SISTEMA DE RECONOCIMIENTO DE VOZ DISTRIBUIDO.
Sistema de reconocimiento de voz distribuido, que comprende al menos un terminal de usuario y al menos un servidor adecuados para comunicarse entre sí por medio de una red de telecomunicaciones,
en el que el terminal de usuario comprende:
- medios de obtención de una señal de audio a reconocer,
- primeros medios de cálculo de parámetros de modelización de la señal de audio, y
- primeros medios de control para seleccionar al menos una señal a emitir con destino al servidor entre la señal de audio a reconocer y una señal que indica los parámetros de modelización calculados, en función del contexto de la aplicación del terminal; y en el que el servidor comprende:
- medios de recepción de la señal seleccionada procedente del terminal de usuario,
- segundos medios de cálculo de parámetros de modelización de una señal de entrada,
- medios de reconocimiento para asociar al menos una forma memorizada a parámetros de entrada, y
- segundos medios de control para controlar los segundos medios de cálculo y los medios de reconocimiento para:
- cuando la señal seleccionada recibida por los medios de recepción es de tipo audio, activar los segundos medios de cálculo de parámetros remitiéndoles la señal seleccionada como señal de entrada y remitir los parámetros calculados por los segundos medios de cálculo a los medios de reconocimiento como parámetros de entrada, y
- cuando la señal seleccionada recibida por los medios de recepción indica parámetros de modelización, remitir dichos parámetros indicados a los medios de reconocimiento como parámetros de entrada
Tipo: Resumen de patente/invención. Número de Solicitud: W04000546FR.
Solicitante: FRANCE TELECOM.
Nacionalidad solicitante: Francia.
Dirección: 6 PLACE D'ALLERAY,75015 PARIS.
Inventor/es: PETIT, JEAN-PIERRE, MONNE, JEAN, BRISARD,PATRICK.
Fecha de Publicación: .
Fecha Concesión Europea: 26 de Agosto de 2009.
Clasificación Internacional de Patentes:
- G10L15/28D
Clasificación PCT:
- G10L15/28 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › G10L 15/00 Reconocimiento de la voz (G10L 17/00 tiene prioridad). › Detalles estructurales de sistemas de reconocimiento de la voz.
Clasificación antigua:
- G10L15/28 G10L 15/00 […] › Detalles estructurales de sistemas de reconocimiento de la voz.
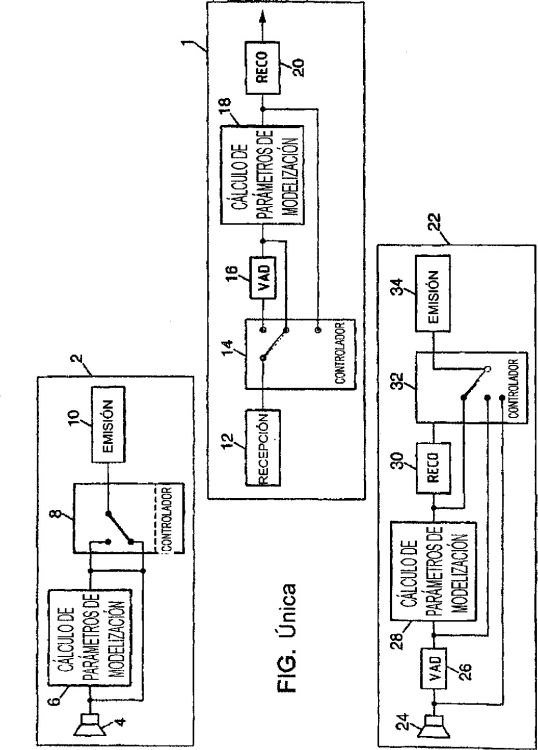
Fragmento de la descripción:
Sistema de reconocimiento de voz distribuido.
La presente invención se refiere al campo del control vocal de aplicaciones, ejercido sobre terminales de usuario, gracias al empleo de medios de reconocimiento de la voz. Los terminales de usuario considerados son todos los dispositivos dotados de un medio de captura de la voz, habitualmente un micrófono, que posee capacidades de tratamiento de este sonido y conectados a uno o más servidores mediante un canal de transmisión. Se trata, por ejemplo, de aparatos de control, de control a distancia utilizados en aplicaciones domésticas, en automóviles (control de auto-radio o de otras funciones del vehículo), en PC o en terminales de teléfono. El campo de las aplicaciones concernidas es esencialmente aquel en el que el usuario ordena una acción, solicita una información o quiere interactuar a distancia utilizando una orden de voz. La utilización de órdenes de voz no excluye la existencia en el terminal de usuario de otros medios de acción (sistema multi-modal), y el retorno de informaciones, de estados o de respuestas también se puede realizar de forma combinada visual, sonora, olfativa y mediante cualquier otro medio perceptible por el ser humano.
De manera general, los medios para la realización del reconocimiento de voz comprenden medios de obtención de una señal de audio, medios de análisis acústico que extraen parámetros de modelización y finalmente medios de reconocimiento que comparan estos parámetros de modelización calculados con modelos y proponen la forma memorizada en los modelos que puede estar asociada a la señal de la forma más probable. Opcionalmente se pueden utilizar medios de detección de actividad vocal VAD ("Voice Activation Detection"). Estos aseguran la detección de secuencias correspondientes a la voz y que deben ser reconocidas. Estos extraen de la señal de audio entrante, fuera de periodos de inactividad vocal, segmentos de voz que a continuación serán tratados mediante los medios de cálculo de los parámetros de modelización.
Más particularmente, la invención se refiere a las interacciones entre los tres modos de reconocimiento de voz llamados embarcado, centralizado y distribuido.
En un modo de reconocimiento de voz embarcado, el conjunto de los medios para realizar el reconocimiento de voz se encuentra al nivel del terminal de usuario. Las limitaciones de este modo de reconocimiento están, por lo tanto, vinculadas a la potencia de los procesadores embarcados y a la memoria disponible para almacenar los modelos de reconocimiento de voz. Como contrapartida, este modo permite un funcionamiento autónomo, sin conexión a un servidor y como tal es susceptible a un fuerte desarrollo vinculado a la reducción del coste de la capacidad de tratamiento.
En un modo de reconocimiento de voz centralizado, todo el procedimiento de voz y los modelos de reconocimiento se encuentran y se ejecutan en una máquina, llamada generalmente servidor vocal, accesible a través del terminal de usuario. El terminal transmite simplemente al servidor una señal de voz. Este método se utiliza particularmente en las aplicaciones ofrecidas por los operadores de telecomunicaciones. De este modo, un terminal básico puede acceder a terminales evolucionados, activados mediante la voz. Muchos tipos de reconocimiento de voz (robusto, flexible, vocabulario muy amplio, vocabulario dinámico, voz continua, mono- o multi-locutor, varios idiomas, etc.) se pueden implementar en un servidor de reconocimiento de voz. En efecto, las máquinas centralizadas tienen capacidades de almacenamiento de modelos, tamaños de memoria de trabajo y potencias de cálculo grandes y crecientes.
En un modo de reconocimiento de voz distribuido, los medios de análisis acústico están embarcados en el terminal de usuario, estando los medios de reconocimiento a nivel del servidor. En este modo distribuido, una función de eliminación de ruido asociada a los medios de cálculo de los parámetros de modelización se puede realizar ventajosamente en la fuente. Solamente se transmiten los parámetros de modelización, lo que permite un aumento sustancial del caudal de transmisión, particularmente interesante para las aplicaciones multimodales. Además, la señal a reconocer puede estar mejor protegida contra los errores de transmisión. Opcionalmente, también se puede embarcar la detección de actividad vocal (VAD) para transmitir los parámetros de modelización solamente durante las secuencias de voz, lo que tiene la ventaja de reducir de manera importante el periodo de transmisión activa. El reconocimiento de voz distribuido permite además transmitir por el mismo canal de transmisión señales de voz y de datos, particularmente texto, imágenes o videos. La red de transmisión puede ser por ejemplo de tipo IP, GPRS, WLAN o Ethernet. Este modo también permite beneficiarse de procedimientos de protección y de corrección contra las pérdidas de paquetes que constituyen la señal transmitida con destino al servidor. Sin embargo, requiere la disponibilidad de canales de transmisión de datos, con un protocolo estricto de transmisión.
La invención propone un sistema de reconocimiento de voz que comprende terminales de usuario y servidores que combinan las diferentes funciones ofrecidas por los medios de reconocimiento de voz embarcado, centralizado y distribuido, para ofrecer la máxima eficacia, comodidad y ergonomía a los usuarios de servicios multi-modales en los que se utiliza el control vocal.
La patente US 6487534 B1 describe un sistema de reconocimiento de voz distribuido que comprende un terminal de usuario que dispone de medios de detección de actividad vocal, medios de cálculo de los parámetros de modelización y medios de reconocimiento. Este sistema comprende además un servidor que también dispone de medios de reconocimiento. El principio descrito es la realización de al menos una primera fase de reconocimiento a nivel del terminal de usuario. En una segunda fase opcional, los parámetros de modelización calculados a nivel del terminal se envían con destino al servidor, para determinar particularmente, esta vez gracias a los medios de reconocimiento del servidor, una forma memorizada en los modelos de éste y asociada a la señal enviada.
El objeto pretendido por el sistema descrito en el documento mencionado es reducir la carga a nivel del servidor. Sin embargo, de esto se deriva que el terminal debe realizar el cálculo de los parámetros de modelización de forma local antes de transmitirlos eventualmente con destino al servidor. Ahora bien, existen circunstancias en las que, por razones de gestión de carga o por razones de aplicación, es preferible realizar este cálculo a nivel del servidor.
De esto se deriva también que los canales utilizados para la transmisión de los parámetros de modelización a reconocer, en un sistema de acuerdo con el documento mencionado, deben ser imperativamente canales adecuados para transmitir este tipo de datos. Ahora bien, dichos canales de protocolo muy estricto no están disponibles forzosamente de forma permanente en la red de transmisión. Es por ello que es interesante poder utilizar canales clásicos de transmisión de señales de audio, para no retardar o bloquear el proceso de reconocimiento iniciado a nivel del terminal.
Un objeto de la presente invención, tal como se define mediante las reivindicaciones 1, 7 y 11, es proponer un sistema distribuido que resulte menos afectado por las limitaciones mencionadas anteriormente.
De este modo, según un primer aspecto, la invención propone un sistema de reconocimiento de voz distribuido, que comprende al menos un terminal de usuario y al menos un servidor adecuados para comunicarse entre sí por medio de una red de telecomunicaciones, en el que el terminal de usuario comprende:
- medios de obtención de una señal de audio a reconocer,
- primeros medios de cálculo de parámetros de modelización de la señal de audio, y
- primeros medios de control para seleccionar al menos una señal a emitir con destino al servidor entre la señal de audio a reconocer y una señal que indica los parámetros de modelización calculados;
y en el que el servidor comprende:
- medios de recepción de la señal seleccionada procedente del terminal de usuario,
- segundos medios de cálculo de parámetros de modelización de una señal de entrada,
medios de reconocimiento para asociar al menos una forma memorizada a parámetros de entrada, y
- segundos medios de control para controlar los segundos medios de cálculo y los medios de reconocimiento...
Reivindicaciones:
1. Sistema de reconocimiento de voz distribuido, que comprende al menos un terminal de usuario y al menos un servidor adecuados para comunicarse entre sí por medio de una red de telecomunicaciones, en el que el terminal de usuario comprende:
- medios de obtención de una señal de audio a reconocer,
- primeros medios de cálculo de parámetros de modelización de la señal de audio, y
- primeros medios de control para seleccionar al menos una señal a emitir con destino al servidor entre la señal de audio a reconocer y una señal que indica los parámetros de modelización calculados, en función del contexto de la aplicación del terminal;
y en el que el servidor comprende:
- medios de recepción de la señal seleccionada procedente del terminal de usuario,
- segundos medios de cálculo de parámetros de modelización de una señal de entrada,
- medios de reconocimiento para asociar al menos una forma memorizada a parámetros de entrada, y
- segundos medios de control para controlar los segundos medios de cálculo y los medios de reconocimiento para:
- cuando la señal seleccionada recibida por los medios de recepción es de tipo audio, activar los segundos medios de cálculo de parámetros remitiéndoles la señal seleccionada como señal de entrada y remitir los parámetros calculados por los segundos medios de cálculo a los medios de reconocimiento como parámetros de entrada, y
- cuando la señal seleccionada recibida por los medios de recepción indica parámetros de modelización, remitir dichos parámetros indicados a los medios de reconocimiento como parámetros de entrada.
2. Sistema de acuerdo con la reivindicación 1, en el que los primeros medios de control seleccionan una señal a emitir en función, además, del estado de la red y/o según una coordinación entre los medios de control respectivos del terminal y del servidor.
3. Sistema de acuerdo con la reivindicación 1, en el que los medios de obtención de la señal de audio a reconocer comprenden medios de detección de actividad vocal para producir la señal a reconocer en forma de extractos de una señal de audio de origen, fuera de periodos de inactividad vocal.
4. Sistema de acuerdo con la reivindicación 3, en el que los primeros medios de control son adecuados para seleccionar la señal a emitir con destino al servidor entre al menos la señal de audio de origen, la señal de audio a reconocer en forma de segmentos extraídos por los medios de detección de actividad vocal y la señal que indica parámetros de modelización calculados por los primeros medios de cálculo de parámetros.
5. Sistema de acuerdo con una cualquiera de las reivindicaciones anteriores, en el que:
- el servidor comprende además medios de detección de actividad vocal para extraer de una señal de tipo audio, fuera de periodos de inactividad vocal, segmentos de voz, y
- los segundos medios de control son adecuados para controlar los segundos medios de cálculo y los medios de reconocimiento cuando la señal seleccionada recibida por los medios de recepción es de tipo audio, para:
si la señal de tipo audio es representativa de segmentos de voz después de la detección de actividad vocal, activar los segundos medios de cálculo de parámetros remitiéndoles la señal seleccionada como señal de entrada y después remitir los parámetros calculados por los segundos medios de cálculo de parámetros a los medios de reconocimiento como parámetros de entrada;
de lo contrario, activar los medios de detección de actividad vocal del servidor remitiéndoles la señal recibida como señal de entrada y después remitir los segmentos extraídos por los medios de detección de actividad vocal a los segundos medios de cálculo de parámetros como señal de entrada y después remitir los parámetros calculados por los segundos medios de cálculo de parámetros a los medios de reconocimiento, como parámetros de entrada.
6. Sistema de acuerdo con una cualquiera de las reivindicaciones anteriores, en el que el terminal de usuario comprende además medios de almacenamiento adecuados para almacenar la señal de audio reconocer o los parámetros de modelización calculados por los primeros medios de cálculo de parámetros.
7. Terminal de usuario para implementar un sistema de reconocimiento de voz distribuido de acuerdo con una de las reivindicaciones 1 a 6, que comprende:
- medios de obtención de una señal de audio a reconocer,
- medios de cálculo de parámetros de modelización de la señal de audio, y
- primeros medios de control para seleccionar al menos una señal a emitir con destino al servidor entre la señal de audio a reconocer y una señal que indica los parámetros de modelización calculados, en función del contexto de la aplicación del terminal.
8. Terminal de usuario de acuerdo con la reivindicación 7, en el que los primeros medios de control seleccionan una señal a emitir en función, además, del estado de la red y/o según una coordinación entre los medios de control respectivos del terminal y del servidor.
9. Terminal de usuario de acuerdo con la reivindicación 7 u 8, en el que al menos una parte de los medios de cálculo de parámetros se descarga desde el servidor.
10. Terminal de usuario de acuerdo con la reivindicación 7 u 8, en el que al menos una parte de los medios de reconocimiento se descarga desde el servidor.
11. Servidor para implementar un sistema de reconocimiento de voz distribuido de acuerdo con una de las reivindicaciones 1 a 6, que comprende:
- medios de recepción, procedente de un terminal de usuario, de una señal seleccionada en dicho terminal,
- medios de cálculo de parámetros de modelización de una señal de entrada,
- medios de reconocimiento para asociar al menos una forma memorizada a parámetros de entrada, y
- medios de control para controlar los segundos medios de cálculo y los medios de reconocimiento para:
- cuando la señal seleccionada recibida por los medios de recepción es de tipo audio, activar los medios de cálculo de parámetros remitiéndoles la señal seleccionada como señal de entrada y remitir los parámetros calculados por los medios de cálculo a los medios de reconocimiento como parámetros de entrada, y
- cuando la señal seleccionada recibida por los medios de recepción indica parámetros de modelización, remitir dichos parámetros indicados a los medios de reconocimiento como parámetros de entrada.
12. Servidor de acuerdo con la reivindicación 11, que comprende medios para descargar por medio de la red de telecomunicaciones, con destino a un terminal, al menos una parte de los primeros medios de cálculo de parámetro o de los medios de reconocimiento del terminal.
13. Servidor de acuerdo con la reivindicación 12, que comprende medios para descargar recursos lógicos de reconocimiento de voz por medio de la red de telecomunicaciones con destino a un terminal.
14. Servidor de acuerdo con la reivindicación 13, en el que dichos recursos comprenden al menos un módulo de entre: un módulo de VAD, un módulo de cálculo de parámetros de modelización de una señal de audio y un módulo de reconocimiento para asociar al menos una forma memorizada a parámetros de modelización.
Patentes similares o relacionadas:
 PROCEDIMIENTO, SISTEMA Y DISPOSITIVO PARA LA CONVERSIÓN DE LA VOZ, del 23 de Mayo de 2011, de Mobiter Dicta Oy: Un dispositivo móvil operable en una red de comunicaciones inalámbricas que comprende: - un medio de entrada de voz para recibir voz y convertir la voz en una señal […]
PROCEDIMIENTO, SISTEMA Y DISPOSITIVO PARA LA CONVERSIÓN DE LA VOZ, del 23 de Mayo de 2011, de Mobiter Dicta Oy: Un dispositivo móvil operable en una red de comunicaciones inalámbricas que comprende: - un medio de entrada de voz para recibir voz y convertir la voz en una señal […]
 PROCEDIMIENTO Y SISTEMA PARA EDITAR TEXTO EN UN DISPOSITIVO ELECTRONICO DE MANO, del 17 de Marzo de 2010, de NOKIA CORPORATION: Un procedimiento de modificación de texto , controlada por la voz, en un dispositivo electrónico de mano, en una sesión de edición, incluyendo […]
PROCEDIMIENTO Y SISTEMA PARA EDITAR TEXTO EN UN DISPOSITIVO ELECTRONICO DE MANO, del 17 de Marzo de 2010, de NOKIA CORPORATION: Un procedimiento de modificación de texto , controlada por la voz, en un dispositivo electrónico de mano, en una sesión de edición, incluyendo […]
 PROCEDIMIENTO PARA PERSONALIZAR UN SERVICIO, del 15 de Diciembre de 2009, de SWISSCOM MOBILE AG: Un procedimiento en una red de comunicaciones para personalizar un servicio, que comprende las etapas de:
generar modelos de lenguaje que dependen del usuario […]
PROCEDIMIENTO PARA PERSONALIZAR UN SERVICIO, del 15 de Diciembre de 2009, de SWISSCOM MOBILE AG: Un procedimiento en una red de comunicaciones para personalizar un servicio, que comprende las etapas de:
generar modelos de lenguaje que dependen del usuario […]
Método y aparato de intercambio de información, del 20 de Mayo de 2020, de Advanced New Technologies Co., Ltd: Un método de intercambio de información, realizado en un dispositivo terminal, caracterizado porque el método comprende: determinar […]
 Máquina de cocina eléctricamente accionada con dispositivo de reconocimiento de voz, del 11 de Julio de 2018, de VORWERK & CO. INTERHOLDING GMBH: Máquina de cocina eléctricamente accionada que comprende
- un dispositivo de reconocimiento de voz que está concebido para comparar señales de voz de un usuario […]
Máquina de cocina eléctricamente accionada con dispositivo de reconocimiento de voz, del 11 de Julio de 2018, de VORWERK & CO. INTERHOLDING GMBH: Máquina de cocina eléctricamente accionada que comprende
- un dispositivo de reconocimiento de voz que está concebido para comparar señales de voz de un usuario […]
Sistema y método de diálogo de múltiples intervalos, del 22 de Febrero de 2017, de 24/7 Customer, Inc: Un sistema para construir y procesar un diálogo de múltiples intervalos con un usuario, que comprende: un procesador; e instrucciones de software que cuando se ejecutan […]
Procedimiento, servidor y sistema para la transcripción de lengua hablada, del 25 de Diciembre de 2013, de VerbaVoice GmbH: Un procedimiento de transcripción para la transcripción de lengua hablada en texto continuo para un usuario (U) que comprende las etapas de: (a) introducir una lengua […]
Cuantificación de la frecuencia fundamental para el reconocimiento de voz distribuido, del 14 de Noviembre de 2012, de Motorola Mobility LLC (50.0%): Un método para un sistema de procesamiento de información para cuantificar la información de la frecuenciafundamental de audio, que comprende: capturar audio […]