Codificador de señal de audio, decodificador de señal de audio, método para proveer una representación codificada de un contenido de audio, método para proveer una representación decodificada de un contenido de audio y programa de computación para su uso en aplicaciones de bajo retardo.
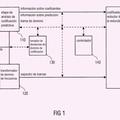
Codificador de señal de audio (100) para proveer una representación codificada (112) de un contenido de audio sobre la base de una representación de entrada (110) del contenido de audio,
la señal de audio comprende:
una ruta de dominio de transformada (120) configurada para obtener un conjunto de coeficientes espectrales (124) e información de moldeado de ruido (126) sobre la base de una representación de dominio de tiempo (122) de una porción del contenido de audio a ser codificado en un modo de dominio de transformada,
de modo que los coeficientes espectrales (124) describen un espectro de una versión de moldeado de ruido (223a; 262a; 285a) del contenido de audio;
en donde la ruta de dominio de transformada (120; 200; 230; 260) comprende un convertidor de dominio de tiempo a dominio de frecuencia (130;222;264;284) configurado para enventanar una representación de dominio de tiempo (220a; 280a) del contenido de audio, o una versión pre-procesada (262a) del mismo, para obtener una representación enventanada (221a;263;283a) del contenido de audio, y para aplicar una conversión dominio de tiempo a dominio de frecuencia, para derivar un conjunto de coeficientes espectrales (222a; 264a;284a) a partir de la representación de dominio de tiempo del contenido de audio enventanada; y
una ruta de dominio de predicción lineal excitada por código (ruta CELP) (140) configurada para obtener una información de excitación por código (144) y una información de parámetro de dominio de predicción lineal (146) sobre la base de una porción del contenido de audio a ser codificado en un modo de dominio de predicción lineal excitado por código (modo CELP);
en donde el convertidor de dominio de tiempo a dominio de frecuencia (130; 221,222; 263,264; 283,284) está configurado para aplicar una ventana de análisis asimétrico predeterminada (520;1130;1330) para un enventanado de una porción actual (1132; 1332) del contenido de audio a ser codificado en el modo de dominio de transformada tanto si la porción actual del contenido de audio es seguida por una porción subsiguiente (1142; 1342) del contenido de audio a ser codificado en el modo de dominio de transformada como si la porción actual del contenido de audio es seguida por una porción subsiguiente del contenido de audio a ser codificado en el modo CELP; y
en donde el codificador de la señal de audio está configurado para proveer selectivamente una información de cancelación de solapamiento (164), que representa componentes de la señal de cancelación de solapamiento que estarían representados por una representación en el modo de dominio de transformada de la porción subsiguiente (1142; 1342) del contenido de audio, si la porción actual (1132; 1332) del contenido de audio es seguida por una porción subsiguiente (1142; 1342) del contenido de audio a ser codificado en el modo CELP.
Tipo: Patente Internacional (Tratado de Cooperación de Patentes). Resumen de patente/invención. Número de Solicitud: PCT/EP2010/065753.
Solicitante: FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V..
Nacionalidad solicitante: Alemania.
Dirección: HANSASTRASSE 27C 80686 MUNCHEN ALEMANIA.
Inventor/es: GEIGER, RALF, RETTELBACH,NIKOLAUS, SCHNELL,MARKUS, FUCHS,Guillaume, LECOMTE,Jérémie, SCHMIDT,KONSTANTIN.
Fecha de Publicación: .
Clasificación Internacional de Patentes:
- G10L19/02 FISICA. › G10 INSTRUMENTOS MUSICALES; ACUSTICA. › G10L ANALISIS O SINTESIS DE LA VOZ; RECONOCIMIENTO DE LA VOZ; PROCESAMIENTO DE LA VOZ O EL HABLA; CODIFICACIÓN O DESCODIFICACIÓN DEL AUDIO O LA VOZ. › G10L 19/00 Técnicas de análisis-síntesis de la voz o de señales de audio para la reducción de la redundancia, p. ej. en codificadores vocales; Codificación o decodificación de la voz o de señales de audio, utilizando modelos filtro-fuente o el análisis psicoacústico (en instrumentos musicales G10H). › utilizando análisis espectrales, p. ej. codificadores vocales de transformación o codificadores vocales subbanda.
- G10L19/022 G10L 19/00 […] › Bloqueo, p. ej. agrupación de muestras en el tiempo; Elección de las ventanas de análisis; Factorización de interferencias.
- G10L19/04 G10L 19/00 […] › utilizando técnicas de predicción.
- G10L19/14
- G10L19/20 G10L 19/00 […] › utilizando codificación específica de clase de sonido, codificadores híbridos o codificación basada en objeto.
PDF original: ES-2533098_T3.pdf
Fragmento de la descripción:
Codificador de señal de audio, decodificador de señal de audio, método para proveer una representación codificada de un contenido de audio, método para proveer una representación decodificada de un contenido de audio y 5 programa de computación para su uso en aplicaciones de bajo retardo
Campo de la técnica
[1] Las formas de realización de acuerdo con la invención se relacionan con un codificador de señal de 1 audio para proveer una representación codificada de un contenido de audio con base en una representación de
ingreso de datos del contenido de audio.
[2] Las formas de realización de acuerdo con la invención se relacionan con un decodificador de señal de audio para proveer una representación decodificada de un contenido de audio con base en una representación
codificada del contenido de audio.
[3] Las formas de realización de acuerdo con la invención se relacionan con un método para proveer una representación codificada de un contenido de audio con base en una representación de ingreso de datos del
contenido de audio.
[4] Las formas de realización de acuerdo con la invención se relacionan con un método para proveer una representación decodificada de un contenido de audio con base en una representación codificada del contenido de
audio.
[5] Las formas de realización de acuerdo con la invención se relacionan con programas de computación
para aplicar tales métodos.
[6] Las formas de realización de acuerdo con la invención se relacionan con un nuevo plan de codificación para una codificación unificada de habla y audio con bajo retardo.
Antecedentes de la invención
[7] A continuación se explicarán brevemente los antecedentes de la invención a efectos de facilitar la comprensión de la invención y sus ventajas.
[8] Durante la década pasada, se hicieron grandes esfuerzos para crear la posibilidad de almacenar digitalmente y distribuir contenidos de audio con buena eficiencia bitrate. Un logro importante en este sentido es la definición de la Norma Internacional ISO/IEC 14496-3. La Parte 3 de la Norma se relaciona con la codificación y decodificación de contenidos de audio, y la subparte 4 de la parte 3 se relaciona con la codificación de audio en
general. La parte 3, subparte 4 de la norma ISO/IEC 14496 define un concepto para la codificación y decodificación de contenido de audio en general. Además, se han propuesto ulteriores mejoras a fin de mejorar la calidad y/o reducir el requerido bitrate.
[9] Asimismo, se han desarrollado codificadores de audio y decodificadores de audio que están 45 adaptados específicamente para la codificación y decodificación de señales de audio. Tales codificadores de audio
optimizados para el habla aparecen descriptos, por ejemplo, en las especificaciones técnicas "3GPP TS 26.9", "3GPP TS 26.19" y "3GPP TS 26.29" del Proyecto de Sociedad de Tercera Generación.
[1] Se ha hallado que existe una cantidad de aplicaciones en las que resulta deseable un bajo retardo en 5 la codificación y decodificación. Por ejemplo, se procura bajo retardo en las aplicaciones multimedia en tiempo real,
porque los retardos que se pueden advertir producen en el usuario en tales aplicaciones una impresión desagradable.
[11] No obstante, también se ha hallado que una combinación equilibrada entre la calidad y el bitrate a 55 veces requiere una alternancia entre modos diferentes de codificación, según el contenido de audio. Se ha hallado
que variaciones del contenido de audio traen aparejado el deseo de cambio entre los modos de codificación, como por ejemplo, entre un modo de dominio de predicción lineal de excitación codificada transformada y un modo de dominio de predicción lineal de excitación del código (como por ejemplo un modo de dominio de predicción lineal de excitación del código algebraico), o entre un modo dominio de frecuencia y un modo de dominio de predicción lineal
de excitación codificada. Esto se debe al hecho de que algunos contenidos de audio (o algunas porciones de un contenido contiguo de audio) puedan ser codificados con una mayor eficiencia de codificación en uno de los modos, mientras que otros contenidos de audio (u otras porciones del mismo contenido contiguo de audio) puedan ser codificados con mejor eficiencia de codificación en modos diferentes.
[12] En vista de esta situación, se ha hallado que resulta deseable alternar entre modos diferentes sin requerir un gran overhead del bitrate para el cambio y también sin comprometer en forma significativa la calidad de audio (por ejemplo, en la forma de un "clic" de cambio). Además, se ha hallado que la alternancia entre modos diferentes deberá ser compatible con el objetivo para tener un bajo retardo de codificación y decodificación.
[13] En vista de esta situación, un objetivo de la invención es crear un concepto para una codificación multimodo de audio que traiga aparejada una combinación equilibrada entre eficiencia bitrate, calidad de audio y retardo cuando se alterne entre modos de codificación diferentes.
Descripción de la invención
[14] Una forma de realización de acuerdo con la invención crea un codificador de señal de audio para proveer una representación codificada de un contenido de audio con base en una representación de ingreso de datos del contenido de audio. El codificador de señal de audio comprende una ruta dominio de la transformada
configurada para obtener un conjunto de coeficientes espectrales y una información para dar forma al sonido (por ejemplo, una información de factor de escala o una información de parámetro dominio de predicción lineal) con base en una representación dominio de tiempo de una porción del contenido de audio a codificar en un modo dominio de la transformada, de modo que los coeficientes espectrales describan un espectro de una versión con moldeado de ruido (por ejemplo, con moldeado de ruido de dominio de predicción lineal o procesada por factor de escala. La ruta 25 dominio de la transformada comprende un convertidor dominio de tiempo a dominio de frecuencia configurado para una función de ventana de representación de dominio de tiempo del contenido de audio, o su versión preprocesada, para obtener una representación del contenido de audio en una función de ventana, y aplicar una conversión de a dominio de tiempo dominio de frecuencia, para derivar un conjunto de coeficientes espectrales a partir de la representación de dominio de tiempo del contenido de audio en una función de ventana. El codificador de señal de 3 audio también comprende una ruta de dominio de predicción lineal excitada por código algebraico (abreviada como ruta ACELP) configurada para obtener una información de excitación de código (como por ejemplo, una información de excitación de código algebraico) y una información de dominio de predicción lineal con base en una porción del contenido de audio a codificar en un modo de dominio de predicción lineal de excitación del código (también abreviado como modo CELP) (como por ejemplo, un modo de dominio de predicción lineal excitada por código 35 algebraico). El convertidor dominio de tiempo a dominio de frecuencia está configurado para aplicar una ventana de análisis asimétrico predeterminada para una función de ventana de una porción actual del contenido de audio a codificar en el modo dominio de la transformada tanto si la porción actual del contenido de audio es sucedida por una porción subsiguiente del contenido de audio a codificar en el modo dominio de la transformada como si la porción actual del contenido de audio es sucedida por una porción subsiguiente del contenido de audio a codificar en 4 el modo CELP. El codificador de la señal de audio está configurado para proveer en forma selectiva una información de cancelación de solapamiento si la porción actual del contenido de audio (que está codificado en el modo dominio de la transformada) es sucedida por una porción subsiguiente del contenido de audio a codificar en el modo CELP.
[15] Esta realización de acuerdo con la invención se basa en el hallazgo de que una combinación 45 equilibrada entre la eficiencia de la codificación (por ejemplo, en términos de bitrate promedio), calidad de audio y
retardo de la codificación puede obtenerse mediante la alternancia entre un modo dominio de la transformada y un modo CELP, donde una función de ventana de una porción del contenido de audio a codificar en el modo dominio de la transformada es independiente de un modo en el cual una porción subsiguiente del contenido de audio está codificado, y donde una reducción o cancelación de artefactos de solapamiento, que resulta del uso de una función 5 de ventana... [Seguir leyendo]
Reivindicaciones:
1. Codificador de señal de audio (1) para proveer una representación codificada (112) de un contenido de audio sobre la base de una representación de entrada (11) del contenido de audio, la señal de audio
comprende:
una ruta de dominio de transformada (12) configurada para obtener un conjunto de coeficientes espectrales (124) e información de moldeado de ruido (126) sobre la base de una representación de dominio de tiempo (122) de una porción del contenido de audio a ser codificado en un modo de dominio de transformada,
de modo que los coeficientes espectrales (124) describen un espectro de una versión de moldeado de ruido (223a; 262a; 285a) del contenido de audio;
en donde la ruta de dominio de transformada (12; 2; 23; 26) comprende un convertidor de dominio de tiempo a 15 dominio de frecuencia (13;222;264;284) configurado para enventanar una representación de dominio de tiempo (22a; 28a) del contenido de audio, o una versión pre-procesada (262a) del mismo, para obtener una representación enventanada (221a;263;283a) del contenido de audio, y para aplicar una conversión dominio de tiempo a dominio de frecuencia, para derivar un conjunto de coeficientes espectrales (222a; 264a;284a) a partir de la representación de dominio de tiempo del contenido de audio enventanada; y
una ruta de dominio de predicción lineal excitada por código (ruta CELP) (14) configurada para obtener una información de excitación por código (144) y una información de parámetro de dominio de predicción lineal (146) sobre la base de una porción del contenido de audio a ser codificado en un modo de dominio de predicción lineal excitado por código (modo CELP);
en donde el convertidor de dominio de tiempo a dominio de frecuencia (13; 221,222; 263,264; 283,284) está configurado para aplicar una ventana de análisis asimétrico predeterminada (52; 113; 133) para un enventanado de una porción actual (1132; 1332) del contenido de audio a ser codificado en el modo de dominio de transformada tanto si la porción actual del contenido de audio es seguida por una porción subsiguiente (1142; 1342) del contenido 3 de audio a ser codificado en el modo de dominio de transformada como si la porción actual del contenido de audio es seguida por una porción subsiguiente del contenido de audio a ser codificado en el modo CELP; y
en donde el codificador de la señal de audio está configurado para proveer selectivamente una Información de cancelación de solapamiento (164), que representa componentes de la señal de cancelación de solapamiento que 35 estarían representados por una representación en el modo de dominio de transformada de la porción subsiguiente (1142; 1342) del contenido de audio, si la porción actual (1132; 1332) del contenido de audio es seguida por una porción subsiguiente (1142; 1342) del contenido de audio a ser codificado en el modo CELP.
2. El codificador de señal de audio (1) según la reivindicación 1, donde el convertidor de dominio de 4 tiempo a dominio de frecuencia (13;222;264;284) está configurado para aplicar la misma ventana (52,113,133)
para un enventanado de una porción actual (1132;1332) del contenido de audio a ser codificado en el modo de dominio de transformada y siguiendo una porción anterior (1122; 1332) del contenido de audio codificado en el modo de dominio de transformada, tanto si la porción actual del contenido de audio es seguida por una porción subsiguiente (1142; 1342) del contenido de audio a ser codificado en el modo de dominio de transformada como si la 45 porción actual del contenido de audio es seguida por una porción subsiguiente del contenido de audio a ser codificado en el modo CELP.
3. El codificador de señal de audio (1) según la reivindicación 1 o la reivindicación 2, donde la ventana de análisis asimétrico predeterminada (52, 113,133) comprende una mitad de ventana izquierda y una mitad de
ventana derecha,
en donde la mitad de ventana izquierda comprende una pendiente de transición de lado Izquierdo (522), en la cual los valores de ventana aumentan monotónlcamente desde cero a un valor central de ventana, y una porción excedida (524) en la cual los valores de ventana son mayores que el valor central de ventana y en la cual la ventana 55 comprende un máximo (524a), y
en donde la mitad de ventana derecha comprende una pendiente de transición de lado derecho (528) en la cual los valores de ventana disminuyen monotónicamente desde el valor central de ventana a cero, y una porción de cero de lado derecho (53).
4. El codificador de señal de audio (1) según la reivindicación 3, en donde la mitad de ventana izquierda comprende no más de uno por ciento de los valores de ventana de cero, y
en donde la porción de cero del lado de derecho (53) comprende una longitud de por lo menos 2% de los valores 5 de ventana de la mitad de ventana derecha.
5. El codificador de señal de audio (1) según la reivindicación 3 ó 4, en donde los valores de ventana de la mitad de ventana derecha de la ventana de análisis asimétrico predeterminada (52) son menores que el valor central de ventana, de modo que no hay porción excedida en la mitad de ventana derecha de la ventana de análisis
asimétrico predeterminada.
6. El codificador de señal de audio (1) según cualquiera de las reivindicaciones 1 a 5, en donde una porción diferente de cero de la ventana de análisis asimétrico predeterminada (52) es más corta, por lo menos en 1% que una longitud de trama.
7. El codificador de señal de audio (1) según cualquiera de las reivindicaciones 1 a 6, en donde el codificador de señal de audio está configurado de modo que las porciones subsiguientes (1122, 1132, 1162,1172; 1322,1332, 1362,1372) del contenido de audio a ser codificado en el modo de dominio de transformación comprende una superposición temporal de por lo menos 4%; y
en donde el codificador de señal de audio está configurado de modo que una porción actual (1132; 1332) del contenido de audio a ser codificado en el modo de dominio de transformada y una porción subsiguiente (1142; 1342) del contenido de audio a ser codificado en el modo de dominio de predicción lineal excitada por código comprende una superposición temporal; y 25
en donde el codificador de la señal de audio está configurado para proveer selectivamente la información de cancelación de solapamiento (164), de modo que la información de cancelación de solapamiento permite una provisión de una señal de cancelación (364) para artefactos de solapamiento de cancelación en una transición desde una porción (1232) del contenido de audio codificado en el modo de dominio de transformada a una porción 3 (1242) del contenido de audio codificado en el modo CELP en un decodificador de señal de audio (3).
8. El codificador de señal de audio (1) según cualquiera de las reivindicaciones 1 a 7, en donde el codificador de la señal de audio está configurado para seleccionar una ventana (113; 133) para un enventanado de una porción actual (1132;1332) del contenido de audio independiente de un modo que se usa para una codificación
de una porción subsiguiente (1142;1342) del contenido de audio que se superpone temporalmente con la porción actual del contenido de audio, de modo que la representación enventanada (221a;263a;283a) de la porción actual del contenido de audio se superpone con una porción subsiguiente (1142;1342) del contenido de audio incluso si la porción subsiguiente del contenido de audio está codificada en el modo CELP; y
en donde el codificador de la señal de audio está configurado para proveer, en respuesta a una detección de que la porción subsiguiente (1142; 1342) del contenido de audio va a ser codificada en un modo CELP, una información de cancelación de solapamiento (164) que representa componentes de señal de cancelación de solapamiento que serían representados por una representación de modo de dominio de transformada de la porción subsiguiente (1142; 1342) del contenido de audio.
9. El codificador de señal de audio (1) según cualquiera de las reivindicaciones 1 a 8, en donde el convertidor de dominio de tiempo a dominio de frecuencia (13; 221, 222, 263, 264; 283, 284) está configurado para aplicar la ventana de análisis asimétrico predeterminada (52; 116) para un enventanado de una porción actual (1162) del contenido de audio a ser codificado en el modo de dominio de transformada y siguiendo una porción
(1152) del contenido de audio codificado en el modo CELP, de manera tal que una representación enventanada (221a;263a;283a) de la porción actual (1162) del contenido de audio a ser codificado en el modo de dominio de transformada (1162) del contenido de audio a ser codificado en el modo de dominio de transformada se superpone temporalmente con la porción previa (1152) del contenido de audio codificado en el modo CELP, y
de modo que las porciones (1122, 1132,1162, 1172) del contenido de audio a ser codificado en el modo de dominio de transformada son enventanadas usando la misma ventana de análisis asimétrico predeterminada (52, 112, 113, 116,117) independiente de un modo en el cual una porción previa del contenido de audio está codificada y es independiente de un modo en el cual una porción subsiguiente del contenido de audio está codificada.
1. El codificador de señal de audio (1) según la reivindicación 9, en donde el codificador de señal de audio está configurado para proveer selectivamente una información de cancelación de solapamiento (164) si la porción actual (1162) del contenido de audio sigue una porción anterior (1152) del contenido de audio codificado en el modo CELP.
11. El codificador de señal de audio (1) según una de las reivindicaciones 1 a 8, en donde el convertidor de dominio de tiempo a dominio de frecuencia (13; 221,222; 263,264; 283,284) está configurado para aplicar una ventana de análisis de transición asimétrica dedicada (136) que es diferente de la ventana de análisis asimétrico predeterminada (52;132;133;137), para un enventanado de una porción actual (1362) del contenido de audio a
ser codificado en el modo de dominio de transformada y siguiendo una porción (1352) del contenido de audio codificado en el modo CELP.
12. El codificador de la señal de audio según cualquiera de las reivindicaciones 1 a 11, en donde la ruta de dominio de predicción lineal excitada por código (ruta CELP) (14) es una ruta de dominio de predicción lineal
excitada por código algebraico configurada para obtener una información de excitación de código algebraico (144) y una información de parámetro de dominio de predicción lineal (146) sobre la base de una porción del contenido de audio a ser codificado en un modo de dominio de predicción lineal excitada por código algebraico (modo CELP).
13. Decodificador de señal de audio (3) para proveer una representación decodificada (312) de un 2 contenido de audio sobre la base de una representación codificada (31) del contenido de audio, el decodificador de
señal de audio comprende:
una ruta de dominio de transformada (32;4;43;46) configurada para obtener una representación de dominio de tiempo (326;416;446;476) de una porción (1222,1232,1262,1272; 1422,1432,1462,1472) del contenido de audio 25 codificado en el modo de dominio de transformada sobre la base de un conjunto de coeficientes espectrales (322,412,442,472) y una información de moldeado de ruido (324;414;444;474);
en donde la ruta de dominio de transformada comprende un convertidor de dominio de frecuencia a dominio de tiempo (33;423,424;451, 452; 484,485) configurado para aplicar una conversión de dominio de frecuencia a 3 conversión de dominio de tiempo (423;451;484) y un enventanado (424; 452;485), para derivar una representación de dominio de tiempo enventanada (424a; 452a; 485a) del contenido de audio a partir del conjunto de coeficientes espectrales o de una versión preprocesada del mismo;
una ruta de dominio de predicción lineal excitada por código (34) configurada para obtener una representación de 35 dominio de tiempo (346) del contenido de audio codificado en un modo de dominio de predicción lineal excitada por código (modo CELP) sobre la base de una información de excitación por código (342) y una información de parámetro de dominio de predicción lineal (344); y
en donde el convertidor de dominio de frecuencia a dominio de tiempo está configurado para aplicar una ventana de 4 síntesis asimétrica predeterminada (62;123;143) para un enventanado de una porción actual (1232;1432) del contenido de audio codificado en el modo de dominio de transformada y siguiendo una porción previa (1222;1422) del contenido de audio codificado en el modo de dominio de transformada tanto si la porción actual del contenido de audio es seguida por una porción subsiguiente (1242;1442) del contenido de audio codificado en el modo de dominio de transformada como si la porción actual del contenido de audio es seguida por una porción subsiguiente del 45 contenido de audio codificado en el modo CELP; y
en donde el decodificador de la señal de audio (3) está configurado para proveer selectivamente una señal de cancelación de solapamiento (362), que se incluye en la representación codificada (31) del contenido de audio, y que representa los componentes de señal de cancelación de solapamiento que estarían representados por una 5 representación en el modo de dominio de transformada de la porción subsiguiente (1142; 1342) del contenido de audio, si la porción actual del contenido de audio codificado en el modo de dominio de transformada es seguida por una porción subsiguiente del contenido de audio codificado en el modo CELP.
14. El decodificador de señal de audio (3) según la reivindicación 13, en donde el convertidor de 55 dominio de frecuencia a dominio de tiempo (33;423,424; 451,452; 484,485) está configurado para aplicar la misma
ventana (62; 123; 143) para un enventanado de una porción actual (1232; 1432) de un contenido de audio codificado en el modo de dominio de transformada y siguiendo una porción anterior (1222;1422) del contenido de audio codificado en el modo de dominio de transformada tanto si la porción actual (1232;1432) del contenido de audio es seguida por una porción subsiguiente (1242;1442) del contenido de audio codificado en el modo de dominio
de transformada como si la porción actual del contenido de audlo es seguida por una porción subsiguiente del contenido de audio codificado en el modo CELP.
15. El decodificador de señal de audio (3) según la reivindicación 13 ó la reivindicación 14, en donde la 5 ventana de síntesis asimétrica predeterminada (62; 123; 143) comprende una mitad de ventana izquierda y una
mitad de ventana derecha,
en donde la mitad de ventana izquierda comprende una porción cero de lado izquierdo (622) y una pendiente de transición de lado izquierdo (624), en la cual los valores de ventana aumentan monotónicamente de cero a un valor 1 central de ventana; y
en donde la mitad de ventana derecha comprende una porción excedida (628) en la cual los valores de ventana son mayores que el valor central de ventana y en la cual la ventana comprende un máximo (628a), y una pendiente de transición del lado derecho (63) en la cual los valores de ventana disminuyen monotónicamente desde el valor 15 central de ventana a cero.
16. El decodificador de señal de audio (3) según la reivindicación 15, en donde la porción cero del lado izquierdo (622) comprende una longitud de por lo menos 2% de los valores de ventana de la mitad de ventana
izquierda, y
en donde la mitad de ventana derecha comprende no más de uno por ciento de valores de ventana cero.
17. El decodificador de señal de audio (3) según la reivindicación 15 ó la reivindicación 16, en donde los valores de ventana de la mitad de ventana izquierda de la ventana de síntesis asimétrica predeterminada (62;
122, 123,126; 142, 143,147) son menores que el valor central de ventana, de manera tal que no hay porción excedida en la mitad de ventana izquierda de la ventana de síntesis asimétrica predeterminada.
18. El decodificador de señal de audio según cualquiera de las reivindicaciones 13 a 17, en donde una porción diferente de cero de la ventana de síntesis asimétrica predeterminada
(62;122,123,126;142,143,147) es más corta, por lo menos en un 1%, que una longitud de trama.
19. El decodificador de señal de audio (3) según cualquiera de las reivindicaciones 13 a 18, en donde el decodificador de señal de audio está configurado de modo que las porciones subsiguientes (1222, 1232, 1262, 1272; 1422, 1432, 1462, 1472) del contenido de audio codificado en el modo de dominio de transformada comprende una
superposición temporal de por lo menos 4%; y
en donde el decodificador de señal de audio está configurado de modo que una porción actual (1232; 1432) del contenido de audio codificado en el modo de dominio de transformada y una porción subsiguiente (1242; 1442) del contenido de audio codificado en el modo de dominio de predicción lineal excitada por código comprende una 4 superposición temporal; y
en donde el decodificador de señal de audio está configurado para proveer selectivamente la señal de cancelación de solapamiento (364) sobre la base de la información de cancelación de solapamiento (362), de modo que la señal de cancelación de solapamiento reduce o cancela los artefactos de solapamiento en una transición de la porción 45 actual del contenido de audio en el modo de dominio de transformada a una porción subsiguiente del contenido de audio codificado en el modo CELP.
2. El decodificador de señal de audio (3) según cualquiera de las reivindicaciones 13 a 19, en donde el decodificador de señal de audio está configurado para seleccionar una ventana (123;143) para un enventanado
de una porción actual (1232;1432) del contenido de audio independiente de un modo que se usa para la codificación de una porción subsiguiente (1242; 1442) del contenido de audio, que se superpone temporalmente con la porción actual (1232;1432) del contenido de audio, de modo que la representación enventanada (424a;452a;485a) de la porción actual del contenido de audio se superpone temporalmente con la porción subsiguiente del contenido de audio aun si la porción subsiguiente del contenido de audio está codificada en el modo CELP; y 55
en donde el decodificador de señal de audio (3) está configurado para proveer, en respuesta a una detección de que la porción subsiguiente del contenido de audio está codificada en el modo CELP, una señal de cancelación de solapamiento (364) para reducir o cancelar artefactos de solapamiento en una transición de la porción actual (1232;1432) del contenido de audio codificado en el modo de dominio transformada a la porción subsiguiente
(1242; 1442) del contenido de audio codificado en el modo CELP.
21. El decodificador de señal de audio (3) según cualquiera de las reivindicaciones 13 a 2, en donde el convertidor de dominio de frecuencia a dominio de tiempo (33; 423,424; 451,452; 484,485) está configurado para
aplicar la ventana de síntesis asimétrica predeterminada (62;123;143) para un enventanado de una porción actual (1262; 1462) del contenido de audio a ser codificado en el modo de dominio de transformada y siguiendo una porción anterior (1252;1452) del contenido de audio codificado en el modo CELP, de modo que porciones (1222; 1232; 1262; 1272) del contenido de audio codificado en el modo de dominio de transformada están enventanadas utilizando la misma ventana de síntesis asimétrica predeterminada (62; 122,123,126,127) 1 independiente de un modo en el cual una porción anterior del contenido de audio está codificada y es independiente de un modo en el cual una porción subsiguiente del contenido de audio está codificado, y
de modo que una representación de dominio de tiempo enventanada (424a; 452a; 485a) de la porción actual del contenido de audio codificado en el modo de dominio de transformada se superpone temporalmente con la porción 15 anterior (1252; 1452) del contenido de audio codificado en el modo CELP.
22. El decodificador de señal de audio (3) según la reivindicación 21, en donde el decodíficador de señal de audio está configurado para proveer selectivamente una señal de cancelación de solapamíento (364) sobre la base de una información de cancelación de solapamiento (362) si la porción actual (1262) del contenido de audio
sigue a una porción anterior (1252) del contenido de audio codificado en el modo CELP.
23. El decodificador de señal de audio (3) según cualquiera de las reivindicaciones 13 a 2, en donde el convertidor de dominio de frecuencia a dominio de tiempo (33; 423,424; 451,452; 484,485) está configurado para aplicar una ventana de síntesis de transición asimétrica dedicada (146), que es diferente de la ventana de síntesis
asimétrica predeterminada (62; 123; 143), para un enventanado de una porción actual (1462) del contenido de audio codificado en el modo de dominio de transformada y siguiendo a una porción (1452) del contenido de audio codificado en el modo CELP.
24. El decodificador de señal de audio según cualquiera de las reivindicaciones 13 a 23, en donde la ruta 3 de dominio de predicción lineal excitada por código (34) es una ruta de dominio de predicción lineal excitada por
código algebraico (346) del contenido de audio codificado en un modo de dominio de predicción lineal excitada por código algebraico (modo CELP) sobre la base de una información de excitación de código algebraico (342) y una información de parámetro de dominio de predicción lineal (344).
25. Método para proveer una representación codificada de un contenido de audio sobre la base de una
representación de entrada del contenido de audio, el método comprende:
obtener un conjunto de coeficientes espectrales y una información de moldeado de ruido sobre la base de una representación de dominio de tiempo de una porción del contenido de audio a ser codificado en el modo de dominio 4 de transformada, de modo que los coeficientes espectrales describen un espectro de una versión de moldeado de ruido del contenido de audio,
en donde una representación de dominio de tiempo del contenido de audio a ser codificado en el modo de dominio de transformada, o una versión preprocesada de la misma, es enventanada, y en donde una conversión de dominio 45 de tiempo a dominio de frecuencia se aplica para derivar un conjunto de coeficientes espectrales de la representación de dominio de tiempo enventanada del contenido de audio;
obtener una información de excitación de código y una información de dominio de predicción lineal sobre la base de una porción del contenido de audio a ser codificada en un modo de dominio de predicción lineal excitada por código 5 (modo CELP);
en donde una ventana de análisis asimétrico predeterminada se aplica para el enventanado de una porción actual del contenido de audio a ser codificado en el modo de dominio de transformada y siguiendo una porción del contenido de audio codificado en el modo de dominio de transformada tanto si la porción actual del contenido de 55 audio es seguida por una porción subsiguiente del contenido de audio a ser codificado en el modo de dominio de transformada como si la porción actual del contenido de audio es seguida por una porción subsiguiente del contenido de audio a ser codificado en el modo CELP; y
en donde una información de cancelación de solapamiento, que representa componentes de la señal de cancelación
de solapamiento que estarían representados por una representación en el modo de dominio de transformada de la porción subsiguiente (1142; 1342) del contenido de audio, es provista selectivamente si la porción actual del contenido de audio es seguida por una porción subsiguiente del contenido de audio a ser codificado en el modo CELP.
26. Método para proveer una representación decodificada de un contenido de audio sobre la base de una
representación codificada del contenido de audio, el método comprende:
obtener una representación de dominio de tiempo de una porción del contenido de audio codificado en un modo de 1 dominio de transformada sobre la base de un conjunto de coeficientes espectrales y una información de moldeado
de ruido,
en donde una conversión de dominio de frecuencia a dominio de tiempo y un enventanado se aplican para derivar una representación de dominio de tiempo enventanada del contenido de audio a partir del conjunto de coeficientes 15 espectrales o a partir de una versión preprocesada del mismo; y
obtener una representación de dominio de tiempo del contenido de audio codificado en un modo de dominio de predicción lineal excitada por código sobre la base de una información de excitación por código y una información de parámetro de dominio de predicción lineal;
en donde una ventana de síntesis asimétrica predeterminada se aplica para un enventanado de una porción actual del contenido de audio codificado en el modo de dominio de transformada y siguiendo una porción previa del contenido de audio codificado en el modo de dominio de transformada tanto si la porción actual del contenido de audio es seguida por una porción subsiguiente del contenido de audio codificado en el modo de dominio de 25 transformada y si la porción actual del contenido de audio es seguida por una porción subsiguiente del contenido de audio codificado en el modo CELP; y
en donde una señal de cancelación de solapamiento es provista selectivamente sobre la base de una información de cancelación de solapamiento, que se incluye en la representación codificada del contenido de audio, y que 3 representa los componentes de señal de cancelación de solapamiento que estarían representados por una representación en el modo de dominio de transformada de la porción subsiguiente (1142; 1342) del contenido de audio, si la porción actual del contenido de audio es seguida por una porción subsiguiente del contenido de audio codificado en el modo CELP.
27. Un programa de computación para desarrollar un método según la reivindicación 25 ó 26 cuando el
programa de computación corre en una computadora.
Patentes similares o relacionadas:
Decodificación de audio estéreo paramétrico, del 9 de Enero de 2019, de DOLBY INTERNATIONAL AB: Receptor, que comprende: un demultiplexor para desmultiplexar un flujo de bits para obtener una señal mono y parámetros de amplitud estéreo; […]
Receptor y método para decodificar flujo de datos codificado estéreofónico paramétrico, del 20 de Septiembre de 2017, de DOLBY INTERNATIONAL AB: Receptor, que comprende: un demultiplexor configurado para extraer una señal monofónica codificada y parámetros de amplitud estereofónica […]
Método de codificación, método de descodificación, codificador, descodificador, programa y medio de grabación, del 29 de Marzo de 2017, de NIPPON TELEGRAPH AND TELEPHONE CORPORATION: Un método de codificación de voz o de señales acústicas que comprende adquirir códigos correspondientes a residuos de predicción obtenidos según […]
Dispositivo de codificación de sonido y procedimiento de codificación de sonido, del 25 de Enero de 2017, de III Holdings 12, LLC: Un aparato de codificación de voz que comprende: una sección de análisis de parámetro de predicción que calcula una diferencia de retardo y una relación […]
 Codificador y decodificador de audio para codificar tramas de señales de audio muestreadas, del 2 de Febrero de 2016, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un codificador de audio adaptado para codificar tramas de una señal de audio muestreada para obtener tramas codificadas, en el que una […]
Codificador y decodificador de audio para codificar tramas de señales de audio muestreadas, del 2 de Febrero de 2016, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un codificador de audio adaptado para codificar tramas de una señal de audio muestreada para obtener tramas codificadas, en el que una […]
Codificador y descodificador de audio para codificar y descodificar muestras de audio, del 6 de Enero de 2016, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un codificador de audio para codificar muestras de audio, que comprende: un primer codificador de introducción de distorsión por repliegue del espectro […]
Códec de audio sin pérdidas escalable y herramienta de autoría, del 6 de Mayo de 2015, de DTS, INC: Un método para codificar un flujo de bits sin pérdidas escalable para muestras de audio de PCM de M-bits para decodificar mediante un decodificador sin […]
Codificador de extensión de ancho de banda, descodificador de extensión de ancho de banda y vocoder de fase, así como métodos correspondientes y programa de computadora, del 25 de Marzo de 2015, de FRAUNHOFER-GESELLSCHAFT ZUR FORDERUNG DER ANGEWANDTEN FORSCHUNG E.V.: Un codificador de extensión de ancho de banda para codificar una señal de audio , la señal de audio que comprende una señal […]