de dicha pluralidad de servidores de dicho primer tipo, y
recuperar (S225, S228; S335, S338) un indicador que indica una ubicación de almacenamiento de los datos solicitados por el mensaje de consulta a partir de la respectiva segunda tabla de búsqueda,
indicando la primera tabla de búsqueda, para cada resultado de transformación, cuál de dicha pluralidad de servidores de dicho primer tipo es responsable de los datos solicitados por el mensaje de consulta,
comprendiendo la respectiva segunda tabla de búsqueda en un servidor del primer tipo de servidor al menos un par de datos, que incluyen, para cada resultado de transformación, un puntero que indica una ubicación de los datos almacenados en un servidor de un segundo tipo de servidor, siendo la respectiva segunda tabla de búsqueda en un servidor del primer tipo de servidor, parte de una segunda tabla de búsqueda completa, y
siendo los servidores del primer tipo de servidor, servidores front-end que no almacenan los datos solicitados por el mensaje de consulta, y siendo los servidores del segundo tipo de servidor, servidores back-end que almacenan los datos solicitados por el mensaje de consulta.
2. Método según la reivindicación 1, que comprende
llevar a cabo el acceso al primer servidor (S225; S335) , si dicha determinación arroja que la ubicación de almacenamiento de la respectiva segunda tabla de búsqueda está en dicho primer servidor.
3. Método según la reivindicación 1, que comprende
reenviar (S228; S338) el resultado de transformación o el mensaje de consulta del primer servidor a un segundo servidor del primer tipo de servidor diferente del primer servidor, si dicha determinación arroja que la ubicación de almacenamiento de la respectiva segunda tabla de búsqueda está en el segundo servidor.
4. Método según la reivindicación 3, que comprende
recibir en el primer servidor del primer tipo de servidor, el indicador recuperado del segundo servidor del primer tipo de servidor, tras el acceso a la segunda tabla de búsqueda en el segundo servidor basándose en el resultado de transformación o el mensaje de consulta reenviado.
5. Método según la reivindicación 3, que comprende
recibir en el primer servidor, los datos solicitados por el mensaje de consulta, del segundo servidor del primer tipo de servidor tras el acceso a un servidor de una pluralidad de servidores de un segundo tipo de servidor basándose en el indicador recuperado partiendo del mensaje de consulta.
6. Método, que comprende
recibir (S228; S338) , en un segundo servidor de un primer tipo de servidor a partir de un primer servidor de una pluralidad de servidores del primer tipo de servidor, un mensaje de consulta o un resultado de transformación basándose en al menos parte de los datos contenidos en el mensaje de consulta;
concluir (S230) , basándose en la recepción del mensaje de consulta o el resultado de transformación, que una ubicación de almacenamiento de una respectiva segunda tabla de búsqueda está en el segundo servidor,
acceder (S231; S339) a la segunda tabla de búsqueda en el segundo servidor de dicho primer tipo, y
recuperar (S231; S339) un indicador que indica una ubicación de almacenamiento de los datos solicitados por el mensaje de consulta a partir de la segunda tabla de búsqueda,
comprendiendo la respectiva segunda tabla de búsqueda en un servidor del primer tipo de servidor al menos un par de datos, que incluyen, para cada mensaje de consulta o resultado de transformación, un puntero que indica una ubicación de los datos almacenados en un servidor de un segundo tipo de servidor, siendo la respectiva segunda tabla de búsqueda en un servidor del primer tipo de servidor, parte de una segunda tabla de búsqueda completa, y
siendo los servidores del primer tipo de servidor, servidores front-end que no almacenan los datos solicitados por el mensaje de consulta, y siendo los servidores del segundo tipo de servidor, servidores back-end que almacenan los datos solicitados por el mensaje de consulta.
7. Método según la reivindicación 6, que comprende además
transformar (S229) al menos parte de los datos contenidos en el mensaje de consulta en un resultado de transformación, en caso de que se reciba el mensaje de consulta.
8. Método según la reivindicación 6, que comprende
devolver (S233; S340) el indicador recuperado del segundo servidor del primer tipo de servidor al primer servidor del primer tipo de servidor.
9. Método según la reivindicación 1, en el que las respectivas segundas tablas de búsqueda de cada servidor del primer tipo de servidor son iguales entre sí en cuanto al tamaño, o diferentes entre sí en cuanto al tamaño
en proporción a una respectiva capacidad de procesamiento de cada uno de dichos servidores, o
de tal manera que una carga de procesamiento para cada uno de los servidores del primer tipo de servidor sean iguales entre sí.
10. Método según la reivindicación 1, en el que la primera tabla de búsqueda comprende al menos un par de datos, comprendiendo cada par de datos
una dirección de un servidor del primer tipo de servidor y un intervalo de valores definido por un valor de inicio y un valor de fin, en un espacio en el que se transforma la parte de los datos en el mensaje de consulta.
11. Método según la reivindicación 10, en el que
los servidores del primer tipo de servidor son servidores front-end y dicha dirección es una dirección IP de los respectivos servidores.
12. Método según la reivindicación 1 ó 7, en el que dicha transformación comprende mapear una cadena con un número entero natural.
13. Método según la reivindicación 10, en el que dicho espacio es un espacio de Hash que resulta de la transformación mediante una transformada de Hash.
14. Servidor (10a) , que comprende:
una unidad (15) de interfaz configurada para recibir un mensaje de consulta;
un transformador (11) configurado para transformar al menos parte de los datos contenidos en el mensaje de consulta en un resultado de transformación;
una primera tabla (13) de búsqueda que indica, para cada resultado de transformación, cuál de una pluralidad de servidores de un primer tipo es responsable de los datos solicitados por el mensaje de consulta;
una respectiva segunda tabla (14) de búsqueda que comprende al menos un par de datos, que incluyen, para cada resultado de transformación, un puntero que indica una ubicación de los datos almacenados en un servidor de un segundo tipo de servidor; y
un procesador (12) configurado para
determinar, basándose en el resultado de transformación y en una primera tabla de búsqueda, una ubicación de almacenamiento de una respectiva segunda tabla de búsqueda en uno de una pluralidad de servidores de un primer tipo de servidor,
acceder a la respectiva segunda tabla de búsqueda en la ubicación de almacenamiento determinada de la respectiva segunda tabla de búsqueda en uno de dicha pluralidad de servidores de dicho primer tipo, y
recuperar un indicador que indica una ubicación de almacenamiento de los datos solicitados por el mensaje de consulta a partir de la segunda tabla de búsqueda,
siendo la respectiva segunda tabla de búsqueda parte de una segunda tabla de búsqueda completa, y
siendo el servidor, un servidor front-end como un servidor del primer tipo de servidor que no almacena los datos solicitados por el mensaje de consulta, y siendo los servidores del segundo tipo de servidor, servidores back-end que almacenan los datos solicitados por el mensaje de consulta.
15. Servidor según la reivindicación 14, que comprende
una unidad (16) de interfaz configurada para reenviar el resultado de transformación o el mensaje de consulta a otro servidor de la pluralidad de servidores, si dicho procesador determina que la ubicación de almacenamiento de la respectiva segunda tabla de búsqueda no está en el servidor.
16. Servidor según la reivindicación 15, en el que la unidad (16) de interfaz está configurada para recibir el indicador recuperado del otro servidor.
17. Servidor según la reivindicación 15, en el que
la unidad (16) de interfaz está configurada para recibir los datos solicitados por el mensaje de consulta del otro servidor.
18. Servidor según la reivindicación 14, que comprende
una unidad de interfaz configurada para enviar el indicador recuperado o los datos solicitados por el mensaje de consulta a otro servidor.
19. Servidor (10b) , que comprende
una unidad de interfaz configurada para recibir, desde otro servidor de una pluralidad de servidores de un primer tipo de servidor, un mensaje de consulta o un resultado de transformación basándose en al menos parte de los datos contenidos en el mensaje de consulta;
una primera tabla de búsqueda que indica, para cada resultado de transformación, cuál de una pluralidad de servidores de un primer tipo es responsable de los datos solicitados por el mensaje de consulta; una respectiva segunda tabla de búsqueda que comprende al menos un par de datos, que incluyen, para cada resultado de transformación, un puntero que indica una ubicación de los datos almacenados en un servidor de un segundo tipo de servidor; y
un procesador configurad para
concluir, basándose en la recepción del mensaje de consulta o el resultado de transformación, que una ubicación de almacenamiento de una respectiva segunda tabla de búsqueda está en el servidor,
acceder a la respectiva segunda tabla de búsqueda en el servidor, y
recuperar un indicador que indica una ubicación de almacenamiento de los datos solicitados por el mensaje de consulta a partir de la segunda tabla de búsqueda,
siendo la respectiva segunda tabla de búsqueda parte de una segunda tabla de búsqueda completa, y
siendo el servidor, un servidor front-end como un servidor del primer tipo de servidor que no almacena los datos solicitados por el mensaje de consulta, y siendo los servidores del segundo tipo de servidor, servidores back-end que almacenan los datos solicitados por el mensaje de consulta.
20. Servidor según la reivindicación 19, que comprende además un transformador configurado para transformar al menos parte de los datos contenidos en el mensaje de consulta en un resultado de transformación, en caso de que se reciba el mensaje de consulta.
21. Servidor según la reivindicación 19, en el que
la unidad de interfaz está configurada para devolver el indicador recuperado o los datos consultados por el mensaje de consulta, del servidor a otro servidor desde el que se recibió el mensaje de consulta o resultado de transformación.
22. Servidor según la reivindicación 14 ó 19, en el que el servidor es de un primer tipo de servidor, y en el que la respectiva segunda tabla de búsqueda comprende al menos un par de datos, que incluyen, para cada resultado de transformación, un puntero que indica una ubicación de los datos almacenados en un servidor de un segundo tipo de servidor, en el que las respectivas segundas tablas de búsqueda de todos los servidores del primer tipo de servidor constituyen una tabla de búsqueda completa.
23. Servidor según la reivindicación 22, en el que las respectivas segundas tablas de búsqueda de cada servidor del primer tipo de servidor son iguales entre sí en cuanto a tamaño, o diferentes entre sí en cuanto a tamaño
en proporción a una respectiva capacidad de procesamiento de cada uno de dichos servidores o
de tal manera que una carga de procesamiento para cada uno de los servidores del primer tipo de servidor sean iguales entre sí.
24. Servidor según la reivindicación 14 ó 19, en el que la primera tabla de búsqueda comprende al menos un par de datos, comprendiendo el par de datos
una dirección de servidores de un primer tipo de servidor y un intervalo de valores definido por un valor de inicio y un valor de fin, en un espacio en el que se transforma la parte de los datos en el mensaje de consulta.
25. Servidor según la reivindicación 24, en el que
los servidores del primer tipo de servidor son servidores front-end y dicha dirección es una dirección IP de los respectivos servidores.
26. Servidor según la reivindicación 14 ó 20, en el que dicho transformador está configurado para mapear una cadena con un número entero natural.
27. Servidor según la reivindicación 24, en el que dicho transformador está configurado para aplicar una transformada de Hash, y dicho espacio es un espacio de Hash que resulta de dicha transformada de Hash.
28. Programa informático que comprende instrucciones que pueden implementarse mediante procesador para realizar el método según una cualquiera de las reivindicaciones 1 a 13.
Patentes similares o relacionadas:
Procedimiento y dispositivo para el procesamiento de una solicitud de servicio, del 29 de Julio de 2020, de Advanced New Technologies Co., Ltd: Un procedimiento para el procesamiento de una solicitud de servicio, comprendiendo el procedimiento: recibir (S201), mediante un nodo de consenso, una solicitud […]
Transferencia automática segura de datos con un vehículo de motor, del 22 de Julio de 2020, de AIRBIQUITY INC: Un dispositivo electrónico en un vehículo para operar en un vehículo de motor en un estado de energía desatendido, comprendiendo el dispositivo […]
Método y aparato para configurar un identificador de dispositivo móvil, del 22 de Julio de 2020, de Advanced New Technologies Co., Ltd: Un método implementado por servidor para configurar un identificador de dispositivo móvil, que comprende: obtener una lista de aplicaciones, APP, […]
Método para un nivel mejorado de autenticación relacionado con una aplicación de cliente de software en un dispositivo informático de cliente que comprende una entidad de módulo de identidad de abonado con un kit de herramientas de módulo de identidad de abonado así como una miniaplicación de módulo de identidad de abonado, sistema, dispositivo informático de cliente y entidad de módulo de identidad de abonado para un nivel mejorado de autenticación relacionado con una aplicación de cliente de software en el dispositivo informático de cliente, programa que comprende un código de programa legible por ordenador y producto de programa informático, del 22 de Julio de 2020, de DEUTSCHE TELEKOM AG: Un método para un nivel mejorado de autenticación relacionado con una aplicación de cliente de software en un dispositivo informático […]
Método para atender solicitudes de acceso a información de ubicación, del 22 de Julio de 2020, de Nokia Technologies OY: Un aparato que comprende: al menos un procesador; y al menos una memoria que incluye un código de programa informático para uno o más programas, […]
Sincronización de una aplicación en un dispositivo auxiliar, del 22 de Julio de 2020, de OPENTV, INC.: Un método que comprende, mediante un dispositivo de medios: acceder, utilizando un módulo de recepción, un flujo de datos que incluye contenido […]
Procesamiento de contenido y servicios de redes para dispositivos móviles o fijos, del 8 de Julio de 2020, de AMIKA MOBILE CORPORATION: Un sistema para suministrar contenido de red a un dispositivo, comprendiendo el sistema : una primera interfaz para comunicarse con una pluralidad […]
Método de control de aplicación y terminal móvil, del 8 de Julio de 2020, de Guangdong OPPO Mobile Telecommunications Corp., Ltd: Un terminal móvil , que comprende: un procesador ; y un módulo de inteligencia artificial AI ; el procesador que se […]