Procedimiento, programa de ordenador con medios de código de programa y producto de programa de ordenador para vigilar el estado de un sistema con componentes distribuidos, en particular de una red con componentes distribuidos, red con componentes distribuidos.
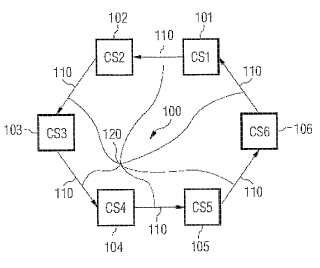
Procedimiento para vigilar el estado de un sistema con componentes distribuidos (101-106),
en particular deuna red (100) con componentes distribuidos, en el que
- los componentes distribuidos (101-106) del sistema están dispuestos en una estructura lógica anular (120),
- cada componente (101-106) del sistema sólo vigila a su correspondiente componente contiguo en laestructura lógica anular (120), detectándose el estado del correspondiente componente contiguo,
caracterizado porque un componente (103) que ha detectado un estado en su componente contiguo (102)que corresponde a un estado que puede predeterminarse, informa a todos los otros componentes (101, 104-106) del sistema sobre el estado predeterminado detectado de su componente contiguo (211).
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/EP2005/052828.
Solicitante: SIEMENS AKTIENGESELLSCHAFT.
Nacionalidad solicitante: Alemania.
Dirección: WITTELSBACHERPLATZ 2 80333 MUNCHEN ALEMANIA.
Inventor/es: HANNA, THOMAS, SOUTHALL,Alan, BERNDT,STEFAN, LAUX,THORSTEN, RUSITSCHKA,STEFFEN, SCHEERING,CHRISTIAN.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- H04L12/24 ELECTRICIDAD. › H04 TECNICA DE LAS COMUNICACIONES ELECTRICAS. › H04L TRANSMISION DE INFORMACION DIGITAL, p. ej. COMUNICACION TELEGRAFICA (disposiciones comunes a las comunicaciones telegráficas y telefónicas H04M). › H04L 12/00 Redes de datos de conmutación (interconexión o transferencia de información o de otras señales entre memorias, dispositivos de entrada/salida o unidades de tratamiento G06F 13/00). › Disposiciones para el mantenimiento o la gestión.
- H04L12/56
PDF original: ES-2391462_T3.pdf
Fragmento de la descripción:
Procedimiento, programa de ordenador con medios de código de programa y producto de programa de ordenador para vigilar el estado de un sistema con componentes distribuidos, en particular de una red con componentes distribuidos, red con componentes distribuidos
La solicitud se refiere a una vigilancia y/o comprobación, denominadas a continuación en general y abreviadamente vigilancia, del estado de un sistema con componentes distribuidos.
En tales sistemas - abreviadamente - distribuidos, como por ejemplo redes de radio y/o de comunicaciones móviles
o fijas, existe por lo general la necesidad de que todos los componentes del sistema distribuido tengan conocimiento de un status o estado de cada uno de los demás componentes del sistema (vigilancia) .
Si falla por ejemplo un componente en un sistema distribuido, por ejemplo debido a que un componente se encuentra o pasa a ser incapaz de funcionar y/o a estar offline, entonces es conveniente que cada uno de los otros componentes del sistema reciba esta información.
Por el estado de la técnica se conocen diversos planteamientos para vigilar el estado de un sistema distribuido, en los que la vigilancia se realiza mediante un llamado mecanismo de ping-pong con los llamados mensajes de pingpong.
En este contexto, es decir, en un tal mecanismo a base de mensajes ping-pong, envía un componente del sistema a un componente a vigilar periódicamente un mensaje ping a través del sistema distribuido, en base al cual el componente a vigilar contesta con una respuesta pong, un llamado acuse de recibo pong.
Cuando falta la respuesta pong de un componente a comprobar, entonces se clasifica este componente, por lo general por parte del componente que envía el mensaje ping, como offline o en general como incapaz de funcionar.
Para que un componente de un sistema distribuido pueda encontrar o comprobar el status o estado de cualquiera de los otros componentes del sistema distribuido, pregunta el mismo a todos los componentes con el mecanismo de ping-pong.
Un (primer) planteamiento aquí conocido para vigilar el estado de un sistema distribuido basado en el mecanismo de ping-pong prevé que cada componente de un sistema distribuido vigile a cada uno de los otros componentes de este sistema y consulte para ello las correspondientes informaciones sobre el status o estado de los otros componentes correspondientes.
Para ello envía cada componente del sistema distribuido a cada uno de los otros componentes del sistema un mensaje ping y recibe, cuando los otros componentes son capaces de funcionar o se encuentran en estado online, las correspondientes respuestas pong (de retorno) .
La figura 3 muestra este primer planteamiento conocido.
Así se representa la figura 3 un sistema de comunicaciones distribuido 300, un sistema de telefonía HiPath IP 300, con varios servidores de comunicaciones 301 a 306 incluidos en una unidad compuesta de comunicaciones. Cada uno de estos servidores de comunicaciones 301 a 306 necesita el conocimiento relativo al fallo de cada uno de los otros servidores de comunicaciones 301 a 306 en el sistema 300.
Para ello envía ahora cada uno de estos servidores de comunicaciones 301 a 306 a cada uno de los otros servidores de comunicaciones 301 a 306 en el sistema de telefonía HiPath IP 300 un mensaje ping 310 y recibe, cuando el respectivo otro servidor de comunicaciones 301 a 306 es capaz de funcionar o se encuentra en estado online, las correspondientes respuestas pong 311.
Un inconveniente en este primer planteamiento conocido es que aquí se genera una gran cantidad de mensajes, de un orden O (n"2) (n = cantidad de componentes del sistema) , en la vigilancia del estado de un sistema distribuido, lo que limita en determinadas circunstancias la potencia o capacidad y/o la capacidad y rapidez del sistema en la detección de faltas.
Así se envían por ejemplo en el sistema de telefonía HiPath IP 300 según la figura 3 cada 60 segundos mensajes ping-pong (310, 311) . Entonces resultan en el caso representado con 6 servidores de comunicaciones 301 a 306 o bien alternativamente 30 servidores (6*5*2) /60s = 1 mensaje por segundo o bien (30*29*2) /60s = 29 mensajes por segundo.
En otro planteamiento conocido para vigilar el estado de un sistema distribuido basándose en el mecanismo de pingpong, está previsto que aquí compruebe un coordinador central componentes de un sistema distribuido, registre los componentes incapaces de funcionar o que han fallado del sistema distribuido y difunda las informaciones correspondientes a todos los componentes del sistema.
La cantidad de mensajes aquí generada es del orden O (n) .
En este otro planteamiento conocido es un inconveniente que sólo puede realizarse con robustez con dificultades, ya que el coordinador central del sistema distribuido ha de mantenerse redundante.
Además se conoce por Jahanian F y colab. “Processor group membership protocols: specification, design and implementation” (protocolos de participación en el grupo de procesadores: especificación, diseño e implementación) , Reliable Distributed Systems (Sistemas distribuidos fiables) , 1993, Actas, 12º Simposio en Princeton, NJ, USA 6-8 Oct., 1993, Los Alamitos, CA, USA, IEEE Comput. SOC, 6 Oct. 1993 (1993-10-06) , páginas 2-11, la reunión de procesadores de cálculo para formar un grupo, para realizar cálculos distribuidos. Para detectar el fallo de procesadores que participan, se propone reunir los procesadores en una estructura lógica anular. Además debe transmitir cada procesador a sus dos procesadores contiguos en el anillo regularmente los llamados mensajes Heartbeat o de mantenerse activo. En base a la cantidad de mensajes Heartbeat no recibidos, debe detectarse un fallo o falta en un procesador.
Fakhouri S.A. y colab., “Gulfstream – a System for dynamic topology management in multi-domain server farms” (Gulfstream – un sistema para la gestión de topologías dinámicas en torres de servidores multidominio”, 42º Simposio anual de fundaciones de la ciencia de computadores; (FOCS 2001) , Las Vegas, 14-17 Oct., 2001, Simposio anual de fundaciones de la ciencia de computadores, Los Alamitos, CA, IEEE Comp. SOC, US, 8 Octubre 2001 (2001-10-08) , páginas 55-62, describe un procedimiento para una torre de servidores (server farm) , reuniéndose adaptadores de red en un grupo y formando un anillo lógico. Para vigilar la funcionalidad de los adaptadores de red se propone enviar regularmente mensajes Heartbeat a un adaptador de la red siguiente en el anillo lógico. La vigilancia se realiza mediante un equipo central asignado a cada grupo, que en el caso de que falten los mensajes Heartbeat recibe de los correspondientes adaptadores de red receptores un mensaje de fallo. El equipo central de red para el correspondiente grupo ejecuta entonces las correspondientes medidas. En el mismo documento se explica además que preferiblemente los adaptadores de red deben enviar mensajes Heartbeat a otros varios adaptadores de red.
El documento US 2003/0204786 A1 da a conocer un procedimiento y un sistema para operar clusters de nodos de un sistema de ordenadores distribuido. Se propone entonces prever los nodos en una estructura lógica anular, enviando los nodos contiguos al correspondiente nodo de ordenador mensajes Heartbeat. Si no se recibe ningún mensaje de los vecinos directos, envía el correspondiente nodo del cluster un mensaje de fallo a los siguientes vecinos del anillo que están en condiciones de funcionar.
Por lo tanto, la tarea de la presente invención consiste en indicar un procedimiento que simplifique y/o realice o posibilite con un reducido coste una vigilancia del estado de un sistema distribuido.
Esta tarea se resuelve mediante el procedimiento, mediante el programa de ordenador con medios de código de programa y mediante el producto de programa de ordenador para vigilar el estado de un sistema con componentes distribuidos, así como mediante la red con componentes distribuidos con las características según la correspondiente reivindicación independiente.
En el procedimiento para vigilar el estado de un sistema con componentes distribuidos se disponen o están dispuestos los componentes distribuidos del sistema en una estructura lógica anular.
Bajo una estructura "lógica" anular (de componentes del sistema) ha de entenderse entonces, sin limitación... [Seguir leyendo]
Reivindicaciones:
1. Procedimiento para vigilar el estado de un sistema con componentes distribuidos (101-106) , en particular de una red (100) con componentes distribuidos, en el que los componentes distribuidos (101-106) del sistema están dispuestos en una estructura lógica anular (120) , cada componente (101-106) del sistema sólo vigila a su correspondiente componente contiguo en la
estructura lógica anular (120) , detectándose el estado del correspondiente componente contiguo,
caracterizado porque un componente (103) que ha detectado un estado en su componente contiguo (102) que corresponde a un estado que puede predeterminarse, informa a todos los otros componentes (101, 104106) del sistema sobre el estado predeterminado detectado de su componente contiguo (211) .
2. Procedimiento según la reivindicación 1, en el que el estado que puede predeterminarse es una incapacidad funcional, en particular un estado de offline,
o una capacidad funcional, en particular un estado de online.
3. Procedimiento según la reivindicación 1 ó 2, en el que se transmite una información “alive” (vivo) , en particular un mensaje de “alive” (110) desde el componente contiguo (102) al componente (103) .
4. Procedimiento según la reivindicación 3, en el que la información "alive" se transmite periódicamente.
5. Procedimiento según la reivindicación 3 ó 4, en el que se detecta una incapacidad funcional del componente contiguo (102) cuando el componente contiguo
(102) no transmite una información de "alive".
6.
10. 106) sobre el estado que puede predeterminarse del componente contiguo (102) se realiza en base a un procedimiento de "informar a todos".
7.
10. 106) , en el que el correspondiente otro componente (101, 104106) , cuando ha recibido la información sobre el estado que puede predeterminarse de un componente contiguo (102) , confirma la recepción de la información, en particular utilizando una información de "acuse de recibo" (acknowledgement) , en particular un mensaje de "acuse de recibo".
8. Procedimiento según la reivindicación 7, en el que la confirmación frente al componente (103) que ha detectado el estado que puede predeterminarse del componente contiguo (102) se realiza en particular transmitiendo un mensaje de "acuse de recibo" al componente (103) .
9.
10. 106) que no confirma la recepción de la información sobre el estado determinado detectado en el componente contiguo (102) , también se detecta el estado que puede predeterminarse.
10. Procedimiento según una de las reivindicaciones precedentes, en el que cada componente (101-106) memoriza informaciones sobre los estados de los demás componentes, en particular en una lista local.
11. Procedimiento según una de las reivindicaciones precedentes, en el que el componente contiguo (103) es bien un componente precedente o un componente siguiente de un componente (103) en la estructura lógica anular.
12. Procedimiento según una de las reivindicaciones precedentes, en el que se vigila una red de comunicaciones (100) , en particular una red de comunicaciones fija y/o una red telefónica con componentes distribuidos (101-106) , siendo los componentes (101-106) servidores de comunicaciones.
13. Programa de ordenador con medios de código de programa, para ejecutar todos los pasos según una de las reivindicaciones precedentes, cuando el programa se ejecuta sobre un componente de la red.
14. Programa de ordenador con medios de código de programa según la reivindicación 13, en el que el programa de ordenador está memorizado en un soporte de datos legible por ordenador.
15. Producto de programa de ordenador con medios de código de programa memorizados en un soporte legible 5 por máquina, para realizar todos los pasos según una de las reivindicaciones 1-12, cuando se ejecuta el programa sobre un componente de la red.
16. Red (100) con componentes (101-106) dispuestos distribuidos en una estructura lógica anular (120) , en la que cada componente (101-106) está equipado tal que un componente (103) sólo vigila a su correspondiente 10 componente contiguo (102) en la estructura lógica anular (120) , pudiendo detectarse un estado del correspondiente componente contiguo (102) , caracterizado porque un componente (103) que ha detectado un estado de su componente contiguo (102) que corresponde a un estado que puede predeterminarse, informa a todos los otros componentes (101, 104106) del sistema sobre el estado predeterminado detectado en su componente contiguo (102) .
Patentes similares o relacionadas:
Dispositivo inalámbrico y procedimiento para visualizar un mensaje, del 25 de Marzo de 2020, de QUALCOMM INCORPORATED: Un dispositivo inalámbrico para visualizar un mensaje, comprendiendo el dispositivo inalámbrico: un visualizador gráfico ; una unidad de comunicaciones inalámbricas […]
Método de indicación de disponibilidad de servicio para terminales de radiofrecuencia de corto alcance, con visualización de icono de servicio, del 26 de Febrero de 2020, de Nokia Technologies OY: Un método que comprende: recibir, en un dispositivo , información de icono de un dispositivo de origen en conexión con descubrimiento de dispositivo […]
Procedimiento y aparato para la transmisión de entramado con integridad en un sistema de comunicación inalámbrica, del 6 de Noviembre de 2019, de QUALCOMM INCORPORATED: Un procedimiento para el entramado de paquetes en un sistema de transmisión inalámbrico que admite transmisiones de radiodifusión, el procedimiento que comprende: […]
Aparato y procedimiento para usar en la realización de peticiones de repetición automática en sistemas de comunicaciones de acceso múltiple inalámbricas, del 6 de Noviembre de 2019, de QUALCOMM INCORPORATED: Un procedimiento para usar en un sistema de comunicaciones inalámbricas que comprende al menos una estación base y al menos dos terminales inalámbricos […]
 Procedimiento y aparato para sistemas inalámbricos de activación, del 31 de Octubre de 2019, de QUALCOMM INCORPORATED: Un procedimiento para controlar de forma inalámbrica una tarjeta de interfaz de red NIC (108 A-N) usando una red inalámbrica , con la NIC (108 A-N) […]
Procedimiento y aparato para sistemas inalámbricos de activación, del 31 de Octubre de 2019, de QUALCOMM INCORPORATED: Un procedimiento para controlar de forma inalámbrica una tarjeta de interfaz de red NIC (108 A-N) usando una red inalámbrica , con la NIC (108 A-N) […]
Método y sistema para visualizar un nivel de confianza de las operaciones de comunicación de red y la conexión de servidores, del 16 de Octubre de 2019, de Nokia Technologies OY: Un método que comprende: recibir, en un servidor , una primera solicitud para un análisis de una primera operación de comunicación desde […]
Un protocolo de red agile para comunicaciones seguras con disponibilidad asegurada de sistema, del 11 de Septiembre de 2019, de VirnetX Inc: Un método para un primer nodo para establecer una sesión con un segundo nodo , el método se realiza en el primer nodo , en el que […]
Dispositivo de nodo para una red de sensores inalámbricos, del 10 de Julio de 2019, de Wirepas Oy: Un dispositivo de nodo para una red de sensores inalámbricos, comprendiendo el dispositivo de nodo: - un transceptor […]