Un aparato y un método para generar datos de salida por ampliación de ancho de banda.
Un aparato (100) para determinar una señal de audio de multi-canal de salida espacial sobre la base de una señal de audio de entrada,
que comprende:
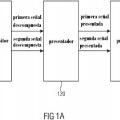
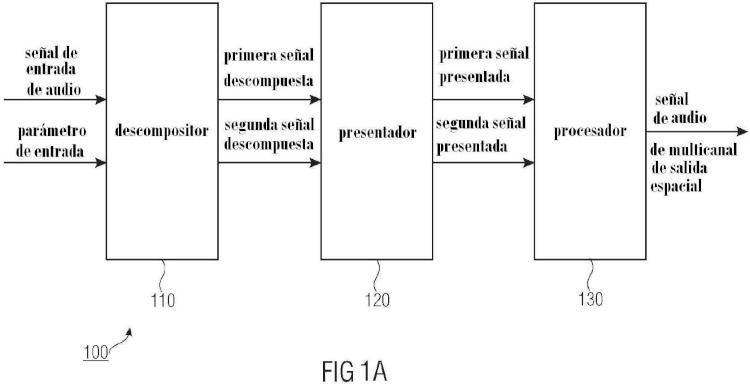
un des-compositor (110) para descomponer la señal de audio de entrada para obtener una primera señal descompuesta que tiene una primera propiedad semántica, donde la primera señal descompuesta comprende una parte de señal de primer plano de la señal de audio de entrada, y una segunda señal descompuesta que tiene una segunda propiedad semántica que es diferente de la primera propiedad semántica, donde la segunda señal descompuesta comprende una parte de señal de fondo de la señal de audio de entrada, donde el des-compositor (110) está adaptado para determinar la segunda señal descompuesta que comprende la parte de señal de fondo de la señal de audio de entrada mediante un método de separación de transitorios y la primera señal descompuesta que comprende la parte de señal de primer plano de la señal de audio de entrada sobre la base de una diferencia entre la segunda señal descompuesta y la señal de audio de entrada;
un presentador (120) para presentar la primera señal descompuesta utilizando una primera característica de presentación para obtener una primera señal presentada que tiene la primera propiedad semántica y para presentar la segunda señal descompuesta utilizando una segunda característica de presentación para obtener una segunda señal presentada que tiene la segunda propiedad semántica, donde la primera característica de presentación y la segunda característica de presentación son diferentes entre sí, donde el presentador (120) está adaptado para presentar la primera señal descompuesta según una característica de audio de primer plano como la primera característica de presentación y para presentar la segunda señal descompuesta según una característica de audio de fondo como la segunda característica de presentación; y
un procesador (130) para procesar la primera señal presentada y la segunda señal presentada para obtener la señal de audio de multi-canal de salida espacial.
Tipo: Patente Europea. Resumen de patente/invención. Número de Solicitud: E11187023.
Solicitante: FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V..
Nacionalidad solicitante: Alemania.
Dirección: HANSASTRASSE 27C 80686 MUNCHEN ALEMANIA.
Inventor/es: DISCH,SASCHA, PULKKI,Ville, LAITINEN,Mikko-Ville, ERKUT,CUMHUR.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- H04S7/00 ELECTRICIDAD. › H04 TECNICA DE LAS COMUNICACIONES ELECTRICAS. › H04S SISTEMAS ESTEREOFONICOS. › Disposiciones para la indicación; Disposiciones para el control, p. ej. para el control de la compensación.
PDF original: ES-2553382_T3.pdf

Patentes similares o relacionadas:
Método de determinación de una función de transferencia relacionada con la cabeza y una función de diferencia de tiempo interaural personalizadas, y producto de programa informático para realizar el mismo, del 8 de Julio de 2020, de Universiteit Antwerpen: Un método de estimar una función de transferencia relacionada con la cabeza (HRTF) individualizada y una función de diferencia de tiempo interaural (ITDF) […]
Método y sistema para el cálculo de funciones de transmisión de oído externo sintéticas mediante síntesis de campo acústico virtual, del 1 de Julio de 2020, de DEUTSCHE TELEKOM AG: Método para el cálculo de funciones de transmisión de oído externo sintéticas de un oyente, con los siguientes pasos: a) poner a disposición una base de datos de pares […]
Renderización mejorada de contenido de audio inmersivo, del 13 de Mayo de 2020, de DOLBY INTERNATIONAL AB: Método de renderización de audio de entrada para su reproducción en un entorno de reproducción, en donde el audio de entrada incluye por lo menos un […]
Aparato y procedimiento para generar señales de salida basadas en una señal de fuente de audio, un sistema de reproducción de sonido y una señal de altavoz, del 22 de Abril de 2020, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Aparato para generar una primera multitud de señales de salida (102a-d) en función de al menos una señal de fuente de audio (104a, 104b), comprendiendo el aparato: […]
Dispositivo para generar salida de audio, del 15 de Abril de 2020, de QUALCOMM INCORPORATED: Un dispositivo de auriculares que comprende: un primer auricular configurado para: recibir un sonido de referencia en un […]
Sistema para trasmitir adaptativamente objetos de audio, del 8 de Abril de 2020, de DTS LLC: Un sistema para adaptar la trasmisión de un flujo de audio orientado a objetos, el sistema comprendiendo: un monitor de recursos de red configurado para recibir una solicitud […]
SISTEMA Y MÉTODO DE SONIDO ESPECTRAL POSICIONAL, del 30 de Marzo de 2020, de REBOLLO GOMEZ, Joaquin: Se describen un sistema y un método de sonido espectral posicional, capacitados para generar en un entorno una multiplicidad de señales variables en función de la posición y […]
Aparato y método para la renderización de audio empleando una definición de distancia geométrica, del 25 de Diciembre de 2019, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Aparato para reproducir un objeto de audio asociado con una posición, que comprende: un calculador de distancia para calcular distancias de la […]