Método, dispositivo de procesamiento de datos y red informática para la detección de anomalías.
Un método para detectar un funcionamiento anómalo dentro de una red informática (10) con múltiples nodos de procesamiento de datos (101-103,
201, 202, 210) que están interconectados a efectos de comunicación de datos, en el que:
a) mediante un primer nodo de procesamiento de datos (101; 102; 103) de la red informática (10) se determina un primer valor de estado, que es una medida de la probabilidad de un funcionamiento anómalo,
b) mediante por lo menos un segundo nodo de procesamiento de datos (102, 103; 101, 103; 101, 102) de la red informática (10) se determina un segundo valor de estado, que es una medida de la probabilidad de un funcionamiento anómalo,
c) dicho segundo valor de estado se transmite desde dicho por lo menos un segundo nodo de procesamiento de datos (102, 103; 101, 103; 101, 102) a dicho primer nodo de procesamiento de datos (101; 102; 103) a través de una comunicación entre pares,
d) a partir de dichos primer y segundo valores de estado se determina un tercer valor de estado mediante el nodo de procesamiento de datos (101; 102; 103), y
e) dependiendo del tercer valor de estado, se determina si ha ocurrido un funcionamiento anómalo, caracterizado porque la etapa de determinar dicho tercer valor de estado comprende las etapas de
- determinar un valor promedio de dichos segundos valores de estado,
- ponderar el primer valor de estado con un primer factor de ponderación,
- ponderar dicho valor promedio con un segundo factor de ponderación, y
- sumar el primer valor de estado ponderado y el valor promedio ponderado, obteniéndose de ese 20 modo dicho tercer valor de estado
Tipo: Patente Europea. Resumen de patente/invención. Número de Solicitud: E07012405.
Solicitante: DEUTSCHE TELEKOM AG.
Nacionalidad solicitante: Alemania.
Dirección: FRIEDRICH-EBERT-ALLEE 140 53113 BONN ALEMANIA.
Inventor/es: MULLER, ACHIM, BYE,RAINER, LUTHER,KATJA, ALPCAN,TANSU DR, ALBAYRAK,SAHIN PROF. DR.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G06F21/00 FISICA. › G06 CALCULO; CONTEO. › G06F PROCESAMIENTO ELECTRICO DE DATOS DIGITALES (sistemas de computadores basados en modelos de cálculo específicos G06N). › Disposiciones de seguridad para la protección de computadores, sus componentes, programas o datos contra actividades no autorizadas.
- H04L29/06 ELECTRICIDAD. › H04 TECNICA DE LAS COMUNICACIONES ELECTRICAS. › H04L TRANSMISION DE INFORMACION DIGITAL, p. ej. COMUNICACION TELEGRAFICA (disposiciones comunes a las comunicaciones telegráficas y telefónicas H04M). › H04L 29/00 Disposiciones, aparatos, circuitos o sistemas no cubiertos por uno solo de los grupos H04L 1/00 - H04L 27/00. › caracterizadas por un protocolo.
PDF original: ES-2398374_T3.pdf
Fragmento de la descripción:
Método, dispositivo de procesamiento de datos y red informática para la detección de anomalías.
Campo de la invención La invención se refiere a redes de comunicación en general, y especialmente a un método, un dispositivo de procesamiento de datos y una red informática para detectar un funcionamiento anómalo dentro de una red informática, en particular debido a una intrusión maliciosa desde el exterior de la red.
Antecedentes de la invención Se conoce por software malicioso o malware (de "malicious software") , un software que está diseñado para atacar sistemas informáticos, en el que el malware se difunde a través de una red de comunicación a la que el sistema informático es conectable. Actualmente, los atacantes se dirigen fundamentalmente a ordenadores personales (PCs) para suplantación, escucha furtiva, violar autorizaciones, modificar o destruir, manipular, falsificar y sabotear datos. Esto ocurre sobre todo utilizando o liberando cierto software malicioso (malware) , que puede clasificarse por ejemplo como troyanos, virus o gusanos. Se utilizan diferentes técnicas para defender y asegurar sistemas potencialmente atacados, tales como por ejemplo software de cortafuegos basado en listas blancas, software de antivirus basado en listas negras, y sistemas de detección de intrusión y de prevención de intrusión (IDS/IPS, intrusion detection and intrusion prevention systems) basados en anomalías.
La gran mayoría de los sistemas de detección de intrusión utilizan enfoques basados en firmas, para detectar ataques. Sin embargo, esto no permite la detección de ataques de día cero, puesto que las firmas sólo pueden generarse retrospectivamente, es decir, después de que el ataque se ha llevado a cabo por lo menos una vez.
La detección basada en anomalías es una alternativa viable a los enfoques basados en firmas, cuando se intenta detectar un comportamiento anómalo del sistema provocado por instrucciones exitosas.
A partir del documento US 6 711 615 B2, por ejemplo, se conoce un método de vigilancia de redes que comprende monitorización y análisis jerárquico de eventos dentro de una red corporativa, en el que mediante monitores de la red se detecta una actividad sospechosa de la red, en base al análisis de los datos de tráfico de la red, para lo cual se proporciona en el monitor una unidad de inferencia basada en firmas y una unidad de detección de anomalías estadísticas. Se generan informes de la actividad sospechosa mediante los monitores de la red, que son recibidos automáticamente por monitores jerárquicos.
Sin embargo, el punto débil de los sistemas basados en anomalías es la elevada tasa de falsos positivos, lo que significa que a menudo se emiten alarmas cuando el sistema de hecho se comporta normalmente. Como consecuencia, esto conduce elevados costes de mantenimiento y, lo que es peor, a situaciones en las que las alarmas correctas son ignoradas por los usuarios debido a la elevada frecuencia de falsas alarmas.
La utilización de sistemas inmunes artificiales (AIS, Artificial Immune System) para vigilancia de redes se describe, por ejemplo, en la tesis de máster de K. Luther "Entwurf eines Künstlichen Immunsystems zur Netzwerküberwachung auf Basis eines Multi-Agenten-Systems", TU Berlín, 2006.
El documento "On decision support for distributed systems protection: A perspective based on the human immune response system and epidemiology", de S. Goel y otros, International Journal of Information Management, Elsevier Science Ltd., GB, volumen 27, número 4, 12 de junio de 2007, páginas 266 a 278, se refiere a un sistema de seguridad de redes basado en AIS, en el que la detección de virus se realiza mediante la inspección aleatoria de paquetes, para limitar los recursos utilizados para la exploración de paquetes. Múltiples sistemas inmunes en un vecindario comparten información entre sí, de manera que la detección del virus en un vecindario puede utilizarse como disparador para incrementar la frecuencia de muestreo de la inspección de paquetes.
En el documento WO 03/029934 A1 se describe un sistema de detección de intrusión basado en agentes, en el que los agentes individuales comparten firmas de ataques y soluciones a través de un mecanismo de intercambio de mensajes, y en el que puede utilizarse una medida interna global de la salud general del grupo de agentes, como un indicador de un posible ataque. Sin embargo, la incidencia de falsos positivos sigue siendo un problema.
Por lo tanto, un objetivo de la presente invención es mostrar una manera novedosa y mejorada de detectar un comportamiento anómalo dentro de una red informática, en el que, en particular, se reduce la tasa de detecciones de falsos positivos.
Resumen de la invención La solución inventiva del objetivo se consigue mediante cada uno de los contenidos de las respectivas reivindicaciones independientes adjuntas. Los contenidos de las respectivas reivindicaciones dependientes adjuntas son realizaciones ventajosas y/o preferidas, o mejoras.
Para detectar un funcionamiento anómalo dentro de una red informática que comprende múltiples nodos interconectados de procesamiento de datos, el método inventivo propone un enfoque cooperativo, en el que mediante un primer nodo de procesamiento de datos de la red informática se determina un primer valor de estado, que es una medida de la probabilidad de un funcionamiento anómalo, y mediante un segundo nodo de procesamiento de datos de la red informática se determina un segundo valor de estado, que es asimismo una medida de la probabilidad de un funcionamiento anómalo. Para conseguir cooperación, dicho segundo valor de estado se transmite mediante comunicación entre pares desde dicho por lo menos un segundo nodo de procesamiento de datos al primer nodo de procesamiento de datos, a partir de dichos primer y segundo valores de estado se determina un tercer valor de estado mediante el primer nodo de procesamiento de datos, y en función del tercer valor de estado se determina si se ha producido un funcionamiento anómalo.
Para determinar el tercer valor del estado se determina un valor promedio de los segundos valores de estado, el primer valor de estado se pondera con un primer factor de ponderación, el valor promedio se pondera con un segundo factor de ponderación, y se suman el primer valor de estado ponderado y el valor promedio ponderado, obteniéndose de ese modo un tercer valor de estado.
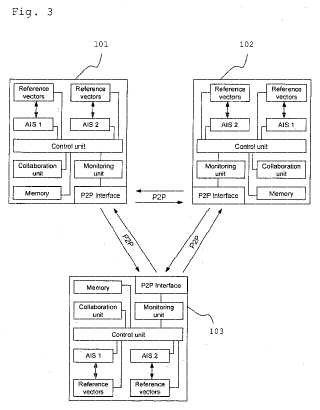
El primer y el segundo nodos de procesamiento de datos son habitualmente ordenadores estacionarios, pero pueden disponerse asimismo como cualesquiera otros dispositivos capaces de procesamiento de datos, tales como por ejemplo dispositivos informáticos móviles o teléfonos inteligentes. Por consiguiente, los nodos de procesamiento de datos pueden interconectarse utilizando cualquier clase de medio de comunicación adecuado, tales como por ejemplo una LAN, una WLAN, Bluetooth o una red celular basada en GSM o UMTS.
Para determinar el primer valor de estado se monitoriza habitualmente el tráfico de red del primer nodo de procesamiento de datos. Por lo tanto, el primer valor de estado en concreto es una medida de la probabilidad de un funcionamiento anómalo del primer nodo de procesamiento. Para reducir las detecciones de falsos positivos de funcionamiento anómalo, se propone una cooperación con otros nodos de procesamiento de datos de la red informática, que tiene como resultado dicho tercer valor de estado que incorpora asimismo los segundos valores de estado recibidos desde los segundos nodos de procesamiento de datos, y en función de este tercer valor se decide si existe un funcionamiento anómalo.
Puesto que muchos ataques maliciosos de la red informática tienen como resultado la difusión de cierto malware dentro de la red informática, la probabilidad de que un nodo de procesamiento de datos dado que detecta una actividad de red anómala esté infectado, aumenta si otros nodos de procesamiento de datos detectan asimismo la actividad de red anómala. Por lo tanto, mediante el enfoque cooperativo del método descrito se aumenta la precisión de la detección, reduciéndose por lo tanto las detecciones de falsos positivos.
Para una detección en curso, las etapas descritas anteriormente de determinación del primer valor de estado, determinación y transmisión de dicho por lo menos un segundo valor de estado, determinación del tercer valor de estado y, en función del tercer valor de estado, decisión sobre si se ha producido un funcionamiento anómalo, se repiten preferentemente en tiempos predefinidos, en particular con una frecuencia predefinida.
En principio, el primer valor de estado puede determinarse mediante cualquier algoritmo de detección de anomalías adecuado, o incluso mediante... [Seguir leyendo]
Reivindicaciones:
1. Un método para detectar un funcionamiento anómalo dentro de una red informática (10) con múltiples nodos de procesamiento de datos (101-103, 201, 202, 210) que están interconectados a efectos de comunicación de datos, en el que:
a) mediante un primer nodo de procesamiento de datos (101; 102; 103) de la red informática (10) se determina un primer valor de estado, que es una medida de la probabilidad de un funcionamiento anómalo,
b) mediante por lo menos un segundo nodo de procesamiento de datos (102, 103; 101, 103; 101, 102) de la red informática (10) se determina un segundo valor de estado, que es una medida de la probabilidad de un funcionamiento anómalo,
c) dicho segundo valor de estado se transmite desde dicho por lo menos un segundo nodo de procesamiento de datos (102, 103; 101, 103; 101, 102) a dicho primer nodo de procesamiento de datos (101; 102; 103) a través de una comunicación entre pares,
d) a partir de dichos primer y segundo valores de estado se determina un tercer valor de estado mediante el nodo de procesamiento de datos (101; 102; 103) , y
e) dependiendo del tercer valor de estado, se determina si ha ocurrido un funcionamiento anómalo, caracterizado porque la etapa de determinar dicho tercer valor de estado comprende las etapas de
- determinar un valor promedio de dichos segundos valores de estado,
- ponderar el primer valor de estado con un primer factor de ponderación,
- ponderar dicho valor promedio con un segundo factor de ponderación, y
- sumar el primer valor de estado ponderado y el valor promedio ponderado, obteniéndose de ese modo dicho tercer valor de estado.
2. El método acorde con la reivindicación 1, en el que las etapas a) a e) se repiten en momentos predefinidos.
3. El método acorde con la reivindicación 1 ó 2, en el que la determinación de dicho primer valor de estado se realiza por medio de un algoritmo basado en un sistema inmune artificial.
4. El método acorde con la reivindicación 3, que comprende además la etapa de almacenar en el primer nodo de procesamiento de datos, por lo menos un conjunto de vectores de referencia que están asociados con un funcionamiento anómalo,
en el que la etapa de determinar dicho primer valor de estado comprende las etapas de
- monitorizar tráfico de datos de la red,
- determinar por lo menos un vector de datos de tráfico a partir del tráfico de red monitorizado, en el que cada uno de los componentes del vector de dicho vector de datos de tráfico está asociado con una respectiva característica predefinida del tráfico de datos de la red monitorizado,
- determinar las distancias entre cada vector de datos de tráfico y cada vector de referencia de un conjunto respectivo de los conjuntos almacenados de vectores de referencia (121, 122, 12N) , mediante una medida predeterminada de la distancia.
5. El método acorde con la reivindicación 4, en el que se almacenan por lo menos dos conjuntos diferentes de vectores de referencia (121, 122, 12N) , y se determinan por lo menos dos vectores de datos de tráfico diferentes.
6. El método acorde con la reivindicación 4 ó 5, en el que la medida predefinida de la distancia es la distancia de Hamming o la distancia euclídea.
7. El método acorde con cualquiera de las reivindicaciones 4 a 6, en el que el primer valor de estado está representado por un contador, y en el que dicho contador se incrementa para cada vector de referencia para el que se determina que la distancia al respectivo vector de datos de tráfico está por debajo de un umbral predefinido.
8. El método acorde con la reivindicación 7, en el que dicho contador se incrementa mediante un valor que es inversamente proporcional a dicha distancia.
9. El método acorde con cualquiera de las reivindicaciones 4 a 8, en el que cada conjunto de vectores de referencia (121, 122, 12N) se determina inicialmente mediante el primer nodo de procesamiento (101; 102; 103) , llevando a cabo las etapas de
aa) determinar datos de aprendizaje que representan un comportamiento normal del sistema, mediante monitorizar el tráfico de red durante una fase de aprendizaje, comprendiendo dichos datos de aprendizaje múltiples vectores de datos de tráfico,
bb) generar un vector de datos aleatorio,
cc) comparar dicho vector de datos aleatorio con cada vector de datos de tráfico de dichos datos de aprendizaje,
dd) añadir dicho vector de datos aleatorio al conjunto de vectores de referencia (121, 122, 12N) si no coincide con ninguno de los vectores de datos de tráfico de dichos datos de aprendizaje, en el que se define que los vectores coinciden si su distancia está por debajo del umbral predefinido, y
ee) repetir las etapas bb) a dd) hasta que el conjunto de vectores de referencia (121, 122, 12N) comprende un número predefinido de vectores de referencia.
10. El método acorde con la reivindicación 9, en el que cada vector de referencia de cada conjunto de vectores de referencia (121, 122, 12N) está asociado con una vida útil predefinida, después de la cual es eliminado del conjunto (121, 122, 12N) y sustituido por un nuevo vector de referencia que se determina realizando las etapas bb) a ee) .
11. El método acorde con cualquiera de las reivindicaciones 4 a 10, que comprende además las etapas de
- seleccionar por lo menos un vector de referencia para el cual se ha determinado que la distancia a un vector de datos de tráfico está por debajo del umbral predefinido,
- generar por lo menos un vector modificado, modificando cada componente de vectorial de dicho vector de referencia seleccionado, mediante una cantidad aleatoria que queda dentro de un intervalo predefinido, y
- añadir dicho vector modificado al respectivo conjunto de vectores de referencia (121, 122, 12N) .
12. El método acorde con cualquiera de las reivindicaciones anteriores, en el que dicho primer factor de ponderación es mayor que dicho segundo factor de ponderación.
13. El método acorde con cualquiera de las reivindicaciones anteriores, en el que la suma de dichos primer y segundo factores de ponderación vale 1.
14. El método acorde con cualquiera de las reivindicaciones anteriores,
en el que la relación entre el primer y el segundo factores de ponderación es esencialmente igual a una relación seleccionada entre el grupo que consiste en 60:40, 70:30, 80:20 y 90:10.
15. El método acorde con cualquiera de las reivindicaciones anteriores, en el que una señal de alarma es generada por el primer nodo de procesamiento de datos (101; 102; 103) cuando el tercer valor de estado supera un umbral predefinido.
16. El método acorde con la reivindicación 15, en el que dicha señal de alarma se transmite desde el primer nodo de procesamiento de datos (101; 102; 103) a un nodo administrativo de monitorización (210) .
17. El método acorde con cualquiera de las reivindicaciones anteriores, en el que cada uno de los segundos valores de estado se determina mediante el respectivo segundo nodo de procesamiento de datos (102, 103; 101, 103; 101, 102) , tal como se define mediante cualquiera de las reivindicaciones 3 a 11, con respecto al primer valor de estado.
18. El método acorde con cualquiera de las reivindicaciones anteriores, en el que cada uno de los segundos valores de estado se determina mediante el respectivo segundo nodo de procesamiento de datos (102, 103; 101, 103; 101, 102) , tal como se define mediante cualquiera de las reivindicaciones 12 a 15, con respecto al tercer valor de estado.
19. El método acorde con cualquiera de las reivindicaciones 4 a 18, en el que el primer nodo de procesamiento de datos (101; 102; 103) transmite, en respuesta a la determinación de que se ha producido un funcionamiento anómalo, el tercer valor de estado y los respectivos vectores de referencia asociados con el funcionamiento anómalo, a dicho por lo menos un segundo nodo de procesamiento de datos (102, 103; 101, 103; 101, 102) .
20. Un dispositivo de procesamiento de datos (101; 102; 103) adaptado para la detección de funcionamiento anómalo dentro de una red informática (10) , que comprende
- una interfaz de red (160) que está adaptada para recibir, mediante una comunicación entre pares desde por lo menos otro dispositivo de procesamiento de datos (102, 103; 101, 103; 101, 102) predefinido, un segundo valor de estado que es una medida de la probabilidad de un funcionamiento anómalo dentro de la red informática (10) ,
- una unidad de monitorización (170) para monitorizar el tráfico de datos de la red,
- por lo menos una unidad de detección de anomalías (111, 112, 11N) adaptada para determinar un primer valor de estado, que es una medida de la probabilidad de un funcionamiento anómalo dentro de la red informática (10) ,
- una unidad de colaboración (150) adaptada para determinar un tercer valor de estado a partir de dicho primer valor de estado y de dichos segundos valores de estado, y
- medios de determinación para determinar, en función de dicho tercer valor de estado, si se ha producido un funcionamiento anómalo, caracterizado porque
la unidad de colaboración (150) está adaptada para determinar dicho tercer valor de estado mediante
- determinar un valor promedio de dichos segundos valores de estado,
- ponderar el primer valor de estado con un primer factor de ponderación,
- ponderar dicho valor promedio con un segundo factor de ponderación, y
- sumar el primer valor de estado ponderado y el valor promedio ponderado, obteniéndose de ese modo dicho tercer valor de estado.
21. El dispositivo acorde con la reivindicación 20, en el que cada unidad de detección de anomalías (111, 112, 11N) y la unidad de colaboración (10) están adaptadas respectivamente para determinar automáticamente primeros y terceros valores de estado en tiempos predefinidos.
22. El dispositivo acorde con la reivindicación 20 ó 21, en el que cada unidad de detección de anomalías (111, 112, 11N) está adaptada para determinar primeros valores de estado mediante un algoritmo basado en un sistema inmune artificial.
23. El dispositivo acorde con la reivindicación 22, adaptado para determinar para cada unidad de detección de anomalías un vector de datos de tráfico a partir de tráfico de red monitorizado, en el que cada uno de los componentes vectoriales de dicho vector de datos de tráfico está asociado con una respectiva característica predefinida del tráfico de datos de red monitorizado, y que comprende medios de almacenamiento para almacenar, para cada unidad de detección de anomalías (111, 112, 11N) , un conjunto de vectores de referencia (121, 122, 12N) que están asociados con un funcionamiento anómalo, en el que
cada unidad de detección de anomalías (111, 112, 11N) está adaptada para determinar las distancias entre un respectivo vector de datos de tráfico y cada vector de referencia del respectivo conjunto de entre los conjuntos almacenados de vectores de referencia (121, 122, 12N) , mediante una medida predefinida de la distancia.
24. El dispositivo acorde con la reivindicación 23, que comprende por lo menos dos unidades de detección de anomalías (111, 112, 11N) .
25. El dispositivo acorde con cualquiera de las reivindicaciones 23 ó 24, en el que cada unidad de detección de anomalías (111, 112, 11N) comprende un contador, en el que la lectura del contador representa el primer valor de estado, y está adaptada para incrementar dicho contador para cada vector de referencia para el cual se determina que la distancia hasta el respectivo vector de datos de tráfico está por debajo de un umbral predefinido.
26. El dispositivo acorde con la reivindicación 25, en el que cada unidad de detección de anomalías (111, 112, 11N) está adaptada para incrementar dicho contador en un valor que es inversamente proporcional a dicha distancia.
27. El dispositivo acorde con cualquiera de las reivindicaciones 23 a 26, adaptado para determinar cada conjunto de vectores de referencia (121, 122, 12N) , mediante la realización de las etapas de
aa) determinar datos de aprendizaje que representan un comportamiento normal del sistema, mediante monitorizar el tráfico de red durante una fase de aprendizaje, comprendiendo dichos datos de aprendizaje múltiples vectores de datos de tráfico,
bb) generar un vector de datos aleatorio,
cc) comparar dicho vector de datos aleatorio con cada vector de datos de tráfico de dichos datos de aprendizaje,
dd) añadir dicho vector de datos aleatorio al conjunto de vectores de referencia (121, 122, 12N) si no coincide con ninguno de los vectores de datos de tráfico de dichos datos de aprendizaje, en el que se define que los vectores coinciden si su distancia está por debajo del umbral predefinido, y
ee) repetir las etapas bb) a dd) hasta que el conjunto de vectores de referencia (121, 122, 12N) comprende un número predefinido de vectores de referencia.
28. El dispositivo acorde con la reivindicación 27, adaptado para eliminar cada vector de referencia de cada conjunto de vectores de referencia (121, 122, 12N) después de una vida útil predefinida asociada, y para sustituirlo por un nuevo vector de referencia que se determina llevando a cabo las etapas bb) a ee) .
29. El dispositivo acorde con cualquiera de las reivindicaciones 23 a 28, en el que cada unidad de detección de anomalías (111, 112, 11N) está adaptada para
- seleccionar por lo menos un vector de referencia del respectivo conjunto de vectores de referencia (121, 122, 12N) para el que se ha determinado que la distancia hasta un vector de datos de tráfico está por debajo del umbral predefinido,
- generar un vector modificado, modificando cada componente vectorial de dicho vector de referencia seleccionado, en una cantidad aleatoria que está dentro de un intervalo predefinido, y
- añadir dicho vector modificado al respectivo conjunto de vectores de referencia (121, 122, 12N) .
30. El dispositivo acorde con cualquiera de las reivindicaciones anteriores, adaptado para generar una señal de alarma cuando el tercer valor de estado supera un umbral predefinido.
31. El dispositivo acorde con cualquiera de las reivindicaciones anteriores, adaptado para transmitir el primer y/o el tercer valor de estado, mediante una comunicación entre pares, por lo menos a otro dispositivo de procesamiento de datos predefinido (102, 103; 101, 103; 101, 102) .
32. El dispositivo acorde con cualquiera de las reivindicaciones 23 a 31, adaptado para transmitir, en respuesta a la determinación de que se ha producido un funcionamiento anómalo, el tercer valor de estado y los respectivos vectores de referencia asociados con el funcionamiento anómalo, por lo menos a otro dispositivo de procesamiento de datos predefinido (102, 103; 101, 103; 101, 102) .
33. Una red informática (10) con múltiples nodos de procesamiento de datos (101-103, 201, 202, 210) que están interconectados a efectos de comunicación de datos,
en la que por lo menos dos de dichos nodos de procesamiento de datos (101-103) están dispuestos como dispositivos de detección de anomalías, de acuerdo con cualquiera de las reivindicaciones 20 a 32.
34. La red informática acorde con la reivindicación 33, que comprende además un nodo central administrativo (210) adaptado para recibir señales de alarma desde dichos dispositivos de detección de anomalías (101-103) .
35. La red informática acorde con la reivindicación 33 ó 34, en la que dichos dispositivos de detección de anomalías (101-103) están adaptados para comunicar mediante comunicación entre pares.
36. La red informática acorde con la reivindicación 35, en la que cada uno de dichos dispositivos de detección de anomalías (101-103) está adaptado para funcionar como un nodo maestro para la comunicación entre pares, en la que dicho el nodo maestro está adaptado para proporcionar una lista de todos los dispositivos de detección de anomalías (101-103) que están conectados a la red informática (10) .
Patentes similares o relacionadas:
Procedimiento y dispositivo para el procesamiento de una solicitud de servicio, del 29 de Julio de 2020, de Advanced New Technologies Co., Ltd: Un procedimiento para el procesamiento de una solicitud de servicio, comprendiendo el procedimiento: recibir (S201), mediante un nodo de consenso, una solicitud […]
Método para un nivel mejorado de autenticación relacionado con una aplicación de cliente de software en un dispositivo informático de cliente que comprende una entidad de módulo de identidad de abonado con un kit de herramientas de módulo de identidad de abonado así como una miniaplicación de módulo de identidad de abonado, sistema, dispositivo informático de cliente y entidad de módulo de identidad de abonado para un nivel mejorado de autenticación relacionado con una aplicación de cliente de software en el dispositivo informático de cliente, programa que comprende un código de programa legible por ordenador y producto de programa informático, del 22 de Julio de 2020, de DEUTSCHE TELEKOM AG: Un método para un nivel mejorado de autenticación relacionado con una aplicación de cliente de software en un dispositivo informático […]
Método para atender solicitudes de acceso a información de ubicación, del 22 de Julio de 2020, de Nokia Technologies OY: Un aparato que comprende: al menos un procesador; y al menos una memoria que incluye un código de programa informático para uno o más programas, […]
Sincronización de una aplicación en un dispositivo auxiliar, del 22 de Julio de 2020, de OPENTV, INC.: Un método que comprende, mediante un dispositivo de medios: acceder, utilizando un módulo de recepción, un flujo de datos que incluye contenido […]
Procedimiento y dispositivo para su uso en la gestión de riesgos de información de aplicación, del 22 de Julio de 2020, de Advanced New Technologies Co., Ltd: Un procedimiento para la gestión de riesgos de información de aplicación en un dispositivo de red, comprendiendo el procedimiento: recibir información […]
Gestión de memoria intermedia recomendada de red de una aplicación de servicio en un dispositivo de radio, del 22 de Julio de 2020, de TELEFONAKTIEBOLAGET LM ERICSSON (PUBL): Un método llevado a cabo por un nodo de red en una red de comunicación por radio , comprendiendo el método: obtener (S1) una predicción del ancho […]
Método, servidor y sistema de inicio de sesión de confianza, del 22 de Julio de 2020, de Advanced New Technologies Co., Ltd: Un método de inicio de sesión de confianza implementado por computadora aplicado a un sistema de inicio de sesión de confianza que comprende un primer sistema de aplicación […]
Método y aparato para configurar un identificador de dispositivo móvil, del 22 de Julio de 2020, de Advanced New Technologies Co., Ltd: Un método implementado por servidor para configurar un identificador de dispositivo móvil, que comprende: obtener una lista de aplicaciones, APP, […]