Método para la estimación de una pose de un modelo de objeto articulado.
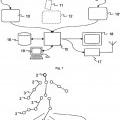
Un método implementado por ordenador para la estimación de una pose de un modelo de objeto articulado (4),
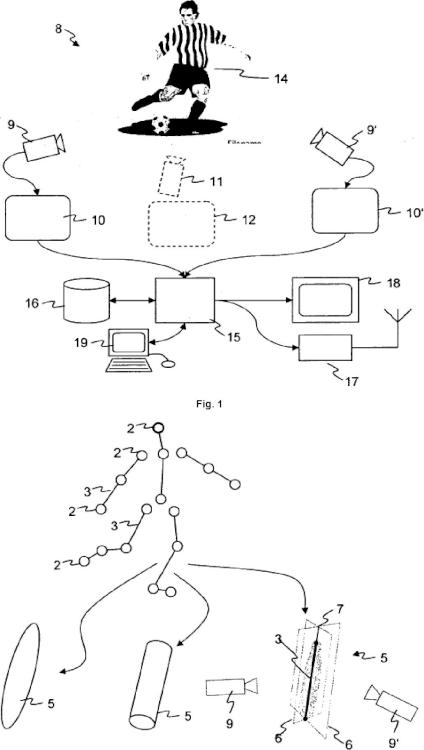
en el que el modelo de objeto articulado (4) es un modelo en 3D basado en ordenador (1) de un objeto del mundo real (14) observado por una o más cámaras de origen (9), y el modelo de objeto articulado (4) representa una pluralidad de articulaciones (2) y de enlaces (3) que enlazan las articulaciones (2), y en el que la pose del modelo de objeto articulado (4) está definido por la localización espacial de las articulaciones (2), el método comprende los pasos de
• obtener por lo menos una imagen de origen (10) desde una corriente de vídeo que comprende una vista del objeto del mundo real (14) grabada por una cámara de origen (9);
• procesar la por lo menos una imagen de origen (10) para extraer un segmento de imagen de origen correspondiente (13) que comprende la vista del objeto del mundo real (14) separado del fondo de la imagen;
• mantener, en una base de datos en forma legible por ordenador, un conjunto de siluetas de referencia, cada silueta de referencia está asociada con un modelo de objeto articulado (4) y con una pose de referencia particular de este modelo de objeto articulado (4);
• comparar el por lo menos un segmento de imagen de origen (13) con las siluetas de referencia y seleccionar un número predeterminado de siluetas de referencia, teniendo en cuenta, para cada silueta de referencia, o un error de coincidencia que indica cuán estrechamente la silueta de referencia coincide con el segmento de imagen de origen (13) y
o un error de consistencia que indica cuánto la pose de referencia es consistente con la pose del mismo objeto del mundo real (14) de acuerdo con lo estimado a partir de por lo menos una de imágenes de origen precedentes y siguientes (10) de la corriente de vídeo;
• recuperar de las poses de referencia de los modelos de objeto articulado (4) asociadas con la seleccionada de las siluetas de referencia; y
• calcular una estimación de la pose del modelo de objeto articulado (4) a partir de las poses de referencia de las siluetas de referencia seleccionadas.
Tipo: Patente Europea. Resumen de patente/invención. Número de Solicitud: E11405250.
Solicitante: LiberoVision AG.
Nacionalidad solicitante: Suiza.
Dirección: TECHNOPARKSTRASSE 1 8005 ZURICH SUIZA.
Inventor/es: GROSS,MARKUS, GERMANN,MARCEL, WÜRMLIN STADLER,STEPHAN, KEISER,RICHARD, ZIEGLER,REMO, NIEDERBERGER,CHRISTOPH, HORNUNG,ALEXANDER.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
PDF original: ES-2553258_T3.pdf


Patentes similares o relacionadas:
Método, sistema y producto del programa informático para determinar la presencia de microorganismos e identificar dichos microorganismos, del 29 de Julio de 2020, de BIOMERIEUX: Un método para determinar la presencia de al menos un microorganismo determinado en una placa de Petri que comprende una o más colonias de microorganismos y un medio de […]
Detección de daño de pantalla para dispositivos, del 8 de Julio de 2020, de Hyla, Inc: Un procedimiento para identificar una condición de una o más pantallas de un dispositivo electrónico, comprendiendo el procedimiento: recibir una solicitud […]
PROCEDIMIENTO DE IDENTIFICACIÓN DE IMÁGENES ÓSEAS, del 29 de Junio de 2020, de UNIVERSIDAD DE GRANADA: Procedimiento de identificación de imágenes óseas. La presente invención tiene por objeto un procedimiento para asistir en la toma de decisiones a un experto forense […]
Procedimientos, sistemas y dispositivos para analizar datos de imágenes pulmonares, del 27 de Mayo de 2020, de Pulmonx Corporation: Procedimiento para analizar datos de tomografía computarizada de un pulmón, comprendiendo el procedimiento: recibir mediante un dispositivo […]
Distribución controlada de muestras sobre sustratos, del 27 de Mayo de 2020, de Roche Diagnostics Hematology, Inc: Un procedimiento para distribuir una muestra de líquido sobre un sustrato , comprendiendo el procedimiento: obtener una […]
Sistema y procedimiento de control de calidad de platos preparados, del 14 de Mayo de 2020, de BEABLOO, S.L: Sistema y procedimiento de control de calidad de platos preparados. El sistema comprende medios de detección para detectar los ingredientes […]
Registro de imagen de catéter del seno coronario, del 13 de Mayo de 2020, de Biosense Webster (Israel), Ltd: Un aparato que comprende: un catéter cardíaco adaptado para su introducción en un seno coronario de un corazón de un sujeto vivo; una pantalla ; un dispositivo […]
Sistema y aplicación para visualizar la realidad exterior mientras se utilizan teléfonos y dispositivos móviles, del 11 de Mayo de 2020, de YAGÜE HERNANZ, Ricardo: 1. Sistema y aplicación para ver en los teléfonos y terminales móviles la realidad exterior a la vez que se usan y se visualizan sus […]