Método y aparato para recuperar información importante.
Un método para recuperar de un conjunto de documentos electrónicos aquéllos que están próximos en contenidocon un documento electrónico usado como documento de entrada,
comprendiendo dicho método:
A) proporcionar un conjunto de documentos (D1,...DN);
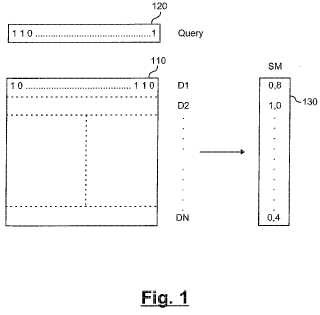
B) generar unos vectores de características de secuencias de bits (110) para los documentos de dicho conjunto,en los que cada vector de características representa uno respectivo de dichos documentos e indica con cadauno de sus componentes vectoriales binarios la presencia o la ausencia de una cierta característica dentrodel respectivo documento;
C) formar una matriz de atributos binaria (100; 800) a partir de los vectores de características (110) de lasecuencia de bits, constando la matriz de atributos binarias de unos bits individuales y representando cadabit un cierto atributo de un cierto documento indicando la presencia o ausencia de una cierta característicadentro del respectivo documento;
D) proporcionar un documento de entrada (200; 400; 700; 820);
E) generar una pluralidad de fragmentos (S1, S2, S3; 410, 420, 430, 440, 450, 460, 470, 480; 710, 720, 730) dedicho documento de entrada (200; 400; 700; 820) que son partes de dicho documento de entrada;
F) generar para cada uno de dichos fragmentos un respectivo vector de características (F1; F2; F3) de lasecuencia de bits de consulta que representa el respectivo fragmento y que indica con cada uno de suscomponentes de vector binarios la presencia o ausencia de una cierta característica dentro del respectivofragmento;
G) efectuar una búsqueda asociativa para cada uno de dichos fragmentos usando dicha matriz de atributosbinaria y el respectivo vector de características (F1; F2; F3) de la secuencia de bits de consulta querepresenta el respectivo fragmento; en el que la búsqueda asociativa de un respectivo fragmento se efectúadeterminando para el fragmento y para cada documento de dicho conjunto una medida de similitud individualentre dicho fragmento y el respectivo documento de dicho conjunto; en el que la respectiva medida desimilitud individual se determina efectuando una operación lógica con bits entre el vector de característicasde secuencias de bits que representa el respectivo fragmento y la secuencia de bits que representa elrespectivo documento en dicha matriz de atributos binaria; en el que dichas medidas de similitudindividuales, estando cada una determinada para un determinado fragmento y un respectivo documento de30 dicho conjunto y que representa una similitud entre dicho fragmento particular y dicho documento respectivode dicho conjunto, son componentes vectoriales de un vector de medida de similitud (SM1; SM2; SM3)asociados con los respectivos fragmentos particulares y con todos los documentos de dicho conjunto dedocumentos;
H) para cada uno de dichos documentos de dicho conjunto se calcula una medida final de similitud individual apartir de las medidas de similitud individuales, las cuales de acuerdo con el paso G) se determinan para elmismo documento respectivo con relación a dichos fragmentos, siendo dichas medidas finales de similitudcomponentes vectoriales de un vector (FSM) de medida final de similitud, el cual se obtiene con él sobre labase de dichos vectores de medida de similitud (SM1, SM2, SM3);
I) juzgar, sobre la base de dichas medidas finales individuales de similitud incluidas como componentesvectoriales en dicho vector (FSM) de medida final de similitud pudiéndose los documentos de dicho conjuntoser considerados como que tienen un contenido próximo al de dicho documento de entrada;
en el que dichos fragmentos (S1, S2, S3; 410, 420, 430, 440, 450, 460, 470, 480; 710, 720, 730) son generadossegmentando dicho documento de entrada (200; 400; 700; 820) en segmentos, en donde de dichos segmentos losdel primero al segundo últimos tienen un tamaño dado, y el último segmento tiene un tamaño dado o es más cortoque el tamaño dado;
en el que los fragmentos del documento de entrada (450, 460, 470, 480; 720, 730) son generados pordesplazamiento de uno o más fragmentos de dicho documento de entrada para generar unos fragmentos solapados(410, 420, 430, 440, 450, 460, 470, 480; 710, 720, 730) de dicho documento de entrada (400; 700) para cuyosvectores de características de secuencia de datos son generados y usados en dicha búsqueda asociativa.
Tipo: Patente Europea. Resumen de patente/invención. Número de Solicitud: E01127768.
Solicitante: VOEGELI, WERNER.
Nacionalidad solicitante: Suiza.
Dirección: QUELENSTRASSE 62 5330 ZURZACH SUIZA.
Inventor/es: VOEGELI,WERNER.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G06F17/30
PDF original: ES-2391261_T3.pdf
Fragmento de la descripción:
Método y aparato para recuperar información importante.
El presente invento se refiere a un método para la recuperación de un conjunto de documentos electrónicos los que tienen un contenido relacionado con un documento electrónico usado como documento de entrada.
En la actualidad las personas se enfrentan a una cantidad siempre creciente de información. La cantidad de información producida en un solo día es tan grande que a una persona, incluso leyendo las 24 horas del día durante toda su vida, le sería imposible leer lo producido en un solo día.
Está claro que la información se produce a un ritmo tan rápido que de algún modo ha de ser tratada electrónicamente. El modo más convencional de tratar, almacenar, archivar y recuperar grandes cantidades de información son las denominadas bases de datos.
Las bases de datos almacenan fragmentos de información individuales ordenados de una manera denominada “indexación”.
La indexación significa que cada fragmento de información está etiquetada con al menos una etiqueta, siendo un tipo de “meta” información que describe algunos aspectos del contenido del fragmento de información que realmente ha sido almacenado.
Un ejemplo muy simple es un registro de dirección que puede comprender el apellido, el nombre dado, el nombre de la calle, código postal, y el nombre de una ciudad. Un campo de índice podría entonces, por ejemplo, ser el apellido que describe un aspecto del registro total de la dirección.
Suponiendo que se hayan almacenado muchas direcciones, entonces cada una tiene una etiqueta que contiene un apellido, y esas etiquetas podrían entonces ser ordenadas automáticamente y podrían ser usadas para acceder de una forma rápida a cada uno de los registros de direcciones, como es bien conocido en la técnica de la tecnología de las bases de datos.
Este método es muy rápido para acceder a cada uno de los registros de direcciones (que se denominan conjuntos de datos en la terminología de la base de datos) , aunque tiene la desventaja de que solamente pueden ser buscados para su recuperación los fragmentos o tipos de información de los que se ha creado un índice. Esto significa que la información de acceso almacenada mediante índices no necesariamente dan al usuario una imagen total de todos los aspectos de la información que ha sido almacenada, debido a que solamente se abren para un usuario aquellos aspectos para los cuales ha sido creado un índice para ser usado como criterio de búsqueda.
Un enfoque completamente diferente es el almacenamiento y el acceso a información simulando una memoria denominada asociativa. De acuerdo con este enfoque cada documento de un conjunto de documentos es representado mediante un denominado “vector de características” el cual, de hecho, es una secuencia de bits. Cada bit de la secuencia de bits solicita la presencia o la ausencia de una cierta característica en el documento que representa.
Las características pueden, por ejemplo, ser la presencia o ausencia de ciertos unigramas, digramas, trigramas, o similares.
Cada documento almacenado es después representado mediante una secuencia de bits en la que cada bit individual indica si una cierta característica está presente o ausente en su correspondiente documento. El acceso a y la recuperación de los documentos así almacenados es después realizada mediante la introducción de un documento de consulta. Este documento de consulta después es también representado mediante una secuencia de bits que es generada de acuerdo con las mismas reglas que las secuencias de bits que representan el documento ya almacenado, es decir para generar un vector de características de consulta.
Después de haber realizado esto se realiza una operación lógica en términos de bits entre la secuencia de bits de consulta y las secuencias de bits que representan los documentos ya almacenados, por ejemplo una lógica AND en términos de bits entre la consulta y cada uno de los vectores de documentos almacenados. Basado en esta operación en términos de bits se ha formado algún tipo de medida de similitud entre la secuencia de bits de consulta y la secuencia de bits que representa uno respectivo de los documentos que forman la base de datos. Las características que están presentes en la consulta y en el documento almacenado dan un “1” lógico como resultado de la operación AND, cuantas más características están presentes en la consulta, y en el documento almacenado resultan más “1” lógicos AND de la operación. Como ejemplo, el número de “1” lógicos puede ser contemplado como una medida de similitud entre una secuencia de bits de consulta y la secuencia de bits (vector de características) de un documento almacenado. Las medidas de similitud (individuales) obtenidas de este modo para los diferentes documentos del conjunto pueden ser consideradas como componentes del vector de un vector de medida de la similitud.
Basado en el vector de medida de similitud que indica la similitud entre el documento de consulta y los documentos individuales almacenados en la base de datos se puede recuperar el documento más similar de la base de datos, que con respecto a las características codificadas en la secuencia de bits está más próximo al documento de consulta.
Con tal acceso asociativo resulta posible introducir cualquier consulta arbitraria en una base de datos y encontrar aquellos documentos que son más similares al documento de la consulta de entrada. Una de las posibilidades de tal búsqueda asociativa es que los documentos que son considerados como “similares” basada en una evaluación de los vectores de características realmente son similares en su contenido a la consulta de entrada. Esto significa que tal búsqueda asociativa puede realizar correctamente un acceso “asociativo” verdadero que es muy similar al que realiza el cerebro humano.
Por ejemplo, si uno lee un cierto libro sobre un tema determinado entonces un ser humano tiene automáticamente muchas asociaciones, a su mente vienen libros relacionados con los mismos o similares temas, sucesos y experiencias unidos a estos temas. Suponiendo que están todos representados mediante vectores de características en una base de datos, entonces uno podría realizar una consulta, basada por ejemplo en un libro que el usuario está leyendo en ese momento, después tal búsqueda asociativa electrónica sería capaz de producir unas asociaciones similares a las del cerebro humano, es decir se podrían recuperar libros y documentos similares, y –caso de estar almacenados y codificados- experiencias o sucesos.
Tal método de búsqueda asociativa o “Método de acceso asociativo (ASSA) ” es por ejemplo conocido por Berkovich, S., El-Qawasmeh, E., Lapir, G.: “Organización de coincidencia próxima en una matriz de atributos aplicada a métodos de acceso asociativos en la recuperación de información”, Actas de la 16ª Conferencia Internacional de Informática Aplicada, 23. – 25.02.1998, Garmisch Partenkirchen, Alemania.
Correspondiendo, pero una exposición en algún modo más detallada, se conoce también de Lapir, G. M.: “Uso de un método de acceso asociativo para sistemas de recuperación de información” Actas de la 23ª Conferencia de Pittsburgh sobre modelización y simulación, 1992, páginas 951-958, XP009099840.
En consecuencia, se conoce un método para la recuperación de un conjunto de documentos electrónicos aquellos documentos que son próximos en contenido de un documento electrónico usado como un documento de entrada, el cual comprende:
- proporcionar un conjunto de documentos;
- generar unos vectores de característica de secuencias de bits para los documentos de dicho conjunto, en donde cada vector de características representa uno respectivo de dichos documentos e indica con cada uno de sus componentes vectoriales binarios la presencia o ausencia de una cierta característica dentro del respectivo documento;
- formar una matriz de atributos binaria a partir de los vectores de características de la secuencia de bits, constando la matriz de atributos binaria de bits individuales y representando cada bit un cierto atributo de un cierto documento mediante la indicación de la presencia o ausencia de una cierta característica dentro del respectivo documento;
-... [Seguir leyendo]
Reivindicaciones:
1. Un método para recuperar de un conjunto de documentos electrónicos aquéllos que están próximos en contenido con un documento electrónico usado como documento de entrada, comprendiendo dicho método:
A) proporcionar un conjunto de documentos (D1, ...DN) ;
B) generar unos vectores de características de secuencias de bits (110) para los documentos de dicho conjunto, en los que cada vector de características representa uno respectivo de dichos documentos e indica con cada uno de sus componentes vectoriales binarios la presencia o la ausencia de una cierta característica dentro del respectivo documento;
C) formar una matriz de atributos binaria (100; 800) a partir de los vectores de características (110) de la secuencia de bits, constando la matriz de atributos binarias de unos bits individuales y representando cada bit un cierto atributo de un cierto documento indicando la presencia o ausencia de una cierta característica dentro del respectivo documento;
D) proporcionar un documento de entrada (200; 400; 700; 820) ;
E) generar una pluralidad de fragmentos (S1, S2, S3; 410, 420, 430, 440, 450, 460, 470, 480; 710, 720, 730) de dicho documento de entrada (200; 400; 700; 820) que son partes de dicho documento de entrada;
F) generar para cada uno de dichos fragmentos un respectivo vector de características (F1; F2; F3) de la secuencia de bits de consulta que representa el respectivo fragmento y que indica con cada uno de sus componentes de vector binarios la presencia o ausencia de una cierta característica dentro del respectivo fragmento;
G) efectuar una búsqueda asociativa para cada uno de dichos fragmentos usando dicha matriz de atributos binaria y el respectivo vector de características (F1; F2; F3) de la secuencia de bits de consulta que representa el respectivo fragmento; en el que la búsqueda asociativa de un respectivo fragmento se efectúa determinando para el fragmento y para cada documento de dicho conjunto una medida de similitud individual entre dicho fragmento y el respectivo documento de dicho conjunto; en el que la respectiva medida de similitud individual se determina efectuando una operación lógica con bits entre el vector de características de secuencias de bits que representa el respectivo fragmento y la secuencia de bits que representa el respectivo documento en dicha matriz de atributos binaria; en el que dichas medidas de similitud individuales, estando cada una determinada para un determinado fragmento y un respectivo documento de dicho conjunto y que representa una similitud entre dicho fragmento particular y dicho documento respectivo de dicho conjunto, son componentes vectoriales de un vector de medida de similitud (SM1; SM2; SM3) asociados con los respectivos fragmentos particulares y con todos los documentos de dicho conjunto de documentos;
H) para cada uno de dichos documentos de dicho conjunto se calcula una medida final de similitud individual a partir de las medidas de similitud individuales, las cuales de acuerdo con el paso G) se determinan para el mismo documento respectivo con relación a dichos fragmentos, siendo dichas medidas finales de similitud componentes vectoriales de un vector (FSM) de medida final de similitud, el cual se obtiene con él sobre la base de dichos vectores de medida de similitud (SM1, SM2, SM3) ;
I) juzgar, sobre la base de dichas medidas finales individuales de similitud incluidas como componentes vectoriales en dicho vector (FSM) de medida final de similitud pudiéndose los documentos de dicho conjunto ser considerados como que tienen un contenido próximo al de dicho documento de entrada;
en el que dichos fragmentos (S1, S2, S3; 410, 420, 430, 440, 450, 460, 470, 480; 710, 720, 730) son generados segmentando dicho documento de entrada (200; 400; 700; 820) en segmentos, en donde de dichos segmentos los del primero al segundo últimos tienen un tamaño dado, y el último segmento tiene un tamaño dado o es más corto que el tamaño dado;
en el que los fragmentos del documento de entrada (450, 460, 470, 480; 720, 730) son generados por desplazamiento de uno o más fragmentos de dicho documento de entrada para generar unos fragmentos solapados (410, 420, 430, 440, 450, 460, 470, 480; 710, 720, 730) de dicho documento de entrada (400; 700) para cuyos vectores de características de secuencia de datos son generados y usados en dicha búsqueda asociativa.
2. El método de la reivindicación 1, en el que dicho solape entre dichos fragmentos de solapamiento es un solape en unidades de uno de los siguientes:
caracteres; sílabas;
fonemas;
palabras.
3. El método de una de las anteriores reivindicaciones, en el que dicho documento de entrada se obtiene a partir de la realización de un proceso de reconocimiento de voz sobre un texto hablado por una voz humana.
4. El método de una de las anteriores reivindicaciones, en el que cada uno de dichos documentos (D1, ..., DN) de dicho conjunto es clasificado como que pertenece a una de una pluralidad de clases (810) , comprendiendo además dicho método:
realizar dicha búsqueda asociativa,
basado en el número de documentos similares al documento de entrada (820) que ha sido encontrado en las clases individuales, que clasifican dicho documento de entrada como perteneciente a una de dichas clases.
5. El método de la reivindicación 4, en el que el número de clases es dos, una de un conjunto importante de documentos y otra de un conjunto no importante de documentos;
se restituyen los resultados de la recuperación a partir de dicha búsqueda asociativa a un usuario solamente si dicho documento de entrada ha sido clasificado como perteneciente a dicha clase importante.
6. El método de una de las anteriores reivindicaciones, que además comprende:
optimizar los parámetros de dicho método como el tamaño del fragmento y el número de elementos de solape basado en un esquema de clasificación dado, comprendiendo dicha optimización:
a) usar los documentos de dicho esquema de clasificación de los que su clasificación es ya conocida;
b) clasificarlos de acuerdo con la reivindicación 6;
c) variar dichos parámetros y repetir los pasos a) y b) ; repitiendo el paso c) hasta haber encontrado un conjunto óptimo de parámetros.
7. El método de una de las anteriores reivindicaciones, en el que los datos de entrada de voz están representados por fonemas para proporcionar dicho documento de entrada, y dichos documentos de dicho conjunto, para los cuales se generan dichos vectores de características de la secuencia de datos, contienen los datos del fonema;
o se usan unos datos de entrada escritos, y dichos documentos de dicho conjunto, para los que se generan dichos vectores de características de la secuencia de datos, contienen unos datos escritos con caracteres;
o se convierten los datos de entrada escritos en datos de fonemas para proporcionar dicho documento de entrada, y dichos documentos de dicho conjunto, para los que se generan dichos vectores de características de la secuencia de datos, contienen datos de fonemas.
8. El método de acuerdo con una de las anteriores reivindicaciones, en el que de acuerdo con el paso H) se calcula la respectiva medida final de similitud a partir de dichas medidas de similitud individuales usando una función de ponderación que da un peso más alto a unas medidas de similitud individuales que indican una similitud más alta entre el respectivo fragmento y un respectivo documento de dicho conjunto y que da un peso más bajo a unas medidas de similitud individuales que indican una similitud más baja entre el respectivo fragmento y un documento respectivo de dicho conjunto.
9. El método de acuerdo con una de las anteriores reivindicaciones, en el que dicha operación lógica en términos de bits es una operación lógica AND en términos de bits.
10. El método de acuerdo con la reivindicación 9, en el que las características presentes están representadas por un “1” lógico y el número de “1” lógicos que resulta de la operación lógica AND en términos de bits se usa como medida de similitud individual.
Patentes similares o relacionadas:
Composiciones y métodos para modelar el metabolismo de Saccharomyces cerevisiae, del 3 de Junio de 2020, de THE REGENTS OF THE UNIVERSITY OF CALIFORNIA: Un metodo implementado por computadora para proporcionar a un usuario una simulacion de una funcion fisiologica de levadura relacionada con un gen heterologo […]
Procedimiento de visualización de páginas por medio de un navegador de un equipo como una caja descodificadora Proveedor de Servicios de Internet, del 10 de Enero de 2020, de FREEBOX (100.0%): Un procedimiento de visualización de páginas por un equipo cliente equipado de un sistema cerrado, conectado a un servidor remoto , integrando […]
Procedimiento implementado por ordenador y controlado por ordenador, producto de programa informático y plataforma para disponer datos para su procesamiento y almacenamiento en un motor de almacenamiento de datos, del 4 de Noviembre de 2019, de Dynactionize N.V: Un procedimiento implementado por ordenador y controlado por ordenador de disposición de datos para procesamiento y almacenamiento de los mismos en un […]
MÉTODO DE DOBLAJE Y LOCUCIONES DE AUDIO, del 11 de Julio de 2019, de TANGO VOZ, S.L: Se describe en este documento un método que permite gestionar la producción de doblajes y locuciones de audio destinados a medios audiovisuales de tal manera que no se […]
Un sistema de control para controlar el funcionamiento de una unidad de procesamiento de datos, del 21 de Mayo de 2019, de IG Knowhow Limited: Un sistema de control para controlar el funcionamiento de una unidad de procesamiento de datos, la unidad de procesamiento de datos recibiendo una primera […]
Dispositivo de procesamiento de información, método de procesamiento de información, programa de procesamiento de información y soporte de registro, del 1 de Mayo de 2019, de RAKUTEN, INC: Dispositivo de procesamiento de información que comprende: un medio (12b) de memoria de palabra de área local que almacena una palabra de área […]
Método para proporcionar una estructura de índice en una base de datos, del 1 de Mayo de 2019, de Capish International AB: Metodo para proporcionar una estructura de indice en una base de datos que comprende una pluralidad de tipos de objetos, donde cada tipo de objetos […]
SISTEMA PARA LA DETECCIÓN REMOTA DEL USO DEL CINTURÓN DE SEGURIDAD EN UN VEHÍCULO, del 18 de Abril de 2019, de CASANOVA RENT VOLKS, S.A. DE C.V: La presente invención se refiere a la industria automotriz, particularmente está relacionada con los cinturones de seguridad con que están equipados los vehículos, […]