Codificación de cuadro/campo adaptativa de nivel de macrobloques para contenido de vídeo digital.
Un método para codificar una instantánea en una secuencia de imágenes,
que comprende:
dividir dicha instantánea en una pluralidad de porciones más pequeñas, donde cada una de dichas porciones más pequeñas es un par de macrobloques verticalmente adyacentes;
codificar de manera selectiva al menos una de dicha pluralidad de porciones más pequeñas en un momento en modo de codificación de cuadro y al menos una de dicha pluralidad de porciones más pequeñas en un momento en modo de codificación de campo; y
codificar de manera selectiva al menos un bloque en al menos una de dicha pluralidad de porciones más pequeñas en un momento en modo de inter codificación.
Tipo: Patente Europea. Resumen de patente/invención. Número de Solicitud: E10182629.
Solicitante: Google Technology Holdings LLC.
Nacionalidad solicitante: Estados Unidos de América.
Dirección: 1600 AMPHITHEATRE PARKWAY MOUNTAIN VIEW, CA 94043 ESTADOS UNIDOS DE AMERICA.
Inventor/es: LUTHRA, AJAY, PANUSOPONE,KRIT, WANG,LIMIN, GANDHI,RAJEEV.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- H04N19/10 ELECTRICIDAD. › H04 TECNICA DE LAS COMUNICACIONES ELECTRICAS. › H04N TRANSMISION DE IMAGENES, p. ej. TELEVISION. › H04N 19/00 Métodos o disposiciones para la codificación, decodificación, compresión o descompresión de señales de vídeo digital. › utilizando codificación adaptativa.
PDF original: ES-2548385_T3.pdf



Fragmento de la descripción:
Codificación de cuadro/campo adaptativa de nivel de macrobloques para contenido de vídeo digital Campo técnico
La presente invención se refiere a codificación y decodificación de contenido de video digital. Más específicamente, la presente invención se refiere a codificación de modo de cuadro y de modo de campo de contenido de vídeo digital a un nivel de macrobloques como se usa en la norma de codificación de vídeo de la norma MPEG-4 Parte 10
AVC/H.264.
Antecedentes
La compresión de vídeo se usa en muchos productos actuales y emergentes. Está en el corazón de los receptores de salón de televisión digital (STB), sistemas de satélite digital (DSS), decodificadores de televisión de alta definición (HDTV), reproductores de disco versátil digital (DVD), videoconferencia, contenido de vídeo y multimedia de internet y otras aplicaciones de vídeo digital. Sin la compresión de vídeo, el contenido de vídeo digital puede ser extremadamente grande, haciendo difícil o incluso imposible que se almacene, transmita o visualice eficazmente el contenido de vídeo digital.
El contenido de vídeo digital comprende un flujo de instantáneas que pueden presentarse como una imagen en un receptor de televisión, monitor de ordenador o algún otro dispositivo electrónico que pueda presentar contenido de vídeo digital. Una instantánea que se presenta en el tiempo antes de una instantánea particular está en la "dirección hacia atrás" en relación con la instantánea particular. De manera similar, una instantánea que se presenta en el tiempo después de una instantánea particular está en la "dirección hacia delante" en relación con la instantánea particular.
La compresión de vídeo se consigue en un proceso de codificación en el que cada instantánea se codifica como un cuadro o como dos campos. Cada cuadro comprende un número de líneas de información espacial. Por ejemplo, un cuadro típico contiene 480 líneas horizontales. Cada campo contiene la mitad del número de líneas en el cuadro. Por ejemplo, si el cuadro comprende 480 líneas horizontales, cada campo comprende 240 líneas horizontales. En una configuración típica, uno de los campos comprende las líneas con número impar en el cuadro y el otro campo comprende las líneas con número par en el cuadro. El campo que comprende las líneas con número impar se denominará como el campo "superior" en lo sucesivo y en las reivindicaciones adjuntas, a menos que se indique específicamente de otra manera. De manera similar, el campo que comprende las líneas con número par se denominará como el campo "inferior" en lo sucesivo y en las reivindicaciones adjuntas, a menos que se indique específicamente de otra manera. Los dos campos pueden entrelazarse juntos para formar un cuadro entrelazado.
La idea general detrás de la codificación de vídeo es eliminar datos del contenido de vídeo digital que sean "no esenciales". La cantidad reducida de datos a continuación requiere menos ancho de banda para difusión o transmisión. Después de que se hayan transmitido los datos de vídeo comprimido, deben decodificarse, o descomprimirse. En este proceso, los datos de vídeo transmitido se procesan para generar datos de aproximación que se sustituyen en los datos de vídeo para reemplazar los datos "no esenciales" que se eliminaron en el proceso de codificación.
La codificación de vídeo transforma el contenido de vídeo digital en una forma comprimida que puede almacenarse usando menos espacio y transmitirse usando menos ancho de banda que el contenido de vídeo digital no comprimido. Se hace aprovechando las redundancias temporales y espaciales en las instantáneas del contenido de vídeo. El contenido de vídeo digital puede almacenarse en un medio de almacenamiento tal como un disco duro, DVD o alguna otra unidad de almacenamiento no volátil.
Existen numerosos métodos de codificación de vídeo que comprimen el contenido de vídeo digital. En consecuencia, las normas de codificación de vídeo se han desarrollado para normalizar los diversos métodos de codificación de vídeo de modo que el contenido de vídeo digital comprimido se representa en formatos que puede reconocer una mayoría de codificadores y decodificadores de vídeo. Por ejemplo, el Grupo de Expertos en Imagen en Movimiento (MPEG) y la Unión Internacional de Telecomunicaciones (ITU-T) han desarrollado normas de codificación de vídeo que se usan ampliamente. Ejemplos de estas normas incluyen las normas MPEG-1, MPEG-2, MPEG-4, ITU-T H261 e ITU-T H263.
La mayoría de las normas de codificación de vídeo modernas, tales como aquellas desarrolladas mediante el MPEG y la ITU-T, están basadas en parte en una predicción temporal con algoritmo de compensación de movimiento (MC). La predicción temporal con compensación de movimiento se usa para eliminar la redundancia temporal entre instantáneas sucesivas en una difusión de vídeo digital.
La predicción temporal con algoritmo de compensación de movimiento utiliza típicamente una o dos instantáneas de referencia para codificar una instantánea particular. Una instantánea de referencia es una instantánea que ya se ha
codificado. Comparando la instantánea particular que se ha de codificar con una de las instantáneas de referencia, la predicción temporal con algoritmo de compensación de movimiento puede aprovechar la redundancia temporal que existe entre la instantánea de referencia y la instantánea particular que se ha de codificar y codificar la instantánea con una cantidad superior de compresión que si la instantánea se codificara sin usar la predicción temporal con algoritmo de compensación de movimiento. Una de las instantáneas de referencia puede estar en la dirección hacia atrás en relación con la instantánea particular que se ha de codificar. La otra instantánea de referencia está en la dirección hacia delante en relación con la instantánea particular que se ha de codificar.
Sin embargo, a medida que aumenta la demanda de resoluciones superiores, el contenido gráfico más complejo y el tiempo de transmisión más rápido, también lo hace la necesidad de mejores métodos de compresión de video. Para este fin, se está desarrollando actualmente una nueva norma de codificación de vídeo conjuntamente mediante la ISO y la ITU-T. Esta nueva norma de codificación de vídeo se denomina la norma MPEG-4 Codificación de Vídeo Avanzada (AVC) / H. 264.
El documento de P. BORGWARDT: "Core Experiment on Interlaced Video coding VCEG-N85" ITU - TELECOMMUNICATIONS STANDARDIZATION SECTOR ITU-T Q.6/SG16 VIDEO CODING EXPERT GROUP (VCEG), 24 de septiembre de 2001, páginas 1-10, evalúa diferentes cambios de sintaxis a exploración de campo entrelazado. Analiza la exploración de campo entrelazado junto con codificación de cuadro/campo adaptativa de macrobloques.
La Patente de Estados Unidos N° US 6.226.327 describe un método y aparato de codificación de vídeo que selecciona entre los modos predictivos basados en cuadro y basados en campo. El documento describe predicción basada en cuadro de cada macrobloque. Para la predicción de movimiento basada en campo de los de los macrobloques, un macrobloque y el macrobloque inmediatamente inferior se consideran como un grupo de macrobloques y se produce la predicción de agrupación de macrobloques mediante agrupación de macrobloques.
Sumario de la invención
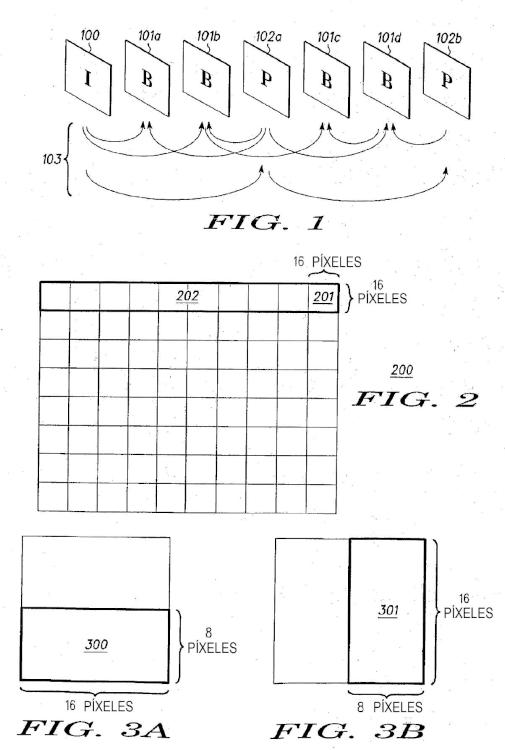
De acuerdo con los aspectos de la invención, se proporciona un método para codificar, un método para decodificar, un aparato para codificar y un aparato para decodificar, como se indica en las reivindicaciones adjuntas. En una de muchas posibles realizaciones, la presente invención proporciona un método para codificar, decodificar y la generación de flujos de bits de contenido de vídeo digital. El contenido de vídeo digital comprende un flujo de instantáneas que puede ser cada una de ¡ntra instantáneas, instantáneas predichas o bi-predichas. Cada una de las instantáneas comprende macrobloques que pueden dividirse adicionalmente en bloques más pequeños. El método implica codificar y decodificar cada uno de los de los macrobloques en cada instantánea en dicho flujo de instantáneas en modo de cuadro o en modo de campo.
Breve descripción de los dibujos
Los dibujos adjuntos ¡lustran diversas realizaciones de la presente invención y son una parte de la memoria descriptiva. Junto con la siguiente descripción, los dibujos demuestran y explican los principios de la presente invención. Las realizaciones ¡lustradas son ejemplos de la presente invención y no limitan el alcance de la invención.
La Figura 1 ¡lustra una secuencia ejemplar de tres tipos de instantáneas que pueden usarse para ¡mplementar la presente invención, como se define... [Seguir leyendo]
Reivindicaciones:
1. Un método para codificar una instantánea en una secuencia de imágenes, que comprende:
dividir dicha instantánea en una pluralidad de porciones más pequeñas, donde cada una de dichas porciones más pequeñas es un par de macrobloques verticalmente adyacentes;
codificar de manera selectiva al menos una de dicha pluralidad de porciones más pequeñas en un momento en modo de codificación de cuadro y al menos una de dicha pluralidad de porciones más pequeñas en un momento en modo de codificación de campo; y
codificar de manera selectiva al menos un bloque en al menos una de dicha pluralidad de porciones más pequeñas en un momento en modo de Ínter codificación.
2. El método de la reivindicación 1, donde se calcula al menos un vector de movimiento para dicho al menos un bloque en al menos una de dicha pluralidad de porciones más pequeñas.
3. El método de la reivindicación 2, donde dicho al menos un vector de movimiento está codificado con predicción de manera espacial para un bloque actual de dicha pluralidad de porciones más pequeñas.
4. Un aparato para codificar una instantánea en una secuencia de imágenes, que comprende:
medios para dividir dicha instantánea en una pluralidad de porciones más pequeñas, donde cada una de dichas porciones más pequeñas es un par de macrobloques verticalmente adyacentes;
medios para codificar de manera selectiva al menos una de dicha pluralidad de porciones más pequeñas en un momento en modo de codificación de cuadro y al menos una de dicha pluralidad de porciones más pequeñas en un momento en modo de codificación de campo; y
medios para codificar de manera selectiva al menos un bloque en al menos una de dicha pluralidad de porciones más pequeñas en un momento en modo de Ínter codificación.
5. El aparato de la reivindicación 4, donde se calcula al menos un vector de movimiento para dicho al menos un bloque en al menos una de dicha pluralidad de porciones más pequeñas.
6. El aparato de la reivindicación 5, donde dicho al menos un vector de movimiento está codificado con predicción de manera espacial para un bloque actual de dicha pluralidad de porciones más pequeñas.
7. El aparato de una cualquiera de las reivindicaciones 4 a 6, donde el al menos un bloque se divide adicionalmente en bloques con tamaño más pequeño que incluyen los mismos posibles tamaños de bloque en el modo de codificación de cuadro o en el modo de codificación de campo, los bloques con tamaño más pequeño son para uso en predicción temporal con compensación de movimiento.
8. El aparato de una cualquiera de las reivindicaciones 4 a 7, donde los medios para codificar de manera selectiva incluyen medios para codificar de manera selectiva un bloque desde el macrobloque de cuadro o el macrobloque de campo, el bloque es para uso en predicción temporal con compensación de movimiento con un tamaño de bloque que incluye 16 por 16 píxeles, 16 por 8 pixeles, 8 por 16 píxeles, 8 por 8 píxeles, 8 por 4 pixeles, 4 por 8 píxeles o 4 por 4 píxeles.
9. El aparato de una cualquiera de las reivindicaciones 4 a 8, donde los medios para codificar en modo de ínter codificación incluyen medios para codificar el macrobloque de cuadro o el macrobloque de campo, o un bloque con tamaño más pequeño desde el macrobloque de cuadro o el macrobloque de campo, incluyendo el bloque con tamaño más pequeño 16 por 8 píxeles, 8 por 16 píxeles, 8 por 8 píxeles, 8 por 4 píxeles, 4 por 8 píxeles o 4 por 4 píxeles.
10. Un método para decodificar una instantánea codificada que tiene una pluralidad de porciones más pequeñas desde un flujo de bits, que comprende:
decodificar al menos una de dicha pluralidad de porciones más pequeñas en un momento en modo de codificación de cuadro y al menos una de dicha pluralidad de porciones más pequeñas en un momento en modo de codificación de campo, donde cada una de dichas porciones más pequeñas es un par de macrobloques verticalmente adyacentes, donde al menos un bloque en dicha al menos una de dicha pluralidad de porciones más pequeñas en un momento se codifica en modo de Ínter codificación;
y
usar dicha pluralidad de porciones más pequeñas decodificadas para construir una instantánea decodificada.
11. El método de la reivindicación 10, donde se recibe al menos un vector de movimiento para dicho al menos un bloque en al menos una de dicha pluralidad de porciones más pequeñas.
12. El método de la reivindicación 11, donde dicho al menos un vector de movimiento está codificado con predicción de manera espacial para un bloque actual de dicha pluralidad de porciones más pequeñas.
13. El método de la reivindicación 12, donde dicho al menos un vector de movimiento está codificado con predicción de manera espacial desde una pluralidad de vectores de movimiento asociados con una pluralidad de bloques vecinos con relación a dicho bloque actual.
14. El método de la reivindicación 13, donde se obtienen dichos vectores de movimiento asociados con dicha pluralidad de bloques vecinos con relación a dicho bloque actual para generar al menos un vector de predicción de movimiento (PMV), donde dicho al menos un vector de predicción de movimiento (PMV) y un valor de diferencia recibido en el flujo de bits se usan para obtener dicho al menos un vector de movimiento de dicho bloque actual.
15. El método de la reivindicación 14, donde dicho al menos un PMV se calcula de acuerdo con una predicción de segmentación direccional.
16. Un aparato para decodificar una instantánea codificada desde un flujo de bits, que comprende:
medios para decodificar al menos una de una pluralidad de porciones más pequeñas en un momento de la instantánea codificada que se codifica en modo de codificación de cuadro y al menos una de dicha pluralidad de porciones más pequeñas en un momento de la instantánea codificada en modo de codificación de campo, donde cada una de dichas porciones más pequeñas es un par de macrobloques verticalmente adyacentes, donde al menos un bloque en al menos una de dicha pluralidad de porciones más pequeñas en un momento se codifica en modo de Ínter codificación; y
medios para usar dicha pluralidad de porciones más pequeñas decodificadas para construir una instantánea decodificada.
17. El aparato de la reivindicación 16, donde se recibe al menos un vector de movimiento para dicho al menos un bloque en al menos una de dicha pluralidad de porciones más pequeñas.
18. El aparato de la reivindicación 17, donde dicho al menos un vector de movimiento está codificado con predicción de manera espacial para un bloque actual de dicha pluralidad de porciones más pequeñas.
19. El aparato de la reivindicación 18, donde dicho al menos un vector de movimiento está codificado con predicción de manera espacial desde una pluralidad de vectores de movimiento asociados con una pluralidad de bloques vecinos con relación a dicho bloque actual.
20. El aparato de la reivindicación 19, donde dichos vectores de movimiento asociados con dicha pluralidad de bloques vecinos con relación a dicho bloque actual se usan para generar al menos un vector de predicción de movimiento (PMV), donde se calcula y codifica una diferencia entre dicho al menos un PMV y dicho al menos un vector de movimiento de dicho bloque actual.
21. El aparato de una cualquiera de las reivindicaciones 16 a 20, donde el al menos un bloque se divide en bloques con tamaño más pequeño que incluyen los mismos posibles tamaños de bloque en el modo de codificación de cuadro o el modo de codificación de campo, los bloques con tamaño más pequeño son para uso en predicción temporal con compensación de movimiento.
22. El aparato de una cualquiera de las reivindicaciones 16 a 21, donde el al menos un bloque o un bloque con tamaño más pequeño desde el al menos un bloque se codifica en modo de Ínter codificación, incluyendo el bloque con tamaño más pequeño 16 por 8 píxeles, 8 por 16 píxeles, 8 por 8 píxeles, 8 por 4 píxeles, 4 por 8 píxeles o 4 por 4 píxeles.
23. El aparato de una cualquiera de las reivindicaciones 16 a 22, donde el al menos un bloque es para uso en predicción temporal con compensación de movimiento con un tamaño de bloque que incluye 16 por 16 píxeles, 16 por 8 píxeles, 8 por 16 píxeles, 8 por 8 píxeles, 8 por 4 píxeles, 4 por 8 píxeles o 4 por 4 píxeles.
Patentes similares o relacionadas:
 Codificación de cuadro/campo adaptativa de nivel de macrobloques para contenido de vídeo digital, del 9 de Septiembre de 2015, de Google Technology Holdings LLC: Un método para codificar una instantánea en una secuencia de imágenes, que comprende:
dividir dicha instantánea en una pluralidad de porciones más […]
Codificación de cuadro/campo adaptativa de nivel de macrobloques para contenido de vídeo digital, del 9 de Septiembre de 2015, de Google Technology Holdings LLC: Un método para codificar una instantánea en una secuencia de imágenes, que comprende:
dividir dicha instantánea en una pluralidad de porciones más […]
 Codificación de cuadro/campo adaptativa de nivel de macrobloques para contenido de vídeo digital, del 29 de Julio de 2015, de Google Technology Holdings LLC: Un método para codificar una instantánea en una secuencia de imágenes, que comprende:
dividir dicha instantánea en una pluralidad de pares […]
Codificación de cuadro/campo adaptativa de nivel de macrobloques para contenido de vídeo digital, del 29 de Julio de 2015, de Google Technology Holdings LLC: Un método para codificar una instantánea en una secuencia de imágenes, que comprende:
dividir dicha instantánea en una pluralidad de pares […]
Codificación de cuadro/campo adaptativa de nivel de macrobloques para contenido de vídeo digital, del 22 de Julio de 2015, de Google Technology Holdings LLC: Un método para codificar o decodificar contenido de vídeo digital, comprendiendo dicho contenido de vídeo digital un flujo de instantáneas que puede […]
 Codificación de cuadro/campo adaptativa de nivel de macrobloques para contenido de vídeo digital, del 22 de Julio de 2015, de Google Technology Holdings LLC: Un método para codificar una instantánea en una secuencia de imagen, que comprende:
dividir dicha instantánea en una pluralidad de porciones más pequeñas, […]
Codificación de cuadro/campo adaptativa de nivel de macrobloques para contenido de vídeo digital, del 22 de Julio de 2015, de Google Technology Holdings LLC: Un método para codificar una instantánea en una secuencia de imagen, que comprende:
dividir dicha instantánea en una pluralidad de porciones más pequeñas, […]
 Modo truco en fotogramas predictivos bidireccionales, del 23 de Julio de 2014, de THOMSON LICENSING: Un método para llevar a cabo una congelación de imagen en modo truco en una señal de vídeo, que incluye los pasos de:
- recibir una instrucción de congelación de […]
Modo truco en fotogramas predictivos bidireccionales, del 23 de Julio de 2014, de THOMSON LICENSING: Un método para llevar a cabo una congelación de imagen en modo truco en una señal de vídeo, que incluye los pasos de:
- recibir una instrucción de congelación de […]