Reconocimiento de voz distribuido utilizando una comunicación unidireccional.
Un método puesto en práctica por ordenador que comprende:
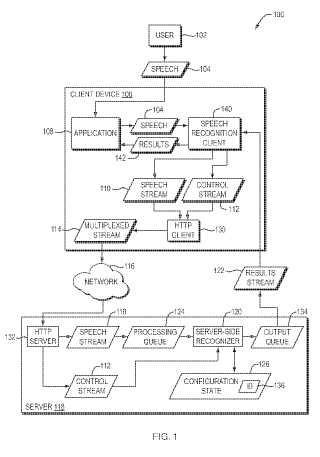
(A) al nivel de un cliente (106),
la transmisión de un flujo de voz y de un flujo de control a un servidor dereconocimiento de voz (118) utilizando un Protocolo de Transferencia de Hipertexto, HTTP, que tiene unprimer periodo de temporización;
(B) al nivel del servidor de reconocimiento de voz, la utilización de un motor de reconocimiento de vozautomático para iniciar el reconocimiento del flujo de voz;
(C) al nivel del cliente, la transmisión de una primera demanda de un resultado de reconocimiento de voz alservidor de reconocimiento de voz utilizando HTTP y
(D) al nivel de servidor de reconocimiento de voz, la transmisión de una notificación al cliente indicando queningún resultado de reconocimiento de voz se hizo disponible dentro de un segundo periodo detemporización que difiere del primer periodo de temporización y
(E) al nivel del cliente, en respuesta a la recepción de la notificación, la transmisión de una segunda demandadel resultado de reconocimiento de voz al servidor de reconocimiento de voz utilizando HTTP.
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/US2009/055480.
Solicitante: Multimodal Technologies, LLC.
Nacionalidad solicitante: Estados Unidos de América.
Dirección: 1710 Murray Avenue Pittsburgh, PA 15217 ESTADOS UNIDOS DE AMERICA.
Inventor/es: KOLL,DETLEF, CARRAUX,ERIC.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G10L19/00 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › Técnicas de análisis-síntesis de la voz o de señales de audio para la reducción de la redundancia, p. ej. en codificadores vocales; Codificación o decodificación de la voz o de señales de audio, utilizando modelos filtro-fuente o el análisis psicoacústico (en instrumentos musicales G10H).
PDF original: ES-2446667_T3.pdf
Fragmento de la descripción:
Reconocimiento de voz distribuido utilizando una comunicación unidireccional
.
ANTECEDENTES DE LA INVENCIÓN
Una diversidad de reconocedores de voz automáticos (ASRs) existen para realizar funciones tales como convertir voz en texto y controlar las operaciones de un ordenador en respuesta a la voz. Algunas aplicaciones de reconocedores de voz automáticos requieren tiempos de ida y retorno más cortos (la cantidad de tiempo entre cuando la voz es emitida y cuando el reconocedor de voz proporciona la salida) que otros para atender a las exigencias operativas del usuario final. A modo de ejemplo, un reconocedor de voz que se utiliza para una aplicación "en vivo" del reconocimiento de voz, tal como controlar el movimiento de un cursor en una pantalla, puede requerir un tiempo de ida y retorno más corto (también referido como un "tiempo de respuesta”) que un reconocedor de voz que se utiliza para generar una transcripción de un informe médico.
El tiempo de respuesta deseado puede depender, a modo de ejemplo, del contenido de la vocalización que se procesa por el reconocedor de voz. A modo de ejemplo, para una vocalización de orden y control corta, tal como "cerrar ventana", un tiempo de respuesta superior a 500 ms puede parecer de lentitud excesiva para el usuario final. Al contrario, para una larga frase dictada que el usuario desea transcribir en texto, los tiempos de respuesta de 1000 ms pueden ser aceptables para el usuario final. De hecho, en este último caso, los usuarios pueden preferir tiempos de respuesta más largos porque, de no ser así, pueden sentir que su voz está siendo interrumpida por la visualización inmediata de texto en respuesta a su voz. Para dictados más largos, tales como párrafos enteros, tiempos de respuesta incluso más largos, de múltiples segundos pueden ser aceptables para el usuario final.
En los sistemas de reconocimiento de voz típicos de la técnica anterior, un tiempo de respuesta creciente mientras se mantiene la exactitud del reconocimiento requiere aumentar los recursos informáticos (ciclos de procesamiento y/o memoria) que se dediquen a realizar el reconocimiento de voz. En consecuencia, cualesquiera aplicaciones que requieran tiempos de respuesta rápidos exigen que el sistema de reconocimiento de voz se ejecute en el mismo ordenador en el que se ejecutan esas mismas aplicaciones. Aunque dicha ubicación puede eliminar el retardo que, de no ser así, se introduciría al exigir que los resultados del reconocimiento de voz sean transmitidos a la aplicación demandante a través de una red, dicha situación tiene también una diversidad de inconvenientes.
A modo de ejemplo, la ubicación operativa requiere que un sistema de reconocimiento de voz haya de instalarse en cada dispositivo del usuario final – tal como en cada ordenador de sobremesa, ordenador portátil, teléfono móvil y
asistente digital personal (PDA) – lo que exige la funcionalidad del reconocimiento de voz. La instalación y mantenimiento de dichos sistemas de reconocimiento de voz en tan gran número y amplia diversidad de dispositivos puede ser tediosa y consumidora de tiempo para los usuarios finales y los administradores de sistemas. A modo de ejemplo, dicho mantenimiento requiere que se actualicen los denominados binarios de sistemas cuando una nueva versión del sistema de reconocimiento de voz se haga disponible. Los datos de los usuarios, tales como modelos de la voz, se crean y acumulan, en el transcurso del tiempo, sobre los dispositivos individuales, ocupando un espacio de almacenamiento de alto valor y la necesidad de sincronizarse con múltiples dispositivos utilizados por el mismo usuario. Dicho mantenimiento puede hacerse particularmente oneroso cuando los usuarios sigan utilizando los sistemas de reconocimiento de voz en un más amplio número y diversidad de dispositivos.
Además, la localización de un sistema de reconocimiento de voz en el dispositivo del usuario final hace que el sistema de reconocimiento de voz consuma recursos informáticos valiosos, tales como ciclos de procesamiento de la unidad central CPU, memoria principal y espacio de disco. Dichos recursos son particularmente escasos en dispositivos móviles portátiles, tales como teléfonos móviles. La producción de resultados del reconocimiento de voz, con tiempos de respuesta rápidos, utilizando tales dispositivos, exige normalmente menoscabar la exactitud del reconocimiento y reducir los recursos disponibles para otras aplicaciones que se ejecuten en el mismo dispositivo.
Una técnica conocida para superar estas limitaciones de recursos, en el contexto de dispositivos incorporados consiste en delegar parte o la totalidad de la responsabilidad del procesamiento del reconocimiento de voz a un servidor del reconocimiento de voz que esté situado a considerable distancia del dispositivo incorporado y que 55 disponga de bastantes más recursos informáticos que el dispositivo incorporado. Cuando un usuario habla en el dispositivo incorporado en esta situación, el dispositivo incorporado no intenta reconocer la voz utilizando sus propios recursos operativos. En cambio, el dispositivo incorporado transmite la voz (o una forma procesada de la voz) por intermedio de una conexión de red al servidor de reconocimiento de voz, que reconoce la voz utilizando sus mayores recursos informáticos y, por lo tanto, produce resultados del reconocimiento con mayor rapidez que el dispositivo incorporado podría haber proporcionado con la misma exactitud. El servidor de reconocimiento de voz transmite, a continuación, los resultados de nuevo, a través de la conexión de la red, al dispositivo incorporado. En condiciones ideales, esta técnica produce resultados del reconocimiento de voz de gran exactitud y con mayor rapidez que sería posible, de no ser así, utilizando el dispositivo incorporado por sí solo.
En la práctica, sin embargo, esta técnica de "reconocimiento de voz en el lado del servidor" tiene numerosos inconvenientes. En particular, por cuanto que el reconocimiento de voz, en el lado del servidor, se basa en la disponibilidad de conexiones de la red, de alta velocidad y fiables, la técnica falla si dichas conexiones no están disponibles cuando se necesiten. A modo de ejemplo, los potenciales aumentos en la velocidad, hechos posibles por el reconocimiento de voz en el lado del servidor, pueden negarse por el uso de una conexión de red sin un ancho de banda suficientemente alto. A modo de ejemplo, la latencia típica de la red de una llamada de HTTP a un servidor
distante puede variar desde 100 ms a 500 ms. Si los datos hablados llegan a un servidor de reconocimiento de voz 500 ms después de emitirse, será imposible para ese servidor producir resultados con suficiente rapidez para actuar con el tiempo de respuesta mínimo (500 ms) requerido por las aplicaciones de órdenes y de control. En consecuencia, incluso el más rápido servidor de reconocimiento de voz producirá resultados que parezcan demasiado lentos si se usan en combinación con una conexión de red lenta.
Además, las técnicas convencionales de reconocimiento de voz, en el lado del servidor, suponen que la conexión de red establecida entre el cliente (p.e. dispositivo incorporado) y el servidor de reconocimiento de voz se mantiene activa continuamente durante el proceso de reconocimiento completo. Aunque hubiera la posibilidad de satisfacer esta condición en una Red de Área Local (LAN) o cuando ambos, cliente y servidor, sean gestionados por la misma entidad, esta condición puede ser imposible, o al menos irrazonable, de satisfacer cuando el cliente y el servidor estén conectados a través de una Red de Área Amplia (WAN) o de Internet, en cuyo caso, las interrupciones para la conexión de la red pueden ser frecuentes e inevitables.
Además, las organizaciones suelen restringir las clases de comunicaciones que sus usuarios puedan realizar a través de redes públicas tales como Internet. A modo de ejemplo, las organizaciones sólo pueden permitir a los clientes, dentro de sus redes, realizar comunicaciones salientes. Esto significa que un cliente puede entrar en contacto con un servidor externo en un determinado puerto, pero que el servidor no puede iniciar un contacto con el cliente. Lo que antecede es una realización, a modo de ejemplo, de una comunicación unidireccional.
Otra frecuente restricción impuesta sobre los clientes es que sólo pueden usar una gama limitada de puertos de salida para comunicarse con servidores externos. Además, puede exigirse que la comunicación saliente, en esos puertos, haya de estar encriptada. A modo de ejemplo, a los clientes se les suele permitir utilizar solamente el puerto HTTP estándar (puerto 80) o el puerto HTTPS estándar seguro encriptado (puerto 443) .
Lo... [Seguir leyendo]
Reivindicaciones:
1. Un método puesto en práctica por ordenador que comprende:
(A) al nivel de un cliente (106) , la transmisión de un flujo de voz y de un flujo de control a un servidor de reconocimiento de voz (118) utilizando un Protocolo de Transferencia de Hipertexto, HTTP, que tiene un primer periodo de temporización;
(B) al nivel del servidor de reconocimiento de voz, la utilización de un motor de reconocimiento de voz automático para iniciar el reconocimiento del flujo de voz;
(C) al nivel del cliente, la transmisión de una primera demanda de un resultado de reconocimiento de voz al servidor de reconocimiento de voz utilizando HTTP y
(D) al nivel de servidor de reconocimiento de voz, la transmisión de una notificación al cliente indicando que ningún resultado de reconocimiento de voz se hizo disponible dentro de un segundo periodo de temporización que difiere del primer periodo de temporización y
(E) al nivel del cliente, en respuesta a la recepción de la notificación, la transmisión de una segunda demanda del resultado de reconocimiento de voz al servidor de reconocimiento de voz utilizando HTTP.
2. El método según la reivindicación 1, que comprende, además:
(F) al nivel del servidor de reconocimiento de voz (118) , el reconocimiento de una primera parte del flujo de voz 25 para producir un primer resultado de reconocimiento de voz y
(G) la transmisión del primer resultado de reconocimiento de voz al cliente (106) utilizando HTTP en respuesta a la segunda demanda.
3. El método según la reivindicación 2, en donde (G) comprende:
(G) (1) la determinación de si cualesquiera resultados de reconocimiento de voz están disponibles;
(G) (2) si no están disponibles resultados del reconocimiento de voz, volver a (G) (1) ; 35
(G) (3) si no es así, la transmisión del primer resultado de reconocimiento de voz al cliente (106) .
4. El método según la reivindicación 3, en donde el servidor de reconocimiento de voz (118) realiza (F) y (G) en paralelo.
5. El método según la reivindicación 1, en donde (A) comprende la transmisión del flujo de voz y del flujo de control utilizando un Protocolo de Transferencia de Hipertexto sobre la Capa de Conexión Segura HTTPS, y en donde (C) comprende la transmisión de la primera demanda utilizando HTTPS.
en donde el dispositivo cliente comprende:
medios (110, 112) para efectuar la transmisión de un flujo de voz y de un flujo de control al servidor de reconocimiento de voz utilizando un Protocolo de Transferencia de Hipertexto, HTTP, que tiene un primer periodo de temporización;
medios para efectuar la transmisión de una primera demanda de un resultado de reconocimiento de voz al servidor de reconocimiento de voz utilizando HTTP y
en donde el servidor de reconocimiento de voz comprende:
medios para, utilizando un motor de reconocimiento de voz automático (120, 218) , iniciar el reconocimiento del flujo de voz;
medios para efectuar la transmisión de una notificación al dispositivo cliente indicando que ningún resultado de reconocimiento de voz se hizo disponible dentro de un segundo periodo de temporización que difiere del primer periodo de temporización y
en donde el dispositivo cliente comprende, además, medios para efectuar, en respuesta a la recepción de la notificación, la transmisión de una segunda demanda del resultado del reconocimiento de voz al servidor de reconocimiento de voz utilizando HTTP.
7. Un método puesto en práctica por ordenador realizado por un servidor de reconocimiento de voz (118) , cuyo método comprende: 5
(A) la recepción de un flujo de voz y de un flujo de control desde un cliente (106) utilizando un Protocolo de Transferencia de Hipertexto, HTTP, que tiene un primer periodo de temporización;
(B) la utilización de un motor de reconocimiento de voz automático para iniciar un reconocimiento del flujo de 10 voz;
(C) la recepción de una primera demanda de un resultado de reconocimiento de voz desde el cliente utilizando HTTP y
(D) la transmisión de una notificación al cliente indicando que ningún resultado de reconocimiento de voz se hizo disponible dentro de un segundo periodo de temporización que difiere del primer periodo de temporización.
8. El método según la reivindicación 7 que comprende, además: 20
(E) la recepción de una segunda demanda del resultado de reconocimiento de voz desde el cliente (106) utilizando HTTP;
(F) el reconocimiento de una primera parte del flujo de voz para producir un primer resultado de reconocimiento 25 de voz y
(G) la transmisión del primer resultado de reconocimiento de voz al cliente utilizando HTTP en respuesta a la segunda demanda.
medios para efectuar la recepción de un flujo de voz (110) y de un flujo de control (112) desde un cliente (106) utilizando un Protocolo de Transferencia de Hipertexto, HTTP, que tiene un primer periodo de temporización;
medios para, utilizando un motor de reconocimiento de voz automático, iniciar un reconocimiento del flujo de voz;
medios para efectuar la recepción de una primera demanda de un resultado de reconocimiento de voz desde el cliente utilizando HTTP; y
medios para efectuar la transmisión de una notificación al cliente indicando que ningún resultado de reconocimiento de voz se hizo disponible dentro de un segundo periodo de temporización que difiere del primer periodo de temporización.
DISPOSITIVO CLIENTE
APLICACIÓN
FLUJO MULTIPLEXADO
RED
SERVIDOR FLUJO HTTP DE VOZ
FLUJO DE CONTROL
SERVIDOR 118
USUARIO
VOZ
VOZ
RESULTADOS
FLUJO
DE VOZ
CLIENTE RECONOCIMIENTO VOZ
FLUJO DE CONTROL
CLIENTE
HTTP
FLUJO DE
RESULTADOS
COLA ESPERA RECONOCEDOR COLA
PROCESAMIENTO LADO SERVIDOR ESPERA
SALIDA
ESTADO DE
CONFIGURACIÓN
INICIO
RECIBIR VOZ DESDE USUARIO EN CLIENTE
CLIENTE TRANSMITE VOZ A TRAVÉS DE RED
CLIENTE DE RECONOCIMIENTO DE VOZ GENERA FLUJO DE VOZ
CLIENTE DE RECONOCIMIENTO DE VOZ GENERA FLUJO DE CONTROL
CLIENTE HTTP MULTIPLEXA FLUJO DE VOZ Y FLUJO DE CONTROL EN FLUJO MULTIPLEXADO
SERVIDOR PROCESA VOZ
SERVIDOR HTTP DEMULTIPLEXA FLUJO MULTIPLEXADO EN FLUJO DE VOZ Y EN FLUJO DE CONTROL
PONER EN COLA DE ESPERA SEGMENTO DE RECUPERAR SIGUIENTE MENSAJE DE CONTROL VOZ EN COLA DE PROCESAMIENTO DESDE FLUJO DE CONTROL
REALIZAR RECONOCIMIENTO DE VOZ EN EJECUTAR MENSAJE DE SEGMENTOS CONTROL
PONER RESULTADOS DEL RECONOCIMIENTO EN COLA DE ESPERA SALIDA
FIN A 272 FIGURA 2D
INICIO
COLA
VALOR
ESPERA
TEMPORIZACIÓN
SALIDA
ALCANZADO?
VACIA?
TRANSMITIR SIGUIENTES RESULTADOS EN COLA ESPERA SALIDA A CLIENTE RECONOCIMIENTO VOZ A TRAVÉS DE LA RED
INFORMAR A CLIENTE RECONOCIMIENTO VOZ DE QUE NO HAY MÁS RESULTADOS DISPONIBLES
DEVOLVER CONTROL A APLICACIÓN CLIENTE
FIN
DESDE 274 FIGURA 2D INICIO RECUPERAR SIGUIENTE SEGMENTO AUDIO DESDE COLA ESPERA PROCESAMIENTO
ID CONFIGURACIÓN ACTUAL >= ID CONFIGURACIÓN REQUERIDA MÍNIMO?
RECONOCER SEGMENTO AUDIO RECUPERADO PARA RESULTADO RECONOCIMIENTO PRODUCTO
FIN
DESDE 220 FIGURA 2A
OBJETO CONFIGURACIÓN REQUIERE RECONFIGURACIÓN DESPUÉS DE ESTE RESULTADO DEL RECONOCIMIENTO?
INTERRUMPIR RECONOCIMIENTO VOZ HASTA QUE SE RECONFIGURE RECONOCEDOR VOZ
A 262 FIGURA 2C
Patentes similares o relacionadas:
Almacenamiento eficiente de registros de códigos cifrados estructurados múltiples, del 22 de Julio de 2020, de Nokia Technologies OY: Un aparato que comprende: medios para formar un vector de código base combinando componentes 5 de vector de un sub-vector señalado por […]
Sistema decodificador, método de decodificación y programa informático respectivo, del 15 de Julio de 2020, de DOLBY INTERNATIONAL AB: Un sistema decodificador para proporcionar una señal estéreo mediante codificación estéreo de predicción compleja, comprendiendo el sistema decodificador: […]
Codificación de las posiciones de los picos espectrales, del 27 de Mayo de 2020, de TELEFONAKTIEBOLAGET LM ERICSSON (PUBL): Un método de codificación de las posiciones de los picos espectrales de un segmento de una señal de audio, comprendiendo el método: - determinar cuál […]
Conformación simultánea de ruido en el dominio del tiempo y el dominio de la frecuencia para transformaciones TDAC, del 20 de Mayo de 2020, de VOICEAGE CORPORATION: Un método de conformación de ruido en el dominio de la frecuencia para interpolar una forma espectral y una envolvente en el dominio del tiempo del ruido […]
Procesamiento avanzado basado en un banco de filtros con modulación exponencial compleja, del 8 de Abril de 2020, de DOLBY INTERNATIONAL AB: Aparato para generar una señal de decorrelación que usa una señal de entrada, comprendiendo: un banco de filtros de sub-banda complejo para filtrar […]
Procesamiento avanzado basado en un banco de filtros con modulación exponencial compleja, del 8 de Abril de 2020, de DOLBY INTERNATIONAL AB: Aparato para generar una señal de decorrelación que usa una señal de entrada, comprendiendo: un banco de filtros de sub-banda para proporcionar una […]
Procesamiento avanzado basado en un banco de filtros con modulación exponencial compleja y métodos para señalizar el tiempo adaptativos, del 8 de Abril de 2020, de DOLBY INTERNATIONAL AB: Aparato para generar una señal de decorrelación que usa una señal de entrada, comprendiendo: un banco de filtros de sub-banda complejo para filtrar […]
Códec de audio multicanal sin pérdida que usa segmentación adaptativa con capacidad de conjunto de parámetros de predicción múltiple (MPPS), del 11 de Marzo de 2020, de DTS, INC: Un método de codificación de audio multicanal, en un flujo de datos de audio de tasa de bits variable sin pérdida, VBR, que comprende: bloquear […]