Decodificador multimodo para señal de audio, codificador multimodo para señal de audio, procedimiento y programa de computación que usan un modelado de ruido en base a linealidad-predicción-codificación.
Un decodificador multimodo para señal de audio (1100; 1200) para proporcionar una representación decodificada (1112;
1212) de un contenido de audio sobre la base de una representación codificada (1110; 1208) del contenido de audio, en donde el decodificador para señal de audio comprende:
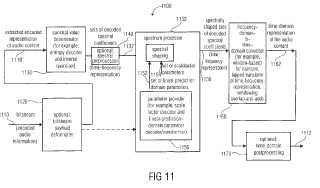
un determinador de valor espectral (1130; 1230a; 1230c) configurado para obtener conjuntos (1132; 1230d) de coeficientes espectrales decodificados (1132; 1230d; r[i]) para una pluralidad de porciones (1410, 1412, 1414, 1416) del contenido de audio; un procesador espectral (1230e; 1378) configurado para aplicar un modelado espectral de un conjunto (1132; 1230d; r[i]) de coeficientes espectrales decodificados, o a una versión pre-procesada (1132') del mismo, dependiendo de un conjunto de parámetros de dominio de predicción lineal para una porción del contenido de audio codificado en el modo de predicción lineal, y para aplicar un modelado espectral a un conjunto (1132; 1230d; r[i]) de coeficientes espectrales decodificados, o una versión pre-procesada (1232') del mismo, dependiendo de un conjunto de parámetros de factores de escala (1152; 1260b) para una porción (1410; 1416) del contenido de audio codificado en el modo de dominio de frecuencia, y
un convertidor de dominio de frecuencia a dominio de tiempo (1160; 1230g) configurado para obtener una representación de dominio de tiempo (1162; 1232; xi,n) del contenido de audio sobre la base de un conjunto modelado espectralmente (1158; 1230f) de coeficientes espectrales decodificados para una porción del contenido de audio codificado en el modo de predicción lineal, y para obtener una representación de dominio de tiempo (1162; 1232) del contenido de audio sobre la base de un conjunto modelado espectralmente de coeficientes espectrales decodificados para una porción del contenido de audio codificado en el modo de dominio de frecuencia.
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/EP2010/064917.
Solicitante: FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V..
Nacionalidad solicitante: Alemania.
Dirección: HANSASTRASSE 27C 80686 MUNCHEN ALEMANIA.
Inventor/es: HERRE, JURGEN, RETTELBACH,NIKOLAUS, NEUENDORF,Max, FUCHS,Guillaume, LECOMTE,Jérémie, BAECKSTROEM,TOM.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G10L19/02 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › G10L 19/00 Técnicas de análisis-síntesis de la voz o de señales de audio para la reducción de la redundancia, p. ej. en codificadores vocales; Codificación o decodificación de la voz o de señales de audio, utilizando modelos filtro-fuente o el análisis psicoacústico (en instrumentos musicales G10H). › utilizando análisis espectrales, p. ej. codificadores vocales de transformación o codificadores vocales subbanda.
- G10L19/14
PDF original: ES-2441069_T3.pdf
Fragmento de la descripción:
Decodificador multimodo para señal de audio, codificador multimodo para señal de audio, procedimiento y programa de computación que usan un modelado de ruido en base a linealidad–predicción–codificación.
Campo Técnico [0001] Las formas de realización de acuerdo con la presente invención se relacionan con un decodificador multimodo para señal de audio para proporcionar una representación decodificada de un contenido de audio sobre la base de una representación codificada del contenido de audio.
Otras formas de realización de acuerdo con la invención se relacionan con un codificador multimodo para señal de audio para proporcionar una representación codificada de un contenido de audio sobre la base de una representación de entrada del contenido de audio.
Otras formas de realización de acuerdo con la invención se relacionan con un procedimiento para proporcionar una representación decodificada de un contenido de audio sobre la base de una representación codificada del contenido de audio.
Otras formas de realización de acuerdo con la invención se relacionan con un procedimiento para proporcionar una representación codificada de un contenido de audio sobre la base de una representación de entrada del contenido de audio.
Otras formas de realización de acuerdo con la invención se relacionan con programas de computación que implementan dichos procedimientos.
Antecedentes de la Invención [0006] A continuación se explicarán algunos antecedentes de la invención con el fin de facilitar la comprensión de la invención y las ventajas de la misma.
Durante la última década se ha realizado un gran esfuerzo para crear la posibilidad de almacenar y distribuir digitalmente contenidos de audio. Un logro importante en este sentido es la definición de la norma internacional ISO (Organización Internacional de Normas) /IEC (Comisión Internacional de Electrotecnia) 14496–3. La parte 3 de esta norma está relacionada con una codificación y decodificación de contenidos de audio y la sub–parte 4 de la parte 3 está relacionada con la codificación de audio en general. La parte 3, sub–parte 4 de la norma ISO/IEC 14496 define un concepto para la codificación y decodificación de contenido de audio en general. Asimismo, otras mejoras han sido propuestas con el fin de mejorar la calidad y/o reducir la velocidad de transmisión de bits necesarios.
Por otra parte, se ha comprobado que el rendimiento de los codificadores de audio basados en el dominio de frecuencia no es óptimo para los contenidos de audio que comprenden lenguaje. Recientemente se ha propuesto un codificador–decodificador (codec) unificado de voz–y–audio que combina eficazmente las técnicas de ambos mundos, es decir, la codificación de voz y la codificación de audio (véase, por ejemplo, la Referencia [1]) .
En un codificador de audio de tales características, algunos cuadros de audio están codificados en el dominio de frecuencia y algunos cuadros de audio están codificados en el dominio de predicción lineal.
Sin embargo, se ha descubierto que es difícil hacer la transición entre los cuadros codificados en distintos dominios sin sacrificar una cantidad significativa de velocidad de transmisión de bits.
En vista de esta situación, hay un deseo de crear un concepto para codificar y decodificar un contenido de audio que comprende tanto voz como audio en general, lo que permite una realización eficaz de transiciones entre las porciones codificados utilizando diferentes modos.
Otro ejemplo de un codificador/descodificador (codec) de habla y de audio unificado conocido (USAC) se describe en LECOMTE Y OTROS: "Efficient Cross-Fade Windows for Transitions between LPC-Based and Non-LPC Based Audio Coding", CONVENCIÓN AES 126; MAYO DE 2009, AES, 60 EAST 42ND STREET, ROOM 2520 NEW YORK , USA, 1 de Mayo de 2009, XP040508994, en el que la conmutación sin costuras entre diferentes codecs de núcleo se logra utilizando ventanas de fundido cruzado adecuadamente diseñadas.
Resumen de la Invención [0013] Una forma de realización de acuerdo con la invención crea un decodificador multimodo para señal de audio para proporcionar una representación decodificada de un contenido de audio sobre la base de una representación codificada del contenido de audio. El decodificador para señal de audio cuenta con un determinador de valor espectral configurado para obtener conjuntos de coeficientes espectrales decodificados para una pluralidad de porciones del contenido de audio. El decodificador multimodo para señal de audio también incluye un procesador de espectro configurado para aplicar un modelado espectral a un conjunto de coeficientes espectrales decodificados, o a una versión pre–procesada del mismo, dependiendo de un conjunto de parámetros de dominio de predicción lineal para una porción del contenido de audio codificado en un modo de predicción lineal, y para aplicar un modelado espectral a un conjunto de coeficientes espectrales decodificados, o a una versión pre–procesada del mismo, independiente de un conjunto de parámetros de factores de escala para una porción del contenido de audio codificado en un modo de dominio de frecuencia. El decodificador multimodo para señal de audio también comprende un convertidor de dominio de frecuencia a dominio del tiempo configurado para obtener una representación de dominio de tiempo del contenido de audio sobre la base de un conjunto modelado espectralmente de coeficientes espectrales decodificados para una porción del contenido de audio codificado en el modo de predicción lineal, y también para obtener una representación de dominio de tiempo del contenido de audio sobre la base de un conjunto modelado espectralmente de coeficientes espectrales decodificados para una porción del contenido de audio codificado en el modo de dominio de frecuencia.
Dicho decodificador multimodo para señal de audio se basa en la constatación de que se pueden obtener transiciones eficaces entre las porciones del contenido de audio codificado en diferentes modos llevando a cabo un modelado espectral en el dominio de frecuencia, es decir, un modelado espectral de conjuntos de coeficientes espectrales decodificados, tanto para porciones de contenido de audio codificado en el modo de dominio de frecuencia como para porciones de contenido de audio codificado en el modo de predicción lineal. Por lo tanto, una representación de dominio de tiempo obtenida sobre la base de un conjunto modelado espectralmente de coeficientes espectrales decodificados para porción del contenido de audio codificado en el modo de predicción lineal está “en el mismo dominio” (por ejemplo, son valores de salida de transformaciones de dominio de frecuencia a dominio de tiempo del mismo tipo de transformación) como una representación de dominio de tiempo obtenida sobre la base de un conjunto modelado espectralmente de coeficientes espectrales decodificados para una porción del contenido de audio codificado en el modo de dominio de frecuencia. De este modo, las representaciones de dominio de tiempo de una porción del contenido de audio codificado en el modo de predicción lineal y de una porción del contenido de audio codificado en el modo de dominio de frecuencia se pueden combinar de manera eficiente y sin artefactos inaceptables. Por ejemplo, las características de cancelación de solapamiento de los convertidores típicos de dominio de frecuencia a dominio de tiempo pueden ser aprovechadas por las señales de conversión de dominio de frecuencia a dominio de tiempo que están en el mismo dominio (por ejemplo, ambos representan un contenido de audio en un dominio de contenido de audio) . Por lo tanto se pueden obtener transiciones de buena calidad entre las porciones del contenido de audio codificado en diferentes modos sin necesidad de una cantidad sustancial de tasa de bits para permitir tales transiciones.
En una realización preferida, el decodificador multimodo para señal de audio comprende además un solapador configurado para solapar y agregar una representación de dominio de tiempo de una porción del contenido de audio codificado en el modo de predicción lineal con una porción del contenido de audio codificado en el modo de dominio de frecuencia. Mediante la superposición de porciones del contenido de audio codificado en diferentes dominios se puede obtener la ventaja lograda mediante la introducción de conjuntos modelados espectralmente de coeficientes espectrales decodificados en el convertidor de dominio de frecuencia a dominio de tiempo en ambos modos del decodificador multimodo para señal de audio. Al llevar a cabo el modelado espectral antes de la conversión de dominio de frecuencia a dominio de tiempo... [Seguir leyendo]
Reivindicaciones:
1. Un decodificador multimodo para señal de audio (1100; 1200) para proporcionar una representación decodificada (1112; 1212) de un contenido de audio sobre la base de una representación codificada (1110; 1208) del contenido de audio, en donde el decodificador para señal de audio comprende:
un determinador de valor espectral (1130; 1230a; 1230c) configurado para obtener conjuntos (1132; 1230d) de coeficientes espectrales decodificados (1132; 1230d; r[i]) para una pluralidad de porciones (1410, 1412, 1414, 1416) del contenido de audio; un procesador espectral (1230e; 1378) configurado para aplicar un modelado espectral de un conjunto (1132; 1230d; r[i]) de coeficientes espectrales decodificados, o a una versión pre–procesada (1132') del mismo, dependiendo de un conjunto de parámetros de dominio de predicción lineal para una porción del contenido de audio codificado en el modo de predicción lineal, y para aplicar un modelado espectral a un conjunto (1132; 1230d; r[i]) de coeficientes espectrales decodificados, o una versión pre–procesada (1232') del mismo, dependiendo de un conjunto de parámetros de factores de escala (1152; 1260b) para una porción (1410; 1416) del contenido de audio codificado en el modo de dominio de frecuencia, y un convertidor de dominio de frecuencia a dominio de tiempo (1160; 1230g) configurado para obtener una representación de dominio de tiempo (1162; 1232; xi, n) del contenido de audio sobre la base de un conjunto modelado espectralmente (1158; 1230f) de coeficientes espectrales decodificados para una porción del contenido de audio codificado en el modo de predicción lineal, y para obtener una representación de dominio de tiempo (1162; 1232) del contenido de audio sobre la base de un conjunto modelado espectralmente de coeficientes espectrales decodificados para una porción del contenido de audio codificado en el modo de dominio de frecuencia.
2. El decodificador multimodo para señal de audio de acuerdo con la reivindicación 1, en donde el decodificador multimodo para señal de audio comprende además un solapador (1233) configurado para solapar y agregar una representación de dominio de tiempo de una porción del contenido de audio codificado en el modo de predicción lineal con una porción del contenido de audio codificado en el modo de dominio de frecuencia.
3. El decodificador multimodo para señal de audio de acuerdo con la reivindicación 2, en donde el convertidor de dominio de frecuencia a dominio de tiempo (1160; 1230g) está configurado para obtener una representación de dominio de tiempo del contenido de audio para una porción (1412; 1414) del contenido de audio codificado en el modo de predicción lineal utilizando una transformación solapada, y para obtener una representación de dominio de tiempo del contenido de audio para una porción (1410; 1416) del contenido de audio codificado en el modo de dominio de frecuencia utilizando una transformación solapada, y en donde el solapador está configurado para solapar las representaciones de dominio de tiempo de las porciones posteriores del contenido de audio codificado en diferentes modos.
4. El decodificador multimodo para señal de audio de acuerdo con la reivindicación 3, en donde el convertidor de dominio de frecuencia a dominio de tiempo (1160; 1230g) está configurado para aplicar transformaciones solapadas del mismo tipo de transformación para obtener representaciones de dominio de tiempo del contenido de audio para porciones del contenido de audio codificado en diferentes modos y en donde el solapador está configurado para solapar y agregar las representaciones de dominio de tiempo de las porciones posteriores del contenido de audio codificado en diferentes modos de manera tal que se reduce o elimina un solapamiento de dominio de tiempo causado por la transformación solapada.
5. El decodificador multimodo para señal de audio de acuerdo con la reivindicación 4, en donde el solapador está configurado para solapar y agregar una representación de dominio de tiempo dividida en ventanas de una primera porción (1414) del contenido de audio codificado en un primero de los modos proporcionados por una transformación solapada asociada, o una versión ajustada a escala de amplitud pero espectralmente no distorsionada del mismo, y una representación de dominio de tiempo dividida en ventanas de una segunda porción posterior (1416) del contenido de audio codificado en un segundo de los modos, proporcionados por una transformación solapada asociada, o una versión ajustada a escala de amplitud pero espectralmente no distorsionada del mismo.
6. El decodificador multimodo para señal de audio de acuerdo con una de las reivindicaciones 1 a 5, en donde el convertidor de dominio de frecuencia a dominio de tiempo (1160; 1230g) está configurado para proporcionar representaciones de dominio de tiempo de las porciones (1410, 1412, 1414, 1416) del contenido de audio codificado en diferentes modos de manera tal que las representaciones de dominio de tiempo proporcionadas se encuentran en un mismo dominio, ya que son linealmente combinables sin aplicar una operación de filtrado de modelado de señales, a excepción de una operación de transición dividida en ventanas, a una o ambas representaciones de dominio de tiempo proporcionadas.
7. El decodificador multimodo para señal de audio de acuerdo con una de las reivindicaciones 1 a 6, en donde el convertidor de dominio de frecuencia a dominio de tiempo (1160; 1230g) está configurado para llevar a cabo una transformada inversa coseno discreta modificada, para obtener, como resultado de la transformada inversa coseno
discreta modificada, una representación de dominio de tiempo del contenido de audio en un dominio de señal de audio tanto para una porción del contenido de audio codificado en el modo de predicción lineal como para una porción del contenido de audio codificado en el modo de dominio de frecuencia.
8. El decodificador multimodo para señal de audio de acuerdo con una de las reivindicaciones 1 a 7, que comprende:
un determinador de coeficientes de filtro de codificación de predicción lineal configurado para obtener coeficientes de filtro decodificados de codificación de predicción lineal (α1 a α16) sobre la base de una representación codificada de los coeficientes de filtro de codificación de predicción lineal para una porción del contenido de audio codificado en el modo de predicción lineal; un transformador de coeficientes del filtro (1260e) configurado para transformar los coeficientes decodificado de codificación de predicción lineal (1260d; α1 a α16) en una representación espectral (1260f; X0[k]) , con el fin de obtener los valores de ganancia del modo de predicción lineal (g[k]) asociados con diferentes frecuencias; un determinador de factores de escala (1260a) configurado para obtener valores decodificados de factores de escala (1260f) sobre la base de una representación codificada (1254) de los valores de factores de escala para una porción del contenido de audio codificado en un modo de dominio de frecuencia; en donde el procesador espectral (1150; 1230e) comprende un modificador espectral configurado para combinar un conjunto (1132; 1230d; r[i]) de coeficientes espectrales decodificados asociados a una porción del contenido de audio codificado en el modo de predicción lineal, o una versión pre–procesada del mismo, con los valores de ganancia del modo de predicción lineal (g[k]) , con el fin de obtener una versión procesada de ganancias (1158; 1230f; rr[i]) de los coeficientes espectrales decodificados, en los que las contribuciones de los coeficientes espectrales decodificados (1130; 1230d; r[i]) , o de la versión pre– procesada del mismo, se ponderan dependiendo de los valores de ganancia del modo de predicción lineal (g[k]) , y que también está configurado para combinar un conjunto (1132; 1230d; x_ac_invquant) de coeficientes espectrales decodificados asociados a una porción del contenido de audio codificado en el modo de dominio de frecuencia, o una versión pre–procesada del mismo, con los valores de factores de escala (1260b) , con el fin de obtener una versión procesada a factores de escala (x_rescal) de los coeficientes espectrales decodificados (x_ac_invquant) en los que las contribuciones de los coeficientes espectrales decodificados, o de la versión pre–procesada del mismo, se ponderan dependiendo de los valores de factores de escala.
9. El decodificador multimodo para señal de audio de acuerdo con la reivindicación 8, en donde el transformador de coeficientes de filtro (1260e) está configurado para transformar los coeficientes de filtro decodificados de codificación de predicción lineal (1260d) , que representan una respuesta al impulso de dominio de tiempo ( W[n]) de un filtro de codificación de predicción lineal, en una representación espectral (X0[k]) utilizando una transformada discreta impar de Fourier; y en donde el transformador de coeficientes de filtro (1260e) está configurado para obtener los valores de ganancia del modo de predicción lineal (g[k]) a partir de la representación espectral (X0[k]) de los coeficientes de filtro decodificados de codificación de predicción lineal (1260d; a1 a a16) , de manera tal que los valores de ganancia dependen de las magnitudes de los coeficientes (X0[k]) de la representación espectral (X0[k]) .
10. El decodificador multimodo para señal de audio de acuerdo con la reivindicación 8 o con la reivindicación 9, en donde el transformador de coeficientes de filtro (1260e) y el combinador (1230e) están configurados de manera tal que una contribución de un determinado coeficiente espectral decodificado (r[i]) , o de una versión pre–procesada del mismo, a una versión de ganancia pre–procesada (rr[i]) del coeficiente espectral determinado está determinado por una magnitud de un valor de ganancia del modo de predicción lineal (g[k]) asociados con el coeficiente espectral decodificado determinado (r[i]) .
11. El decodificador multimodo para señal de audio de acuerdo con una de las reivindicaciones 1 a 9, en donde el procesador espectral (1230e) está configurado de manera tal que una ponderación de una contribución de un determinado coeficiente espectral decodificado (r[i]) , o de una versión pre–procesada del mismo, a una versión procesada de ganancia (rr[i]) del coeficiente espectral determinado aumenta al aumentar la magnitud de un valor del ganancia del modo de predicción lineal (g[k]) asociado con el coeficiente espectral decodificado determinado (r
Patentes similares o relacionadas:
Decodificación de audio estéreo paramétrico, del 9 de Enero de 2019, de DOLBY INTERNATIONAL AB: Receptor, que comprende: un demultiplexor para desmultiplexar un flujo de bits para obtener una señal mono y parámetros de amplitud estéreo; […]
Receptor y método para decodificar flujo de datos codificado estéreofónico paramétrico, del 20 de Septiembre de 2017, de DOLBY INTERNATIONAL AB: Receptor, que comprende: un demultiplexor configurado para extraer una señal monofónica codificada y parámetros de amplitud estereofónica […]
Método de codificación, método de descodificación, codificador, descodificador, programa y medio de grabación, del 29 de Marzo de 2017, de NIPPON TELEGRAPH AND TELEPHONE CORPORATION: Un método de codificación de voz o de señales acústicas que comprende adquirir códigos correspondientes a residuos de predicción obtenidos según […]
Dispositivo de codificación de sonido y procedimiento de codificación de sonido, del 25 de Enero de 2017, de III Holdings 12, LLC: Un aparato de codificación de voz que comprende: una sección de análisis de parámetro de predicción que calcula una diferencia de retardo y una relación […]
 Codificador y decodificador de audio para codificar tramas de señales de audio muestreadas, del 2 de Febrero de 2016, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un codificador de audio adaptado para codificar tramas de una señal de audio muestreada para obtener tramas codificadas, en el que una […]
Codificador y decodificador de audio para codificar tramas de señales de audio muestreadas, del 2 de Febrero de 2016, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un codificador de audio adaptado para codificar tramas de una señal de audio muestreada para obtener tramas codificadas, en el que una […]
Codificador y descodificador de audio para codificar y descodificar muestras de audio, del 6 de Enero de 2016, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un codificador de audio para codificar muestras de audio, que comprende: un primer codificador de introducción de distorsión por repliegue del espectro […]
Códec de audio sin pérdidas escalable y herramienta de autoría, del 6 de Mayo de 2015, de DTS, INC: Un método para codificar un flujo de bits sin pérdidas escalable para muestras de audio de PCM de M-bits para decodificar mediante un decodificador sin […]
Codificador de extensión de ancho de banda, descodificador de extensión de ancho de banda y vocoder de fase, así como métodos correspondientes y programa de computadora, del 25 de Marzo de 2015, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un codificador de extensión de ancho de banda para codificar una señal de audio , la señal de audio que comprende una señal […]