Codificación, modificación y síntesis de segmentos de voz.
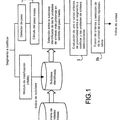
Procedimiento de análisis, modificación y síntesis de señales de voz que comprende:
-a. una fase de localización de ventanas de análisis mediante un proceso iterativo de determinación de la fase de la primera componente sinusoidal de la señal y comparación entre el valor de fase de dicha componente y un valor predeterminado hasta encontrar una posición para la que la diferencia de fase representa un desplazamiento temporal menor a media muestra de voz
-b. una fase de selección de tramas de análisis correspondientes a un alófono y reajuste de la duración y la frecuencia fundamental según un modelo, de manera que si la diferencia entre la duración original o la frecuencia fundamental original y las que se quieren imponer supera unos umbrales, se ajustan la duración y la frecuencia fundamental para generar tramas de síntesis.
-c. una fase de generación de voz sintética a partir de las tramas de síntesis tomando como información espectral de la trama de síntesis la información de la trama de análisis más cercana y tomando tantas tramas de síntesis como periodos tenga la señal sintética.
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/EP2010/070353.
Solicitante: TELEFONICA, S.A..
Nacionalidad solicitante: España.
Inventor/es: RODRIGUEZ CRESPO, MIGUEL ANGEL, ESCALADA SARDINA,José Gregorio, ARMENTA LOPEZ DE VICUÑA,Ana.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G10L13/02 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › G10L 13/00 Síntesis de la voz; Sistemas de síntesis de la voz a partir de texto. › Métodos de producción de voz sintética; Sintetizadores de voz.
- G10L13/033 G10L 13/00 […] › Edición de voz, p. ej. manipulando la voz del sintetizador.
- G10L13/06 G10L 13/00 […] › Unidades de voz elementales utilizadas en sintetizadores de voz; reglas de concatenación.
- G10L19/08 G10L […] › G10L 19/00 Técnicas de análisis-síntesis de la voz o de señales de audio para la reducción de la redundancia, p. ej. en codificadores vocales; Codificación o decodificación de la voz o de señales de audio, utilizando modelos filtro-fuente o el análisis psicoacústico (en instrumentos musicales G10H). › Determinación o codificación de la función de excitación; Determinación de los parámetros de predicción a largo plazo.
- G10L19/093 G10L 19/00 […] › usando modelos de excitación sinusoidales.
PDF original: ES-2532887_T3.pdf
Fragmento de la descripción:
Codificación, modificación y síntesis de segmentos de voz Campo de la invención
La presente invención se aplica a las tecnologías del habla. Más concretamente, se refiere a las técnicas de tratamiento digital de señales de voz usadas, entre otros, dentro de conversores texto-voz.
Antecedentes de la invención
Muchos de los sistemas de conversión texto-voz actuales se basan en la concatenación de unidades acústicas tomadas de voz pregrabada. Esta aproximación es la que permitió dar el salto de calidad necesario para el uso de conversores texto-voz en multitud de aplicaciones comerciales (fundamentalmente, en la generación de Información hablada a partir de texto en sistemas de respuesta vocal interactiva a los que se accede telefónicamente).
Aunque la concatenación de unidades acústicas permite obviar el difícil problema de modelar completamente la producción de la voz humana, tiene que manejar otro problema básico: cómo concatenar trozos de voz tomados de distintos ficheros de origen, que pueden presentar diferencias apreciables en los puntos de concatenación.
Las posibles causas de discontinuidad y defectos en la voz sintética son de diverso tipo:
1. La diferencia en las características del espectro de la señal en los puntos de concatenación: frecuencias y anchos de banda de los formantes, forma y amplitud de la envolvente espectral.
2. Pérdida de la coherencia de fase entre las tramas de voz que se concatenan. Se pueden ver también como desplazamientos relativos inconsistentes de la posición de las tramas de voz (ventanas) a ambos lados de un punto de concatenación. La concatenación entre tramas incoherentes produce una desintegración o dispersión de la forma de onda que se percibe como una importante pérdida de calidad. La voz resultante suena poco natural: mezclada y confusa.
3. Diferencias prosódicas (entonación y duración) entre las unidades pregrabadas y la prosodia objetivo (deseada) para la síntesis de un enunciado.
Por este motivo, los conversores texto-voz suelen emplear diversos procedimientos de tratamiento de señales de voz que permiten, tras la concatenación de unidades, unirlas suavemente en los puntos de concatenación, y modificar su prosodia para que resulte continua y natural. Y todo ello debe hacerse degradando lo menos posible la
señal original.
Los sistemas de conversión texto-voz más tradicionales contaban con un repertorio de unidades relativamente reducido (por ejemplo, difonemas o demisílabas), en los que normalmente sólo se disponía de un candidato para cada una de las posibles combinaciones de sonidos contempladas. En estos sistemas la necesidad de hacer modificaciones a las unidades es muy elevada.
Los sistemas de conversión texto-voz más recientes se basan en la selección de unidades de un inventario mucho más amplio (síntesis por corpus). Este amplio inventario dispone de muchas alternativas de las diferentes combinaciones entre sonidos, que se diferencian en su contexto fonético, prosodia, posición dentro de la palabra y del enunciado. La selección óptima de esas unidades de acuerdo a un criterio de coste mínimo (costes de unidad y de concatenación) permite reducir la necesidad de hacer modificaciones en las unidades, y mejora mucho la calidad y naturalidad de la voz sintética resultante. Pero no es posible eliminar totalmente la necesidad de manipular las unidades pregrabadas, porque los corpus de voz son finitos y no pueden asegurar una completa cobertura para sintetizar de manera natural cualquier enunciado, y siempre habrá puntos de concatenación.
Existen distintos procedimientos de representación y modificación de señales de voz que han sido usados dentro de conversores texto-voz.
Los procedimientos basados en el solapamiento y suma de ventanas de la señal de voz en el dominio temporal (procedimientos PSOLA, "Pitch Synchronous Overlap and Add") gozan de gran aceptación y difusión. El más clásico de estos procedimientos aparece descrito en "Pitch-synchronous waveform processing techniques for text-to-speech synthesis using dyphones" (E. Moulines y F. Charpentier, Speech Communication, vol. 9, pp. 453-467, dic. 199). Se obtienen tramas (ventanas) de la señal de voz de manera síncrona con el periodo fundamental ("pitch"). Las ventanas de análisis deben estar centradas en los instantes de cierre de la glotis (GCIs, "Glottal Closure Instants") u otros puntos identificables dentro de cada periodo de la señal, que deben encontrarse cuidadosamente y ser etiquetados coherentemente, para evitar desajustes de fase en los puntos de concatenación. El marcado de estos puntos es una tarea laboriosa que no se puede realizar de forma completamente automática (requiere ajustes), y que condiciona el buen funcionamiento del sistema. La modificación de duración y frecuencia fundamental (F) se realiza mediante la inserción o borrado de tramas, y el alargamiento o estrechamiento de las mismas (cada trama de síntesis es un periodo de la señal, y el desplazamiento entre dos tramas sucesivas es el inverso de la frecuencia
fundamental). Puesto que los procedimientos PSOLA no Incluyen un modelo explícito de la señal de voz, la tarea de interpolar las características espectrales de la señal en los puntos de concatenación resulta difícil de realizar.
El procedimiento MBROLA ("Multl-Band Resynthesls Overlap and Add") descrito en "Text-to-Speech Synthesls based on a MBE re-synthesis of the segments database" (T. Dutoit y H. Leich, Speech Communlcatlon, vol. 13, pp. 435-44, 1993) aborda el problema de la falta de coherencia de fase en las concatenaciones sintetizando una versión modificada de las partes sonoras de la base de datos de voz, forzando que tengan un F y una fase determinada (Igual en todos los casos). Pero este proceso afecta a la naturalidad de la voz.
También se han propuesto procedimientos tipo LPC ("Linear Predlctive Coding") para hacer síntesis de voz, como el descrito en "An approach to Text-to-Speech synthesls" (R. Sproat and J. Olive, Speech Coding and Synthesis, pp. 611-633, Elsevler, 1995). Estos procedimientos limitan la calidad de la voz al suponer un modelo de sólo polos. El resultado depende mucho de si la voz original de referencia se ajusta mejor o peor a las suposiciones del modelo. Suele plantear problemas especialmente con voces femeninas e Infantiles.
También se han propuesto modelos de tipo sinusoidal, en los que la señal de voz se representa mediante una suma de componentes sinusoidales. Los parámetros de los modelos sinusoidales permiten hacer de forma bastante directa e Independiente tanto la Interpolación de parámetros como las modificaciones prosódicas. En cuanto a asegurar la coherencia de fase en los puntos de concatenación, algunos modelos han optado por manejar un estimador de los Instantes de cierre de la glotis (proceso que no siempre da buenos resultados), como por ejemplo en "Speech Synthesis based on Sinusoidal Modellng" (M. W. Macón, PhD Thesls, Georgia Instltute of Technology, oct. 1996). En otros casos se ha asumido la simplificación de considerar una hipótesis de fase mínima (que afecta a la naturalidad de la voz en algunos casos, haciendo que se perciba más hueca y amortiguada), como en un trabajo publicado por algunos de los Inventores de esta propuesta: "On the Use of a Sinusoidal Model for Speech Synthesis ¡n Text-to-Speech" (M. Á. Rodríguez, P. Sanz, L. Monzón y J. G. Escalada, Progress ¡n Speech Synthesls, pp. 57-7, Sprlnger, 1996).
Los modelos sinusoidales han ¡do incorporando diferentes aproximaciones para resolver el problema de la coherencia de fase. En "Removlng Linear Phase Mlsmatches ¡n Concatenatlve Speech Synthesls" (Y. Stylianou, IEEE Transactlons on Speech and Audio Processing, vol. 9, no. 3, pp. 232-239 marzo 21) se propone un procedimiento para analizar la voz con ventanas que se desplazan de acuerdo al F de la señal, pero sin necesidad de que estén centradas en los GCIs. Esas tramas son sincronizadas a posteriori en un punto común basándose en la información del espectro de fase de la señal, sin afectar a la calidad de la voz. Se aplica la propiedad de la Transformada de Fourier, en la que añadir una componente lineal al espectro de fase equivale a desplazar la forma de onda en el dominio del tiempo. Se fuerza que el primer armónico de la señal quede con una fase resultante de valor , y el resultado es que todas las ventanas de voz quedan centradas de manera coherente respecto a la forma de onda, independientemente de en qué punto concreto de un periodo de la señal se centró originalmente. Así, las tramas corregidas pueden ser combinadas de manera coherente en la síntesis.
Para la extracción de parámetros se realizan procedimientos de análisis mediante síntesis como... [Seguir leyendo]
Reivindicaciones:
1. Procedimiento de análisis, modificación y síntesis de señales de voz que comprende:
-a. una fase de localización de ventanas de análisis mediante un proceso iterativo de determinación de la fase de la primera componente sinusoidal de la señal y comparación entre el valor de fase de dicha componente y un valor predeterminado hasta encontrar una posición para la que la diferencia de fase representa un desplazamiento temporal menor a media muestra de voz
-b. una fase de selección de tramas de análisis correspondientes a un alófono y reajuste de la duración y la frecuencia fundamental según un modelo, de manera que si la diferencia entre la duración original o la frecuencia fundamental original y las que se quieren imponer supera unos umbrales, se ajustan la duración y la frecuencia fundamental para generar tramas de síntesis.
-c. una fase de generación de voz sintética a partir de las tramas de síntesis tomando como información espectral de la trama de síntesis la información de la trama de análisis más cercana y tomando tantas tramas de síntesis como periodos tenga la señal sintética.
2. Procedimiento según la reivindicación 1, en el que una vez localizada la primera ventana de análisis se busca la siguiente desplazándose medio periodo y así sucesivamente.
3. Procedimiento según las reivindicaciones 1 o 2, en el que se realiza una corrección de fase añadiendo una componente lineal a la fase de todas las sinusoides de la trama.
4. Procedimiento según cualquiera de las reivindicaciones anteriores, en el que el umbral de modificación para la duración es menor del 25%.
5. Procedimiento según la reivindicación 4, en el que el umbral de modificación para la duración es menor del 15%.
6. Procedimiento según cualquiera de las reivindicaciones anteriores, en el que el umbral de modificación para la frecuencia fundamental es menor del 15%.
7. Procedimiento según la reivindicación 6, en el que el umbral de modificación para la frecuencia fundamental es menor del 1%.
8. Procedimiento según cualquiera de las reivindicaciones anteriores, en el que la fase de generación a partir de las tramas de síntesis se realiza por solapamiento y suma con ventanas triangulares.
9. Uso del procedimiento de cualquiera de las reivindicaciones anteriores en conversores de texto-voz.
1. Uso del procedimiento de cualquiera de las reivindicaciones 1 a 9 para mejorar la inteligibilidad de las grabaciones de voz.
11. Uso del procedimiento de cualquiera de las reivindicaciones 1 a 9 para concatenar segmentos de grabaciones de voz diferenciados en cualquier característica de su espectro.
Patentes similares o relacionadas:
PROCEDIMIENTO PARA LA SINTESIS DE DIFONEMAS Y/O POLIFONEMAS A PARTIR DE LA ESTRUCTURA FRECUENCIAL REAL DE LOS FONEMAS CONSTITUYENTES, del 7 de Junio de 2012, de UNIVERSITAT POLITECNICA DE CATALUNYA: La presente invención se refiere al procedimiento para la generación de la señal acústica de voz sintética de sonidos a partir de una mínima información previa de […]
DISPOSITIVO Y PROCEDIMIENTO DE SINTESIS DEL HABLA., del 1 de Marzo de 2007, de MATSUSHITA ELECTRIC INDUSTRIAL CO., LTD.: Aparato de síntesis del habla para sintetizar el habla consistente en una pluralidad de segmentos de habla, cada uno de los cuales comprende por lo menos un fonema, […]
IDENTIFICACION DE REGIONES DE SOLAPADO DE UNIDADES PARA UN SISTEMA DE SINTESIS DE HABLA POR CONCATENACION., del 1 de Mayo de 2004, de MATSUSHITA ELECTRIC INDUSTRIAL CO., LTD. FRANK, ARMIN: Un método para identificar una región de solapado de unidades para la síntesis de habla por concatenación, que comprende: la definición de un modelo […]
SINTETIZADOR DE HABLA BASADO EN FOMANTES QUE UTILIZA UNA CONCATENACION DE SEMISILABAS CON TRANSICION INDEPENDIENTE POR FUNDIDO GRADUAL EN LOS DOMINIOS DE LOS COEFICIENTES DE FILTRO Y DE FUENTES., del 16 de Abril de 2004, de MATSUSHITA ELECTRIC INDUSTRIAL CO., LTD.: Un sintetizador de habla concatenativo, que comprende: una base de datos que contiene (a) unos datos de formas de onda de semisílabas asociados con una pluralidad […]
SISTEMA DE SINTESIS DE LA PALABRA Y BASE DE DATOS DE FORMAS DE ONDAS DE REDUNDANCIA REDUCIDA., del 1 de Agosto de 2003, de MATSUSHITA ELECTRIC INDUSTRIAL CO., LTD.: SE REVELA UN SISTEMA DE SINTESIS DEL HABLA QUE UTILIZA UNA BASE DE DATOS DE FORMAS DE ONDA QUE POSEE UNA REDUNDANCIA REDUCIDA. CADA UNA DE LAS FORMAS DE ONDA DE UN CONJUNTO […]
PROCEDIMIENTO Y DISPOSICION PARA LA DETERMINACION DE CARACTERISTICAS ESPECTRALES DE LA VOZ EN UNA EXPRESION VERBAL., del 16 de Noviembre de 2002, de SIEMENS AKTIENGESELLSCHAFT: Bastidor con forma de marco, en especial bastidor de pared lateral para palets, que está compuesto de varios listones de perfil que rodean a una […]
PROCEDIMIENTO Y DISPOSITIVO PARA LA SINTESIS DE SEÑALES VOCALES., del 16 de Octubre de 2002, de MATSUSHITA ELECTRIC INDUSTRIAL CO., LTD.: UN APARATO DE SINTESIS DEL HABLA QUE DEFORMA Y CONECTA LOS TROZOS DEL HABLA PARA SINTETIZAR EL HABLA, TIENE UNA BASE DE DATOS, DE FORMAS DE ONDA […]
 PROCEDIMIENTO DE SELECCION DE UNIDADES DE SINTESIS, del 16 de Octubre de 2009, de THALES: Procedimiento de selección de unidades de síntesis de una información que se presenta en forma de un segmento de palabra a codificar y que puede descomponerse en […]
PROCEDIMIENTO DE SELECCION DE UNIDADES DE SINTESIS, del 16 de Octubre de 2009, de THALES: Procedimiento de selección de unidades de síntesis de una información que se presenta en forma de un segmento de palabra a codificar y que puede descomponerse en […]