PROCEDIMIENTO, DISPOSITIVO Y MEDIO DE CÓDIGO DE PROGRAMA INFORMÁTICO PARA LA CONVERSIÓN DE VOZ.
Un procedimiento para convertir una señal de habla de un hablante fuente en un a señal de voz convertida,
que comprende los pasos de: - una etapa de entrenamiento, en la cual: - dada una base de datos de entrenamiento de datos fuente y diana paralelos, para cada período de tono de dicha base de datos de entrenamiento: - modelar cada período de tono por medio de una onda glotal y un filtro de tracto glotal de acuerdo con el modelo de Lu y Smith, para obtener un conjunto de parámetros Liljencrants - Fant LF, dicho conjunto de parámetros LF comprende un parámetro de fuerza de excitación E e y un conjunto de parámetros T, T p, T e, T a, T c que modelan una onda glotal y un conjunto de coeficientes de filtro de tracto vocal omnipolar (α1...α p); - convertir dichos parámetros T, T p, T e, T a, T c en parámetros R g, R k, R a; - convertir dichos coeficientes de filtro de tracto vocal omnipolar (α 1...α p) en frecuencias espectrales en línea en la escala de Bark lsf 1...lsf p; - definir un vector glotal G a convertir; - definir un vector de tracto vocal de LSF a convertir, dicho vector de tracto vocal de LSF comprende dichas frecuencias espectrales en línea en la escala de Bark lsf 1...lsf p; - aplicar la eliminación del ruido de la ondícula para obtener una obtener una estimación del ruido de aspiración glotal; - a partir del conjunto de vectores de tracto vocal de LSF obtenidos para cada período de tono de dicha base de datos de entrenamiento, estimar una función de transformación lineal probabilística continua del tracto vocal usando el criterio de error cuadrático mínimo; el procedimiento se caracteriza porque dicha etapa de modelado comprende además los pasos de: - modelar dicha estimación del ruido de aspiración modulando el ruido gaussiano de la varianza unitaria próxima a cero con la mencionada onda glotal modelada y ajustando su energía ANE para coincidir con la mencionada estimación del ruido de aspiración; dicho vector glotal G a convertir comprende dicho parámetro de fuerza de excitación E e, dichos parámetros R, R g, R k , R a y dicha energía ANE de la estimación del ruido de aspiración, el procedimiento comprende además: - una etapa de conversión en la cual una onda de habla de prueba dada se modela y se transforma en un conjunto de parámetros E e', R g', R k, R a', ANE', LSF'; - una etapa de síntesis en la cual una onda de habla convertida se sintetiza a partir de dicho conjunto de parámetros convertidos E e', R g', R k, R a', ANE', LSF'
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/EP2008/062502.
Solicitante: ASOCIACIÓN CENTRO DE TECNOLOGÍAS DE INTERACCIÓN VISUAL Y COMUNICACIONES VICOMTECH
DEL POZO ECHEZARRETA, MARÍA ARANTZAZU.
Nacionalidad solicitante: España.
Inventor/es: DEL POZO ECHEZARRETA,María,Arantzazu.
Fecha de Publicación: .
Fecha Solicitud PCT: 19 de Septiembre de 2008.
Clasificación Internacional de Patentes:
- G10L21/02A4
Clasificación PCT:
- G10L21/02 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › G10L 21/00 Tratamiento de la señal de la voz para producir otra señal audible o no audible, p. ej. visual o táctil, con el fin de modificar su calidad o su inteligibilidad (G10L 19/00 tiene prioridad). › Mejora de la inteligibilidad de la voz, p. ej. reducción de ruido o eliminación de ecos (reducción de efectos de eco en los sistemas de transmisión en línea H04B 3/20; supresión de eco en teléfonos de manos libres H04M 9/08).
Países PCT: Austria, Bélgica, Suiza, Alemania, Dinamarca, España, Francia, Reino Unido, Grecia, Italia, Liechtensein, Luxemburgo, Países Bajos, Suecia, Mónaco, Portugal, Irlanda, Eslovenia, Finlandia, Rumania, Chipre, Lituania, Letonia, Ex República Yugoslava de Macedonia, Albania.
PDF original: ES-2364005_T3.pdf
Fragmento de la descripción:
Campo de la invención
La presente invención se refiere a procedimientos y sistemas para la conversión de voz.
Estado de la técnica
La Conversión de Voz se dirige a la transformación del habla de un hablante fuente para que suene como un hablante diana diferente. Los sintetizadores de texto a voz, sistemas de diálogo y reparación del habla están entre las numerosas aplicaciones que pueden beneficiarse gratamente del desarrollo de la tecnología de la conversión de voz.
Las representaciones de las señales de voz más ampliamente usadas son el Modelo Fuente - Filtro y el Modelo Sinusoidal. La representación Fuente - Filtro (G, Fant, Acoustic Theory of Speech Production, ISBN 9027916004) se basa en un modelo de producción simple compuesto de una onda fuente glotal que excita un filtro variable en el tiempo cargado en su salida por la radiación de los labios. El principal reto en el modelo Fuente - Filtro es la estimación de la onda glotal y los parámetros del filtro del tracto vocal de la señal del habla.
Entre las parametrizaciones existentes de la onda glotal, el modelo Liljencrants-Fant (LF) (The LF-model revisited. Transformation and frequency domain analysis, STL – QPSR, vol. 36, núm. 2 – 3, 1995, pág. 119 – 156) se ha convertido en el modelo de elección para la investigación sobre la fuente glotal. Ha demostrado ser capaz de modelar una amplia gama de fonaciones que se producen de forma natural y los efectos de las variaciones de sus parámetros son fáciles de entender. Explota la linealidad de las propiedades de la invariancia en el tiempo de la representación Fuente - Filtro y asume la conmutación de los filtros del tracto vocal y de la radiación de los labios para combinar el modelo de excitación fuente y la radiación de los labios en la parametrización de la derivada de la onda glotal.
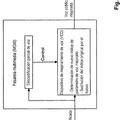
La Predicción Lineal (LP) es una técnica popular usada para obtener una parametrización combinada de los componentes de la fuente glotal, el tracto vocal y de la radiación de los labios en un único filtro omnipolar H(z). Dicho filtro se excita, tal como se muestra en la figura 1, por una secuencia de impulsos separados en el período fundamental To durante el habla sonora y mediante el ruido gaussiano blanco durante el habla no sonora. Si la señal del habla fuera realmente la respuesta de un filtro omnipolar, el error o residual de LP sería un tren de impulsos separados en los instantes de excitación sonora y el modelo de la fuente de voz de impulso/ruido sería exacto. En la práctica, sin embargo, el residuo de LP se parece más a una señal de ruido blanco con valores mayores alrededor de los instantes de excitación. Aunque la excitación del filtro de LP con el residuo de LP da como resultado un habla que es indistinguible del original, usando un tren de impulsos como excitación sonora se produce un habla con una calidad muy zumbante. La fuerza de la LP descansa en su capacidad para estimar automáticamente un conjunto de coeficientes de filtro que representan de forma compacta la cubierta del espectro del habla, haciéndolo popular en aplicaciones en las que las características espectrales de la onda de la voz necesitan ser capturadas con un pequeño número de parámetros. Su principal inconveniente, por otra parte, proviene del modelo sobre–simplificado de la onda glotal que evita su uso en sistemas que requieran salidas de voz de alta calidad.
Como alternativa a la LP, H. Lu y colaboradores han propuesto un procedimiento de optimización convexa para estimar automáticamente el filtro del tracto vocal y la onda glotal conjuntamente (Joint estimation of vocal tract filter and glottal source waveform via convex optimization, Proc, 1999 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, New Paltz, Nueva York, oct. 17 – 20, 1999). El mejor modelo de la fuente glotal empleado por esta aproximación da como resultado un habla que tiene una mejor calidad que la de la LP. Además, la parametrización de la onda glotal permite su modificación paramétrica, que puede explotarse en aplicaciones de conversión de voz.
Los Modelos Sinusoidales asumen que la onda del habla está compuesta de la suma de un pequeño número de sinusoides con amplitudes, frecuencias y fases variables en el tiempo. Dicho modelo fue principalmente desarrollado por McAulay y Quatieri (Speech Analysis/Synthesis Based on a Sinusoidal Representation, IEEE Transactions on Acoustics, Speech and Signal Processing, pág. 744 – 754, 1986) a mediados de los 80 y ha demostrado ser capaz de producir un habla de alta calidad incluso después de transformaciones de tono y escala de tiempo. Sin embargo, a causa del alto número de amplitudes sinusoidales, frecuencias y fases involucradas, el modelo sinusoidal resulta menos flexible que la representación de Fuente - Filtro para modificar características espectrales.
Para obtener un habla convertida de alta calidad, las implementaciones de conversión de voz (VC) de la técnica actual emplean principalmente variaciones y extensiones del modelo sinusoidal original. Además, generalmente adoptan una formulación de Fuente - Filtro basada en la LP para llevar a cabo las transformaciones espectrales.
Las cubiertas espectrales están generalmente codificadas en frecuencias espectrales en línea (LSF) para la conversión de voz, ya que las LSF han demostrado poseer muy buenas características de interpolación lineal y relacionarse bien con la asignación de formatos y ancho de banda. Ya que la resolución de frecuencia del oído humano es mayor a bajas frecuencias que a altas frecuencias, las cubiertas espectrales a menudo se envuelven en una escala no lineal, por ejemplo, la escala de Bark, tomando en cuenta la sensibilidad no uniforme del oído humano. Habitualmente solo se transforman las cubiertas espectrales de segmentos de habla sonora, ya que los sonidos no sonoros contienen poca información del tracto vocal y sus cubiertas espectrales presentan altas variaciones. Entre las diferentes técnicas de conversión de cubiertas espectrales existentes, se ha hallado que las transformaciones lineales de probabilidad continua son más robustas y eficientes. Estas pueden obtenerse a través de al menos una minimización del error cuadrático de las bases de datos de entrenamiento de fuente y diana o usando marcos generales de transformación de probabilidad máxima (Ye, H. y Young, S. Quality-enhanced Voice Morphing using Maximum Likelihood Transformations, IEEE Audio Speech and Language Processing, vol. 14, núm. 4, pág. 1301 – 1312, 2006). Un problema de la compartición de todos los procedimientos de conversión de cubiertas espectrales es la ampliación de los picos espectrales, la expansión de los anchos de banda formantes y la sobre-suavización provocada por el efecto de promediación de las interpolaciones de los parámetros. El fenómeno hace que el sonido del habla convertida sea ligeramente apagado. Para resolver este asunto, a menudo se aplica un post-filtrado como etapa de post-procesamiento para anchos de banda de formantes estrechos y se suprime el ruido en los valles espectrales como, por ejemplo, en Ye, H. y Young, S. Quality-enhanced Voice Morphing using Maximum Likelihood Transformations, IEEE Audio Speech and Language Processing, vol. 14, núm. 4, pág. 1301 – 1312, 2006.
Como para la conversión de residuos de LP, los sistemas sinusoidales de VC han desarrollado procedimientos de predicción y selección de residuos (D. Suendermann, A. Bonafonte, H. Ney, y J. Hoege, A study on residual prediction techniques for voice conversion, in Proc. ICASSP, 2005, pág. 13 – 16) basados en la correlación entre la cubierta espectral y los residuos de LP. Estos procedimientos reintroducen el detalle espectral diana perdido después de la conversión de la cubierta. Ya que los residuos contienen los errores introducidos por la parametrización de LP, se ha hallado que las técnicas de predicción de residuos mejoran el rendimiento de la conversión. Sin embargo, los residuos de LP no constituyen un modelo exacto de fuente de voz y la predicción de residuos sola no es capaz de modificar la calidad de la fuente de voz. Esto no permite su uso en aplicaciones que requieran modificaciones de la claridad de la voz tales como, por ejemplo, la reparación del habla.
La solicitud de patente WO 2008/018653 A1 presenta una técnica adicional de conversión de voz que usa los parámetros de Liljencrants-Fant de la onda glotal.
Resumen de la invención
Por lo tanto es un objeto de la presente invención suministrar un procedimiento de conversión de voz basado... [Seguir leyendo]
Reivindicaciones:
1. Un procedimiento para convertir una señal de habla de un hablante fuente en un a señal de voz convertida, que comprende los pasos de:
- una etapa de entrenamiento, en la cual:
- dada una base de datos de entrenamiento de datos fuente y diana paralelos, para cada período de tono de dicha base de datos de entrenamiento:
- modelar cada período de tono por medio de una onda glotal y un filtro de tracto glotal de acuerdo con el modelo de Lu y Smith, para obtener un conjunto de parámetros Liljencrants – Fant LF, dicho conjunto de parámetros LF comprende un parámetro de fuerza de excitación Ee y un conjunto de parámetros T, Tp, Te, Ta, Tc que modelan una onda glotal y un conjunto de coeficientes de filtro de tracto vocal omnipolar (α1…αp);
- convertir dichos parámetros T, Tp, Te, Ta, Tc en parámetros Rg, Rk, Ra;
- convertir dichos coeficientes de filtro de tracto vocal omnipolar (α1…αp) en frecuencias espectrales en línea en la escala de Bark lsf1…lsfp;
- definir un vector glotal G a convertir;
- definir un vector de tracto vocal de LSF a convertir, dicho vector de tracto vocal de LSF comprende dichas frecuencias espectrales en línea en la escala de Bark lsf1…lsfp;
- aplicar la eliminación del ruido de la ondícula para obtener una obtener una estimación del ruido de aspiración glotal;
- a partir del conjunto de vectores de tracto vocal de LSF obtenidos para cada período de tono de dicha base de datos de entrenamiento, estimar una función de transformación lineal probabilística continua del tracto vocal usando el criterio de error cuadrático mínimo;
el procedimiento se caracteriza porque dicha etapa de modelado comprende además los pasos de:
- modelar dicha estimación del ruido de aspiración modulando el ruido gaussiano de la varianza unitaria próxima a cero con la mencionada onda glotal modelada y ajustando su energía ANE para coincidir con la mencionada estimación del ruido de aspiración;
dicho vector glotal G a convertir comprende dicho parámetro de fuerza de excitación Ee, dichos parámetros R, Rg, Rk , Ra y dicha energía ANE de la estimación del ruido de aspiración,
el procedimiento comprende además:
- una etapa de conversión en la cual una onda de habla de prueba dada se modela y se transforma en un conjunto de parámetros Ee, Rg, Rk, Ra, ANE, LSF;
- una etapa de síntesis en la cual una onda de habla convertida se sintetiza a partir de dicho conjunto de parámetros convertidos Ee, Rg, Rk, Ra, ANE, LSF.
2. El procedimiento de acuerdo con la reivindicación 1, en el que dicha etapa de entrenamiento comprende además:
- a partir del conjunto de vectores glotales G obtenidos para cada período de tono de dicha base de datos de entrenamiento, estimar una función de transformación lineal probabilística continua de la onda glotal usando el criterio de error cuadrático mínimo.
3. El procedimiento de acuerdo con la reivindicación bien 1 ó bien 2, en el que dicho paso de modelar cada período de tono por medio de una onda glotal y un filtro de tracto vocal de acuerdo con el modelo de Lu y Smith, comprende los pasos de:
- modelar la onda glotal usando el modelo de Rosenberg – Klatt;
- usar optimización convexa para obtener un conjunto de parámetros glotales de Rosenberg – Klatt y los coeficientes del filtro de tracto vocal omnipolar α1…αp en el que dicho paso de usar optimización convexa comprende un paso de pre-énfasis adaptativo para estimar y eliminar la contribución de filtro de inclinación espectral de la onda del habla antes de la optimización convexa.
4. El procedimiento de acuerdo con la reivindicación 3, en el que dicho paso de modelar cada período de tono por medio de una onda glotal y un filtro de tracto vocal de acuerdo con el modelo de Lu y Smith, comprende además los pasos de:
- obtener una onda glotal derivada mediante el filtrado inverso de dicho período de tono usando dichos coeficientes de filtro de tracto vocal omnipolar α1…αp;
- ajustar dicho conjunto de parámetros LF a dicha onda glotal derivada de filtrado inverso mediante estimación directa y optimización no lineal constreñida.
5. El procedimiento de acuerdo con cualquier reivindicación precedente, en el que dicha etapa de conversión comprende, para cada período de tono de dicha onda de habla de prueba:
- obtener un vector glotal G a convertir, comprendiendo dicho vector glotal un parámetro de fuerza de excitación Ee, un conjunto de parámetros R, Rg, Rk, Ra y la energía ANE de dicha estimación de ruido de aspiración;
- obtener el vector de tracto vocal de LSF a convertir, dicho vector de tracto vocal de LSF comprende un conjunto de frecuencias espectrales en línea en la escala de Bark lsf1…lsfp;
- aplicar dicha función de transformación lineal probabilística continua del tracto vocal estimada durante la etapa de entrenamiento para obtener un vector de parámetros de LSF de tracto vocal convertidos;
- transformar dicho vector glotal G usando dicha función de transformación lineal probabilística continua de onda glotal estimada durante la etapa de entrenamiento, obteniendo así un vector glotal convertido G que comprende un conjunto de parámetros convertidos Ee, Rg, Rk, Ra, ANE, LSF;
6. El procedimiento de acuerdo con la reivindicación 5, en el que dichas etapas de obtener un vector glotal G a convertir y un vector de tracto vocal de LSF a convertir comprende además los pasos de:
- modelar cada período de tono por medio de una onda glotal y un filtro de tracto vocal de acuerdo con el modelo de Lu y Smith, para obtener un conjunto de parámetros LF, comprendiendo dicho conjunto de parámetros LF un parámetro de fuerza de excitación Ee y un conjunto de parámetros T, Tp, Te, Ta, Tc que modelan la onda glotal, y un conjunto de coeficientes de filtro de tracto vocal omnipolar α1…αp;
- convertir dichos coeficientes de filtro de tracto vocal omnipolar en frecuencias espectrales en línea en la escala de Bark lsf1…lsfp;
- convertir dichos parámetros T en parámetros R, Rg, Rk, Ra;
- definir un vector glotal G a convertir;
- definir un vector de tracto vocal de LSF a convertir.
7. El procedimiento de acuerdo con la reivindicación bien 5 o bien 6, en el que dicha etapa de conversión comprende además un paso de post-filtrado de dicho vector de parámetros convertidos de tracto vocal de LSF.
8. El procedimiento de acuerdo con cualquier reivindicación precedente, en el que dicha etapa de síntesis, en la cual se sintetiza dicha onda de habla convertida a partir de dicho conjunto de parámetros convertidos Ee, Rg, Rk, Ra, ANE, LSF; comprende los pasos de:
- interpolar las trayectorias de dichos parámetros convertidos Rg, Rk, Ra, ANE, LSF; de cada período de tono, obteniendo así un conjunto de parámetros interpolados Rg”, Rk”, Ra”, ANE”, LSF”; que comprende los parámetros Rg”, Rk”, Ra”, energía interpolada (ANE) y un vector de tracto vocal interpolado de LSF”;
- convertir dicho vector de tracto vocal interpolado de LSF” en un vector de coeficientes de filtro omnipolar A”;
- convertir dichos parámetros R interpolados Rg”, Rk”, Ra” en parámetros T interpolados Tp”, Te”, Ta”, Tc” ;
- para cada marco de dicha onda de voz de prueba, generar una señal de excitación ek(n), en la que k indica el kenésimo marco.
9. El procedimiento de acuerdo con la reivindicación 8, en el que dicha etapa de generar una señal de excitación comprende, para cada uno de dichos marcos:
- si dicho marco es sonoro:
- a partir de dichos parámetros T interpolados Tp”, Te”, Ta”, Tc” y de dicho parámetro de fuerza de excitación Ee
generar una onda glotal interpolada lfk(n);
- a partir de dicho parámetro de energía interpolado ANE”, generar un ruido de aspiración interpolado ank(n);
- generar dicha señal de excitación sonora ek(n) añadiendo dicha onda glotal interpolada lfk(n) y dicho ruido de aspiración interpolado ank(n);
5 - si dicho marco no es sonoro:
- generar dicha señal de excitación no sonora ek(n) a partir de una fuente de ruido gaussiano gnk(n).
10. El procedimiento de acuerdo con la reivindicación bien 8 o bien 9 en el que dicha etapa de síntesis comprende además:
- generar una contribución sintética de cada marco filtrando dicha señal de excitación ek(n) con dicho vector de 10 coeficientes de filtro omnipolar A”;
- multiplicar dicha contribución sintética por una ventana de Hamming, superponer y añadir, para generar la señal de habla convertida.
11. Un procedimiento aplicable a transformaciones de calidad de voz, tales como la reparación del habla traqueoesofágica, que comprende los pasos de procedimiento de cualquier reivindicación precedente.
12. Un dispositivo que comprende medios adaptados para llevar a cabo los pasos del procedimiento de cualquier reivindicación precedente.
13. Un medio de código de programa informático adaptado para realizar los pasos del procedimiento de cualquier reivindicación 1 – 11, cuando dicho programa se ejecuta en un ordenador, un procesador de señales digitales, una matriz de puertas programables por campo, un circuito integrado específico para la aplicación, un microprocesador, un microcontrolador o cualquier otra forma de hardware programable.
Patentes similares o relacionadas:
DISPOSITIVO DE MEJORA DE SONIDO DE VOZ, del 16 de Enero de 2012, de FUJITSU LIMITED: Un dispositivo de mejora de sonido de voz incluyendo: una unidad de calculo SNR configurada para calcular una SNR que es una relacion […]
DISPOSITIVO Y PROCEDIMIENTO PARA GENERAR UNA SEÑAL MULTICANAL CON UN PROCESAMIENTO DE SEÑAL DE VOZ, del 16 de Septiembre de 2011, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Dispositivo para generar una señal multicanal con un número de señales de canal de salida, que es mayor que un número de señales de canal de entrada de una señal […]
 MEJORAMIENTO DE AUDIO EN DOMINIO CODIFICADO, del 21 de Abril de 2010, de NOKIA CORPORATION: Un procedimiento de mejoramiento de una señal de audio codificada que comprende índices que representan parámetros de señales de audio de señales de audio que comprenden […]
MEJORAMIENTO DE AUDIO EN DOMINIO CODIFICADO, del 21 de Abril de 2010, de NOKIA CORPORATION: Un procedimiento de mejoramiento de una señal de audio codificada que comprende índices que representan parámetros de señales de audio de señales de audio que comprenden […]
SISTEMA Y DISPOSITIVO INALÁMBRICO Y PONIBLE PARA REGISTRO, PROCESAMIENTO Y REPRODUCCIÓN DE SONIDOS EN PERSONAS CON DISTROFIA EN EL SISTEMA RESPIRATORIO, del 5 de Marzo de 2020, de ARAGÓN HAN, Daniel: La invención se refiere a un sistema y dispositivo para el registro, procesamiento y reproducción de sonidos en personas con distrofia en el […]
Métodos, aparatos y sistema para codificar y decodificar una señal, del 8 de Enero de 2020, de HUAWEI TECHNOLOGIES CO., LTD.: Un método para codificar una señal, que comprende: realizar un proceso de decisión de clasificación sobre una señal de banda de alta frecuencia de una señal […]
Métodos para codificar y decodificar una señal de audio, decodificador de audio y codificador de audio, del 1 de Enero de 2020, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un método para codificar una señal de audio, comprendiendo el método: (a) recibir una señal de audio ; (b) generar una señal de audio codificada; […]
Método y aparato para la mejora multisensorial del habla en un dispositivo móvil, del 13 de Noviembre de 2019, de Zhigu Holdings Limited: Un dispositivo móvil de mano, que comprende: un micrófono de conducción de aire que está configurado para convertir ondas acústicas en una señal […]
Método y dispositivo de enriquecimiento espectral, del 14 de Junio de 2019, de Orange: Procedimiento de enriquecimiento del contenido espectral de una señal que tiene un espectro incompleto incluyendo una primera banda espectral, comprendiendo […]