Localización optimizada de recursos de red.
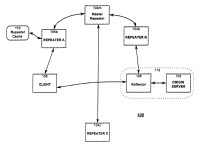
Un método, en una red informática que consta de una red de servidores repetidores (104) para espejar al menos ciertos recursos almacenados en al menos un servidor origen (102),
dichos servidores repetidores estando adaptados para servir contenido a al menos un cliente (106), caracterizado porque el método consta de los siguientes pasos:
(A) recibir, en un módulo de software, una petición de un recurso de un servidor origen efectuada por un cliente, seleccionando el módulo de software un servidor repetidor de la red de repetidores (104) para servir el recurso al cliente, utilizando la selección un coste que incluya la carga o un coste de transmisión previsto o una velocidad de transmisión prevista, y causar que el cliente (106) solicite el recurso del servidor repetidor seleccionado (104), utilizando un identificador de recursos recibido desde el módulo de software, designando el identificador de recursos al servidor repetidor seleccionado.
(B) en respuesta al servidor repetidor seleccionado (104), al que se solicita que sirva el recurso al cliente (106), determinar, en el servidor repetidor seleccionado (104), si el recurso solicitado se encuentra disponible en el servidor repetidor seleccionado (104);
(C) cuando se determina que el recurso solicitado no está disponible en el servidor repetidor seleccionado (104), obtener el recurso solicitado desde el servidor origen (102) o desde otro servidor repetidor (104); y
(D) proporcionar el recurso al cliente (106) desde el servidor repetidor seleccionado (104).
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/US1999/001477.
Solicitante: LEVEL 3 CDN INTERNATIONAL, INC.
Nacionalidad solicitante: Estados Unidos de América.
Dirección: 1025 ELDORADO BLVD. BROOMFIELD CO 80021 ESTADOS UNIDOS DE AMERICA.
Inventor/es: FARBER, DAVID A., GREER, RICHARD E., SWART, ANDREW D, BALTER, JAMES A.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G06F9/50 FISICA. › G06 CALCULO; CONTEO. › G06F PROCESAMIENTO ELECTRICO DE DATOS DIGITALES (sistemas de computadores basados en modelos de cálculo específicos G06N). › G06F 9/00 Disposiciones para el control por programa, p. ej. unidades de control (control por programa para dispositivos periféricos G06F 13/10). › Asignación de recursos, p. ej. de la unidad central de procesamiento [CPU].
- H04L29/08 ELECTRICIDAD. › H04 TECNICA DE LAS COMUNICACIONES ELECTRICAS. › H04L TRANSMISION DE INFORMACION DIGITAL, p. ej. COMUNICACION TELEGRAFICA (disposiciones comunes a las comunicaciones telegráficas y telefónicas H04M). › H04L 29/00 Disposiciones, aparatos, circuitos o sistemas no cubiertos por uno solo de los grupos H04L 1/00 - H04L 27/00. › Procedimiento de control de la transmisión, p. ej. procedimiento de control del nivel del enlace.
PDF original: ES-2328426_T3.pdf
Fragmento de la descripción:
Localización optimizada de recursos de red.
1. Área de la invención
La presente invención hace referencia a la duplicación de recursos en redes informáticas.
2. Antecedentes de la invención
La llegada de las redes informáticas globales, como por ejemplo Internet, ha generado maneras completamente nuevas y diferentes de obtener información. Un usuario de Internet ahora puede acceder a la información desde cualquier lugar del mundo, sin importar la ubicación real del usuario ni de la información. Un usuario puede obtener información sólo conociendo una dirección de red para esa información y proporcionando dicha dirección a un programa de aplicación apropiado, como un navegador de red.
El rápido crecimiento de la popularidad de Internet ha impuesto una gran carga de tráfico en toda la red. Las soluciones a problemas de demanda (por ejemplo, una mejor accesibilidad y enlaces de comunicación más rápidos) sólo logran incrementar los niveles de exigencia de carga sobre el suministro de servicio. Los sitios web de Internet (aquí denominados "editores") deben gestionar necesidades de ancho de banda cada vez mayores, adaptarse a los cambios dinámicos de carga, y mejorar el rendimiento para aquellos clientes navegadores distantes, especialmente para los que se encuentran en otros continentes. La adopción de aplicaciones ricas en contenido, como por ejemplo audio y vídeo en vivo, ha agravado el problema aún más.
Para hacer frente a las necesidades básicas de crecimiento de ancho de banda, un editor web se suscribe, por lo general, a un ancho de banda adicional proporcionado por un proveedor de servicios de Internet (ISP, por sus siglas en inglés), ya sea en forma de "cableados o tubos" adicionales, o más largos, o canales desde el ISP hasta las instalaciones del editor, o en la forma de un mayor compromiso de ancho de banda en un conjunto de servidores de hospedaje (de hosting) remoto del ISP. Estos incrementos no siempre son tan minuciosos como necesita el editor, y bastante a menudo los tiempos de espera pueden causar que la capacidad del sitio web del editor se quede atrás con respecto a la demanda.
Para hacer frente a problemas más serios de crecimiento de ancho de banda, los editores pueden desarrollar soluciones personalizadas más complejas y costosas. La solución más común al requerimiento, es decir incrementar la capacidad, se basa por lo general en la duplicación de los recursos de hardware y el contenido del sitio (a lo que se denomina creación de réplicas o "mirroring"), y en la duplicación de los recursos de ancho de banda. Estas soluciones, sin embargo, son difíciles y costosas de utilizar y ofrecer. Como resultado, sólo los editores más importantes pueden utilizarlas, dado que sólo dichos editores pueden amortizar los costes sobre un gran número de usuarios (y consultas al sitio web).
Se ha desarrollado una gran cantidad de soluciones para promover la duplicación y la técnica de "mirroring". En general, estas tecnologías están diseñadas para ser utilizadas por un solo sitio web y no incluyen elementos que permitan que sus componentes sean compartidos por muchos sitios web de manera simultánea.
Ciertos mecanismos de solución ofrecen software de duplicación que permite mantener actualizados los servidores espejados. Por lo general, estos mecanismos operan haciendo una copia completa de un sistema de archivos. Un sistema de este tipo, opera manteniendo sincronizadas de manera transparente múltiples copias de un sistema de archivos. Otro sistema proporciona mecanismos para copiar de manera explícita y regular archivos que han cambiado. Los sistemas de bases de datos son particularmente difíciles de espejar dado que cambian de manera continua. Varios mecanismos permiten la duplicación de bases de datos, aunque no se cuenta con métodos estándar para lograrlo. Muchas compañías que ofrecen cachés de proxy los describen como herramientas de duplicación. Sin embargo, los cachés proxy difieren de éstas en que son operados en nombre de clientes y no de los editores.
Una vez que un sitio web es servido por múltiples servidores, asegurar que la carga sea distribuida o equilibrada correctamente entre los servidores es todo un desafío. La resolución de direcciones round-robin basadas en el servidor de nombres de dominio provoca que diferentes clientes sean direccionados a diferentes réplicas o "mirrors".
Otra solución, la distribución compensada de carga, tiene en cuenta la carga de cada servidor (medida de diversas maneras) para determinar cuál de todos los servidores debería gestionar una petición en particular.
Los compensadores de carga utilizan una variedad de técnicas para enrutar la petición al servidor apropiado. La mayoría de dichas técnicas de distribución compensada de carga requiere que cada servidor sea una réplica exacta del sitio web primario. Los compensadores de carga no tienen en cuenta la "distancia de red" que existe entre el cliente y los posibles servidores espejo.
Suponiendo que los protocolos de cliente no puedan cambiar con facilidad, existen dos problemas principales en la utilización de recursos duplicados. El primero es cómo seleccionar la copia del recurso que se deberá utilizar. Es decir, cuando se efectúa una petición de un recurso a un solo servidor, cómo debería realizarse la elección de una réplica del servidor (o de datos). A este problema se le denomina "problema de rendezvous". Existe una gran cantidad de formas de hacer que los clientes se encuentren en servidores espejo distantes. Estas tecnologías, al igual que los compensadores de carga, deben enrutar una petición a un servidor apropiado, pero a diferencia de los compensadores de carga, tienen en cuenta el rendimiento y la topología de la red al realizar la determinación.
Muchas compañías ofrecen productos que mejoran el rendimiento de la red priorizando y filtrando el tráfico de red.
Los cachés de proxy proporcionan una manera para que los agregadores de los contenidos de los clientes puedan reducir el consumo de los recursos de red mediante el almacenamiento de copias de recursos populares cerca de los usuarios finales. Un cliente agregador es un proveedor de servicio de Internet u otra organización que incorpora una gran cantidad de clientes que operan navegadores de Internet. Los agregadores de cliente pueden utilizar cachés de proxy para reducir el ancho de banda requerido para proporcionar contenido web a estos navegadores. Sin embargo, los cachés de proxy tradicionales son operados en nombre de clientes web y no de los editores web.
Los cachés de proxy almacenan los recursos más populares de todos los editores, lo que significa que deben ser considerablemente grandes para alcanzar una eficiencia de caché razonable. (La eficiencia de un caché se define como la cantidad de peticiones de recursos que ya están almacenados dividida por la cantidad total de peticiones).
Los cachés de proxy dependen de indicaciones (hints) del control de caché entregadas con los recursos para determinar cuándo se deberían reemplazar los recursos. Estas indicaciones son predictivas, y a menudo son necesariamente incorrectas, por lo que los cachés de proxy con frecuencia proporcionan datos obsoletos. En muchos casos, los operadores de caché de Proxy le ordenan a su proxy que ignore las indicaciones con el fin de lograr que el caché sea más eficiente, incluso aunque esto cause que sirva, con una mayor frecuencia, datos caducados.
Los cachés de proxy ocultan a los editores la actividad de los clientes. Una vez que un recurso es almacenado, el editor no tiene forma de saber cuán a menudo se accedió a él desde el caché.
Los sistemas de caché son conocidos en el arte anterior en distintas modificaciones a partir de:
Povey D. Harrison J: "A Distributed Internet Caché", Twentieth Australasian Computer Science Conference. ASCS'97, 5-7 Feb. 1997, Sydney, NSW, Australia, vol. 19, no. 1, páginas 176-184, XP000918489 Australian Computer Science Communications James Cook Univ. Australia ISSN: 0157-3055.
Chankhunthod A et al: "A Hierarchical Internet Object Caché", Proceedings of the USENIX Annual Technical Conference, 22 de enero de 1996 (1996-01-22), páginas 153-163, XP0000918501.
Wessels D et al: "Application of Internet Caché Protocol (ICP), version 2-RFC2187" IETF Standard, Internet Engineering Task Force, IETF,... [Seguir leyendo]
Reivindicaciones:
1. Un método, en una red informática que consta de una red de servidores repetidores (104) para espejar al menos ciertos recursos almacenados en al menos un servidor origen (102), dichos servidores repetidores estando adaptados para servir contenido a al menos un cliente (106),
caracterizado porque el método consta de los siguientes pasos:
2. El método de la reivindicación 1, donde dicho paso (A) de causar es llevado a cabo por medios conectados de manera operacional con el al menos un servidor origen (102).
3. El método de la reivindicación 1 ó 2, donde un cliente (106) puede solicitar un recurso utilizando al menos un primer identificador de recursos, y donde dicho paso (A) devuelve un segundo identificador de recursos distinto de dicho primer identificador de recursos, y estando asociado con el servidor repetidor seleccionado en la red de servidores repetidores.
4. El método de la reivindicación 3, donde el segundo identificador de recursos es una modificación del primer identificador de recursos.
5. El método de la reivindicación 3 ó 4, donde el primer identificador de recursos comprende un nombre de equipo.
6. El método de cualquiera de las reivindicaciones 3 a 5, donde el segundo identificador de recursos comprende una dirección de Protocolo de Internet (IP) o un nombre de equipo asociado con un servidor repetidor en la red de servidores repetidores.
7. El método de cualquiera de las reivindicaciones 3 a 6, donde el primer identificador de recursos está asociado con una ubicación del recurso.
8. El método de cualquiera de las reivindicaciones 1 a 7, donde dicho paso (A) de causar proporciona al cliente un identificador de recursos modificado que designa un repetidor seleccionado en la red de servidores repetidores.
9. El método de cualquiera de las reivindicaciones 1 a 8, donde el paso de selección realiza una selección basada, al menos en parte, en una dirección de red asociada con el cliente.
10. El método de cualquiera de las reivindicaciones 1 a 9, donde el paso de selección realiza una selección basada, al menos en parte, en una carga de al menos algunos de los servidores repetidores.
11. El método de cualquiera de las reivindicaciones 1 a 10, donde el paso de selección realiza una selección basada, al menos en parte, en un coste o velocidad de transmisión entre al menos algunos de los servidores repetidores y el cliente.
12. El método de cualquiera de las reivindicaciones 3 a 11, donde la red es parte de Internet y donde el primer identificador de recursos es un localizador uniforme de recursos (URL, por sus siglas en inglés) para designar recursos en Internet.
13. El método de cualquiera de las reivindicaciones 3 a 12, donde los identificadores son localizadores uniformes de recursos (URLs).
14. El método de cualquiera de las reivindicaciones 3 a 13, donde los identificadores de recursos comprenden nombres que deben ser convertidos por un Servicio de Nombres de Dominio (DNS, por sus siglas en inglés) o direcciones IP.
15. El método de la reivindicación 14, donde los nombres son nombres de equipos o nombres de dominio.
16. El método de cualquiera de las reivindicaciones 3 a 15, donde el primer identificador de recursos está incluido en otro recurso anteriormente solicitado por y servido al cliente.
17. El método de cualquiera de las reivindicaciones 3 a 16, donde la ubicación especificada por el primer identificador de recursos es un servidor origen.
18. El método de cualquiera de las reivindicaciones 3 a 17, donde la ubicación especificada por el primer identificador de recursos es distinta de la red de servidores repetidores.
19. El método de cualquiera de las reivindicaciones 1 a 8, donde el recurso solicitado es una imagen embebida.
20. El método de cualquiera de las reivindicaciones 1 a 19, donde el recurso solicitado en sí mismo contiene identificadores de recursos, y donde el método consta adicionalmente de:
21. El método de cualquiera de las reivindicaciones 1 a 20, donde los recursos son seleccionados del grupo que consta de: contenido de vídeo estático y dinámico, contenido de audio, texto, contenido de imagen, páginas web, archivos HTML, archivos XML, archivos en lenguaje descriptor, documentos, documentos de hipertexto, archivos de datos y recursos embebidos.
22. Red informática que consta de una red de servidores repetidores (104) para espejar al menos ciertos recursos almacenados en al menos un servidor origen (102), dichos servidores encontrándose adaptados para servir contenido a al menos un cliente (106), la red informática constando de medios para ejecutar el método de cualquiera de las reivindicaciones 1-21.
Patentes similares o relacionadas:
Procedimiento y dispositivo para el procesamiento de una solicitud de servicio, del 29 de Julio de 2020, de Advanced New Technologies Co., Ltd: Un procedimiento para el procesamiento de una solicitud de servicio, comprendiendo el procedimiento: recibir (S201), mediante un nodo de consenso, una solicitud […]
Método para un nivel mejorado de autenticación relacionado con una aplicación de cliente de software en un dispositivo informático de cliente que comprende una entidad de módulo de identidad de abonado con un kit de herramientas de módulo de identidad de abonado así como una miniaplicación de módulo de identidad de abonado, sistema, dispositivo informático de cliente y entidad de módulo de identidad de abonado para un nivel mejorado de autenticación relacionado con una aplicación de cliente de software en el dispositivo informático de cliente, programa que comprende un código de programa legible por ordenador y producto de programa informático, del 22 de Julio de 2020, de DEUTSCHE TELEKOM AG: Un método para un nivel mejorado de autenticación relacionado con una aplicación de cliente de software en un dispositivo informático […]
Método para atender solicitudes de acceso a información de ubicación, del 22 de Julio de 2020, de Nokia Technologies OY: Un aparato que comprende: al menos un procesador; y al menos una memoria que incluye un código de programa informático para uno o más programas, […]
Sincronización de una aplicación en un dispositivo auxiliar, del 22 de Julio de 2020, de OPENTV, INC.: Un método que comprende, mediante un dispositivo de medios: acceder, utilizando un módulo de recepción, un flujo de datos que incluye contenido […]
Transferencia automática segura de datos con un vehículo de motor, del 22 de Julio de 2020, de AIRBIQUITY INC: Un dispositivo electrónico en un vehículo para operar en un vehículo de motor en un estado de energía desatendido, comprendiendo el dispositivo […]
Método y aparato para configurar un identificador de dispositivo móvil, del 22 de Julio de 2020, de Advanced New Technologies Co., Ltd: Un método implementado por servidor para configurar un identificador de dispositivo móvil, que comprende: obtener una lista de aplicaciones, APP, […]
Procesamiento de contenido y servicios de redes para dispositivos móviles o fijos, del 8 de Julio de 2020, de AMIKA MOBILE CORPORATION: Un sistema para suministrar contenido de red a un dispositivo, comprendiendo el sistema : una primera interfaz para comunicarse con una pluralidad […]
Método de control de aplicación y terminal móvil, del 8 de Julio de 2020, de Guangdong OPPO Mobile Telecommunications Corp., Ltd: Un terminal móvil , que comprende: un procesador ; y un módulo de inteligencia artificial AI ; el procesador que se […]