Método y sistema para conseguir hashing de audio invariante al canal.
Un método de hashing robusto de audio, incluyendo un paso de extracción de hash robusto en el que se extrae un hash robusto (110) a partir de contenido de audio (102,
106); dicho paso de extracción de hash robusto incluye:
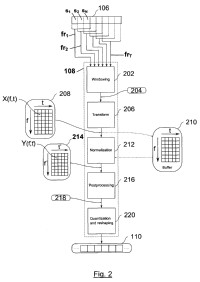
- dividir el contenido de audio (102, 106) en, al menos, una trama;
- aplicar un proceso de transformación (206) en la trama para calcular, en dicha trama, un conjunto de coeficientes transformados (208);
- aplicar un proceso de normalización (212) a los coeficientes transformados (208) para obtener un conjunto de coeficientes normalizados (214), en el que dicha normalización (212) implica el cálculo del producto del signo de cada coeficiente de dichos coeficientes transformados (208) por el cociente de dos funciones homogéneas de cualquier combinación de dichos coeficientes transformados (208), donde ambas funciones homogéneas son del mismo orden;
- aplicar un procedimiento de cuantificación (220) sobre dichos coeficientes normalizados (214) para obtener el hash robusto (110) del contenido de audio (102,106).
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/EP2011/002756.
Solicitante: Bridge Mediatech, S.L.
Nacionalidad solicitante: España.
Inventor/es: PEREZ GONZALEZ,FERNANDO, COMESAÑA ALFARO,PEDRO, PÉREZ FREIRE,LUIS, PÉREZ VIEITES,DIEGO.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G10L25/18 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › G10L 25/00 Técnicas de análisis del habla o voz no restringidos a un solo de los grupos G10L 15/00 - G10L 21/00 (silenciar los amplificadores basados en semiconductores, cuando algunas de las características especiales de una señal son detectadas por un detector de voz, p. ej. detectar cuando no hay ninguna señal, H03G 3/34). › siendo los parámetros extraídos información espectral de cada una de las subbandas.
PDF original: ES-2459391_T3.pdf
Fragmento de la descripción:
Método y sistema para conseguir hashing de audio invariante al canal
Campo de la Invención La presente invención se relaciona con el campo del procesado de audio, específicamente con el campo del hashing robusto de audio, también conocido como identificación de audio basada en contenido, hashing de audio perceptual, o fingerprinting de audio.
Antecedentes de la Invención La identificación de contenidos multimedia, y contenidos de audio en particular, es un campo que atrae considerable atención por tratarse de una tecnología que posibilita muchas aplicaciones, abarcando desde el cumplimiento del derecho de copia o la búsqueda en bases de datos multimedia al enlazado de metadatos, sincronización de audio y vídeo, y la provisión de muchos otros servicios de valor añadido. Muchas de dichas aplicaciones se basan en la comparación de un contenido entre un audio capturado por un micrófono y los valores almacenados en una base de datos de referencia de contenidos de audio. Algunas de estas aplicaciones se ejemplifican a continuación.
Peters et al revelan en US Patent App. No. 10/749, 979 un método y sistema para identificar audio ambiente capturado desde un micrófono y mostrar al usuario contenido asociado con dicho audio capturado. Métodos similares se describen en International Patent App. No. PCT/US2006/045551 (asignada a Google) para identificar audio ambiente correspondiente a un medio de difusión, presentando información personalizada al usuario en respuesta al audio identificado, y algunas aplicaciones interactivas adicionales.
US Patent App. No. 09/734, 949 (asignada a Shazam) describe un método y sistema para interactuar con los usuarios, en base a una muestra proporcionada por el usuario relacionada con su entorno que es entregada a un servicio interactivo con el fin de disparar eventos, tales como (pero no limitados a) una captura de micrófono.
US Patent App. No. 11/866, 814 (asignada a Shazam) describe un método para identificar un contenido capturado de un flujo de datos, que puede ser audio difundido por una fuente de difusión tal como una radio o una estación de televisión. Este método podría ser usado para identificar una canción en una emisión de radio.
Wang et al describen en US Patent App. No. 10/831, 945 un método para realizar transacciones, tales como adquisiciones musicales, en base a un sonido capturado utilizando, entre otros, un método de hashing de audio robusto.
El uso de hashing robusto también es considerado por R. Reisman en US Patent App. No. 10/434, 032 para aplicaciones de TV interactivas. Lu et al. consideran en US Patent App. No. 11/595, 117 el uso de hashes de audio robustos para realizar mediciones de audiencias de programas de difusión.
Existen muchas técnicas para realizar identificación de audio. Cuando se tiene la certeza de que el audio a identificar y la referencia de audio existen y son iguales bit a bit, se pueden utilizar las técnicas tradicionales de hashing criptográfico para realizar búsquedas eficientes. No obstante, si las copias de audio difieren en un único bit esta aproximación falla. Otra técnica para la identificación de audio se basa en metadatos añadidos, pero no son robustos ante conversión de formatos, borrado manual de los metadatos, conversión D/A/D, etc. Cuando el audio puede ser distorsionado leve o fuertemente es obligatorio emplear otras técnicas que sean suficientemente robustas ante dichas distorsiones. Esas técnicas incluyen el watermarking y el hashing robusto de audio. Las técnicas basadas en watermarking asumen que el contenido a identificar lleva incluído cierto código (la marca de agua) que ha sido incrustado a priori. No obstante, la inserción de una marca de agua no siempre es viable, bien por razones de escalabilidad, bien por otros inconvenientes tecnológicos. Es más, dada una copia sin marca de agua de un contenido de audio el detector de la marca no puede extraer ninguna información identificativa de aquél. Por contra, las técnicas de hashing robusto de audio no necesitan ningún tipo de inserción de información en los contenidos de audio, convirtiéndolas en más universales. Las técnicas de hashing de audio robusto analizan el contenido de audio con el fin de obtener un descriptor robusto, normalmente conocido como "hash robusto" o "fingerprint", que puede ser comparado con otros descriptores almacenados en bases de datos.
Existen muchas técnicas de hashing de audio robusto. Se puede encontrar una revisión de los algoritmos más populares en el artículo de Cano et al. titulado “A review of audio fingerprinting”, Journal of VLSI Signal
Processing 41, 271-284, 2005. Algunas de las técnicas actuales persiguen identificar canciones completas o secuencias de audio, o incluso CDs o listas de reproducción. Otras técnicas permiten identificar una canción o una secuencia de audio utilizando únicamente un pequeño fragmento de ella. Normalmente estas últimas pueden adaptarse para realizar identificación en streaming, i.e. capturando fragmentos sucesivos de un flujo de audio y realizando la comparación con bases de datos de tal modo que los contenidos de referencia no están necesariamente sincronizados con aquellos que han sido capturados. Éste es, en general, el modo de operación más habitual para realizar identificación de difusiones de audio y de audio capturado por un micrófono.
La mayoría de métodos para realizar hashing de audio robusto dividen el flujo de audio en bloques contiguos de corta duración, normalmente con un grado significativo de solape. A cada uno de estos bloques se le aplican distintas operaciones con el fin de extraer características distintivas de tal modo que sean robustas frente a un conjunto dado de distorsiones. Estas operaciones incluyen, por un lado, la aplicación de transformaciones de señal como la Fast Fourier Transform (FFT) , Modulated Complex Lapped Transform (MCLT) , Discrete Wavelet Transform, Discrete Cosine Transform (DCT) , Haar Transform o la Walsh-Hadamard Transform, entre otras. Otro procesado que es común a muchos métodos de hashing robusto es la separación de las señales de audio transformado en sub-bandas, emulando propiedades del sistema auditivo humano con el fin de extraer parámetros perceptualmente significativos. Es posible obtener algunos de dichos parámetros de las señales de audio procesadas, tales como los Mel-Frequency Cepstrum Coefficients (MFCC) , Spectral Flatness Measure (SFM) , Spectral Correlation Function (SCF) , la energía de los coeficientes de Fourier, los centroides espectrales, la tasa de cruces por cero, etc. Por otro lado, operaciones habituales también incluyen el filtrado tiempo-frecuencia para eliminar efectos espúreos del canal y para incrementar la decorrelación, y el uso de técnicas de reducción de dimensionalidad como Principal Components Analysis (PCA) , Independent Component Analysis (ICA) , o la DCT.
Un método conocido para el hashing robusto de audio que se adecúa a la descripción general proporcionada anteriormente se describe en la patente Europea No. 1362485 (asignada a Philips) . Los pasos de este método se pueden resumir como sigue: dividir la señal de audio en segmentos enventanados solapantes de longitud fija, calcular los coeficientes del espectrograma de la señal de audio utilizando un banco de filtros de 32 bandas en escala de frecuencias logarítmica, realizar un filtrado 2D de los coeficientes del espectrograma, y cuantificar los coeficientes resultantes con un cuantificador binario según su signo. De esta forma el hash robusto se compone de una secuencia binaria de 0s y 1s. La comparación entre dos hashes robustos tiene lugar calculando su distancia Hamming. Si dicha distancia es menor que un cierto umbral, entonces se decide que los dos hashes robustos representan la misma señal de audio. Este método proporciona un rendimiento razonablemente bueno bajo distorsiones leves, pero en general su funcionamiento empeora bajo las condiciones del mundo real. Un número significativo de trabajos posteriores ha añadido procesado adicional o modificado ciertas partes del método con el fin de mejorar su robustez ante diferentes tipos de distorsión.
El método descrito en EP1362485 ha sido modificado en la solicitud de patente internacional PCT/IB03/03658 (asignada a Philips) con el fin de obtener robustez ante cambios en la velocidad de reproducción de las señales de audio. Con el fin de tratar con los desalineamientos en los dominios del tiempo y de la frecuencia causados por cambios en la velocidad, este método introduce un paso adicional en el método descrito en EP1362485. Este paso consiste en calcular la autocorrelación temporal de los coeficientes de salida del banco de filtros, cuyo número de bandas también es incrementado de 32... [Seguir leyendo]
Reivindicaciones:
1. Un método de hashing robusto de audio, incluyendo un paso de extracción de hash robusto en el que se extrae un hash robusto (110) a partir de contenido de audio (102, 106) ; dicho paso de extracción de hash robusto incluye:
- dividir el contenido de audio (102, 106) en, al menos, una trama;
- aplicar un proceso de transformación (206) en la trama para calcular, en dicha trama, un conjunto de coeficientes transformados (208) ;
- aplicar un proceso de normalización (212) a los coeficientes transformados (208) para obtener un conjunto de coeficientes normalizados (214) , en el que dicha normalización (212) implica el cálculo del producto del signo de cada coeficiente de dichos coeficientes transformados (208) por el cociente de dos funciones homogéneas de cualquier combinación de dichos coeficientes transformados (208) , donde ambas funciones homogéneas son del mismo orden;
-aplicar un procedimiento de cuantificación (220) sobre dichos coeficientes normalizados (214) para obtener el hash robusto (110) del contenido de audio (102, 106) .
2. El método de la reivindicación 1 mediante el que se realiza un paso de comparación en el que el hash robusto (110) se compara con al menos un hash de referencia (302) para obtener una correspondencia.
3. El método de la reivindicación 2, en el que el paso de comparación implica, para cada hash de referencia (302) :
extraer del correspondiente hash de referencia (302) al menos un sub-hash (306) de la misma longitud J que la longitud del hash robusto (110) ;
convertir (308) el hash robusto (110) y cada uno de dichos sub-hashes (306) en los correspondientes símbolos de reconstrucción dados por el cuantificador;
calcular una medida de similitud (312) de acuerdo con la correlación normalizada (310) entre el hash robusto (110) y cada uno de dichos sub-hashes (306) de acuerdo con la siguiente regla:
donde hq representa el hash a estudiar (110) de longitud J, hr un sub-hash de referencia (306) de la misma longitud J, y donde comparar una función de dichas medidas de similitud (312) con un umbral predefinido;
decidir, en base a dicha comparación, si el hash robusto (110) y el hash de referencia (302) representan el mismo contenido de audio.
4. El método de las anteriores reivindicaciones, en el que el proceso de normalización (212) se aplica sobre los coeficientes transformados (208) dispuestos en una matriz de tamaño F×T para obtener una matriz de coeficientes normalizados (214) de tamaño F’ × T’, con F’ = F, T’ : T, cuyos elementos Y (f’, t’) se calculan de acuerdo con la siguiente regla:
donde X (f’, M (t’) ) son los elementos de la matriz de coeficientes transformados (208) , Xf’ es la fila f-ésima de la matriz de coeficientes transformados (208) , M () es una función que hace corresponder a índices del conjunto {1, …, T’} otros índices de {1, …, T}, y tanto H () como G () son funciones homogéneas del mismo orden.
5. El método de la reivindicación 4, en el que las funciones homogéneas H () y G () son tales que:
con donde kl es el máximo de {M (t’) −Ll, 1}, ku es el mínimo de {M (t’) +Lu−1, T}, M (t’) >1, y Ll>1, L >0.
u
6. El método de la reivindicación 5, en el que M (t’) =t’+1 y , derivando en la siguiente regla de normalización:
7. El método de la reivindicación 6, en el que
donde Ll =L, a=[a (11, a (2) , …, a (L) ] es un vector de ponderación, y p es un número real positivo.
8. El método de las anteriores reivindicaciones, en el que el proceso de transformación (206) implica una subdivisión espectral por sub-bandas de cada trama (204) .
9. El método de las anteriores reivindicaciones, en el que durante el proceso de cuantificación (220) se emplea al menos un cuantificador multinivel.
10. El método de la reivindicación 9, en el que se obtiene al menos un cuantificador multinivel mediante un método de entrenamiento que comprende:
• el cálculo de una partición (608) , obteniéndose Q intervalos de cuantificación disjuntos mediante la maximización de una función de coste predefinida que depende de los estadísticos de los coeficientes normalizados calculados a partir de un conjunto de entrenamiento (602) de fragmentos de audio; y
• el cálculo de símbolos (612) , asociando un símbolo a cada intervalo calculado.
11. El método de la reivindicación 10, en el que la función de coste es la entropía empírica de los coeficientes cuantificados, calculada de acuerdo con la siguiente fórmula:
12. Un método para decidir si dos hashes robustos calculados de acuerdo con el método de hashing de audio robusto de cualquiera de las anteriores reivindicaciones representan el mismo contenido de audio, caracterizado por que dicho método comprende:
donde Ni, f es el número de coeficientes de la fila f-ésima de la matriz de coeficientes postprocesados asignados al intervalo i-ésimo de la partición, y Lc es la longitud de cada fila.
• la extracción del hash más largo (302) de al menos un sub-hash (306) de la misma longitud J que la longitud del hash más corto (110) ;
• la conversión (308) del hash más corto (110) y de dichos sub-hashes (306) en los correspondientes símbolos de reconstrucción dados por el cuantificador;
• el cálculo de una medida de similitud (312) de acuerdo con la correlación normalizada (310) entre el hash más corto (110) y cada uno de dichos sub-hashes (306) de acuerdo con la siguiente regla:
donde hq representa el hash que está siendo analizado (110) de longitud J, hr un sub-hash de referencia (306) de la misma longitud J, y donde la comparación de una función de dichas medidas de similitud (312) con un umbral predefinido;
• la decisión, en base a dicha comparación, de si los dos hashes robustos (110, 302) representan el mismo contenido de audio.
13. Un sistema de hashing robusto de audio, caracterizado por que comprende un módulo de extracción de hash robusto (108) para extraer un hash robusto (110) a partir de contenido de audio (102, 106) , y el módulo de extracción de hash robusto (108) comprendiendo medios de procesamiento de datos configurados para:
• la división del contenido de audio (102, 106) en al menos una trama;
• la aplicación de un proceso de transformación (206) sobre dichas tramas para calcular, para cada una de ellas, un conjunto de coeficientes transformados (208) ;
• la aplicación de un proceso de normalización (212) sobre los coeficientes transformados (208) para obtener un conjunto de coeficientes normalizados (214) , donde dicho proceso de normalización (212) comprende el cálculo del producto del signo de cada coeficiente transformado (208) por el cociente de dos funciones homogéneas de cualquier combinación de los coeficientes transformados (208) , donde ambas funciones homogéneas son del mismo orden;
• la aplicación de un proceso de cuantificación (220) en dichos coeficientes normalizados (214) para obtener un hash robusto (110) del contenido de audio (102, 106) .
14. El sistema de la reivindicación 13 que comprende a mayores un módulo de comparación (114) para comparar el hash robusto (110) con al menos un hash de referencia (302) para encontrar una correspondencia.
15. Un sistema para decidir si dos hashes robustos calculados mediante el sistema de hashing robusto de
audio de las reivindicaciones 13 y 14 representan el mismo contenido de audio, que caracterizado por que 35 dicho sistema comprende medios de procesamiento de datos configurados para:
• la extracción del hash más largo (302) de al menos un sub-hash (306) con la misma longitud J que la longitud del hash más corto (110) ;
• la conversión (308) del hash más corto (110) y cada uno de dichos sub-hashes (306) en los correspondientes símbolos de reconstrucción dados por el cuantificador;
• el cálculo de una medida de similitud (312) de acuerdo con la correlación normalizada (310) entre el hash más corto (110) y cada uno de dichos sub-hashes (306) de acuerdo con la siguiente regla:
donde hq representa el hash a comparar (110) de longitud J, hr un sub-hash de referencia (306) de la misma longitud J, y donde
• la comparación de una función de dicha media de similitud (312) con un umbral predefinido;
• la decisión, en base a dicha comparación, de si dos hashes robustos (110, 302) representan el mismo contenido de audio.
Patentes similares o relacionadas:
Codificación de audio, del 10 de Junio de 2020, de HUAWEI TECHNOLOGIES CO., LTD.: Un método de codificación de audio, que comprende: realizar procesamiento de transformación de tiempo-frecuencia sobre una señal en el dominio del […]
Método y sistema para verificación de orador, del 20 de Mayo de 2020, de BEIJING DIDI INFINITY TECHNOLOGY AND DEVELOPMENT CO., LTD: Un método de verificación de orador, que comprende: adquirir una grabación de audio; extraer señales de voz de la grabación de audio; extraer características […]
Método y dispositivo para detectar la señal de audio, del 12 de Febrero de 2020, de HUAWEI TECHNOLOGIES CO., LTD.: Un método para detectar una señal activa, en donde el método comprende: cuando se determina que una señal de audio es una señal sin voz, […]
Seleccionar un procedimiento de ocultación de pérdida de paquetes, del 8 de Enero de 2020, de TELEFONAKTIEBOLAGET LM ERICSSON (PUBL): Un método para seleccionar un procedimiento de ocultación de pérdida de paquetes, comprendiendo el método: detectar un tipo de audio […]
Estimación de audibilidad de muestras de audio, del 12 de Noviembre de 2019, de BMAT LICENSING, S.L.U: Un procedimiento para estimar la audibilidad de una muestra de audio en una mezcla de audio de un programa de medio de radio difusión, que comprende: […]
Procedimiento y dispositivo de clasificación de señales de audio, del 6 de Noviembre de 2019, de HUAWEI TECHNOLOGIES CO., LTD.: Un procedimiento de clasificación de señales de audio, que comprende: determinar , según actividad de voz de una trama de audio actual, si hay que […]
Dispositivo de iluminación y marco con dicho dispositivo de iluminación unido al mismo, del 9 de Octubre de 2019, de AG Inc: Un dispositivo de iluminación adaptado para iluminar una pintura (P) que está parcialmente dibujada con pintura especial que emite o refleja la luz tras la […]
Clasificador de señales de audio, del 18 de Septiembre de 2019, de TELEFONAKTIEBOLAGET LM ERICSSON (PUBL): Un método para clasificar señales de audio, comprendiendo el método: para un segmento de una señal de audio: - identificar un conjunto de picos espectrales; […]