Análisis lingüístico basado en una selección de palabras y dispositivo de análisis lingüístico.
Procedimiento para el análisis lingüístico automatizado basado en una selección de palabras,
que comprende los pasos: a) la preparación de un sistema informático (1.30) mediante
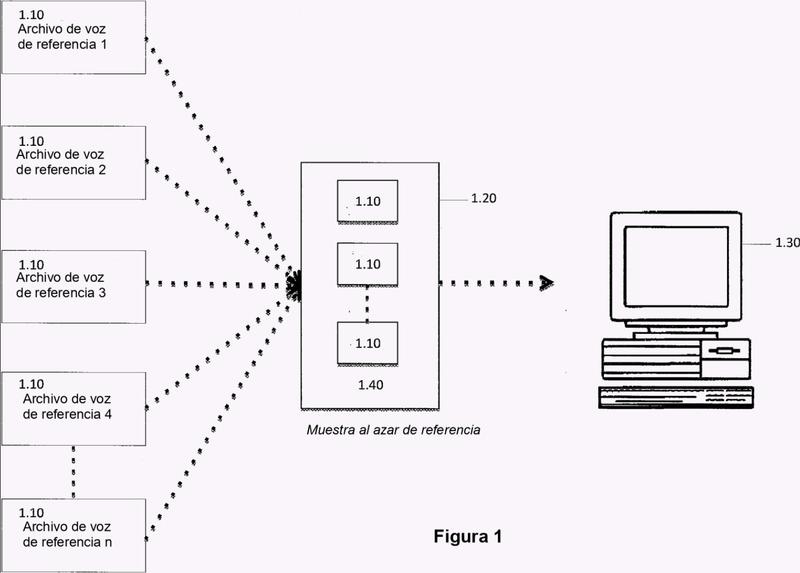
aa) el almacenamiento de varios archivos de voz de referencia (1.10) en una unidad de memoria (1.20) del sistema informático (1.30) para formar una muestra al azar de referencia (1.40), comprendiendo cada archivo de voz de referencia (1.10) una cantidad mínima de 100 palabras y procediendo todos los archivos de voz de referencia (1.10) de distintas personas que presentan características conocidas,
ab) el almacenamiento de un archivo de diccionario (2.20) con al menos 250 distintas categorías (2.10) en una unidad de memoria (1.20) del sistema informático (1.30), cubriendo el archivo de diccionario almacenado, que comprende el vocabulario central, al menos el 95 % de las palabras contenidas en los archivos de voz, y estando clasificadas todas las palabras del archivo de diccionario (2.20) en al menos una de las al menos 250 categorías (2.10),
ac) la realización de una comparación individual de cada archivo de voz de referencia (1.10) de la muestra al azar de referencia (1.40) con el archivo de diccionario (2.20) mediante la determinación de la frecuencia porcentual (3.40) de las palabras en cada archivo de voz de referencia (1.10) que están contenidas en cada categoría (2.10) del archivo de diccionario (2.20),
ad) el almacenamiento de un conjunto de reglas (5.40) en una unidad de memoria (1.20) del sistema informático (1.30), que con métodos estadísticos y/o algorítmicos determina relaciones al menos entre las frecuencias porcentuales (3.40), determinadas según la característica ac), en una o varias categorías (2.10), y al menos una característica (4.20) conocida de las personas de las que proceden los archivos de voz de referencia (1.10),
b) a continuación de la preparación del sistema informático según las características aa) a ad), el registro y el almacenamiento de un archivo de voz (6.10), adicionalmente a los archivos de voz de referencia (1.10) de la muestra al azar de referencia (1.40), en una unidad de memoria (1.20) del sistema informático (1.30), estando presentes cada archivo de voz (6.10) y cada archivo de voz de referencia directamente como archivo de texto o como archivo de audio, que mediante una transcripción se convierte en un archivo de texto,
c) el análisis del archivo de voz (6.10) registrado y almacenado adicionalmente según la característica b), mediante ca) la realización de una comparación individual del archivo de voz (6.10) con el archivo de diccionario (2.20) mediante la determinación frecuencia porcentual (7.30) de las palabras en el archivo de voz (6.10) que están contenidas en cada categoría (2.10) del archivo de diccionario (2.20),
cb) el procesamiento de las frecuencias porcentuales (7.30) determinadas según la característica ca), con la ayuda del conjunto de reglas (5.40) que con métodos estadísticos y/o algorítmicos examina las frecuencias porcentuales (7.30) determinadas según la característica ca) en cuanto a similitudes con las frecuencias porcentuales (3.40) determinadas según la característica ac), y que clasifica el archivo de voz (6.10) conforme a las similitudes detectadas y las asigna a al menos una característica conocida que presentan las personas de las que proceden los archivos de voz de referencia (1.10),
d) la creación de un archivo de salida (8.20) que contiene características (4.20) asignadas al archivo de voz (6.10) según la característica cb),
e) la emisión del archivo de salida (8.20),
en el que
ga) durante el registro del archivo de voz (6.10) adicional según la característica b), al menos una vez un archivo parcial del archivo de voz (6.10) se almacena de forma intermedia en la unidad de memoria (1.20) del sistema informático (1.30), comprendiendo cada archivo de voz (6.10) adicional al menos 100 palabras,
gb) el archivo parcial almacenado de forma intermedia se analiza mediante
gba) la realización de una comparación individual del archivo parcial con el archivo de diccionario (2.20) mediante la determinación de la frecuencia porcentual (7.30) de las palabras en el archivo parcial que están contenidas en cada categoría (2.10) del archivo de diccionario (2.20), gbb) el procesamiento de las frecuencias porcentuales (7.30) determinadas según la característica gba) con la ayuda del conjunto de reglas (5.40) que con métodos estadísticos y/o algorítmicos examina las frecuencias porcentuales (7.30) determinadas según la característica gba) en cuanto a similitudes con las frecuencias porcentuales (3.40) determinadas según la característica ac), y que clasifica el archivo parcial conforme a las similitudes detectadas y lo asigna a al menos una característica conocida que presentan las distintas personas de las que proceden los archivos de voz de referencia (1.10),
gc) la creación de un archivo de salida provisional que contiene características (4.20) asignadas al archivo parcial según la característica gbb),
gd) la emisión del archivo de salida provisional.
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/EP2014/053643.
Solicitante: PRECIRE Technologies GmbH.
Inventor/es: GRATZEL,DIRK C, GREB,CHRISTIAN.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G10L15/18 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › G10L 15/00 Reconocimiento de la voz (G10L 17/00 tiene prioridad). › utilizando una modelización del lenguaje natural.
PDF original: ES-2751375_T3.pdf
Patentes similares o relacionadas:
Aparato para responder a una llamada telefónica cuando un destinatario de la llamada telefónica decide que resulta inapropiado hablar y método relacionado, del 26 de Febrero de 2020, de Saronikos Trading and Services, Unipessoal Lda: Aparato (1a; 1b) para responder a una llamada telefónica cuando un destinatario de dicha llamada telefónica decide que resulta inapropiado hablar, […]
Creación de una base de datos de referencia de parámetros de habla para clasificar expresiones del habla, del 24 de Enero de 2018, de VOICESENSE LTD.: Un método implementado por ordenador de creación de una base de datos de referencia de parámetros de habla para clasificar expresiones del habla según diversas características […]
Sistemas y métodos para realizar ASR en presencia de palabras heterógrafas, del 7 de Junio de 2017, de Rovi Guides, Inc: Un aparato para corregir automáticamente los errores del reconocimiento del habla, el aparato comprende: medios para recibir una entrada verbal del usuario que […]
SISTEMA DE MENSAJERÍA INSTANTÁNEA, del 9 de Febrero de 2017, de PROYECTOS Y SOLUCIONES TECNOLÓGICAS AVANZADAS, S.L.P: Sistema de mensajería instantánea comprendiendo una aplicación de mensajería instantánea para la comunicación entre usuarios y máquinas mediante lenguaje […]
Sistema de mensajería instantánea, del 7 de Febrero de 2017, de PROYECTOS Y SOLUCIONES TECNOLÓGICAS AVANZADAS, S.L.P: Sistema de mensajería instantánea comprendiendo una aplicación de mensajería instantánea para la comunicación entre usuarios y máquinas mediante lenguaje natural, […]
Método para descubrir y reconocer patrones, del 18 de Febrero de 2015, de Aalto-Korkeakoulusäätiö: Método para reconocer un concepto en una señal, por ejemplo una señal de voz, mediante un aparato, comprendiendo el método: recibir , […]
Procedimiento, sistema y programa informático para recoger múltiples fragmentos de información durante un diálogo de usuario, del 17 de Septiembre de 2014, de 24/7 Customer, Inc: Un procedimiento implementado en ordenador para construir y procesar un diálogo multifranja con un usuario, que comprende las etapas de: activación de todas las […]
PROCEDIMIENTO PARA DELETREO NEMOTÉCNICO GENÉRICO, del 28 de Febrero de 2012, de MICROSOFT CORPORATION: Un procedimiento para crear un Modelo de Lenguaje de n - gramas para usar con una aplicación de software de reconocimiento del habla, comprendiendo […]