MÉTODO PARA GESTIONAR EL RECONOCIMIENTO DEL HABLA DE LLAMADAS DE AUDIO.
Método para gestionar el reconocimiento del habla de llamadas de audio.
En el método de la invención dichas llamadas de audio se realizan en un sistema basado en protocolo de control de recursos de medios, o MRCP, y dicho reconocimiento del habla se lleva a cabo por un motor ASR controlado por un servidor de MRCP buscando una coincidencia entre un flujo de audio generado por un usuario y una gramática compilada.
El método se caracteriza porque comprende realizar dicho reconocimiento del habla de manera continua enviando, dicho servidor de MRCP, eventos regularmente a dicho usuario cuando se producen coincidencias, indicando cada uno de dichos eventos un resultado parcial de dicho reconocimiento del habla e ignorando coincidencias insatisfactorias, deteniendo dicho reconocimiento del habla cuando se recibe una petición de detención desde dicho usuario o cuando dicho flujo de audio finaliza.
Tipo: Patente de Invención. Resumen de patente/invención. Número de Solicitud: P201131647.
Solicitante: TELEFONICA, S.A..
Nacionalidad solicitante: España.
Inventor/es: URDIALES,Diego, SANTIAGO,Miguel Ángel, ORDÁS,Isabel.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G10L15/00 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › Reconocimiento de la voz (G10L 17/00 tiene prioridad).
Fragmento de la descripción:
Método para gestionar el reconocimiento del habla de llamadas de audio Campo de la técnica La presente invención se refiere, en general, a un método para gestionar el reconocimiento del habla de llamadas de audio, realizándose dichas llamadas de audio en un sistema basado en un protocolo de control de recursos de medios, o MRCP, llevándose a cabo dicho reconocimiento del habla por un motor ASR controlado por un servidor de MRCP buscando una coincidencia entre un flujo de audio generado por un usuario y una gramática compilada, y más concretamente a un método que comprende realizar dicho reconocimiento del habla de manera continua enviando, dicho servidor de MRCP, eventos regularmente a dicho usuario cuando se producen coincidencias, indicando cada uno de dichos eventos un resultado parcial de dicho reconocimiento del habla e ignorando las coincidencias insatisfactorias, deteniendo dicho reconocimiento del habla cuando se recibe una petición de detención desde dicho usuario o cuando dicho flujo de audio finaliza.
Estado de la técnica anterior
Uno de los usos principales del reconocimiento del habla hasta ahora han sido los sistemas de IVR (Respuesta de Voz Interactiva) . Los centros de llamadas usan sistemas de IVR para reducir costes, automatizando la gestión de peticiones de cliente. Para realizar esto, es necesario capturar el habla y luego procesarla mediante un motor ASR (Reconocimiento del Habla Automático) . El ASR analiza el habla y produce una coincidencia si algo se ha detectado.
El motor ASR requiere una gramática para procesar el habla. Esta gramática contiene un conjunto limitado de palabras u oraciones esperadas. Los resultados son coincidentes sólo si la persona que habla dice algún elemento de la lista. Los resultados se analizan programáticamente y el sistema se comportará de una u otra manera dependiendo de ellos.
Para interactuar con un motor de reconocimiento del habla, el IETF define un protocolo denominado protocolo de control de recursos de medios (MRCP) . El MRCP se describe en la RFC 4463 [1]. Este protocolo controla recursos de servicio de medios como sintetizadores de habla, reconocedores, etc. Tal como se define en esta RFC, el MRCP usa el RTSP como protocolo de control de sesión. Actualmente, hay un borrador para especificar el MRCP que usa el SIP (MRCP versión 2 [2]) .
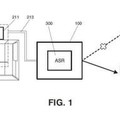
Con respecto a la arquitectura de MRCP, tal como se mostrará en la figura 1, consiste en un cliente que requiere flujos de medios generados (reconocedores) o necesita flujos de medios procesados (sintetizadores) y un servidor que tenga los recursos o dispositivos para procesar (reconocedores) o generar (sintetizadores) los flujos.
El cliente establece una sesión de control con el servidor para el procesamiento de medios usando un protocolo tal como RTSP (MRCPv1) o SIP (MRCPv2) . Esto también configurará y establecerá el flujo de RTP entre el cliente y el servidor u otro punto de extremo de RTP.
El conjunto de mensajes de MRCP consiste en peticiones del cliente para el servidor, las respuestas del servidor al cliente y eventos asíncronos del servidor al cliente.
La figura 2 mostrará el intercambio de mensajes, tanto para sesiones de SIP como de MRCP. Inicialmente, el cliente de MRCPv2 (21) envía el SIP INVITE (211) al servidor de MRCPv2 (22) para establecer la sesión, indicando el tipo de recurso de servidor requerido (a=resource:speechrecog) . El servidor de MRCPv2 debe responder con el identificador de canal completo y el puerto de TCP al que deben enviarse los mensajes de MRCPv2 (221) .
SET-PARAMS (213) es un método que lleva un conjunto de parámetros en la cabecera para configurar el motor ASR. La respuesta del servidor al cliente cuando se ha configurado el ASR es 200 COMPLETE (222) .
El método DEFINE-GRAMMAR (214) , del cliente al servidor, proporciona una o más gramáticas y solicita al servidor acceder a, recoger y compilar las gramáticas que se necesitan. La respuesta del servidor al cliente cuando se ha realizado esto es 200 COMPLETE (223) .
El método RECOGNIZE (215) solicita al recurso de reconocedor que comience el reconocimiento. La petición RECOGNIZE usa el cuerpo de mensaje para especificar las gramáticas aplicables a la petición. El MRCPv2 debe enviar la respuesta 200 IN-PROGRESS (224) para informar al cliente de MRCPv2 de que el reconocimiento acaba de comenzar.
START-OF-INPUT (225) es un evento del servidor al cliente que indica que el recurso de reconocimiento ha detectado habla.
RECOGNITION-COMPLETE (226) es un evento del recurso de reconocedor al cliente que indica que el reconocimiento se ha completado. El resultado de reconocimiento se envía en el cuerpo del mensaje de MRCPv2.
El método “STOP” (216) del cliente al servidor indica al recurso que detenga el reconocimiento si una petición está activa. El servidor confirma el fin del reconocimiento con 200 COMPLETE (227) .
Finalmente, puesto que el canal de MRCPv2 ya no se usa, también puede finalizarse la sesión SIP (217, 228, 218) .
Hay 2 modos de operación soportados para reconocimiento:
- Reconocimiento de modo normal: intenta hacer coincidir todo el habla contra la gramática y devuelve un estado de no coincidencia si la entrada no coincide o se supera el límite de tiempo del método.
- Reconocimiento de modo de palabras activas: el reconocedor busca una coincidencia con la gramática de habla específica e ignora el habla que no coincide. El reconocimiento se completa sólo para una coincidencia satisfactoria de gramática o si el cliente cancela la petición o si hay un límite de tiempo sin entrada o del reconocimiento.
Hay unos cuantos parámetros que pueden enviarse al servidor de MRCP dentro de las peticiones RECOGNIZE
(215) o SET-PARAMS (213) incluyendo sus valores en los campos de cabecera. Esos valores se usan para configurar el motor ASR y prepararlo para el reconocimiento. Por ejemplo, normalmente se usan valores de configuración tales como umbral de confianza, nivel de sensibilidad, etc. Los parámetros relacionados con los límites de tiempo que podrían ser significativos son los siguientes:
- Límite de tiempo sin entrada: indica cuando se inicia el reconocimiento y no hay habla detectada durante un determinado periodo de tiempo. En ese caso, el reconocedor envía un evento RECOGNITION-COMPLETE al cliente y termina la operación de reconocimiento.
- Límite de tiempo del reconocimiento: indica cuando se inicia el reconocimiento y no hay coincidencia durante un determinado periodo de tiempo. En ese caso, el reconocedor envía un evento RECOGNITION-COMPLETE al cliente y termina la operación de reconocimiento.
- Límite de tiempo de habla completada: indica la longitud de silencio requerida tras el habla de usuario antes de que el reconocedor del habla finalice un resultado (o bien aceptándolo o bien generando un evento de no coincidencia) .
- Límite de tiempo de habla no completada: indica la longitud de silencio tras el habla de usuario después del cual un reconocedor finaliza un resultado. Una vez que se ha disparado el límite de tiempo, se rechaza el resultado parcial.
- Duración máxima de palabras activas: indica la longitud máxima de unidad de habla que se considerará para el reconocimiento de palabras activas.
- Duración en minutos de palabras activas: indica la longitud mínima de unidad de habla que se considerará para el reconocimiento de palabras activas.
Tal como se describió anteriormente, los recursos de medios que proporcionan una funcionalidad de reconocimiento del habla, tal como servidores de procesamiento del habla en IVR, se controlan a través de un protocolo convencional denominado MRCP. Este protocolo soporta 2 modos de reconocimiento diferentes, en los que un flujo de audio se hace coincidir con una gramática predefinida para producir un resultado de reconocimiento. Estos modos se seleccionan para aplicaciones con flujos de audio cortos y limitados, tal como la conversación que una persona mantiene con una máquina. Ninguno de los modos de operación existentes soporta flujos de audio de longitud arbitraria, tales como los que suceden en una conversación de persona a persona, que requieren un lazo continuo de peticiones de reconocimiento que no se controla de manera óptima.
De hecho, determinadas aplicaciones exigen que, durante una conversación de persona a persona, los resultados del reconocimiento aparezcan en tiempo real o al menos cuando la conversación aún sigue en curso. Para este propósito, los modos de reconocimiento del protocolo actual fuerzan un proceso de reconocimiento intermitente con iteraciones de petición-respuesta. No hay ningún mecanismo en el protocolo para controlar un recurso...
Reivindicaciones:
1. Método para gestionar el reconocimiento del habla de llamadas de audio, realizándose dichas llamadas de audio en un sistema basado en protocolo de control de recursos de medios, o MRCP, llevándose a cabo dicho reconocimiento del habla por un motor ASR controlado por un servidor de MRCP buscando una coincidencia entre un flujo de audio generado por un usuario y una gramática compilada, caracterizado porque comprende realizar dicho reconocimiento del habla de manera continua enviando, dicho servidor de MRCP, eventos regularmente a dicho usuario cuando se producen coincidencias, indicando cada uno de dichos eventos un resultado parcial de dicho reconocimiento del habla e ignorando coincidencias insatisfactorias, deteniendo dicho reconocimiento del habla cuando se recibe una petición de detención desde dicho usuario o cuando dicho flujo de audio finaliza.
2. Método según la reivindicación 1, que comprende realizar dicho reconocimiento del habla según un modo de operación diferente del reconocimiento de modo normal y reconocimiento de modo de palabras activas definidos por el grupo de trabajo de ingeniería de Internet.
3. Método según la reivindicación 2, que comprende indicar dicho modo de operación a dicho servidor de MRCP por medio de una petición SET-PARAMS o RECOGNIZE existente del protocolo MRCP.
4. Método según cualquiera de las reivindicaciones anteriores, que comprende decidir, un módulo de reconocimiento del habla automático de dicho sistema basado en MRCP, cuándo se ha producido una coincidencia y enviar, dicho servidor de MRCP, un evento cada vez que se ha producido una coincidencia.
5. Método según cualquiera de las reivindicaciones anteriores, que comprende incluir un parámetro en la petición SET-PARAMS y/o RECOGNIZE existente del protocolo MRCP, indicando dicho parámetro un intervalo de tiempo máximo en el que dicho servidor de MRCP debe comprobar resultados parciales no devueltos.
6. Método según cualquiera de las reivindicaciones anteriores, que comprende usar diferentes gramáticas compiladas mientras que se realiza dicho reconocimiento del habla cargando, dicho usuario, una gramática dada por medio de la petición DEFINE-GRAMMAR existente del protocolo MRCP y compilar, dicho servidor de MRCP, dicha gramática dada.
7. Método según la reivindicación 6, que comprende descargar un gramática concreta desde dicho servidor de MRCP cuando recibe, dicho servidor de MRCP, una petición UNLOAD-GRAMMAR, definiéndose dicha petición UNLOAD-GRAMMAR para el protocolo MRCP.
8. Método según la reivindicación 6 ó 7, que comprende incluir un parámetro de límite de tiempo de carga de gramáticas en una petición SET-PARAMS o DEFINE-GRAMAR existente del protocolo MRCP, indicando dicho parámetro de límite de tiempo de carga de gramáticas el tiempo máximo que hay que esperar una respuesta de una petición DEFINE-GRAMMAR.
9. Método según la reivindicación 8, que comprende enviar una respuesta COMPLETE del protocolo MRCP desde dicho servidor de MRCP hasta dicho usuario si se supera dicho parámetro de límite de tiempo de carga de gramáticas y continuar enviando dichos resultados parciales según una gramática anterior.
10. Método según cualquiera de las reivindicaciones anteriores, que comprende cambiar el estado de dicho servidor de MRCP, según el protocolo MRCP, de un estado de reconocimiento a un estado en espera sólo cuando se recibe una petición STOP de dicho usuario a dicho servidor de MRCP.
11. Método según cualquiera de las reivindicaciones anteriores, que comprende establecer una llamada en una central automática privada, o PBX, y crear dos canales de procesamiento entre dicha PBX y dicho servidor de MRCP, uno por cada parte de dicha llamada y usándose cada uno de dichos dos canales de procesamiento para realizar dicho procesamiento del habla sobre flujos de audio generados por la parte que llama.
12. Método según la reivindicación 11, en el que dicho flujo de audio tiene una longitud arbitraria y contiene intervalos de silencio.
Figura 1
Figura 2 Figura 3
Figura 4 Figura 5
Figura 6 Figura 7
Patentes similares o relacionadas:
Método y aparato de intercambio de información, del 20 de Mayo de 2020, de Advanced New Technologies Co., Ltd: Un método de intercambio de información, realizado en un dispositivo terminal, caracterizado porque el método comprende: determinar […]
SISTEMA Y DISPOSITIVO INALÁMBRICO Y PONIBLE PARA REGISTRO, PROCESAMIENTO Y REPRODUCCIÓN DE SONIDOS EN PERSONAS CON DISTROFIA EN EL SISTEMA RESPIRATORIO, del 5 de Marzo de 2020, de ARAGÓN HAN, Daniel: La invención se refiere a un sistema y dispositivo para el registro, procesamiento y reproducción de sonidos en personas con distrofia en el […]
Sistema y método para la automatización y uso seguro de aplicaciones móviles en vehículos, del 21 de Mayo de 2019, de UNIVERSIDAD DE LA LAGUNA: Sistema y método para la automatización y uso seguro de aplicaciones móviles especialmente diseñado para ser utilizado por conductores de vehículos mientras se conduce […]
SISTEMA DE IDENTIFICACIÓN DE SONIDOS MEDIANTE CLASIFICACIÓN PARAMÉTRICA DE SERIES DERIVADAS, del 17 de Mayo de 2018, de UNIVERSIDAD DE SEVILLA: La presente invención tiene por objeto un sistema de identificación de sonidos que se basa en la descripción y selección de unos pocos parámetros […]
Sistema de identificación de sonidos mediante clasificación paramétrica de series derivadas, del 11 de Mayo de 2018, de UNIVERSIDAD DE SEVILLA: La presente invención tiene por objeto un sistema de identificación de sonidos que se basa en la descripción y selección de unos pocos parámetros […]
SISTEMA Y MÉTODO PARA LA AUTOMATIZACIÓN Y USO SEGURO DE APLICACIONES MÓVILES EN VEHÍCULOS, del 21 de Septiembre de 2017, de UNIVERSIDAD DE LA LAGUNA: Sistema y método para la automatización y uso seguro de aplicaciones móviles especialmente diseñado para, ser utilizado por conductores de vehículos mientras […]
Tarjeta inteligente con micrófono, del 7 de Enero de 2015, de VODAFONE HOLDING GMBH: Una tarjeta inteligente, que comprende un micrófono para capturar una señal de audio, y al menos un medio (104; 110; 111i) de procesamiento para procesar […]
 Método e instalación de comprobación de sistemas de alarma a distancia en ascensores, del 7 de Mayo de 2014, de ORONA, S. COOP.: Método e instalación de comprobación de sistemas de alarma a distancia en ascensores.
Permiten realizar una comprobación completa, eficaz y rápida de los […]
Método e instalación de comprobación de sistemas de alarma a distancia en ascensores, del 7 de Mayo de 2014, de ORONA, S. COOP.: Método e instalación de comprobación de sistemas de alarma a distancia en ascensores.
Permiten realizar una comprobación completa, eficaz y rápida de los […]