MÉTODO Y SISTEMA DE PROCESAMIENTO EN FLUJO CONTINUO EN UNA PLATAFORMA DE CÁLCULO DISTRIBUIDA DE MAPEO Y REDUCCIÓN.
Un método y un sistema de procesamiento en flujo continuo en una plataforma de cálculo distribuida de mapeo y reducción.
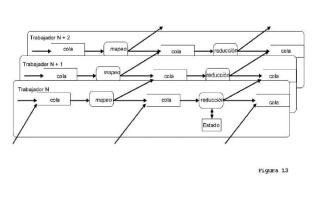
El método comprende dicha plataforma de cálculo distribuida que comprende al menos un agrupamiento con una pluralidad de nodos con capacidad de cálculo, usando el método información relativa a un estado asociado a al menos operaciones de reducción, el método comprende generar dicho estado como resultado de una operación de reducción realizada por un nodo, en forma de una cola de salida, y usar dicho estado como cola de entrada de una operación de reducción posterior realizada por dicho nodo, formando dicha coa de salida y dicha cola de entrada una única cola que se actualiza tras el procesamiento de operación de reducción.
El sistema está dispuesto para implementar el método de la presente invención.
Tipo: Patente de Invención. Resumen de patente/invención. Número de Solicitud: P201230550.
Solicitante: TELEFONICA, S.A..
Nacionalidad solicitante: España.
Inventor/es: ESCALADA SARDINA,José Gregorio, URRUELA PLANAS,Andreu, GUNNAR ZANGELIN,Ken.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G06F9/54 FISICA. › G06 CALCULO; CONTEO. › G06F PROCESAMIENTO ELECTRICO DE DATOS DIGITALES (sistemas de computadores basados en modelos de cálculo específicos G06N). › G06F 9/00 Disposiciones para el control por programa, p. ej. unidades de control (control por programa para dispositivos periféricos G06F 13/10). › Comunicación entre programas.
Fragmento de la descripción:
Método y sistema de procesamiento en flujo continuo en una plataforma de cálculo distribuida de mapeo y reducción.
Campo de la técnica La presente invención se refiere en general, en un primer aspecto, a un método de procesamiento en flujo continuo en una plataforma de cálculo distribuida de mapeo y reducción (map and reduce) , y más específicamente a un método para optimizar el rendimiento del procesamiento de un flujo de datos continuo en una plataforma de cálculo distribuida.
Un segundo aspecto de la invención se refiere a un sistema dispuesto para implementar el método del primer aspecto.
Por estado, se entenderá cualquier información de interés que debe mantenerse y actualizarse de manera continua su evolución a lo largo del tiempo (por ejemplo un perfil de usuario para recomendaciones) . Este estado contendrá toda la información relevante para cada elemento que va a modelarse.
Estado de la técnica anterior
La gran cantidad (creciente) de datos generados y disponibles en la actualidad ha llevado al desarrollo de paradigmas, plataformas y aplicaciones para procesar y crear valor de toda esta información. Este proceso se ha estimulado por la aparición del paradigma MapReduce (o map and reduce, MR) y su implementación en un proyecto de fuente abierta (Apache Hadoop) y un ecosistema de productos orientado a soluciones para grandes datos. En este ecosistema, también pueden encontrarse soluciones NoSQL.
Pero cada vez más, “grandes” no sólo significa “gran cantidad” sino también requisitos más estrictos en otras dimensiones del espacio de solución. Apache Hadoop es óptimo para tareas simples de procesamiento por lotes con terabytes y petabytes de datos implicados, pero las empresas e instituciones se enfrentan a tareas más complejas: cálculo de gráficos, análisis interactivo, uniones complejas, requisitos de atomicidad, consistencia, aislamiento y durabilidad (ACID) , requisitos en tiempo real o la necesidad de actualizaciones crecientes continuas (manteniendo todas ellas la necesidad de procesar el volumen de información relevante generada) .
Estos requisitos se cubren con diferentes estrategias: evoluciones del paradigma MapReduce y su implementación, soluciones especializadas para procesamiento de gráficos, soluciones de procesamiento de eventos complejos (CEP) , e incluso una tendencia a la innovación en SQL [1].
En 2004, Google presentó el paradigma MapReduce [2], un modelo de programación para expresar cálculos distribuidos en conjuntos de datos masivos y un marco de ejecución para procesamiento de datos a gran escala. Permite distribuir problemas de datos muy grandes en un agrupamiento de máquinas.
La teoría sobre procesamiento distribuido y paralelo ha estado en el centro de la ciencia de la información durante mucho tiempo (y MR se basa en principios de programación funcional) , aunque la nueva propuesta llegó justo a tiempo para solucionar un problema en crecimiento de manejar nuevas fuentes de datos y extraer información y el valor de las mismas.
Mucho antes, ya existía la necesidad de trabajar con grandes conjuntos de datos [3]. RDBMS también han evolucionado a sistemas cada vez más grandes. Los sistemas CEP han tenido su sitio durante algunos años, y recientemente, cada vez más se están ampliando para hacer frente a los problemas de grandes datos.
Pero MR todavía constituye el núcleo del procesamiento de grandes datos, y está desarrollándose para solucionar los nuevos problemas que surgen. Al principio existía la necesidad de procesar una gran cantidad de datos de manera distribuida para obtener soluciones en un tiempo razonable, y el paradigma MR en 2004 y su implementación de fuente abierta con Apache Hadoop constituyeron la solución óptima. Entonces el espacio distribuido de clave-valores resultaron ser útiles para almacenar y recuperar información de manera económica. Este fue el origen de las soluciones BigTable y Dynamo, y una serie de productos (Cassandra, MongoDB...) . Ahora la atención se dirige al procesamiento en tiempo real. Este camino proporciona nuevas soluciones basándose en MR (Google’s Percolator, Yahoo’s S4) y una serie de evoluciones MR para mejorar el tiemporespuesta.
La solución propuesta también es una evolución de MR, de modo que estos antecedentes técnicos presentarán en más detalle esta tecnología.
Implementación de MapReduce y Apache Hadoop
MapReduce (MR) es un paradigma que ha evolucionado a partir de la programación funcional y que se aplica a sistemas distribuidos. Se presentó en 2004 por Google [2]. Está previsto para procesar problemas cuya solución puede expresarse en funciones conmutativas y asociativas.
En esencia, MR ofrece una abstracción para procesar grandes conjuntos de datos en un conjunto de máquinas, configurado en un agrupamiento. Con esta abstracción, la plataforma puede resolver fácilmente el problema de sincronización, liberando así al desarrollador de tener que pensar en este tema.
Todos los datos de estos conjuntos de datos se almacenan, procesan y distribuyen en forma de pares de clavevalor, en los que tanto la clave como el valor pueden ser de cualquier tipo de datos.
A partir del campo de programación funcional, se demuestra que cualquier problema cuya solución puede expresarse en términos de funciones conmutativas y asociativas, puede expresarse en dos tipos de funciones: mapeo (también denominado mapeo en el paradigma de MR) y pliegue (denominado reducción en el paradigma de MR) . Cualquier trabajo debe expresarse como una secuencia de estas funciones. Estas funciones tienen una restricción: operan en algunos datos de entrada, y producen un resultado sin efectos secundarios, es decir sin modificar ni los datos de entrada ni ningún estado global. Esta restricción es el punto clave para permitir una fácil paralelización.
Dada una lista de elementos, el mapeo toma como argumento una función f (que toma un único argumento) y lo aplica a todos los elementos en una lista (la parte superior de la figura 1) , que devuelve una lista de resultados. La segunda etapa, pliegue, acumula un nuevo resultado mediante iteración a través de los elementos en la lista de resultados. Toma tres parámetros: un valor de base, una lista, y una función, por ejemplo. Normalmente, mapeo y pliegue se usan en combinación. La salida de una función es la entrada de la siguiente (puesto que la programación funcional evita datos mutables y de estado, todo el cálculo debe progresar pasando resultados de una función a la siguiente) , y este tipo de funciones puede realizarse en cascada hasta finalizar la tarea.
En el tipo de mapeo de la función, se aplica un cálculo especificado por usuario en todos los registros de entrada en un conjunto de datos. Como el resultado depende sólo de los datos de entrada, la tarea puede dividirse entre cualquier número de instancias (los mapeadores) , trabajando cada uno de los mismos en un subconjunto de los datos de entrada, y puede distribuirse entre cualquier número de máquinas. Estas operaciones se producen en paralelo. Se procesa cada par de clave-valor de los datos de entrada, y pueden producir ninguno, uno o múltiples pares de clave-valor, con la misma o diferente información. Dan lugar a una salida intermedia que luego se envía a las funciones de reducción.
La fase de reducción tiene la función de agregar los resultados diseminados en la fase de mapeo. Con el fin de realizar esto, todos los resultados de todos los mapeadores se clasifican por el elemento clave del par de clavevalor, y la operación se distribuye entre varias instancias (los reductores, que también se ejecutan en paralelo entre las máquinas disponibles) . La plataforma garantiza que todos los pares de clave-valor con la misma clave se presentan al mismo reductor. Esta fase tiene entonces la posibilidad de agregar la información emitida en la fase de mapeo.
El trabajo que va a procesarse puede dividirse entre cualquier número de implementaciones de estos ciclos de dos fases.
La plataforma proporciona el marco para ejecutar estas operaciones distribuidas en paralelo en varias CPU. El único punto de sincronización es en la salida de la fase de mapeo, en la que todos los pares de clave-valor deben estar disponibles para clasificarse y redistribuirse. De esta manera, el desarrollador sólo tiene que preocuparse por la implementación (según las limitaciones del paradigma) de las funciones de mapeo y reducción, y la plataforma oculta la complejidad de distribución y sincronización de datos. Básicamente, el desarrollador puede acceder a recursos combinados (CPU, disco, memoria) de toda la agrupación, de una manera transparente. La utilidad...
Reivindicaciones:
1. Método de procesamiento en flujo continuo en una plataforma de cálculo distribuida de mapeo y reducción, comprendiendo dicha plataforma de cálculo distribuida al menos un agrupamiento con una pluralidad de nodos con capacidad de cálculo, usando el método información relativa a un estado asociado a al menos operaciones de reducción, caracterizado porque el método comprende generar dicho estado como resultado de una operación de reducción realizada por un nodo, en forma de una cola de salida, y usar dicho estado como cola de entrada de una operación de reducción posterior realizada por dicho nodo, formando dicha cola de salida y dicha cola de entrada una única cola que se actualiza tras el procesamiento de operación de reducción.
2. Método según la reivindicación 1, que comprende generar una pluralidad de estados como resultado de una pluralidad correspondiente de operaciones de reducción realizadas por una pluralidad de nodos, en forma de datos de cola, y usar dichos estados como entradas de operaciones de reducción posteriores realizadas por los respectivos nodos.
3. Método según la reivindicación 1 ó 2, que comprende almacenar al menos parte de los bloques que forman dicho estado en una memoria local del respectivo nodo, y acceder a y recuperar dichos bloques de estado desde al menos dicha memoria local para dichas operaciones de reducción posteriores.
4. Método según la reivindicación 3, que comprende almacenar todos los bloques que forman dicho estado en la memoria local del respectivo nodo, y acceder a y recuperar dichos bloques de estado desde sólo dicha memoria local para dichas operaciones de reducción posteriores.
5. Método según la reivindicación 3, que comprende almacenar en un disco local del respectivo nodo el resto de los bloques que forman dicho estado que no se han almacenado en la memoria local, y acceder a y recuperar dichos bloques de estado desde tanto la memoria local como el disco local, para dichas operaciones de reducción posteriores.
6. Método según cualquiera de las reivindicaciones anteriores, que comprende compartir dicho nodo o al menos uno de dicha pluralidad de nodos su respectivo estado con otros nodos, realizando dichos otros nodos operaciones de reducción usando dicho estado compartido como entrada para las mismas.
7. Método según cualquiera de las reivindicaciones anteriores, que comprende realizar dicho procesamiento de flujo continuo planificando operaciones en colas de datos, y ejecutarlas automáticamente cuando hay disponibles datos de entrada en el respectivo nodo.
8. Método según la reivindicación 7, que comprende controlar las colas de datos para especificar una latencia máxima.
9. Método según la reivindicación 7 u 8, que comprende controlar las colas de datos para especificar si los datos de entrada, incluyendo el estado, deben borrarse después del procesamiento, o si deben conservarse para su uso posterior.
10. Método según cualquiera de las reivindicaciones anteriores, que comprende organizar dicho estado como una división de los intervalos clave.
11. Método según cualquiera de las reivindicaciones anteriores, que comprende dividir el estado en varios compartimentos.
12. Método según la reivindicación 11 cuando depende de la reivindicación 9, que comprende asignar un sello de tiempo a cada uno de dichos compartimentos, y borrar las entradas de estado sin usar según el sello de tiempo asociado al compartimento que comprende parte del estado.
13. Sistema de plataforma de cálculo distribuida para procesamiento en flujo continuo de mapeo y reducción, comprendiendo dicha plataforma de cálculo distribuida al menos un agrupamiento con una pluralidad de nodos con capacidad de cálculo y configurado para realizar al menos operaciones de reducción usando información relativa al estado asociado a las mismas, caracterizado porque al menos uno de dichos nodos comprende al menos una cola de estado de entrada y al menos una cola de estado de salida, porque dicho al menos un nodo está configurado para generar dicho estado como resultado de una operación de reducción realizada por dicho al menos un nodo y proporcionar dicho resultado a dicha al menos una cola de salida de estado, y porque dichas colas de estado de entrada y de salida están interconectadas formando una única cola de modo que hay una realimentación desde dicha cola de estado de salida a dicha cola de estado de entrada.
14. Sistema según la reivindicación 13, que comprende una pluralidad de nodos, comprendiendo cada uno al menos una cola de estado de entrada y al menos una cola de estado de salida, y configurada para generar dicho estado como resultado de una operación de reducción y proporcionar dicho resultado a dicha al menos una cola de salida de estado, en el que las colas de estado de entrada y de salida de cada nodo están
interconectadas formando una única cola de modo que hay una realimentación desde dicha cola de estado de salida a dicha cola de estado de entrada.
15. Sistema según la reivindicación 13 ó 14, en el que dicho al menos un nodo o al menos parte de dicha
pluralidad de nodos comprenden al menos una memoria local para almacenar/recuperar al menos parte de los 5 bloques que forman el estado del respectivo nodo.
16. Sistema según la reivindicación 15, en el que dicho al menos un nodo o al menos parte de dicha pluralidad de nodos comprenden al menos un disco local para almacenar/recuperar el resto de los bloques que forman el estado que no se han almacenado en la memoria local.
17. Sistema según la reivindicación 15 ó 16, que comprende un módulo de gestor de bloque que optimiza
los recursos manejando el almacenamiento/recuperación de bloques de estado en dicha memoria local y/o dicho disco local, para mantener los bloques de datos de estado activos en la memoria local.
18. Sistema según cualquiera de las reivindicaciones 13 a 17, en el que dicho al menos un nodo o al menos parte de dicha pluralidad de nodos implementa el método según cualquiera de las reivindicaciones 1 a 12.
Figura 1
Figura 2 Figura 3 Figura 4 Figura 6
Figura 8
Figura 9 Figura 10
Figura 15 Figura 16
Figura 17 Figura 18
Figura 19 Figura 20
Patentes similares o relacionadas:
Aparatos y procedimientos de ampliación de servicios de aplicaciones, del 12 de Febrero de 2020, de QUALCOMM INCORPORATED: Un procedimiento para ampliar servicios de un dispositivo de usuario, que comprende: identificar una primera aplicación residente en el dispositivo […]
Función de interrupción de seguimiento de advertencias, del 25 de Diciembre de 2019, de INTERNATIONAL BUSINESS MACHINES CORPORATION: Un sistema informático para facilitar el procesamiento en un entorno informático, comprendiendo dicho sistema informático: una memoria; y un procesador […]
Procedimiento, dispositivo, terminal y medio de almacenamiento para ajustar cola de mensaje de difusión, del 6 de Noviembre de 2019, de Guangdong OPPO Mobile Telecommunications Corp., Ltd: Un procedimiento para ajustar una cola de mensaje de difusión realizada en un terminal, que comprende: determinar un emisor de difusión objetivo de cada […]
Aparato, método y programa de procesamiento de datos basado en microservicios, del 30 de Octubre de 2019, de FUJITSU LIMITED: Un aparato de procesamiento de datos basado en microservicios, que comprende: un registro de tipos, que almacena una lista de tipos, siendo un tipo una expresion semantica […]
Autoanálisis de memoria dual para asegurar múltiples puntos finales de red, del 2 de Octubre de 2019, de Bitdefender IPR Management Ltd: Un sistema informático que comprende un procesador de hardware y una memoria, configurado el procesador de hardware para ejecutar un hipervisor […]
Estructura de API de sensor para aplicaciones basadas en la nube, del 4 de Septiembre de 2019, de QUALCOMM INCORPORATED: Un procedimiento para ejecutar en un dispositivo móvil para proporcionar una API común, interfaz de programación de aplicaciones , comprendiendo […]
Recopilación y limpieza de datos en la fuente, del 14 de Agosto de 2019, de IQVIA Inc: Un dispositivo móvil para limpiar datos, que comprende: un receptor (311a, 311b) para recopilar datos electrónicos para limpiar; un procesador acoplado […]
Agrupación automática de ventanas de aplicación, del 10 de Julio de 2019, de Microsoft Technology Licensing, LLC: Un procedimiento de agrupación de ventanas de aplicación, comprendiendo el procedimiento realizado en un dispositivo informático una pantalla , un dispositivo […]