MÉTODO PARA GESTIONAR EL RENDIMIENTO EN APLICACIONES DE MÚLTIPLES CAPAS IMPLANTADAS EN UNA INFRAESTRUCTURA DE TECNOLOGÍA DE INFORMACIÓN.
Método para gestionar el rendimiento en aplicaciones de múltiples capas implantadas en una infraestructura de tecnología de información.
En el método de la invención, dichas aplicaciones de múltiples capas proporcionan servicios a un usuario y tienen recursos asignados en dicha infraestructura de TI y la gestión al menos comprende detectar la degradación del rendimiento y proporcionar acciones correctivas por medio de enfoques estadísticos o modelos analíticos.
El método de la invención comprende usar una combinación de dichos enfoques estadísticos y dichos modelos analíticos teniendo en cuenta los datos de monitorización procedentes de dicha infraestructura de TI con el fin de asignar dichos recursos con elasticidad y con el fin de proporcionar, cuando se detecta una anomalía o anomalías, dichas acciones correctivas procesando dichos datos de monitorización, comprendiendo dicho procesamiento operaciones estadísticas, predicciones, reconocimientos y/o correlaciones de patrón.
El sistema está dispuesto para implementar el método del primer aspecto.
Tipo: Patente de Invención. Resumen de patente/invención. Número de Solicitud: P201131833.
Solicitante: TELEFONICA, S.A..
Nacionalidad solicitante: España.
Inventor/es: GALÁN,Fermín, BLASCO,Ignacio, MORÁN,Daniel, BERNAT,Jesús, ELICEGUI,Javier, GARCÍA,Emilio.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G06F11/34 FISICA. › G06 CALCULO; CONTEO. › G06F PROCESAMIENTO ELECTRICO DE DATOS DIGITALES (sistemas de computadores basados en modelos de cálculo específicos G06N). › G06F 11/00 Detección de errores; Corrección de errores; Monitorización (detección, corrección o monitorización de errores en el almacenamiento de información basado en el movimiento relativo entre el soporte de registro y el transductor G11B 20/18; monitorización, es decir, supervisión del progreso del registro o reproducción G11B 27/36; en memorias estáticas G11C 29/00). › Registro o evaluación estática de la actividad del computador, p. ej. de las interrupciones o de las operaciones de entrada-salida.
Fragmento de la descripción:
MÉTODO PARA GESTIONAR EL RENDIMIENTO EN APLICACIONES DE MÚLTIPLES CAPAS IMPLANTADAS EN UNA INFRAESTRUCTURA DE TECNOLOGÍA DE INFORMACIÓN
Campo de la técnica La presente invención se refiere en general, en un primer aspecto, a un método para gestionar el rendimiento en aplicaciones de múltiples capas implantadas en una infraestructura de tecnología de información, proporcionando dichas aplicaciones de múltiples capas servicios a un usuario y teniendo recursos asignados en dicha infraestructura de TI, comprendiendo dicha gestión al menos detectar la degradación del rendimiento y proporcionar acciones correctivas por medio de enfoques estadísticos o modelos analíticos y más particularmente a un método que comprende usar una combinación de dichos enfoques estadísticos y dichos modelos analíticos teniendo en cuenta los datos de monitorización procedentes de dicha infraestructura de TI con el fin de asignar dichos recursos con elasticidad y con el fin de proporcionar,
cuando se detecta una anomalía o anomalías, dichas acciones correctivas procesando dichos datos de monitorización, comprendiendo dicho procesamiento operaciones estadísticas, predicciones, reconocimientos y/o correlaciones de patrón.Un segundo aspecto de la invención se refiere a un sistema dispuesto para implementar el método del primer aspecto.
Estado de la técnica anterior
Los enfoques de informática en la nube [1] permiten ajustar los recursos asignados a los clientes (normalmente, potencia de cálculo, almacenamiento y red) a la demanda de utilización actual de sus servicios. La elasticidad automática (considerada una de las “aplicaciones clave” de la informática en la nube) consiste en añadir o sustraer automáticamente los recursos mencionados anteriormente a o de los servicios implantados en la nube sin ninguna intervención humana basándose en la demanda [2].
Por ejemplo, una empresa dada desarrolla un servicio de compras en línea nuevo. Cuando se lanza en primer lugar, la empresa puede tener una estimación de los recursos necesarios pero el uso real puede variar en el tiempo (por ejemplo, durante las primeras semanas sólo unos pocos usuarios pueden usarlo, y después empieza a aumentar de una manera lineal) e incluso el uso puede cambiar dependiendo de las horas del día (por ejemplo, la hora pico puede ser de 6 a 10 p.m.
mientras que de 2 a 6 a.m. apenas se usa) o los días de la semana (por ejemplo, puede usarse más durante la semana de trabajo que los fines de semana) . Puesto que a priori es difícil estimar de manera precisa la demanda real de recursos en un momento dado, el ajuste a escala automático es una de las características más 5 importantes que un servicio en la nube debería proporcionar. Esta característica de adaptación de un conjunto de recursos a las necesidades basándose en la carga se conoce como elasticidad.
Poder adaptar los recursos de aplicación a la demanda es una característica muy importante, aunque esto no garantiza un comportamiento correcto. En algunos 10 casos, las aplicaciones empiezan a tener un mal funcionamiento, aunque esto no se debe a ningún aumento en la demanda, sino que se produce por algunas cuestiones internas como por ejemplo un disco duro que está casi lleno debido a una gran cantidad de archivos de registro, o un número muy alto de conexiones bloqueadas en un sistema de base de datos. La capacidad de detectar un comportamiento deficiente 15 de un sistema (debido a problemas internos) y corregirlos sin proporcionar más recursos pero mejorando el rendimiento se conoce como autorregeneración. En general, el resultado de aplicar una medida de elasticidad para un problema de autorregeneración no mejora el comportamiento final de la aplicación. Algunos productos, como SQL Anywhere, ofrecen algunas herramientas que permiten realizar
20 procedimientos de autorregeneración interna [17]. Los sistemas operativos a menudo proporcionan funciones para configurar acciones que realizan algunos tipos de procedimientos de autorregeneración a nivel máquina. A este nivel, las aplicaciones de múltiples capas son particularmente importantes. Las aplicaciones de múltiples capas son un tipo especial de aplicaciones 25 que dividen las funcionalidades en N capas separadas (N capas) [3]. El paradigma de N capas es muy común en aplicaciones basadas en Internet. Desde un punto de vista de implantación, una aplicación de múltiples capas puede implantarse en diferentes máquinas siguiendo diversas opciones: varias capas en una única máquina, varias máquinas para una capa particular, etc.
30 Desde un punto de vista de informática en la nube, las aplicaciones de múltiples capas son especialmente importantes, puesto que su comportamiento se basa en el funcionamiento apropiado de todas las capas; y el comportamiento de cada una de las capas también depende del modo en el que se comportan las diferentes máquinas que las soportan. Un problema complejo de un sistema de regeneración de 35 aplicaciones es identificar la razón de una QoS deficiente en estas aplicaciones de múltiples capas. La causa puede ser una asignación de recursos en la nube no adecuada para hacer frente a las necesidades de aplicación (elasticidad) o cualquiera de los demás problemas registrados de la forma interna en la que se realizan algunas acciones (autorregeneración) .
5 Para detectar o bien la falta de recursos o bien un funcionamiento interno inapropiado de los elementos, pueden aplicarse diferentes clases de mecanismos: algunos de ellos se basan en enfoques estadísticos (por ejemplo, una red neuronal que detecta la necesidad de ajustar a escala una capa de aplicación particular basándose en medidas de monitorización específicas) , mientras que otras se basan en 10 un conjunto de procedimientos analíticos (por ejemplo, cuando un parámetro de monitorización dado alcanza un umbral implica un problema de autorregeneración particular) . Además, los enfoques estadísticos pueden incluso predecir la capacidad o problema de regeneración antes de que ocurra. Para este fin, pueden definirse modelos para detectar los problemas de ajustabilidad a escala y regeneración para 15 aplicaciones de múltiples capas en entornos de informática en la nube, modelos o bien analíticos o bien empíricos. Los modelos analíticos (también denominados modelos Ab initio, primer principio) se basan estrictamente en consideraciones de primer nivel de cada uno de los componentes individuales del sistema. Ejemplos de estos modelos son las ecuaciones diferenciales, modelos de colas, redes de Petri o árboles de 20 decisión. Éstos proporcionan salidas válidas sin entrenamiento. Por otro lado, los modelos empíricos (estadísticos) tienden a capturar el comportamiento real de cualquier sistema, basándose en un historial y experimentación anterior, e incluyendo lo que no es ideal que ignoren los modelos analíticos. En la actualidad, la mayoría de los sistemas de informática en la nube ofrecen 25 herramientas que puede analizar el comportamiento de un recurso de informática en la nube particular (CPU, disco duro, etc.) . Sin embargo, las soluciones comerciales no proporcionan algoritmos de regeneración general a nivel de aplicación. El estado de la técnica a nivel de investigación ha producido modelos analíticos para que las aplicaciones de múltiples capas [3] detecten cuellos de botella en una capa específica 30 de una aplicación multicapa. Sin embargo, se pretende que estos estudios modelen el comportamiento de aplicaciones en diferentes condiciones de carga; no se considera el efecto producido por la degradación del rendimiento del sistema no provocado por cargas adicionales. Esta insuficiencia en el modelo puede provocar el aumento de la ajustabilidad a escala de una aplicación particular sin aumentar el rendimiento o,
35 incluso peor, disminuirlo.
Los enfoques de autorregeneración actuales previamente descritos tienen dos problemas. En primer lugar, carecen de generalidad ya que los mecanismos de autorregeneración están sumamente unidos a un componente particular (base de datos, sistema operativo, etc.) y no se centran en el algoritmo general para aplicar las 5 acciones. En segundo lugar, no se proporciona un mecanismo holístico a nivel de aplicación para definir las acciones de autorregeneración que deben realizarse.
Además, las propuestas existentes consideran el uso de modelos para detectar problemas de ajustabilidad a escala y regeneración, pero a menudo se limitan al uso de modelos o bien analíticos o...
Reivindicaciones:
1. Método para gestionar el rendimiento en aplicaciones de múltiples capas implantadas en una infraestructura de tecnología de información, proporcionando dichas aplicaciones de múltiples capas servicios a un usuario y teniendo recursos asignados en dicha infraestructura de TI, comprendiendo dicha gestión al menos detectar la degradación del rendimiento y proporcionar acciones correctivas por medio de enfoques estadísticos o modelos analíticos, caracterizado porque dicho método comprende realizar los siguientes pasos: usar una combinación de dichos enfoques estadísticos y dichos modelos analíticos teniendo en cuenta los datos de monitorización procedentes de dicha infraestructura de TI para:
asignar dichos recursos con elasticidad; y proporcionar, cuando se detecta una anomalía o anomalías, dichas acciones correctivas procesando dichos datos de monitorización, comprendiendo dicho procesamiento operaciones estadísticas, predicciones, reconocimientos y/o correlaciones de patrón,
predecir el comportamiento futuro del uso de dichos servicios; y analizar al menos dichos datos de monitorización para anticipar dichas acciones correctivas, comprendiendo dichos datos de monitorización métricas de dicha infraestructura de TI y/o de dichos servicios, comprendiendo dichas métricas incidentes de evento y supervisando métricas de calidad de servicio y/o métricas internas de dicha infraestructura de TI, en el que dichos datos de monitorización proceden de las métricas de infraestructura y/o métricas de servicio de dicha infraestructura de TI, dicha infraestructura de TI comprende host físicos y/o virtuales y redes de interconexión y elementos de almacenamiento usados por dichos host físicos y/o virtuales y por dichas aplicaciones de múltiples capas, dichas métricas de infraestructura comprenden indicadores del rendimiento de dichos host físicos y/o virtuales, redes de interconexión y elementos de almacenamiento y dichas métricas de servicio comprenden indicadores del rendimiento del software ejecutado en dicha infraestructura de TI, reunir información de al menos una métrica de dichos host físicos y/o virtuales e indicadores del rendimiento claves de dichas aplicaciones de múltiples capas en dichos datos de monitorización y representar dichos datos de monitorización mediante un par de valores: una marca de tiempo que indica cuándo se obtuvieron los datos y un valor de una métrica monitorizada real,
realizar una predicción de evolución a corto plazo de dichas métricas de infraestructura y/o de servicio con referencia a un intervalo estimado de tiempo antes de una marca de tiempo de la última muestra monitorizada por medio de técnicas de predicción de la siguiente lista no cerrada aplicada a dichos datos de monitorización: regresión lineal, regresión múltiple, redes neuronales,
promedios móviles integrados autorregresivos, modelado de BoxJenkins o usar datos históricos combinados con valores de datos reales usados como un factor de corrección,
emitir un par de valores diferentes tras realizar dicha predicción de evolución a corto plazo de modo que dicho par de valores indican: una marca de tiempo en el futuro y un valor que es un valor estimado para una métrica concreta,
generar patrones a partir de la evolución temporal de dichos datos de monitorización, en el que dichos patrones se basan en un conjunto de métricas de dichos datos de monitorización, usando dicho conjunto de métricas antes del momento en que se detectan dicha anomalía o anomalías,
2. Método según la reivindicación 1, que comprende controlar cada uno de dichos servicios de una manera independiente por medio de una adaptación por servicio de dicha infraestructura de tecnología de información.
3. Método según la reivindicación 1, en el que dicha al menos una métrica es una de la siguiente lista no cerrada de métricas: CPU, carga de memoria y utilización de disco.
4. Método según la reivindicación 1 ó 3, que comprende realizar un procesamiento previo de dichos datos de monitorización con el fin de homogeneizar dichos datos de monitorización, comprendiendo dicho procesamiento previo la realización de un nuevo muestreo, interpolación y suavizado, sincronización de marcas de tiempo de datos y/o utilización de técnicas estadísticas.
5. Método según la reivindicación 1, que comprende comparar los valores monitorizados reales con un conjunto de predicciones con el fin de obtener una proporción de éxito, obteniéndose dicho conjunto de predicciones usando de manera simultánea una pluralidad de dichas técnicas de predicción o usando una de dichas técnicas de predicción y en el que dichos valores monitorizados reales se obtienen después de dicho intervalo de tiempo estimado en relación con dicho conjunto de predicciones.
6. Método según la reivindicación 5, que comprende emplear una de dichas
técnicas de predicción según dicha proporción de éxito con el fin de realizar dicha predicción de evolución a corto plazo.
7. Método según la reivindicación 1, que comprende almacenar los patrones generados en una base de datos de patrones e identificar dichos patrones generados por medio de un mecanismo de reconocimiento basado en patrones que comprende buscar acontecimientos entre dichos datos de monitorización y dichos patrones generados almacenados en dicha base de datos de patrones.
8. Método según la reivindicación 7, que comprende realizar una identificación de dichos patrones generados usando diferentes técnicas de correspondencia de patrones y valorando cada una de dichas técnicas de correspondencia de patrones según un grado de éxito, siendo dicho grado de éxito más alto cuando dichos datos de monitorización identificados como un patrón generado conducen a una anomalía.
9. Método según cualquiera de las reivindicaciones anteriores, que comprende asociar dicha anomalía o anomalías a uno o más incidentes, describiendo dichos uno o más incidentes un comportamiento no deseado de dicha infraestructura de TI que necesita corregirse y siendo dichos uno o más incidentes, incidentes externos cuando se indican mediante sensores y/o alarmas previstos en dicha infraestructura de TI y siendo incidentes internos según heurísticas aplicadas a dichos datos de monitorización.
10. Método según la reivindicación 9, en el que dichas heurísticas comprenden: usar evolución de métricas y estudio continuo de datos históricos para establecer umbrales de confianza que determinan si una métrica particular está dentro de su rango de operación normal o si dicha métrica particular está fuera de dicho rango de operación normal generando un incidente interno; o usar dicha predicción a corto plazo para prever un incidente interno; o analizar la distribución de probabilidad de tiempo de dicho uno o más incidentes que responden al comportamiento estacionario con el fin de prever un incidente interno.
11. Método según la reivindicación 9 ó 10, que comprende almacenar las relaciones entre dicha anomalía o anomalías y dicho uno o más incidentes y almacenar la correspondencia entre dicha anomalía o anomalías y dichos patrones generados en una base de datos de anomalías.
12. Método según la reivindicación 11, que comprende detectar dicha anomalía o anomalías según las siguientes acciones:
desencadenar una indicación de anomalía cuando un número determinado de
dichos uno o más incidentes detectados en dicha infraestructura de TI en un periodo de tiempo dado corresponden parcial o totalmente a una de dicha anomalía o anomalías según una búsqueda en dicha base de datos de anomalías, estableciendo una probabilidad de éxito según la proximidad de dicho número determinado al número de incidentes almacenado en dicha base de datos de anomalías para dicha una de dicha anomalía o anomalías; o recibir una indicación de que se ha detectado uno de dichos patrones generados en el comportamiento de dicha infraestructura de TI y asociar dicho patrón generado con la correspondiente anomalía o anomalías consultando en dicha base de datos de anomalías.
13. Método según la reivindicación 12, que comprende agrupar dicha anomalía o anomalías en una única anomalía cuando un conjunto de anomalías se correlacionan entre sí.
14. Método según cualquiera de las reivindicaciones anteriores, que comprende generar un flujo de trabajo de dichas acciones correctivas para una anomalía determinada e información relacionada de dicha anomalía determinada, comprendiendo dicha información relacionada la intensidad, duración, estimación de trama de tiempo presente y la probabilidad de éxito, aplicándose dichas acciones correctivas a los elementos de dicha infraestructura de TI de la que proceden dichos datos de monitorización y/o aplicándose a uno o más de dichos elementos cuyas métricas no están implicadas en la detección de dicha anomalía determinada.
15. Método según la reivindicación 14, que comprende: usar el protocolo simple de gestión de red, o SNMP, cuando se aplican dichas acciones correctivas a dichos host físicos y/o a dichas redes de interconexión; usar dicho SNMP o interfaz de gestión de datos en la nube cuando se aplican dichas acciones correctivas a dichos elementos de almacenamiento; y usar instrucciones de XMLRPC, REST, SOAP, Telnet o Shell segura cuando se aplican dichas acciones correctivas a dichas aplicaciones de múltiples capas y/o a dichos servicios.
16. Sistema para gestionar el rendimiento en aplicaciones de múltiples capas implantadas en una infraestructura de tecnología de información, proporcionando dichas aplicaciones de múltiples capas servicios a un usuario y teniendo recursos asignados en dicha infraestructura de TI, comprendiendo dicha gestión al menos detectar la degradación del rendimiento y proporcionar acciones correctivas por medio de enfoques estadísticos o modelos analíticos,
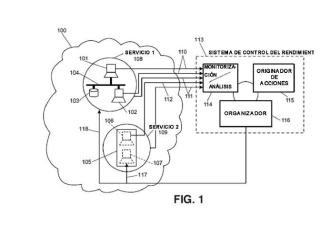
caracterizado porque dicho sistema comprende una entidad de control del rendimiento que recibe datos de monitorización procedentes de dicha infraestructura de TI y usa una combinación de dichos enfoques estadísticos y dichos modelos analíticos tomando dichos datos de monitorización para: asignar dichos recursos con elasticidad; y proporcionar, cuando se detecta una anomalía o anomalías, dichas acciones correctivas procesando dichos datos de monitorización, comprendiendo dicho procesamiento operaciones estadísticas, predicciones, reconocimientos y/o correlaciones de patrón, en donde dicha entidad de control del rendimiento al menos comprende: un módulo de monitorización para recibir dichos datos de monitorización y para realizar dicho procesamiento de dichos datos de monitorización; un módulo originador de acciones para realizar dicha provisión de dichas acciones correctivas según dicho procesamiento y dicha combinación de dichos enfoques estadísticos y dichos modelos analíticos; y un módulo organizador para aplicar dichas acciones correctivas a al menos un elemento de dicha infraestructura de TI y/o a al menos una de dichas aplicaciones de múltiples capas, comprendiendo dicha infraestructura de TI host físicos y/o virtuales y redes de interconexión y elementos de almacenamiento usados por dichos host físicos y/o virtuales y por dichas aplicaciones de múltiples capas; comprendiendo dicha entidad de control del rendimiento además: reflejando dichos conjuntos de uno o más incidentes un comportamiento no deseado de dicha infraestructura de TI y recibiendo dicho módulo de detección de anomalías como entradas dichos patrones generados, salidas procedentes de dicho módulo de monitorización, salidas procedentes de dicho módulo de predicción de serie temporal y alarmas implantadas en dicha infraestructura de TI que indican dicho comportamiento no deseado.
un módulo de predicción de serie temporal encargado de proporcionar una
predicción de evolución a corto plazo que hace referencia a un intervalo
estimado antes de una marca de tiempo de la última muestra monitorizada
por medio de técnicas de predicción aplicadas a las salidas procedentes de
dicho módulo de monitorización;
un módulo de reconocimiento de patrón encargado de generar e identificar
patrones a partir de la evolución temporal de dichos datos de
monitorización, recibiendo dicho módulo de reconocimiento de patrón como
entrada dichas salidas procedentes de dicho módulo de monitorización,
basándose cada uno de dicho patrones en un conjunto de métricas de
dichas métricas de infraestructura y/o dichas métricas de servicio, y
almacenando dicho módulo de reconocimiento de patrón los patrones
generados en una base de datos de patrones; y
un módulo de detección de anomalías que detecta e identifica dicha
anomalía o anomalías basándose en conjuntos de uno o más incidentes,
17. Sistema según la reivindicación 16, en el que dichos datos de monitorización comprenden métricas de infraestructura y métricas de servicio, comprendiendo dichas métricas de infraestructura indicadores del rendimiento de dichos host físicos y/o virtuales, comprendiendo dichos elementos de almacenamiento y/o dichas redes de interconexión y dichas métricas de servicio indicadores del rendimiento del software ejecutado en dicha infraestructura de TI.
18. Sistema según la reivindicación 17, en el que dicho módulo de monitorización recibe como entrada dichos datos de monitorización y, homogeneizando dichos datos de monitorización, emite un par de valores que contienen la siguiente información: una marca de tiempo que indica cuándo se obtuvieron los datos; y un valor que indica una métrica monitorizada determinada de dichas métricas de infraestructura y métricas de servicio; en el que dicha homogeneización comprende la realización de un nuevo muestreo, interpolación, suavizado de muestras, sincronización de marcas de tiempo y/o cualquier técnica estadística.
19. Sistema según la reivindicación 16, en el que dicho módulo de predicción de serie temporal emite tres valores: una marca de tiempo que indica dicho intervalo estimado; un valor estimado de dicha métrica monitorizada determinada; una proporción de éxito de dicha predicción de evolución a corto plazo; en el que dicha proporción de éxito se calcula según la similitud entre dicho valor estimado y el valor de dicha métrica monitorizada determinada después de dicho intervalo estimado.
20. Sistema según la reivindicación 16, en el que dicho módulo de reconocimiento de patrón emite un patrón de dichos patrones generados y un parámetro de éxito asociado a dicho patrón, siendo dicho parámetro de éxito más alto cuando dicho patrón conduce a dicha anomalía o anomalías.
21. Sistema según la reivindicación 16, en el que dicho módulo de detección de anomalías aplica heurísticas a dichas salidas procedentes de dicho módulo de monitorización y a dichas salidas procedentes de dicho módulo de predicción
de serie temporal con el fin de producir dicho conjunto de uno o más incidentes, almacenar las relaciones entre dicha anomalía o anomalías y dichos conjuntos de uno o más incidentes en una base de datos de anomalías y almacenar correspondencias entre dicha anomalía o anomalías y dichos patrones generados.
22. Sistema según la reivindicación 21, en el que dicho módulo de detección de anomalías realiza dicha detección de dicha anomalía o anomalías consultando en dicha base de datos de anomalías un conjunto de incidentes producidos en un determinado periodo de tiempo o consultando en dicha base de datos de anomalías un patrón generado recibido como entrada en dicho módulo de detección de anomalías.
23. Sistema según la reivindicación 22, en el que dicho módulo de detección de anomalías emite una indicación de anomalía y una probabilidad de éxito de dicha detección de dicha anomalía o anomalías; y una confirmación de anomalía que se activa cuando se confirman dicha anomalía o anomalías por dicho módulo organizador.
24. Sistema según la reivindicación 23, en el que dicho módulo de detección de anomalías desencadena una comprobación con el fin de realizar una prueba en al menos un elemento de dicha infraestructura de TI, proporcionando dicha prueba información del éxito en la detección de una anomalía.
25. Sistema según la reivindicación 23 ó 24, en el que dicho módulo de reconocimiento de patrón recibe como entrada dicha confirmación de anomalía de dicho módulo de detección de anomalías y genera un patrón, cuando se recibe dicha confirmación de anomalía, dicho patrón se basa en un conjunto de métricas antes del momento en que se recibe dicha confirmación de anomalía y almacenándose dicho patrón en dicha base de datos de patrones.
26. Sistema según la reivindicación 25, en el que dicho parámetro de éxito de dicho módulo de reconocimiento de patrón es función de dicha confirmación de anomalía.
27. Sistema según cualquiera de las reivindicaciones anteriores a partir de la 16, en el que dicho módulo originador de acciones recibe al menos salidas de dicho módulo de monitorización y dicho módulo de predicción de serie temporal y proporciona a dicho módulo organizador un flujo de trabajo de dichas acciones correctivas, estando dichas acciones correctivas determinadas por dicha combinación de dichos enfoques estadísticos y dichos modelos analíticos
o por acciones sencillas que no necesitan tipos de modelo, estando encargado
un submódulo evaluador de dicho módulo originador de acciones de equilibrar
los resultados obtenidos con dichos enfoques estadísticos y dichos modelos
analíticos.
28. Sistema según la reivindicación 27, en el que dicho submódulo evaluador
5 selecciona dicho flujo de trabajo proporcionado a dicho módulo organizador
según un historial pasado de proporciones de éxito de dichos enfoques
estadísticos y dichos modelos analíticos para una anomalía concreta, estando
cada una de dichas proporciones de éxito determinada por la realimentación
proporcionada a dicho módulo originador de acciones desde dicho módulo
10 organizador.
29. Sistema según la reivindicación 28, que comprende:
dicho módulo de detección de anomalías que envía una referencia única a
una anomalía concreta y datos asociados de dicha anomalía concreta a dicho
módulo organizador;
15 dicho módulo organizador que reenvía dichos datos asociados a dicho
módulo originador de acciones;
dicho módulo originador de acciones que proporciona dicho flujo de trabajo a
dicho módulo organizador según dichos datos asociados y dicha combinación
de dichos enfoques estadísticos y dichos modelos analíticos; y
20 dicho módulo organizador que aplica dichas acciones correctivas a al menos
un elemento de dicha infraestructura de TI y/o a al menos una de dichas
aplicaciones de múltiples capas.
Patentes similares o relacionadas:
Procedimiento de gestión de módulos de software integrados para una computadora electrónica de un dispositivo de conmutación eléctrica, del 17 de Junio de 2020, de SCHNEIDER ELECTRIC INDUSTRIES SAS: Procedimiento de gestión de módulos de software integrados para una computadora electrónica integrada de un dispositivo eléctrico de conmutación de […]
Restauración de aceleración de servicio, del 10 de Junio de 2020, de Microsoft Technology Licensing, LLC: Un método para restaurar la aceleración del servicio para un servicio, el método que comprende: determinar que la aceleración del servicio para el […]
Aparato, sistema y método para procesar datos de registro de aplicaciones, del 3 de Junio de 2020, de LSIS Co., Ltd: Un sistema de procesamiento de datos de registro que comprende: un dispositivo de control de supervisión que se configura para ejecutar una aplicación y generar […]
Método y dispositivo para procesar información de llamadas de servicio, del 20 de Mayo de 2020, de Advanced New Technologies Co., Ltd: Un método para procesar una cadena de llamadas de servicio, el método que comprende: adquirir una o más cadenas de llamadas de servicio […]
Un método y sistema para modelado de tareas de aplicaciones de teléfono móvil, del 1 de Enero de 2020, de DEUTSCHE TELEKOM AG: Un sistema para determinar el uso y ayudar en la operación de aplicaciones secuenciales interactivas que se ejecutan en uno o más dispositivos móviles, que comprende: […]
Procedimiento de supervisión del rendimiento de una aplicación de software, del 13 de Noviembre de 2019, de Actual Experience PLC: Procedimiento de supervisión del nivel de rendimiento de una aplicación de software que se ejecuta en un dispositivo informático conectado a una red de ordenadores y […]
 Control de utilización de red, del 30 de Octubre de 2019, de Microsoft Technology Licensing, LLC: Un procedimiento de especificación y asignación de ancho de banda de red para aplicaciones distribuidas que se ejecutan en una red en máquinas (114; […]
Control de utilización de red, del 30 de Octubre de 2019, de Microsoft Technology Licensing, LLC: Un procedimiento de especificación y asignación de ancho de banda de red para aplicaciones distribuidas que se ejecutan en una red en máquinas (114; […]
Notificación de instrumentación en tiempo de ejecución, del 21 de Agosto de 2019, de INTERNATIONAL BUSINESS MACHINES CORPORATION: Un procedimiento implementado por ordenador para la notificación de instrumentación en tiempo de ejecución, el procedimiento que comprende: ejecutar […]